以下Code加入了后台运行(并发),但没有任何控制,时间不固定。
#/bin/bash v_start=`date "+%s"` for((i=1; i<=4; i++)) do { echo "success" sleep 2 }& done wait v_end=`date "+%s"` echo "Time:$((v_end-v_start))"
展示:
[root@GipagodHost mnt]# sh x.sh success success success success Time:2 #如果进程数量增大, 则此处的时间不会等于单个进程的消耗时间 [root@GipagodHost mnt]#
实现了并发目的,但不受任何控制,如果每个单独进程消耗资源较多,进程数有很多,会造成资源耗尽。为了控制进程数量,我们引入了管道和文件操作符;
无名管道: 就是我们经常使用的 例如: cat text | grep "abc" 那个“|”就是管道,只不过是无名的,可以直接作为两个进程的数据通道;
有名管道: mkfilo指令可以创建一个管道文件 ,例如: mkfifo fifo_file;
管道有一个特点,如果管道中没有数据,那么取管道数据的操作就会停滞,直到管道内进入数据,然后读出后才会终止这一操作,同理,写入管道的操作,如果没有读取操作,这一个动作也会停滞。
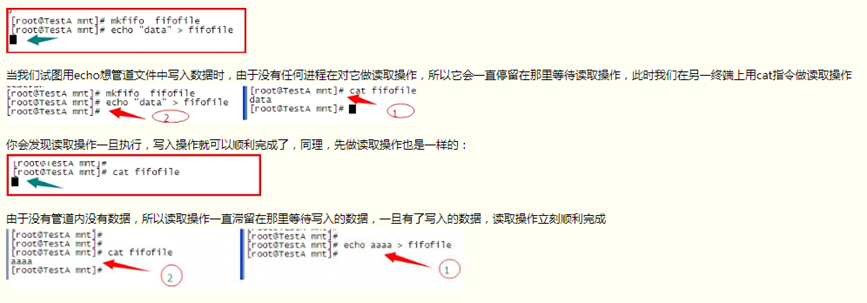
以上实验,看以看到,仅仅一个管道文件似乎很难控制后台线程数
文件操作符:
系统运行起始,就相应设备自动绑定到了 三个文件操作符 分别为 0 1 2 对应 stdin ,stdout, stderr 。在 /proc/self/fd 中 可以看到 这三个对应文件
[root@GipagodHost ~]# cd /proc/self/fd [root@GipagodHost fd]# ls 0 1 2 255 [root@GipagodHost fd]# echo "test information" >0 test information [root@GipagodHost fd]# echo "test information" >1 test information [root@GipagodHost fd]# echo "test information" >2 test information
输出到这三个文件的内容都会显示出来。只是因为显示器作为最常用的输出设备而被绑定。我们可以exec 指令自行定义、绑定文件操作符,文件操作符一般从3-(n-1)都可以随便使用,此处的n 为 ulimit -n 的定义值的。
[root@GipagodHost fd]# ulimit -n 65535 [root@GipagodHost fd]# exec 5000<>/mnt/5000.file [root@GipagodHost fd]# exec 65535<>/mnt/5000.file -bash: 65535: Bad file descriptor [root@GipagodHost fd]# exec 65534<>/mnt/5000.file [root@GipagodHost fd]# ls /proc/self/fd 0 1 2 3 4 5000 65534 [root@GipagodHost fd]# ls /mnt/ 5000.file x.sh
以下是管道结合文件操作符来实现进程数控制的代码:
#/bin/bash trap "exec 1000>&-; exec 1000<&-; exit 1" 2 # 修改CTRL+C的操作,先释放后退出 exec 1000>&- 和exec 1000<&- 是释放文件操作 mkfifo test.fifo # 创建 exec 1000<>test.fifo # 关联 rm -fr test.fifo # 文件操作符和管道文件绑定后,管道文件就用不到了,对操作符的操作等同于对管道文件操作, 不直接使用管道文件的原因是,管道文件读写操作必须同时进行
# 而绑定操作符后即解决了这个问题 for((i=1; i<=5; i++)) do echo >&1000 # 我们向文件操作符(管道)中写入5个空行,之所以是空行不是字符是因为管道内的内容是以行为基本单位的 done # 这个数字5 也就是我们要控制的进程数量 v_start=`date "+%s"` for((i=1; i<=20; i++)) do read -u1000 # read -u操作符 的作用是读取管道内容的一行, 它和下面代码块中的 echo >&1000是控制进程数量的关键操作 { echo "success" #此代码块位置是防止具体的应用程序代码 sleep 2 echo >&1000 # 以上程序代码执行完毕后,表示这个后台进程该结束了,因为执行前管道内已经被读取了一行,因此执行完毕后,需要补充,正是这个操作保证了管道内始终是5个空行 }& done wait v_end=`date "+%s"` echo "Time:$((v_end-v_start))" exec 1000>&- # 释放 exec 1000<&-

当我们试图用 read 读取管道中的一个字符时,结果是不成功的,而刚才我们已经证实使用cat是可以读取的。
第17-24行: 这里假定我们有100个任务,我们要实现的时 ,保证后台只有10个进程在同步运行 。read -u1000 的作用是:读取一次管道中的一行,在这儿就是读取一个空行。减少操作附中的一个空行之后,执行一次任务(当然是放到后台执行),需要注意的是,这个任务在后台执行结束以后会向文件操作符中写入一个空行,这就是重点所在,如果我们不在某种情况某种时刻向操作符中写入空行,那么结果就是:在后台放入10个任务之后,由于操作符中没有可读取的空行,导致 read -u1000 这儿 始终停顿。
执行结果:
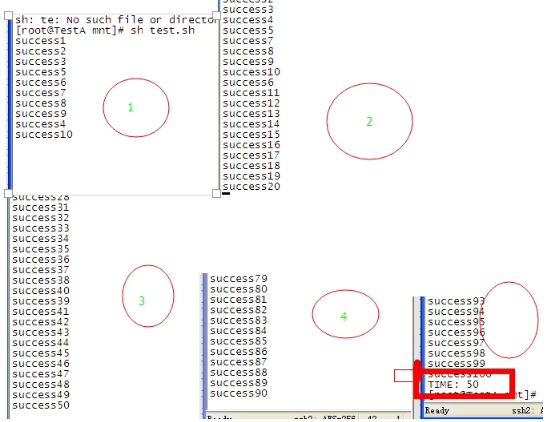
每次的停顿中都能看到 只有10个进程在运行,一共耗时50s 一共100个任务,每次10个 ,每个5s 正好50s
上边的结果图之所以这么有规律,这是因为我们所执行的100个任务耗时都是相同的,比如,系统将第一批10个任务放入后台的过程所消耗的时间 几乎可以忽略不计,也就是说这10个任务几乎可以任务是同时运行,当然也就可以认为是同时结束了,而按照刚才的分析,一个任务结束时就会向文件描述符写入空行,既然是同时结束的,那么肯定是同时写入的空行,所以下一批任务又几乎同时运行,如此循环下去的。实际应用时,肯定不是这个样子的,比如,第一个放到后台执行的任务,是最耗时间的,那他肯定就会是最后一个执行完毕。所以,实际上来说,只要有一个任务完成,那么下一个任务就可以被放到后台并发执行了。