GoRedis项目
文章目录
项目简介
使用Go语言实现的简易版单机Redis服务器,可以同时响应多个客户端的查询或者存储请求。目前实现了使用RESP协议与客户端进行通信、然后支持AOF持久化和AOF重写、支持事务,事务失败了可以进行回滚、支持发布订阅功能。
项目结构图
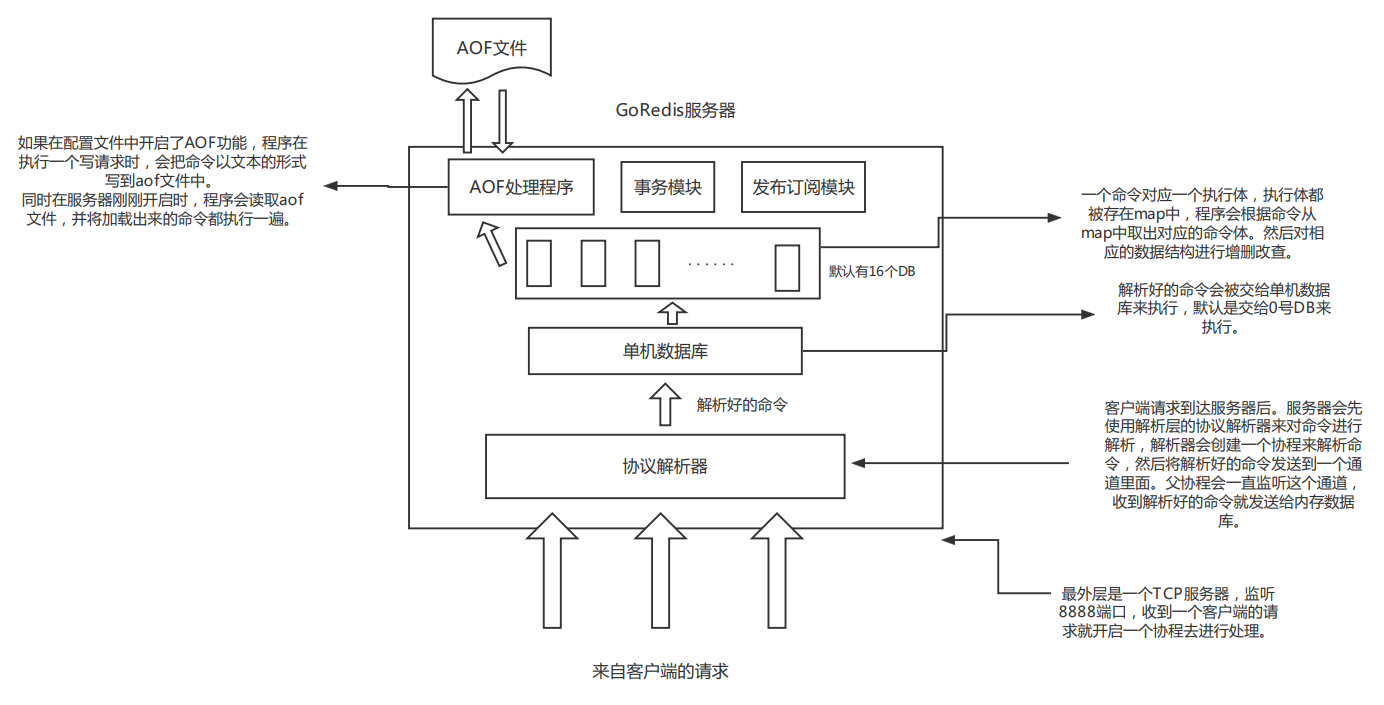
一个客户端请求的流程
简易版:
- 服务器程序监听63791端口,接受到客户端请求之后,就创建一个协程去处理,在这个协程里面,会调用协议解析层的处理程序。
- 首先会把客户端请求包装成一个client结构体,加上当前数据库编号、当前是否处于事务状态的标记、当前客户端订阅了哪些频道等等字段。然后调用一个ParseStream函数对命令进行解析,这个函数内部会创建一个协程专门对命令进行解析,解析好的命令会被包装成payload结构体,然后发送到一个无缓冲通道里面,外层一直监听这个通道,读到payload结构体就开始调用内存数据库层的处理程序来处理。
- 命令到达内存数据库层之后,首先会切换到当前客户端指定的那个DB,默认是0号DB。然后调用DB层的执行程序开始真正执行解析好的命令,每一条命令在内存数据库初始化的时候都被注册到了一个map里面,程序会根据解析好的命令从map里面取出对应的命令执行体来执行。
- 每个DB实际上就是一个sync.Map,map的key是这种数据结构的名称(string类型),value是interface{}类型的指针,所以map的value可以指向任意一种数据结构。取值的时候,只需要把指针取出来,然后进行一次类型断言就可以得到对应数据结构的值。目前支持了五种数据结构:string、list、hash、set和zset。
详细版:
1.TCP服务器:
- 监听配置文件指定的端口,默认是63791。首先创建两个通道:sigChan和closeChan,sigChan用于接收来自系统的关闭信号。服务器开启两个协程,分别用于监听sigChan和closeChan,如果sigChan通道有值,就说明系统发送了关系信号,直接向closeChan通道发送值,服务器收到closeChan的通知,正常关闭服务器。
- 服务器接收到来自客户端的连接之后,开启一条协程去调用解析层的handler.Handle(ctx, conn)函数。
2.协议解析:
- 首先Handler函数会将传进来的连接 – conn参数,包装成一个connection.Connection类型的client,该结构体组合了一个conn net.Conn字段,并加上其它信息:当前数据库编号、当前是否处于事务状态的标记、当前客户端订阅的频道等等。
- 然后调用解析层的ParseStream函数,将client传进去,该函数会开启一个协程对client中的参数进行解析,并返回一个无缓冲通道ch,解析好的命令就包装成PayLoad结构体(含Data和Err两个字段)发送到通道里。
- 同时外层会一直监听ch,如果取到值,首先处理错误,然后调用handler.db.Exec(client, r.Args)开始执行解析好的命令,有错误就调用client.Write回写给客户端。
3.内存数据库:
- 首先数据库引擎层的Exec函数会切换到当前客户端指定的数据库,如果没有指定,默认就是0号数据库。
- 然后调用数据库层的db.Exec(client, args)函数开始真正在内存数据库中执行命令。
- 在db.Exec函数中,首先从命令列表cmdTable(map[string]*command,其中command包含一个命令的执行函数有以及该命令的参数数量)中取出对应的命令,然后执行。
4. 内存数据库的数据结构:
