Python-入门-列表
文章目录
列表是什么

- 列表是元素的集合,存储在一个变量中。
- 列表中存储的元素类型没有限制,根据需要动态分配和回收内存
- 列表中的每个元素都会分配一个数字用来表示它的位置(索引),第一个索引是 0,第二个索引是 1,依此类推。
- 列表的数据项不需要具有相同的类型
- 列表可以存储重复数据
列表的CRUD
创建列表
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
与字符串的索引一样,列表索引从 0 开始。列表可以进行截取、组合等。
列表中元素的类型的多样性
a_list=['lemon', 100, ['a', 'b', 'c', 'd'], True]#同一个list的类型可以是字符串,整型,布尔型(true和false),以及嵌套的lis
访问列表中的值
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7]
print("list1[0]: ", list1[0]) # list1[0]: physics
# 嵌套列表
list1 = ['physics', 'chemistry', 1997, 2000,[1,2,3,4,5]]
print("list1[0]: ", list1[4][0]) # list1[0]: 1
print(a[1:3]) #按下标0开始,不包括最右边的3
print(a[1:]) #1以及之后的全部
print(a[:3]) #3之前的但不包括3
print(a[:]) #所有
print(a[::2])#[start:end:step]start和end为空的时候,默认是全选,step为空时默认是1,这个表示的是从索引为0开始,以步长为2来选择元素
print(a[1:3:2])#以索引为1开始,索引3结束,步长为2来选择元素
print(a[::-1])#当step为-1时,将列表进行了逆序排序
print(a[::-2])#将列表进行了逆序排序,步长为2来选择元素
更新列表
修改列表中的元素需要使用索引表示将指定索引位置的元素进行重新赋值。
list1 = ['physics', 'chemistry', 1997, 2000]
list1[0]= 'maths'
print("list1[0]: ", list1[0]) # list1[0]: maths
删除元素
移除列表中的元素,可以通过 del 语句,通过索引号指定要删除的元素对象。
list1 = ['physics', 'chemistry', 1997, 2000]
del list1[0]
print("list1[0]: ", list1[0]) # list1[0]: chemistry
拼接列表
print('列表相加:', [1, 2, 3] + [4, 5, 6])# 列表相加: [1, 2, 3, 4, 5, 6]
列表相乘
print('列表相乘:', ['a', 'b']*3) # 列表相乘: ['a', 'b', 'a', 'b', 'a', 'b']
判断
print('判断列表元素是否存在于列表中:', 'a' in ['a', 'b']) # True
print('判断列表元素是否存在于列表中:', 'a' not in['a', 'b']) # Falue
遍历列表
python 迭代列表中元素,主要有三种方式,具体如下:
第一种方法(直接)
list1 = ['physics', 'chemistry', 1997, 2000]
for item in list1:
print(item)
或者

names = ['james', 'michael', 'emma', 'emily']
index = 0 #通过while循环来列出所有元素
while index < len(names):
print(names[index])
index += 1
第二种方法range
借助 range 和 len 内置函数,通过元素索引遍历列表元素;
list1 = ['physics', 'chemistry', 1997, 2000]
for i in range(len(list1)):
print(i, list1[i])
第三种方法enumerate
通过内置枚举函数 enumerate 直接获取遍历的索引和元素;
list1 = ['physics', 'chemistry', 1997, 2000]
for i, item in enumerate(list1):
print(i, item)
列表常用方法
获取列表长度
len() 方法返回列表元素个数。
print(len([1, 2, 3])) # 3
列表后面添加元素
append() 方法用于在列表末尾添加新的对象。
food=['egg', 'fish', 'cake', 'tomato']
food.append('ice') #在list的末尾添加元素
print(food)
指定位置添加元素
insert() 函数用于将指定对象插入列表。
food=['egg', 'fish', 'cake', 'tomato']
food.insert(1, 'meat') #在1这个位置添加元素
print(food)
删除元素
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
