论文地址:https://vlg.cs.dartmouth.edu/c3d/c3d_video.pdf
Abstract
作者的研究结果有三个方面: 1)与二维相比,三维卷积网更适合时空特征学习;2)所有层具有3×3×3的小卷积核的同构架构是3D卷积网的最佳架构之一;3)学习到的特征,即C3D(卷积3D),使用一个简单的线性分类器,在4个不同的基准上优于最先进的方法,并在其他2个基准上与当前的最佳方法相比较。
1. Introduction
一个有效的视频理解算法有四个属性: (i)它需要是通用的,这样它就可以很好地表示不同类型的视频,同时具有区别性。例如,互联网视频可以是风景、自然场景、体育、电视节目、电影、宠物、食物等;(ii)网络结构提取的特征需要紧凑,也就是说具有很好 的表达能力(类似于降维):由于我们正在处理数百万个视频,一个紧凑的视频处理算法有助于处理、存储和检索更可伸缩的任务;(iii)它需要高效地计算,因为在现实世界系统中每分钟都要处理数以千计的视频;(iv)它必须简单实现。与其使用复杂的特征编码方法和分类器,一个好的视频特征提取结构应该与一个简单的模型(例如线性分类器)工作。
基于2D卷积的图像特征提取不能够提取视频中的时空信息,因此,作者提出了3D卷积,C3D是通用的、紧凑的、简单的和高效的。综上所述,作者在本文中的贡献如下:
- 实验表明,三维卷积深度网络是一种良好的特征学习机器,可以同时建模外观和运动。
- 根据经验发现,3×3×3卷积内核在有限的被探索的架构集中工作得最好。
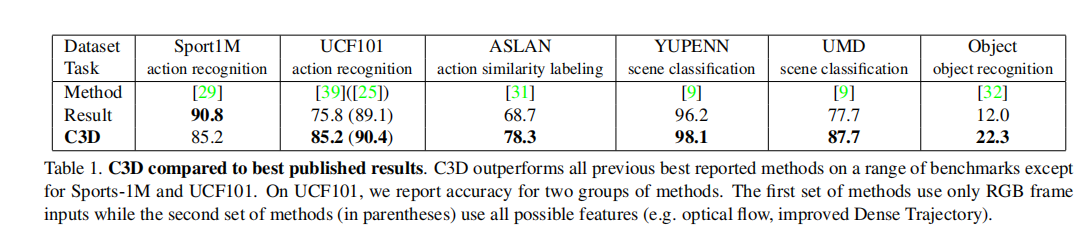
- 在4个不同的任务和6个不同的基准测试上,其性能优于或接近目前的最佳方法(见表1)。它们也很紧凑,计算效率也很高。
3. Learning Features with 3D ConvNets
3.1. 3D convolution and pooling
作者认为三维卷积网络非常适合于时空特征学习。与二维卷积相比,由于三维卷积和三维池化操作,它能够更好地建模时间信息。在三维卷积网络中,卷积和池化操作是在时空上执行的,而在二维卷积网络中,它们只能在空间上执行。图1说明了差异,在一个图像上应用二维卷积将输出一个图像,在多个图像上应用二维卷积(将它们作为不同的通道[36])也会得到一个图像。因此,二维卷积网络在每次卷积操作后都会丢失输入信号的时间信息。只有三维卷积保留了输入信号的时间信息,从而产生了一个输出体积。 只有三维卷积保留了输入信号的时间信息,从而产生了一个输出体积。同样的现象也适用于二维和三维池化。

根据2D ConvNet [37]的研究结果,3×3卷积核的小接受域产生了最好的结果。因此,在架构搜索研究中,作者将空间接受野固定为3×3,并且只改变三维卷积核的时间深度。
Notations: 参考大小为c × l × h × w的视频序列,其中c是通道数,l是帧数的长度,h和w分别是帧的高度和宽度。我们也用d×k×k来表示三维卷积和池化核大小,其中d是核时间深度,k是核空间大小。
Common network settings: 网络设置以视频序列作为输入,并预测属于101个不同动作的类标签。所有的视频帧都被调整为128×171。这大约是UCF101帧分辨率的一半。视频被分割成不重叠的16帧片段,然后被用作网络的输入。输入尺寸为3×16×128×171。在训练期间,使用3×16×112×112的随机裁剪进行抖动。网络有5个卷积层和5个池化层(每个卷积层紧是一个池化层),2个全连接层和一个softmax损失层来预测动作标签。从1层到5层的5个卷积层的滤波器数分别为64、128、256、256、256。所有卷积核的大小都为d,其中d是核的时间深度。所有这些卷积层都应用了适当的填充(空间和时间)和步幅1,因此从这些卷积层的输入到输出的大小没有变化。所有的池化层都是最大池化,内核大小为2×2×2(第一层除外),步幅为1,这意味着输出信号的大小比输入信号减少了8倍。第一个池化层的内核大小为1×2×2,目的是不过早合并时间信号,并满足16帧的序列长度(例如,在完全崩溃时间信号之前,可以暂时合并因子2最多4倍)。这两个完全连接的层有2048个输出。使用30个视频序列的小批量从零开始训练网络,初始学习率为0.003。学习速率在每4个epoch后除以10。训练在16epoch后停止。

Varying network architectures: 只改变卷积层的内核时间深度,同时保持所有其他公共设置固定。使用两种类型的架构进行实验: 1)同质时间深度:所有卷积层都具有相同的核时间深度;2)不同的时间深度:核时间深度在层间发生变化。对于齐次设置,作者实验了4个核时间深度d分别为1、3、5和7的网络。我们将这些网络命名为depth-d,其中d是它们的均匀时间深度。请注意,depth-1网相当于在单独的帧上应用二维卷积。对于不同的时间深度设置,作者实验了两个时间深度分别从第一层到第5层增加3-3-5-5-7和减少7-5-5-3-3。所有这些网络在最后一个池化层都有相同大小的输出信号,因此对于全连接的层,它们有相同数量的参数。由于核时间深度的不同,它们的参数数量仅在卷积层上有所不同。与完全连接层中的数百万个参数相比,这些差异非常小。例如,上述任何两个时间深度差为2的网,彼此之间只有更少或更多的17K个参数。参数数量的最大差异是depth-1网和depth-7网,其中depth-7网多有51K个参数,小于每个网络1750万参数总数的0.3%。这表明网络的学习能力是可比性的,参数数量的差异不会影响架构搜索的结果。
3.2. Exploring kernel temporal depth
3×3×3是3D二维网络(根据我们的实验子集)的最佳核选择,3D二维在视频分类方面始终优于2D二维。

3.3. Spatiotemporal feature learning
Network architecture:卷积核为3×3×3的齐次设置是三维卷积网络的最佳选择。这一发现也与2D ConvNets [37]中的类似发现相一致。有了一个大规模的数据集,可以训练一个3×3×3内核尽可能受机器内存限制和计算能力。利用当前的GPU内存,作者设计的3D卷积网有8个卷积层,5个池化层,然后是两个完全连接的层,和一个softmax输出层。网络架构如图3所示。为简单起见,我们从现在开始称这个网络为C3D。所有的3D卷积滤波器都是3×3×3,步幅为1×1×1。所有3D池化层均为2×2×2,步幅为2×2×2,除了池1的内核大小为1×2×2,步幅为1×2×2,旨在在早期阶段保留时间信息的2×2×2。每个全连接的层有4096个输出单元。
 Dataset. Sports-1M
Dataset. Sports-1M
Training: 训练是在Sports-1M进行的。由于Sports-1M有许多长视频,作者从每个训练视频中随机抽取5个2秒长的片段。片段的大小被调整为有一个帧大小为128×171。在训练中,将输入片段随机裁剪到16×112×112序列中进行空间和时间抖动。也以50%的概率水平翻转它们。训练由SGD完成,小批量大小为30个示例。初始学习率为0.003,每150K次迭代除以2次。优化在1.9M次迭代(约13个时代)时停止。除了从头开始训练的C3D网外,还尝试用在I380K上预先训练的模型对C3D网进行微调。
Sports-1M classifification results:
 What does C3D learn? 作者使用了反卷积进行可视化。可以观察到,C3D从关注前几帧中的外观开始,并跟踪后续帧中的突出运动。图4可视化了两个C3D conv5b特征图的反卷积,其中最高的激活度投影到图像空间。在第一个例子中,该功能关注整个人,然后跟踪撑杆跳高性能在其他框架上的运动。类似地,在第二个例子中,它首先关注眼睛,然后跟踪化妆时眼睛周围发生的运动。因此,C3D不同于标准的2D卷积,它有选择性地关注运动和外观。
What does C3D learn? 作者使用了反卷积进行可视化。可以观察到,C3D从关注前几帧中的外观开始,并跟踪后续帧中的突出运动。图4可视化了两个C3D conv5b特征图的反卷积,其中最高的激活度投影到图像空间。在第一个例子中,该功能关注整个人,然后跟踪撑杆跳高性能在其他框架上的运动。类似地,在第二个例子中,它首先关注眼睛,然后跟踪化妆时眼睛周围发生的运动。因此,C3D不同于标准的2D卷积,它有选择性地关注运动和外观。
4. Action recognition
Dataset: UCF101
Classifification model: 提取C3D特征并将其输入到一个多类线性SVM中用于训练模型。使用3种不同的网络实验C3D特征提取:在I380K训练的C3D,在Sports-1M训练的C3D,在I380K训练和在Sports-1M训练的C3D进行微调。在多网设置中,作者将这些网络结构l2标准化的C3D特征提取连接起来。
Baselines:
Results:
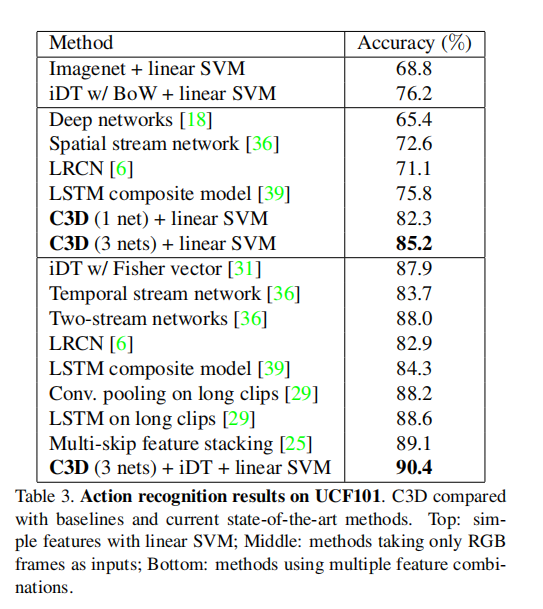
C3D is compact: 为了评估C3D特征的紧凑性,作者使用PCA将特征投影到更低的维度,并使用线性SVM报告UCF101 [38]上投影特征的分类精度。对iDT [44]和图像[7]应用相同的过程,并比较图5中的结果。
作者通过可视化学习到的C3D特征来定性地评估我们学习到的三维特征,以验证它是否是一个很好的视频通用特征。我们从UCF101中随机选择100K片段,然后从Imagenet和C3D中提取fc6特征。然后使用t-SNE [43]将这些特征投影到二维空间中。