- 内存数据库是sync.Map实现的,该map的key是string类型的命令名称,value是*database.DataEntity类型的值,其中DataEntity是一个结构体,里面包含一个interface{}。
- 然后内存数据库会根据指定的命令,将对应的数据结构存入map中;如果是读命令,首先根据key获取到对应的*database.DataEntity,然后使用类型断言转换成对应的数据结构。
- 一共有5种数据结构:
- string:go语言内置的string类型实现。
- list:双向链表实现。
- hash:sync.Map实现。
- set:sync.Map实现。
- sortedset:sync.Map和跳表共同实现。
核心功能的介绍
AOF持久化和重写
如果配置文件中开启了AOF(appendonly yes),就会执行AOF持久化和AOF重写。
AOF重写
数据库在初始化的时候会调用aof包的NewAofHandler函数,该函数会从配置文件中读取aof持久化文件的路径和文件名,然后就调用handler.LoadAof函数来处理aof文件。该函数首先会调用resp包中的ParseStream函数来解析文件中的指令,接着创建一个伪客户端来执行解析出来的所有命令,执行完之后,aof重写就完成了。
AOF持久化
AOF处理程序在初始化的时候会创建一个handler.aofChan通道,然后开启一个协程监听该通道,如果接收到值,就将通道中的指令落盘。
数据库的每一个DB都有一个addAof字段,该字段是一个函数。数据库在初始化时,会为每一个DB都初始化这个函数。当数据库执行写指令时,该函数会将当前的DB编号以及指令,封装到一个payload结构体中,然后发送到handler.aofChan通道中。
事务
如何监听key是否改变
主要是基于版本号来实现,每个DB中维护了一个versionMap,是map[string]int结构,用来储存每个key的版
本号,每个命令体都内含三个函数:prepare、exec、undo,分别用于提取出被写和被读的key、执行命令以及
命令回滚,每条命令在执行前都会调用prepare函数,提取出被写的key,然后更新版本号。
watch的实现
watch是一个乐观锁,每个客户端结构体都有一个储存被监视key的map,如果执行了watch命令,程序会把
watch后面的key都储存进一个watchMap(map[string]int,储存key的名字和版本号),在执行事务前,程序会检查watchMap中的所有key,如果
某个key的版本发生了变化,会直接结束事务。
事务开始
每个客户端结构体都有一个标记事务状态的变量:multiState,事务开始时,程序会将这个变量标记为true。
事务开始之后
每个客户端结构体都有一个储存事务命令的队列:queue,每条命令在执行前都会先判断当前的事务状态,
即判断multiState是否为true,如果为true,那么不会立即执行这条命令,而是将它储存进事务队列中。
每个客户端结构体都有一个储存事务执行时出现错误的切片:txErrors,在将命令储存进事务队列之前,会先判断这条
命令是否存在或者是否有语法错误,如果有,就先将error放入txErrors切片中,然后再将命令入队。
取消事务
将事务状态multiState设置为false,再将事务队列清空即可。
执行事务
- 首先判断
txErrors切片中是否有值,如果该切片中有值,说明命令有错误,那么会直接放弃事务。 - 接着将每条命令中被写的key都取出来,然后与
watchMap中的版本号做比较,如果版本号发生变化,
会直接结束事务。 - 接着开始正式执行事务队列中的命令,一边执行命令一边取出每条命令对应的回滚函数,存进一个切片
undoCmdLines中,