food=['egg', 'fish', 'cake', 'tomato']
food.pop() #删除list末尾的元素
print(food)
food.pop(2) #删除索引2的元素
print(food)
定义 remove() 方法具有指定值的首个元素,如果有重复,删除的是第一次出现的元素,如果元素不存在会报错
list2 = [1, 2, 4, 5, 7, 4]
list2.remove(4)#从列表中找出第一个数值为4的值然后删除,不管第二个
print('remove:', list2)
返回的是某个元素在列表里面的个数
count()方法返回元素出现次数
fruits = ['apple', 'banana', 'cherry']
number = fruits.count("cherry")
print(number)
合并列表
定义 extend()方法将列表元素(或任何可迭代的元素)添加到当前列表的末尾
list1 = [1, 3, 3, 4, 5]
list2 = [6, 5, 8, 9]
list1.extend(list2) #在列表1后面添加列表2
print(list1)
返回的是元素在列表中的第一个位置
定义 index()方法返回该元素最小索引值(找不到元素会报错)
list2 = [1, 2, 4, 5, 7, 4]
print('index:', list2.index(4)) # 从列表中找出第一个数值为4的索引位置,不管第二个
排序
从小到大排序,类型不能混 ,使用的是ASCII值进行排序
list2 = [1, 2, 4, 5, 7, 4]
list2.sort()#对原列表进行排序
print('sort;', list2)
将列表进行翻转
定义reverse() 方法反转元素的排序顺序
fruits = ['apple', 'banana', 'cherry']
fruits.reverse()
print(fruits)
清除列表
定义 clear()方法清空列表所有元素
list2 = [1, 2, 4, 5, 7, 4]
list2.clear()
print(list2)
浅拷贝列表
定义 copy()方法返回指定列表的副本 ,如果某个元素是引用类型那么复制的就是这个元素的地址
fruits = ['apple', 'banana', 'cherry', 'orange']
c = fruits.copy()
print(c
深拷贝列表
使用用deepcopy()方法,才是真正的复制了一个全新的列表,包含原列表内部的引用类型
import copy
old = [1,[1,2,3],3]
new = copy.deepcopy(old)
注意: 使用深浅拷贝需要导入copy模块,因为深拷贝要拷贝的元素跟多,所以速度会远不如浅拷贝,在编程的过程中要注意避免造成多余的系统负担;
进阶
二维数组
二维数组是数组内的数组。它是一个数组数组。在这种类型的数组中,数据元素的位置由两个索引而不是一个索引来引用。所以它代表了一个包含行和列的数据表格。
如果我说我有5个学生的5个科目的数据,现在你可以有5个不同的列表来存储这些数据,但这将是低效的,坦率地说,不是一个使用列表的好结构。 而且,即使是小数据也是可能的,但是对于10万名学生,我们该怎么办呢?显然,作为一个优秀的程序员,这种结构是不可接受的。
现在,二维阵列应运而生。如果我们可以将这五个学生数组存储在一个数组中呢?嗯,我们可以的!这就是数组数组的含义。
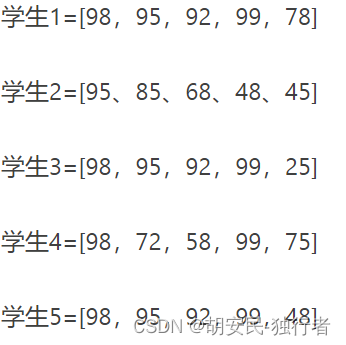
我们将把这些数组存储在数组本身中。因为如果你绘制这些元素考虑它们的几何点,那么你将需要两个平面(即x和y),因此称为二维数组或二维数组。
student_data = [
[98, 95, 92, 99, 78],
[95, 85, 68, 48, 45],
[98, 95, 92, 99, 25],
[98, 72, 58, 99, 75],
[98, 95, 92, 99, 48] ]
为了访问元素,我们将使用两个索引,第一个索引用于定义存储元素的列表的位置,第二个索引用于定义元素在该列表中的位置。
student_data[2][3]
如果我们想要将新学生的结果存储在这些2维数组中,那么我们可以使用内置函数append()。
student6 = [ 56, 89, 48, 96, 45]
student_data.append(student6)
如果我们只想增加一个学生的成绩那么我们可以通过下标方式找到学生列表然后在添加
student_data[1].append( 98 )
现在假设学生3给科目5复试,得了98分,现在这个增加的分数必须更新。那么,我们如何才能做到这一点呢?我们可以简单地使用赋值运算符来实现这一点。
student_data[ 2 ][ 4 ] = 98
如果您想要更新完整的学生成绩表怎么办?那么编辑每个条目就是一项繁重的任务。因此,尽管逐个编辑元素,我们仍然可以更改整个信息数组,但是也是有可以更简单的方式来直接更新指定学生的全部成绩的
student1 = [45, 78, 96, 78, 85]
student_data[ 0 ] = student1
假设学生4离开了学校,并且他的记录必须被删除,那么我们将不得不删除他的整个条目,或者我们可以说数组。因此,要删除列表对象元素,我们使用POP函数。(del 也是可以的)
student_data.pop( 3 )
学生 1 有一门成绩因为作弊而作废了,那么我们需要给他删除,我们可以这样做
student_data[ 1 ].pop(1)
矩阵
矩阵是二维数组的特殊情况,其中每个数据元素具有严格相同的大小。所以每个矩阵也是一个二维数组,但反之亦然。矩阵是许多数学和科学计算中非常重要的数据结构。正如我们在前面中已经讨论过的两个双维数组结构,我们将在本章中专注于矩阵特有的数据结构操作, 我们也使用numpy包进行矩阵数据操作。
考虑在早上,中午,晚上和深夜测量记录温度1周的情况。它可以使用数组以及numpy中可用的重塑方法呈现为7X5矩阵。
from numpy import *
a = array([['Mon',18,20,22,17],['Tue',11,18,21,18],
['Wed',15,21,20,19],['Thu',11,20,22,21],
['Fri',18,17,23,22],['Sat',12,22,20,18],
['Sun',13,15,19,16]])
m = reshape(a,(7,5))
print(m)
上述数据可以表示为如下的二维数组。
[['Mon' '18' '20' '22' '17']
['Tue' '11' '18' '21' '18']
['Wed' '15' '21' '20' '19']
['Thu' '11' '20' '22' '21']
['Fri' '18' '17' '23' '22']
['Sat' '12' '22' '20' '18']
['Sun' '13' '15' '19' '16']]
矩阵中的数据元素可以通过使用索引来访问。访问方法与在二维数组中访问数据的方式相同。
print(m[2]) # ['Wed' '15' '21' '20' '19']
print(m[4][3]) # 23
添加数据-> 添加一行
m_r = append(m,[['Avg',12,15,13,11]],0)
当上面的代码被执行时,它会产生以下结果
[['Mon' '18' '20' '22' '17']
['Tue' '11' '18' '21' '18']
['Wed' '15' '21' '20' '19']
['Thu' '11' '20' '22' '21']
['Fri' '18' '17' '23' '22']
['Sat' '12' '22' '20' '18']
['Sun' '13' '15' '19' '16']
['Avg' '12' '15' '13' '11']]
我们可以使用insert()方法将列添加到矩阵。这里我们不得不提及我们想要添加列的索引以及包含添加的列的新值的数组。在下面的例子中,我们在开头的第五个位置添加一个新列。
m_c = insert(m,[5],[[1],[2],[3],[4],[5],[6],[7]],1)
当上面的代码被执行时,它会产生以下结果
[['Mon' '18' '20' '22' '17' '1']
['Tue' '11' '18' '21' '18' '2']
['Wed' '15' '21' '20' '19' '3']
['Thu' '11' '20' '22' '21' '4']
['Fri' '18' '17' '23' '22' '5']
['Sat' '12' '22' '20' '18' '6']
['Sun' '13' '15' '19' '16' '7']]
我们可以使用delete()方法从矩阵中删除一行。我们必须指定行的索引以及行的值为0,列的值为1的轴值。
m = delete(m,[2],0)
当上面的代码被执行时,它会产生以下结果
[['Mon' '18' '20' '22' '17']
['Tue' '11' '18' '21' '18']
['Thu' '11' '20' '22' '21']
['Fri' '18' '17' '23' '22']
['Sat' '12' '22' '20' '18']
['Sun' '13' '15' '19' '16']]
我们可以使用delete()方法从矩阵中删除一列。我们必须指定列的索引,参数2为1就行
m = delete(m,s_[2],1)
当上面的代码被执行时,它会产生以下结果
[['Mon' '18' '22' '17']
['Tue' '11' '21' '18']
['Wed' '15' '20' '19']
['Thu' '11' '22' '21']
['Fri' '18' '23' '22']
['Sat' '12' '20' '18']
['Sun' '13' '19' '16']]
要更新矩阵行中的值,我们只需在行的索引处重新分配值。
m[3] = ['Thu',0,0,0,0]
当上面的代码被执行时,它会产生以下结果
[['Mon' '18' '20' '22' '17']
['Tue' '11' '18' '21' '18']
['Wed' '15' '21' '20' '19']
['Thu' '0' '0' '0' '0']
['Fri' '18' '17' '23' '22']
['Sat' '12' '22' '20' '18']
['Sun' '13' '15' '19' '16']]
