推荐算法相信大家都不陌生,日常生活的各种APP都会根据你的喜好和特征来给你推荐,接下来详细介绍一下其中的基于内容的推荐算法
基于内容的模式起源于信息检索领域,这种模式是以物品的内容为基础,推荐的原理是分析系统的历史数据,提取对象的内容特种和用户的兴趣偏好。
这里关键的环节是计算被推荐对象的内容特征和用户模型的兴趣特征二者之间的相似性。基于内容的推荐算法不需要大量的用户数据,广泛使用于大量文本信息的场合。
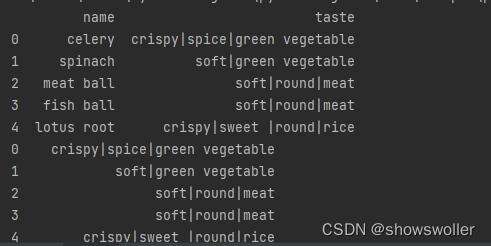
问题描述:你经常到一家店去吃麻辣香锅,老板开发了一个菜品推荐程序,老板先整理出店里各种菜品的口味记录到数据文件中,在你点菜时,程序分析出你的历史评价得知你喜欢的菜品,并据此推荐你可能喜欢的菜品
数据集请点赞关注收藏后私信博主要
问题分析:推荐算法使用的是各个菜品的口味特征为文本类型,可以考虑构建taste特征的tifdf矩阵,对文本信息向量化处理,然后使用距离度量方法,计算相似度,然后推荐。
数据如下
结果如下
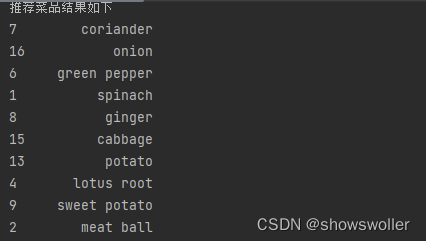
可以看出,对于你评分较高的芹菜,系统能够推荐出相似度较高的菜品
源码如下
import pandas as pd
from numpy import *
from sklearn.feature_extraction.text import TfidfVectorizer
food=pd.read_csv(r'hot-spicy pot.csv')
print(food.head())
print(food['taste'].head())
from sklearn.metrics.pairwise import pairwise_distances
tfidf=TfidfVectorizer(stop_words='english')
tfidf_matrix=tfidf.fit_transform(food['taste'])
print(tfidf_matrix.shape)
cosine_sim=pairwise_distances(tfidf_matrix,metric='cosine')
def content_based_recommendation(name,cosine_sim=cosine_sim):
idx=indices[name]
sim_scores=list(enumerate(cosine_sim[idx]))
sim_scores=sorted(sim_scores,key=lambda x:x[1])
sim_scores=sim_scores[1:11]
food_indices=[i[0]for i in sim_scores]
return food['name'].iloc[food_indices]
indices=pd.Series(food.index,index=food['name']).drop_duplicates()
result=content_based_recommendation("celery")
print("推荐菜品结果如下")
print(result)数据集请点赞关注收藏后私信博主要