java jdk到这里下载:https://www.oracle.com/java/technologies/downloads/#java8-windows
文章目录
前言
Shell/Hadoop fs/HDFS/dfs的一些相关操作,相当于是在集群内部,跟集群的一些客户端打交道

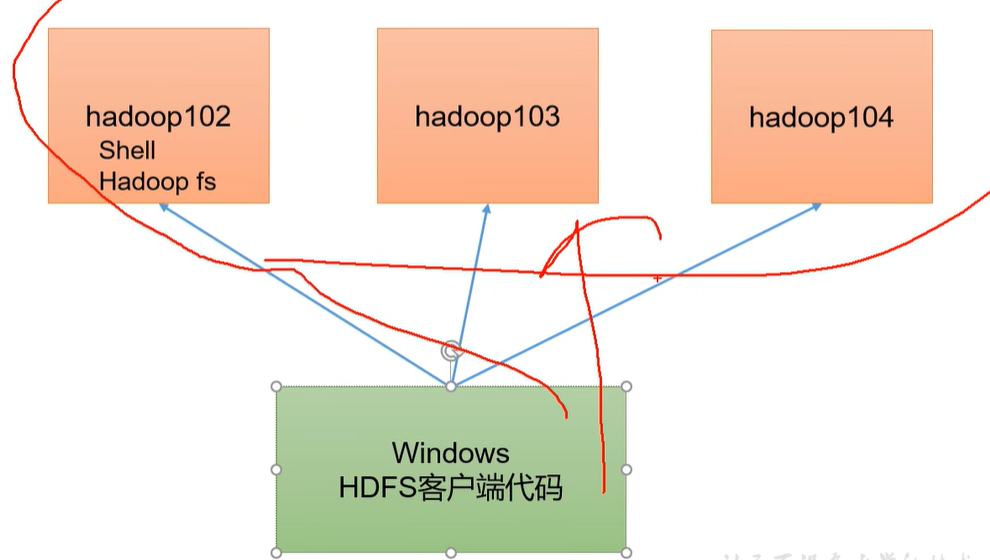
本文目标:希望在Windows环境对远程的集群进行一个客户端访问,于是现在就在Windows环境上写代码,写HDFS客户端代码,远程连接上集群,对它们进行增删改查相关操作。
一、window10安装配置hadoop
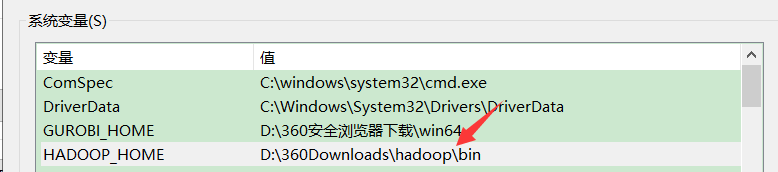
想让我们的windows能够连接上远程的Hadoop集群,windows里面也得有相关的环境变量。