5. Action Similarity Labeling
Dataset: ASLAN
Features: 作者将视频分成16帧的片段,重叠为8帧。并提取C3D特征:每个剪辑的prob,fc7,fc6,池5。视频的特征是通过平均每种类型的特征的剪辑特征,然后进行L2归一化
Classifification model: 给定一对视频,作者计算了在[21]中提供的12个不同的距离。利用4种类型的特征,得到了每个视频对的48维(12×4 = 48)特征向量。由于这48个距离彼此之间不具有可比性,将它们独立地归一化,使每个维度的均值和单位方差为零。最后,训练一个线性SVM对这些48个模糊的特征向量将视频对分为相同或不同。
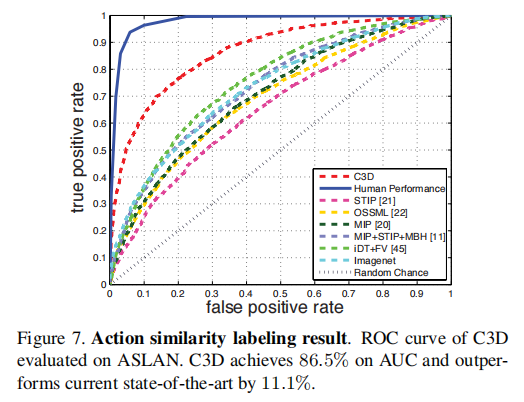
Results:

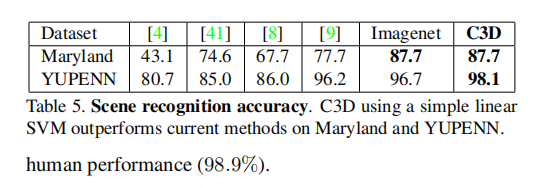
6. Scene and Object Recognition
Datasets: YUPENN
Classifification model: 对于这两个数据集,使用相同的特征提取和线性SVM设置来进行分类,并遵循这些数据集的作者所描述的相同的留一评估协议。对于对象数据集,标准的评估是基于帧的。然而,C3D需要一个长度为16帧的视频剪辑来提取该特征。在所有视频上滑动一个16帧的窗口来提取C3D特征。并为每个剪辑选择地面真实标签作为剪辑中最频繁出现的标签。如果一个剪辑中最常见的标签出现在8帧以下,认为它是没有对象的负剪辑,并在训练和测试中丢弃它。使用线性SVM训练和测试C3D特征,并报告目标识别精度。
Results:
7. Runtime Analysis