如果执行命令的过程中出现了语义错误,就停止执行后面的命令,逆向执行undoCmdLines中的回滚函数即可。
回滚
在执行每一条命令之前,程序会先根据这条命令生成对应的回滚命令,然后存到一个切片里面,如果中间某条命令执行失败,就根据切片中的命令进行回滚。
回滚命令的生成与原命令是对应的,比如SET的回滚命令就是DEL,RPUSH的回滚命令就是RPOP,如果某条命令的执行流程较为复杂,那么会执行一个万能回滚命令:rollbackGivenKeys,该函数比较简单粗暴,它会将key直接删除,然后将原来key对应的数据重新set进数据库。
发布/订阅
主要的数据结构
客户端维护的信息:客户端维护了一个map,该map的结构是map[string]true,表示该客户端订阅了哪些频道。(下面简称为clientMap)
服务器维护的信息:服务器的pubsub包中维护了一个subs map,该map是map[string]*List结构,List中存的是
客户端结构体,储存的是频道和频道的订阅者链表。(下面简称为serverMap)。
订阅频道
首先向clientMap中添加这个频道,然后向serverMap中添加相关信息:
1. 如果serverMap中存在该频道,那么取出client链表,再将当前client`添加进去。 2. 如果serverMap中不存在该频道,那么创建client链表,再将当前client``添加进去。
退订频道
首先向clientMap中删除这个频道,然后向serverMap中删除相关信息:
- 如果
serverMap中存在该频道,那么取出client链表,再将当前client删除。 - 如果
serverMap中不存在该频道,直接向客户端返回错误信息。
发送消息
从serverMap中取出对应的频道以及频道的订阅者链表,然后遍历链表,依次向订阅者发送消息。
核心功能的实现
内存数据库是怎么实现的,如何支持多种数据结构
首先内存数据库是一个单机数据库,表示单机数据库的结构体中有一个储存DB指针的切片,单机数据库在被初始化的时候,会为这个DB切片赋值,默认是有16个DB。
DB才是真正储存数据的数据库,DB实际上是一个map,我使用了GO语言自带的sync.Map来实现(保证多客户端能并发安全的读写)。这个map的key是string类型的,map的value是一个指向interface{}类型的指针,这使得DB可以存储多种不同的数据结构。
初次存数据的时候,程序会先创建一个对应数据结构的指针,存好数据之后,再将该数据的名称与该种数据结构的指针当作键值对储存进map中。
读取数据的时候,根据数据的名称,从map中取出对应的interface{}类型指针,然后进行类型断言即可。
内存数据库如何根据客户端来的指令执行对应的命令
对每种数据结构,都有特定的命令关键字,比如对于hash结构,设置一个键值对的命令关键字是mset、获取一个键对应的值的命令关键字是mget。
每个命令关键字,都对应着一个命令执行体command,command是一个结构体,里面有命令执行的函数以及该命令对应的参数数量等字段,在内存数据库被初始化的时候,所有的命令执行体都会被注册到一个命令列表里面(一个map),我们可以根据命令关键字从这个命令列表中取出对应的命令执行体。
客户端的命令来了之后,命令的第一个单词其实就是命令关键字,根据这个关键字取出对应的命令执行体后,再把命令剩下的部分传给命令执行体去执行。
通信协议是怎么实现的
该项目的通信协议采用的是和Redis一样的RESP协议,在RESP协议中,通过首字节的字符来区分不同的数据类型,比如:
- 单行字符串:首字节是
+,后面跟上单行字符串,最后以/r/n结尾,比如ok回复:+OK\r\n。 - 错误:首字节是
-,后面跟上错误的信息,最后以/r/n结尾,比如:-Error message\r\n。 - 数字:首字节是
:,后面更上数字格式的字符串,最后以/r/n结尾,比如::10\r\n。 - 多行字符串:首字节是
$字符,后面跟上字符串的长度,接着是\r\n,然后是实际的字符串,最后依旧是\r\n结尾,比如:$5\r\nhello\r\n。 - 数组:首字节是
*,后面跟上数组元素个数,接下来的格式与多行字符串的格式是一样的,比如:*3\r\n$3\r\nSET\r\n$5\r\nCity1\r\n$8\r\nShanghai\r\n。
项目中实现了一个协议解析器,专门按照RESP协议的格式来解析命令和创建回复,在收到客户端发过来的命令的时候,程序会专门创建一个协程来解析命令,将解析好的命令包装成payload发送到一个无缓冲的通道里面,外层监听这个通道,并将收到的payload交给数据库层的处理程序去执行。
事务是怎么实现的
事务的执行需要有以下四个东西:用于标记事务是否正在执行的状态变量、用于储存事务命令的队列、用于监听事务执行时key是否发生变化的机制、用于保存watch监听的key的数据结构。
每个客户端命令在进入协议解析层的时候,都会被包装成一个client结构体,这个client结构体在原来的基础上,增加了事务相关的字段,有标记事务是否正在进行的布尔变量multiState、存储事务命令的切片queue、储存watch命令监视的key的map:watching、在解析事务命令时出错,用于存储错误的txErrors切片。然后每个DB结构体都带有一个versionMap字段,用于储存每个key的版本号,key一旦被执行了写命令,版本号就会+1。
客户端执行watch命令的时候,程序会把watch命令后面的key都存进client结构体的watching map中,key是键的名称,value是键的版本号。
客户端执行multi的时候,就是事务开始了,程序会先判断multiState是否为true,就是判断之前有没有执行过multi命令,如果没有,就把状态变量multiState标记为true,然后向客户端返回一个ok。
接着每次客户端向服务器发送命令,服务器都会首先判断当前是否处于事务状态,如果处于事务状态,就不会被执行,而是先判断该命令有没有错误,有错误就把错误储存进client结构体的txErrors切片中,最后将命令放入client结构体的事务队列中。
当客户端执行exec命令的时候,就表示事务到了执行阶段,程序首先会判断client结构体的txErrors切片是否为空,如果不为空,说明出现了语法错误,事务将直接被丢弃。如果为空,说明事务命令没有语法错误,程序会把client结构体的watching map中的key取出来和DB结构体中的version map中的key做比较,如果不一样说明key发生了变化,事务将被丢弃。
最后当一切都没有问题,程序会遍历事务队列,开始一个一个的执行事务命令,如果中间出现了错误,那么前面执行成功的命令都会被回滚。
事务怎么进行回滚
前面说过每个命令都对应着一个command结构体,这个结构体中不仅有命令的执行函数和命令的参数数量字段,其实还有每条命令对应的回滚函数,简单命令的回滚函数基本上就是执行与这条命令相反的命令,比如SET的回滚命令就是DEL,RPUSH的回滚命令就是RPOP,如果某条命令的执行流程较为复杂,那么会执行一个万能回滚命令:rollbackGivenKeys,该函数比较简单粗暴,它会将key直接删除,然后将原来key对应的数据重新set进数据库。
在事务命令开始执行前,程序会创建一个切片,专门用来保存每条命令对应的回滚命令,然后循环一边保存回滚命令一边执行事务,如果中间某条命令的执行出现了错误,循环会被break掉。程序会逆向遍历保存回滚命令的切片,一个一个的执行回滚命令。
事务进行时,服务器是如何区分不同客户端的
由于TCP是长连接,客户端与服务器建立好连接,完成一次数据读写之后,服务器并不会关闭连接,而是保持着连接状态,等待着下一次的数据读写。所以客户端向服务器发送完一次命令之后,client结构体并不会被销毁。
AOF持久化和重写是怎么实现的
首先如果配置文件中开启了AOF,程序就会执行AOF持久化和AOF重写。
AOF重写
内存数据库在初始化的时候会调用aof包的NewAofHandler函数,该函数会从配置文件中读取aof持久化文件的路径和文件名,然后就调用一个LoadAof函数来处理aof文件。该函数首先会调用解析层的ParseStream函数来解析文件中的命令,接着创建一个伪客户端来执行解析出来的所有命令,执行完之后,aof重写就完成了。
AOF持久化
AOF处理程序在初始化的时候会创建一个大小为65535的通道,然后开启一个协程监听该通道,如果接收到值,就将通道中的指令以RESP协议的格式落盘。
数据库的每一个DB都有一个addAof字段,该字段是一个函数。数据库在初始化时,会为每一个DB都初始化这个函数。当数据库执行写指令时,该函数会将当前的DB编号以及命令,封装到一个payload结构体中,然后发送到上述通道中。
发布/订阅是怎么实现的
主要的数据结构
客户端维护的信息:客户端维护了一个map,该map的结构是map[string]true,表示该客户端订阅了哪些频道。(下面简称为clientMap)
服务器维护的信息:服务器的pubsub包中维护了一个subs map,该map是map[string]*List结构,List中存的是
客户端结构体,储存的是频道和频道的订阅者链表。(下面简称为serverMap)。
订阅频道
首先向clientMap中添加这个频道,然后向serverMap中添加相关信息:
1. 如果serverMap中存在该频道,那么取出client链表,再将当前client`添加进去。 2. 如果serverMap中不存在该频道,那么创建client链表,再将当前client``添加进去。
退订频道
首先向clientMap中删除这个频道,然后向serverMap中删除相关信息:
- 如果
serverMap中存在该频道,那么取出client链表,再将当前client删除。 - 如果
serverMap中不存在该频道,直接向客户端返回错误信息。
发送消息
从serverMap中取出对应的频道以及频道的订阅者链表,然后遍历链表,依次向订阅者发送消息。
服务器出现错误,如何关闭所有与客户端的连接
我在协议层的TCP Handler结构体中封装了一个保存client结构体的activeConn字段,它是一个sync.Map类型,当服务器收到来自客户端的请求时,会将这个客户端包装成一个client并存到这个activeConn中。
当服务器意外关闭时,程序收到来自系统的关闭信号,然后会遍历activeConn,将所有客户端连接都关闭。
介绍一下用到的跳表和快速列表结构
跳表
跳表是一个随机化的数据结构,实质上是一种可以进行二分查找的有序链表。跳跃表在原有的单向有序链表上增加了多级的索引,通过索引可以实现快速查找,快速插入,快速删除。它的查询复杂度平均O(logN), 最坏O(N), 堪比红黑树, 但实现起来远比红黑树简单。
跳表的结构
我实现的跳表结构首先有两个最基本的结构:用于表示一个元素的结构体Element,里面有Member(string类型)和Score(float64类型)两个字段,还有一个用于表示跳表层的结构体Level,里面有一个forward指针(指向前面一个节点的相同层)和span(与前面一个节点的跨度)字段。
然后是用于表示跳表一个节点的结构体node,node结构体中有三个字段,分别是该节点储存的元素、该节点层的切片(每个节点有 1~16 个层级,切片的长度就是这个节点的上面有几层索引)和一个回退指针。
跳表有一个表头结构,里面是指向跳表的头节点指针header、指向表尾节点的tail指针、跳跃表的长度length以及跳跃表的最大层级level。需要注意的是跳表在创建的时候,会创建一个哨兵节点,跳表的长度和最大层级不会包括这个节点。
跳表的查找
- 优先从高层查找。
- 若当前节点的值, 小于要查找的值, 并且next指针指向大于目标值的节点, 就要降一级寻找, 或者next指针指向了null, 那么也需要降一级查找。
跳表节点的插入
跳表是一个根据元素分数排序的有序结构,新元素会根据分数被插入到合适的位置,插入前程序会查找跳表插入的位置。
- 优先从高层查找。
- 若当前节点的值, 小于要查找的值, 并且next指针指向大于目标值的节点, 就要降一级寻找, 或者next指针指向了null, 那么也需要降一级查找。
找到待插入的位置之后,程序会根据随机算法,为新节点生成一个层的高度,然后将其插入到该插入的位置,接着更新前面一个节点与下一个节点的跨度,最后更新表头的信息。
跳表节点的删除
删除操作首先要找到待删除节点的位置,找节点的步骤与插入节点的操作类似,在每一层中进行查找,分数比当前节点小,就往后遍历,比当前节点大就下沉。找到该节点之后,就可以进行删除操作了。
删除之后,先更新每一层索引的状态:更新待删除节点前一个节点的跨度以及forward指针的指向。
然后更新后面一个节点的回退指针,最后更新跳表中的最大层级即可。
快速列表
快速列表(quicklist)是Redis中特有的一种数据结构,主要是为了解决双端链表的弊端:双端链表的附加空间比较高,因为prev和next指针会占掉一部分的空间(64位系统占用8 + 8 = 16字节)。而且链表的每个节点都是单独分配内存,会加剧内存的碎片化。
我实现的快速列表其实就是链表+切片,每个链表的节点中储存的是容量为1024的切片,所以一个链表节点就可以看作是一页,页的大小就是1024。
迭代器
此外我还实现了了快速列表的迭代器,快速列表的迭代器中有三个字段:链表的节点node(可以看成一页),元素在页中的偏移量、表头结构。这样实现的迭代器,使得迭代器既可以在元素之前迭代,也可以在页之间快速迭代。
快速列表的查找
快速列表的查找效率要比链表高,首先利用迭代器一页一页进行迭代,首先定义一个累加偏移量的变量pageBeg,每迭代一页就把这页的大小累加到pageBeg中,每次比较pageBeg + len(page)与index的大小,如果前者更大,表示元素就在该页中,如果后者更大,表示元素在后面的页中。
当确定了元素在哪一页后,利用元素的下标直接在页内的slice中直接定位即可。
快速列表的插入和删除
快速列表的插入操作首先是要找到待插入的位置,然后分为三种情况:
- 向最后一页的最后一个位置插入元素,直接插入表尾即可。
- 某一页插入一个元素,且该页未满,直接插入该页即可。
- 某一页插入一个元素,该页满了,就新创建一页,然后将前512个元素留在原来那页,将后512个元素移到新的页中,新插入的元素,如果下标在[0,512]之间,就插入到原来页,如果下标在[516, 1024]之间,就插入到新创建的页中。
快速列表的删除操作首先同样要找到待删除的元素位置,然后分为四种情况:
- 删除后的页不为空,且删除的不是该页的最后一个元素,什么都不用管。
- 删除后的页不为空,且删除的是该页的最后一个元素,需要将迭代器移动到下一页的最后一个元素。
- 删除的页为空(需要删除该页),且删除的页是最后一页,将迭代器置空。
- 删除的页为空(需要删除该页),且删除的页不是最后一页,将迭代器指向下一页。
介绍一下Go的sync.Map结构