下载hadoop3.2.2 windows版到非中文路径(我虚拟机上也是3.2.4,然而windwow版本最新只有3.2.2)
下载hadoop安装包:
https://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
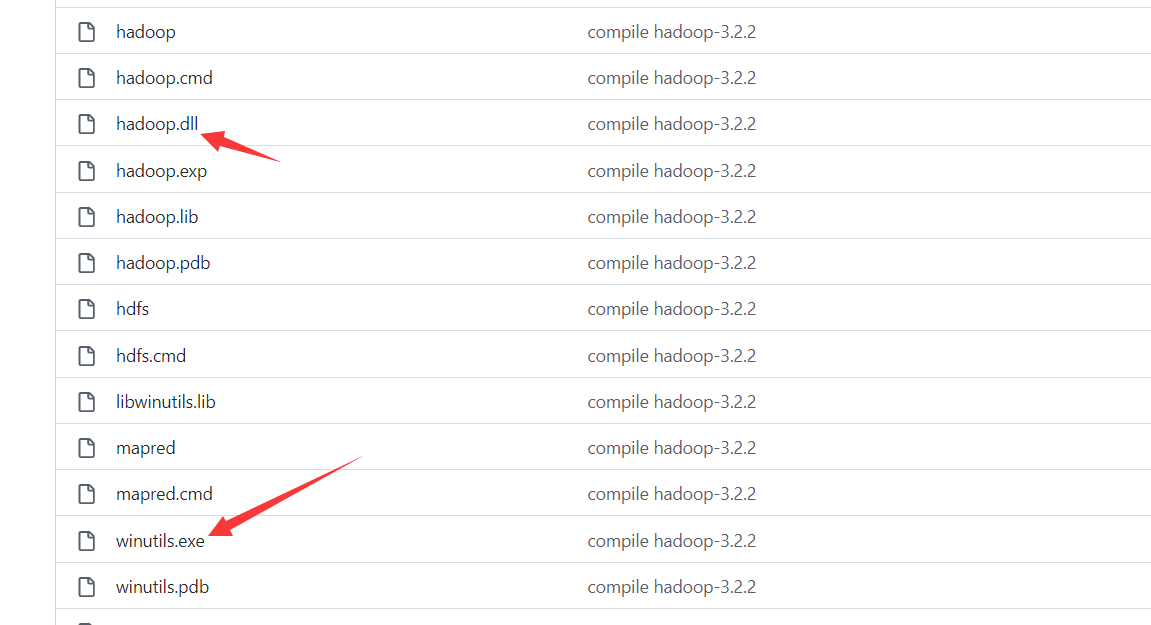
下载windows下使用hadoop需要的工具 winutils.exe 和 hadoop.dll:
https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.2/bin
选择这两个下载即可:
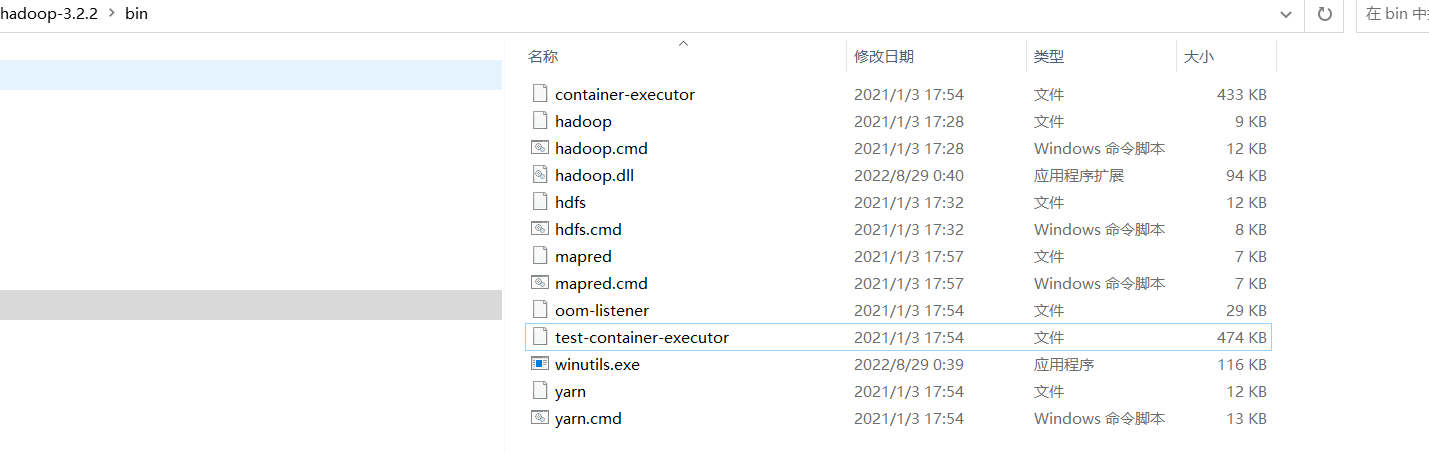
把这两个文件放到放入hadoop bin 目录下即可:
把整个hadoop文件夹移动到D盘。
bin目录加入环境变量:
