招商银行2022FinTech数据赛道总结
比赛链接:FinTech精英训练营官方网站。
第一次参加这种比赛,真的学到了不少东西,感谢其他大佬在交流群里的无私分享,小白又了解到了很多可以学习的东西。这次比赛排名还是很拉的,A榜只有0.952,B榜只有0.723,综合排名应该到了快400名吧。但不管怎么说,既然参加了这次比赛,还学习了很多东西,还是值得好好整理一下的。
文章目录
1. 比赛简介
数据是结构化的表格数据,一共49个属性(不含ID和标签),但没有具体的属性介绍,标签是二分类。
竞赛时间:4月29日9:00-5月12日17:00;
竞赛流程:4月29日9:00-5月9日24:00,赛题开放A榜数据(test_A榜),预测结果数据每天限提交3次;5月10日00:00-5月12日17:00,赛题开放B榜数据(test_B榜),预测结果数据每天限提交3次。重复提交或提交格式错误均扣除有效提交次数,请谨慎提交答案,结果提交后请务必点击“运行”按钮,方可查看当前个人排名。
排行榜依据“最终得分”计算排名,“最终得分”计算公式为:A榜最高分 * 0.3 + B榜最高分 * 0.7。“最终得分”越大,成绩排名越前。
注:AUC这个指标和准确率不一样,它受到样本不均衡的影响很小,对正负比例不敏感,因此。只要是AUC做评价指标的,基本都不需要考虑正负样本比例的问题。
2. 可提高的地方
每一列的含义可以参考往年的资料进行分析→招商银行2020FinTech精英训练营数据赛道参赛回顾。
(1)探索性分析
之前都是使用pandas-profiling,这次数据出问题就跳过了EDA的步骤,但赛后换了一个eda的包之后就能用了。所以也先mark在这:
- 通用:pandas-profiling、SweetViz;
- Notebook上:LUX、AutoViz。
EDA可以分析的内容:
- 样本数量、数据字段的异常值、缺失值;
- 数据(含标签)字段的类型及其分布、字段和标签的分布关系;
- 字段之间的相关性分析;
- 有时间特征的可以按不同时间窗口划分观察;
- 训练集和测试集的分布差异。
(2)数据预处理
数据类型转换
数值型变量:转为float
有序型分类变量:使用LabelEncoder()编码;
无序型分类变量:使用独热编码。
缺失值处理
将“?”字段统一替换为Nan缺失值;
可以考虑将所有数值特征统一减2,“2”应该是出题方为了脱敏进行的变换,个人之前没有减是觉得“2”已经代表了一种属性,没必要调整,但未来遇到这样的情况获取可以考虑进行类似的变换。
填充方法:
-
删除:当缺失值的个数只占整体很小一部分的时候,可直接删除缺失值(行)
-
填补:
-
前填充/后填充:method=‘ffill’—前填充;method=‘bfill’–后填充;
-
均值、中位数、众数填充:fillna(df[‘XX’].mean()) # .mean()或.median()或.mode()

-
插值法:计算的是缺失值前一个值和后一个值的平均数:df[‘XX’] = df[‘XX’].interpolate();
-
-
拟合:
- 回归填补:利用线性回归对缺失值进行填补;
- 随机森林填充:对于一个有n个特征的数据来说,其中特征T有缺失,我们就将特征T当作标签,其他n-1个特征和原来的标签组成新的特征矩阵。对于特征T来说,他没有缺失的部分就是我们的y_train,这部分对应的标签就是X_train,缺失部分就是我们需要预测的部分,也即是y_predict,这部分对应的标签就是X_test,对于数据中有多个特征缺失的情况,需要从缺失值最少的特征开始填补(填补缺失值越少的特征需要的准确信息越少)。当填补一个特征时,将其他特征的缺失值用0代替,依次填补直到所有特征填补完全。
此外,还可以考虑用随机森林进行填充。
异常值处理
采用3σ原则或者孤立森林方法进行异常值检测。
处理:可以考虑将过大、过小的值都限定到一个上限和下限。
数据规范化
可选:最大-最小归一化、标准化、中心化,其中min-max不改变数据分布,标准化改变数据分布(具体看所选取的算法要求);
重采样
过采样/欠采样:目的是为了平衡类别。
目前没有实践,有看到采用imblearn库来做的。eg:from imblearn.over_sampling import RandomOverSampler
(3)特征工程
特征过滤
基础:去除共线性:将相互之间热力值高(相关性高于0.9)的特征列去掉,仅保留一列(根据结果决定);
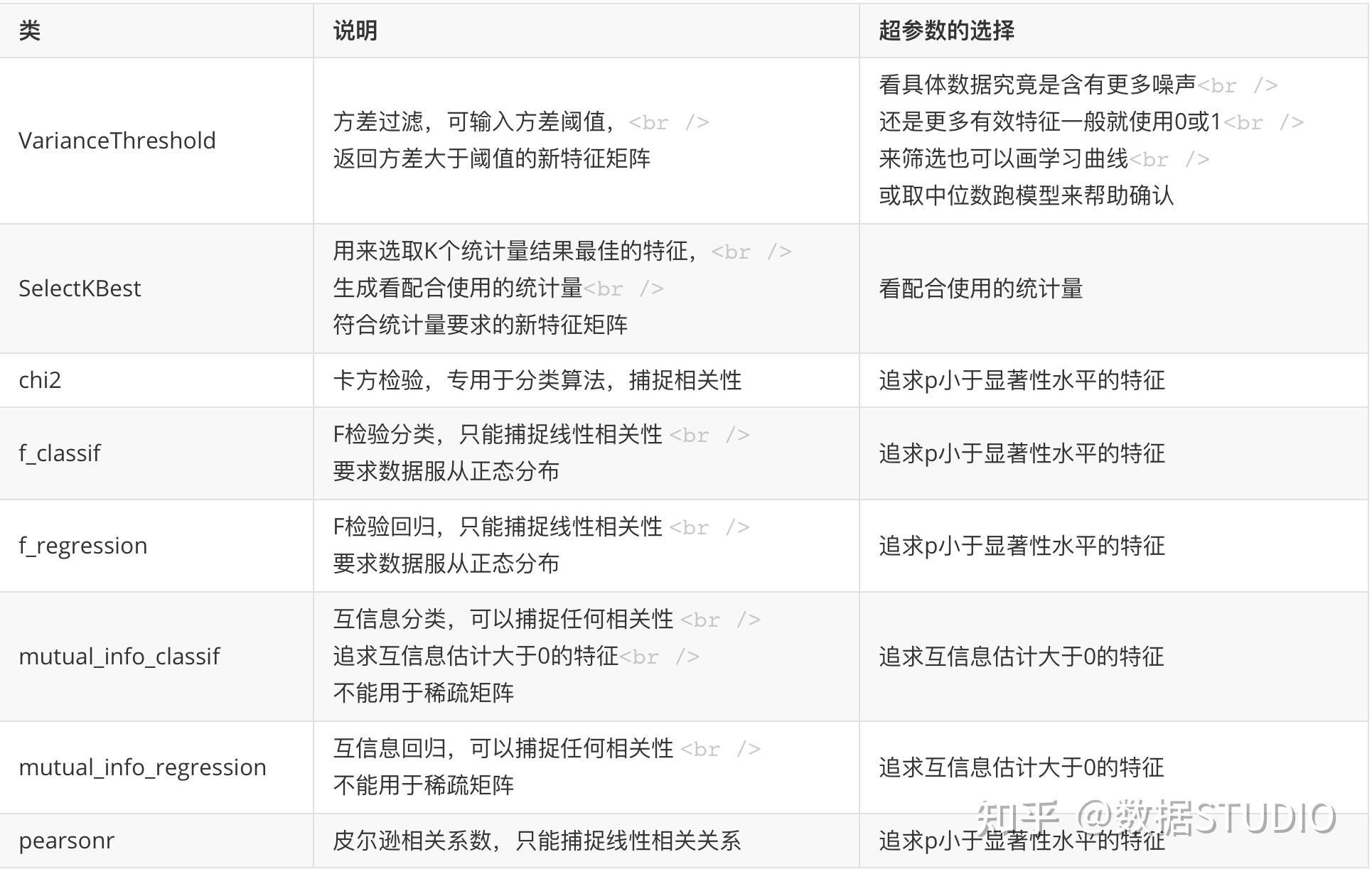
过滤法:方差过滤法+卡方检验法/F检验法/互信息法;
特征过滤主要是对冗余特征进行处理,常见处理方法有方差法、卡方检验法、F检验法、装代法、包裹法等,其中常用的组合为方差过滤法和F检验法,卡尔检验法常用来处理线性关系,F检验法即可以用来线性关系,还可以用来处理非线性关系。
找“毒特”(删除训练集与测试集分布不一致的特征):
- 通过对抗验证的思路找到auc指标远大于0.5的特征进行删除;
- 删除其他和“毒特”相关性较高的特征。
特征交叉
对于任何两列相关系数在指定范围(0.3~0.8)内的特征做交叉衍生;
采用暴力全集特征交叉(二阶、加减乘除)、group组合提取偏离值特征以及数值变量与类别变量交叉(三阶);
类别变量组合特征,连续变量排序特征,trd和beh中提取tfidf和word2vec特征,交易聚集度特征等;
cate类交叉,num类分桶(等频、等宽、卡方)
使用featuretools这个包把三个表连接起来,基于“ 深度特征合成 ”的方法来自动生成特征。生成完之后大概500多维。参考资料:https://zhuanlan.zhihu.com/p/43630912、https://www.cnblogs.com/wkang/p/103。
手工特征。
特征选择
使用LGB+shap或者+rfe的方法进行筛选,具体可见:特征选择方法总结。