sync.Map是官方在sync包中提供的一种并发map,使用起来非常简单,和普通map相比,只有遍历的方式有区别。普通的map使用for range的方式就可以遍历,而sync.Map需要使用它自带的Range函数才能遍历。
sync.Map是通过 read 和 dirty 两个字段将读写分离,读的数据存在只读字段 read 上,将最新写入的数据则存在 dirty 字段上。
读取时会先查询 read,不存在再查询 dirty,写入时则只写入 dirty。
读取 read 并不需要加锁,而读或写 dirty 都需要加锁,另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上,对于删除数据则直接通过标记来延迟删除。
sync.Map的查找
查找元素会调用Load函数,该函数的执行流程:
首先去read map中找值,不用加锁,找到了直接返回结果。
如果没有找到就判断read.amended字段是否为true,true说明dirty中有新数据,应该去dirty中查找,开始加锁。
加完锁以后又去read map中查找,因为在加锁的过程中,m.dirty可能被提升为m.read。
如果二次检查没有找到key,就去m.dirty中寻找,然后将misses计数加一。
sync.Map的添加和更新
新增或者更新元素会调用Store函数,该函数的前面几个步骤与Load函数是一样的:
首先去read map中找值,不用加锁,找到了直接调用tryStore()函数更新值即可。
如果没有找到就开始对dirty map加锁,加完锁之后再次去read map中找值,如果存在就判断该key对应的entry有没有被标记为unexpunge,如果没有被标记,就直接调用storeLocked()函数更新值即可。
如果在read map中进行二次检查还是没有找到key,就去dirty map中找,找到了直接调用storeLocked()函数更新值。
如果dirty map中也没有这个key,说明是新加入的key,首先要将read.amended标记为true,然后将read map中未删除的值复制到dirty中,最后向dirty map中加入这个值。
sync.Map的删除
删除会调用Delete函数,该函数的步骤如下:
首先去read map中找key,找到了就调用e.delete()函数删除。
如果在read map中没有找到值就开始对dirty map加锁,加锁完毕之后再次去read map中查找,找到了就调用e.delete()函数删除。
如果二次检查都没有找到key(说明这个key是被追加之后,还没有提升到read map中就要被删除),就去dirty map中删除这个key。
key究竟什么时候被删除
我们可以发现,如果read map中存在待删除的key时,程序并不会去直接删除这个key,而是将这个key对应的p指针指向nil。
在下一次read -> dirty的同步时,指向nil的p指针会被标记为expunged,程序不会将被标记为expunged的 key 同步过去。
等到再一次dirty -> read同步的时候,read会被dirty直接覆盖,这个时候被标记为expunged的key才真正被删除了,这就是sync.Map的延迟删除。
日志功能是怎么实现的
没有使用第三方的日志库,而是自己封装了一个,支持打印五种级别的日志:“DEBUG”, “INFO”, “WARN”, “ERROR”, “FATAL”,当发生一些特殊事件的时候,比如建立了一个TCP连接、程序出现错误等等,程序会将事件信息封装成相应级别的日志然后打印到日志文件中。
为了避免日志信息过多造成冗余,日志文件以天为单位进行区分,每过一天就会创建一个新的日志文件,文件名中带有日期。