在data目录下,创建两目录 namenode,datanode

进入etc/hadoop目录,修改core-site.xml
<configuration>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/D://360Downloads//hadoop//data//temp</value>
</property>
</configuration>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D://360Downloads//hadoop//data//namenode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/D://360Downloads//hadoop//data//snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/D://360Downloads//hadoop//data//snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D://360Downloads//hadoop//data//datanode</value>
</property>
</configuration>
把jdk文件放到与hadoop同级的文件夹下面(主要是没有空格就行)
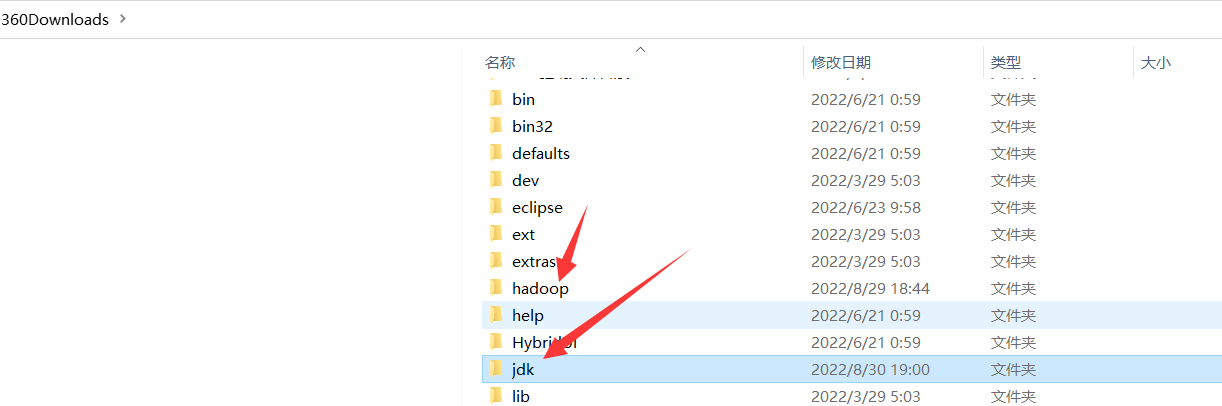
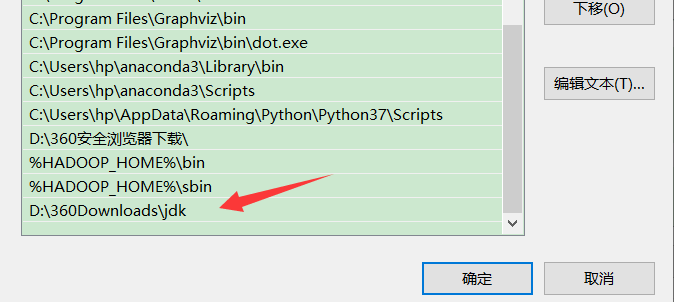
把jdk配置到环境变量:
找到hadoop-env.cmd 配置jdk路径
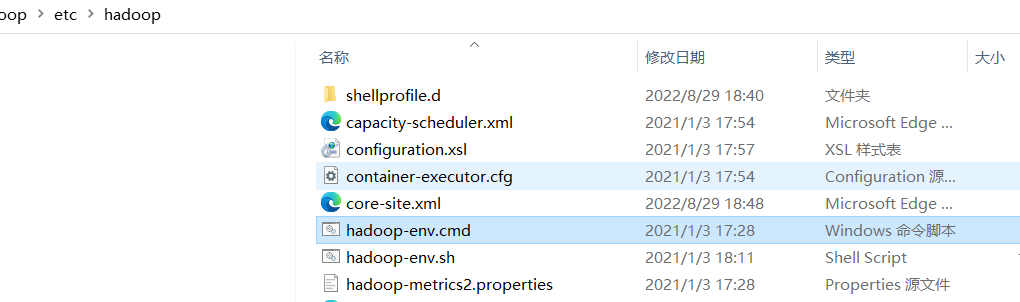
修改如下:

查看hadoop是否成功,cmd输入:hadoop
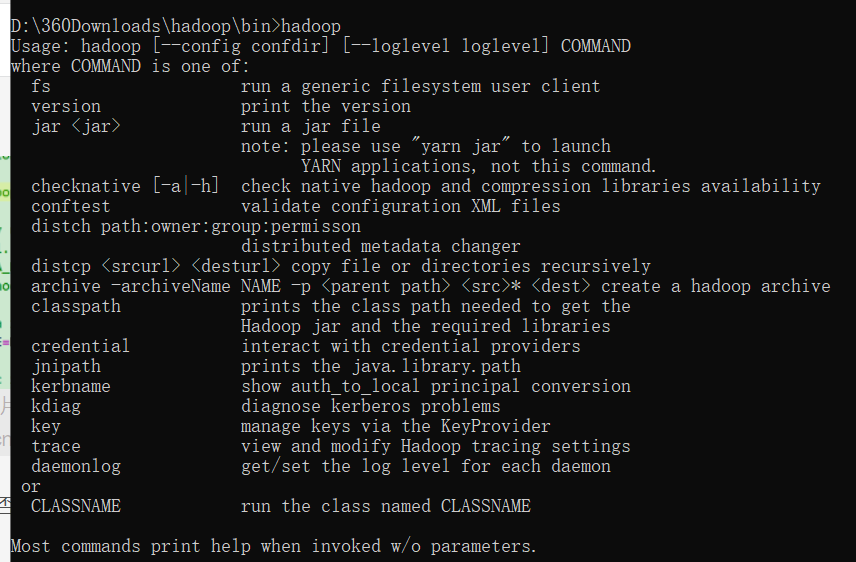
参考文章:
https://blog.csdn.net/qq_40278285/article/details/113742065
二、启动集群
初始化:
hdfs namenode -format
如下:
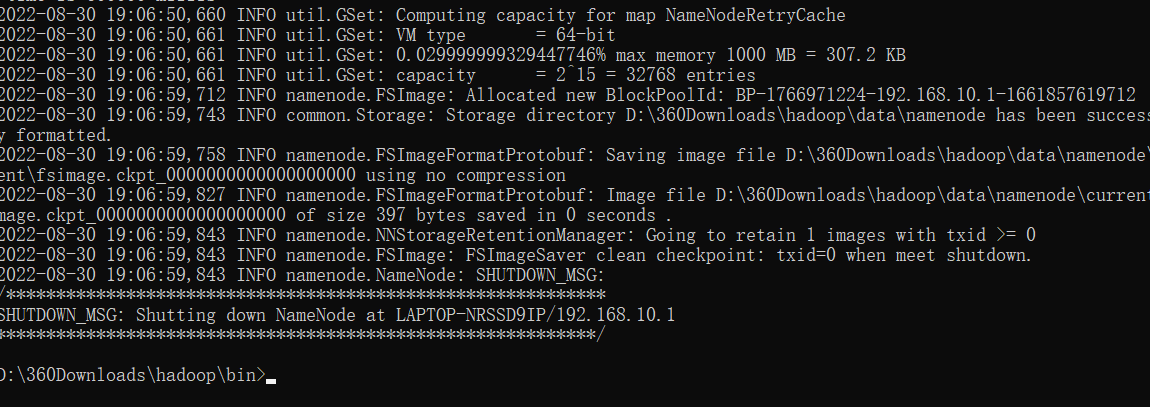
可以看到data下的namenode不是空的了:

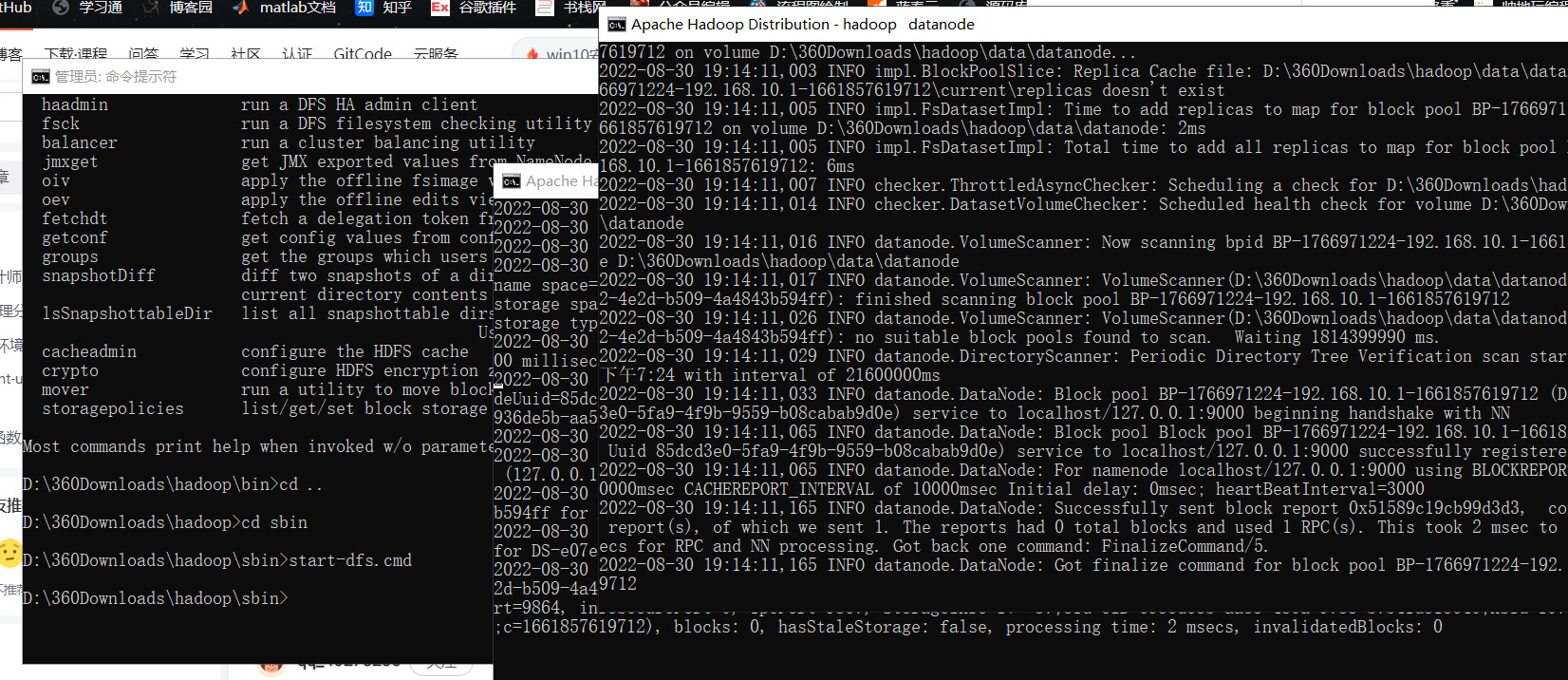
切换到sbin目录下,执行:
start-dfs.cmd
如下:
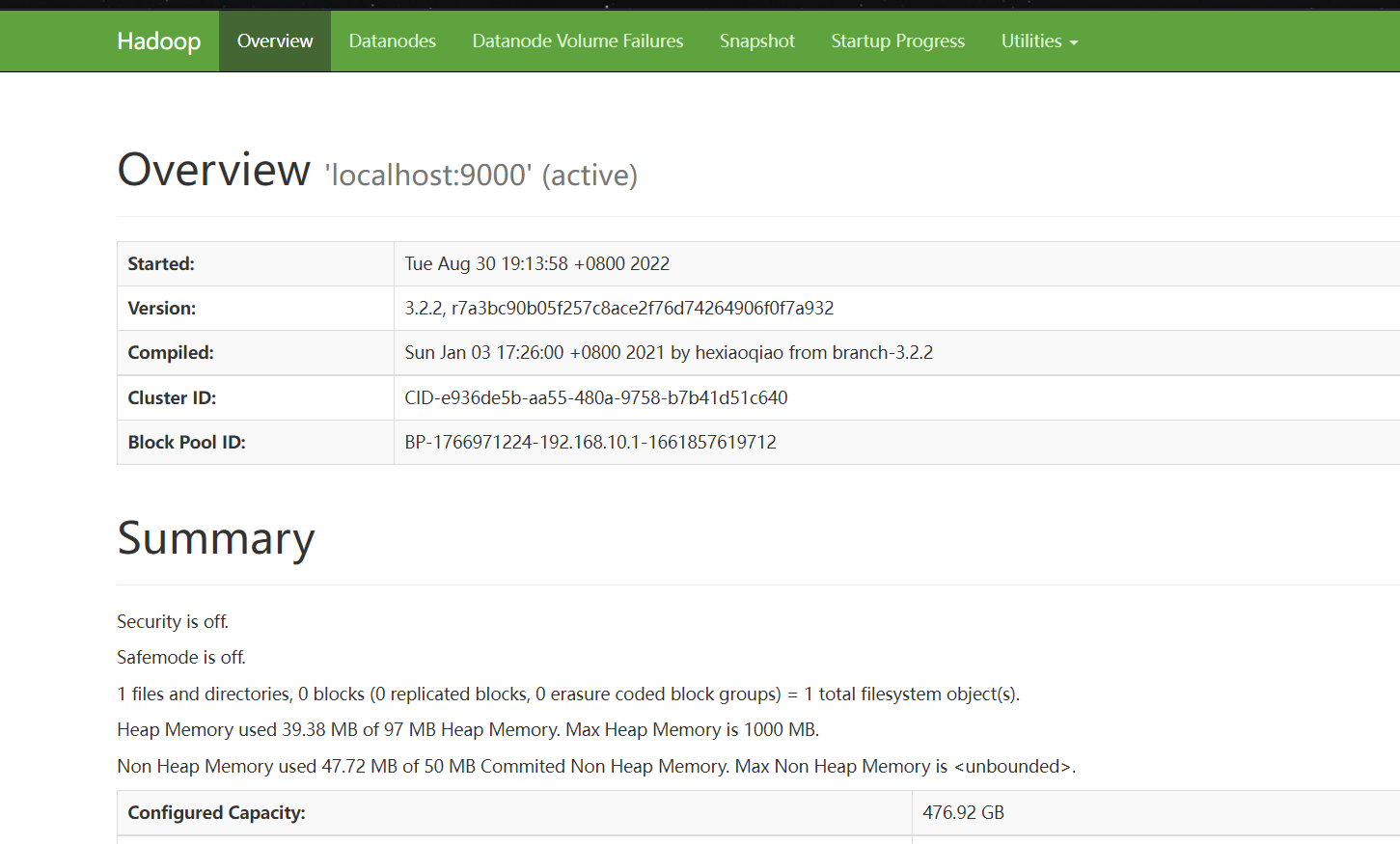
Web界面查看HDFS信息,在浏览器输入http://localhost:9870/,可访问NameNode
如下: