日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
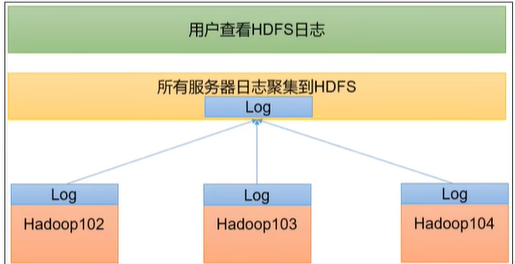
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意: 开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和HistoryServer。
文章目录
一、配置步骤
1.1 配置 yarn-site.xml
vim yarn-site.xml
添加内容:
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
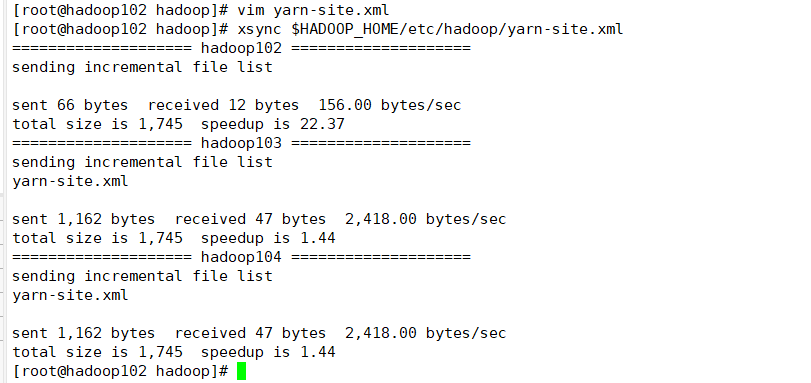
1.2 分发配置
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
如下:
1.3 重启NodeManager 、ResourceManager 和 HistoryServer
先关闭:
mapred --daemon stop historyserver
sbin/stop-yarn.sh
再启动:
sbin/start-yarn.sh
mapred --daemon start historyserver
如下:

二、测试
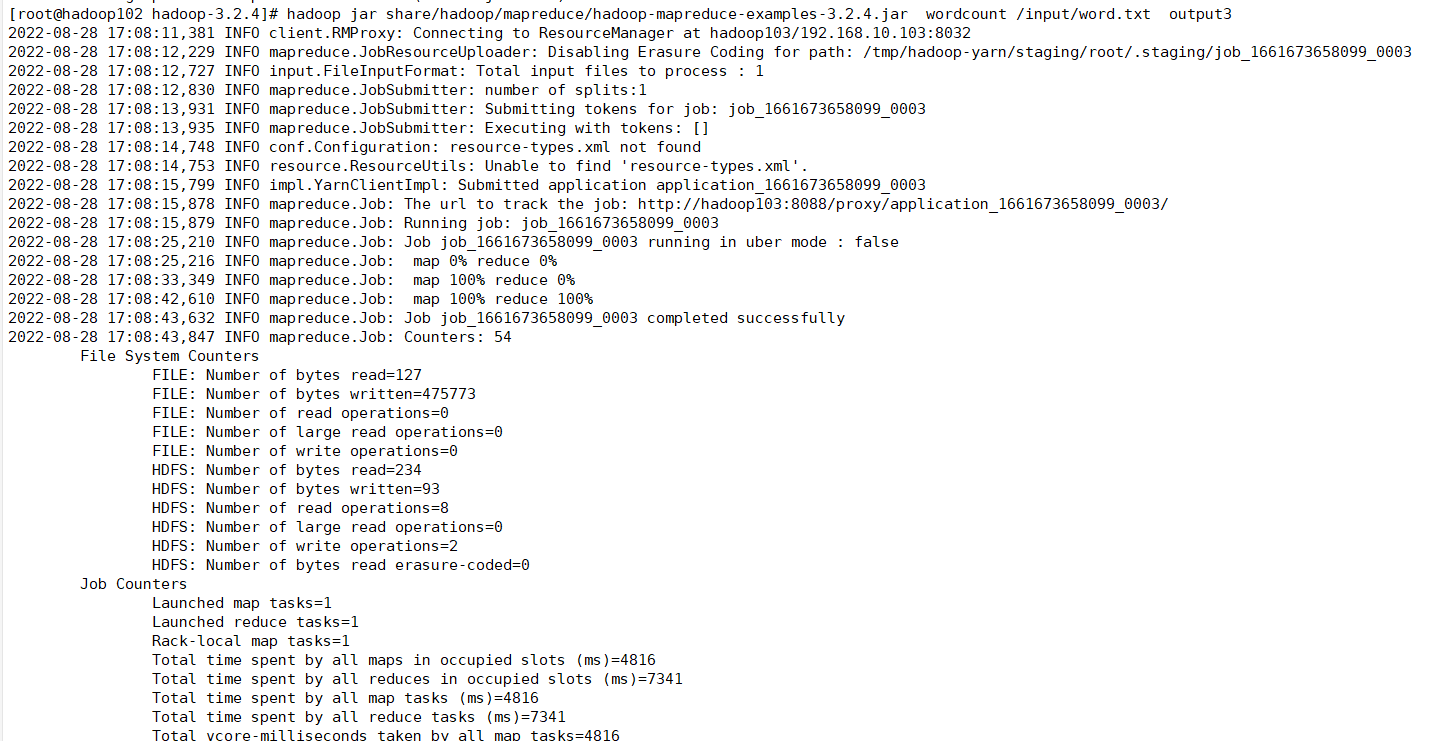
2.1 执行程序
执行程序(注意输出路径不能存在):
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar wordcount /input/word.txt output3
如下:
2.2 查看日志
浏览器:http://hadoop102:19888/jobhistory
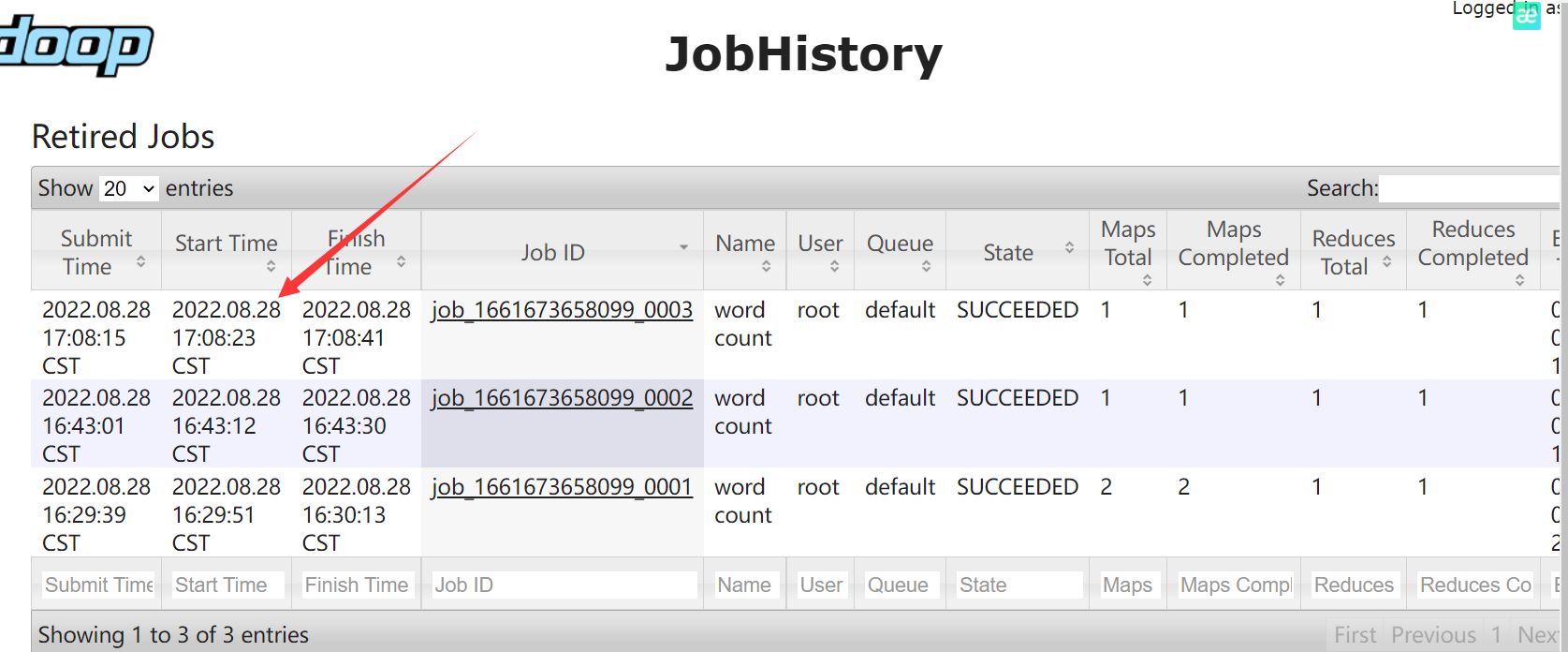
点击job ID 就可以查看日志:
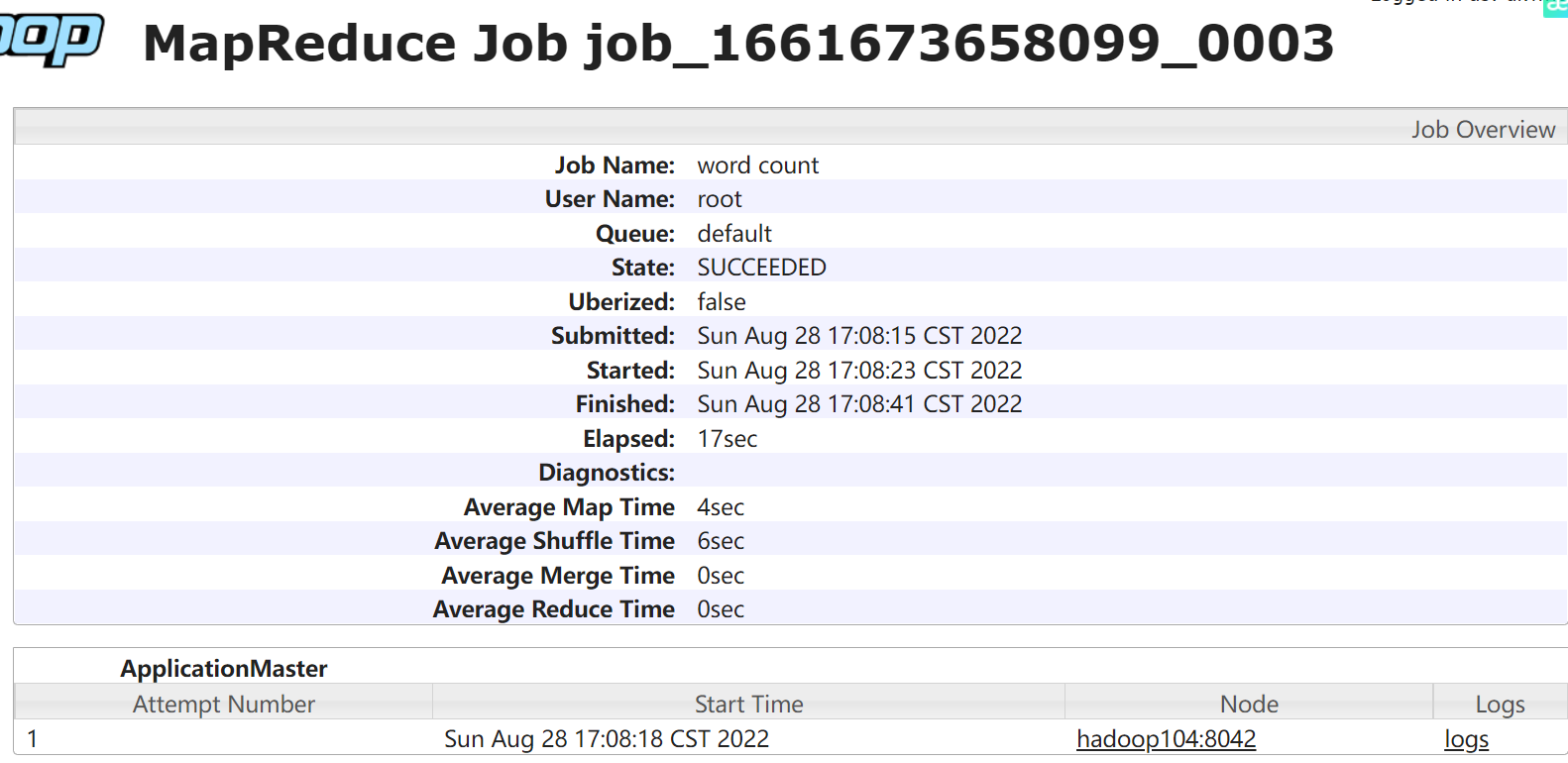
点击右小角的logs,查看运行日志详情:
