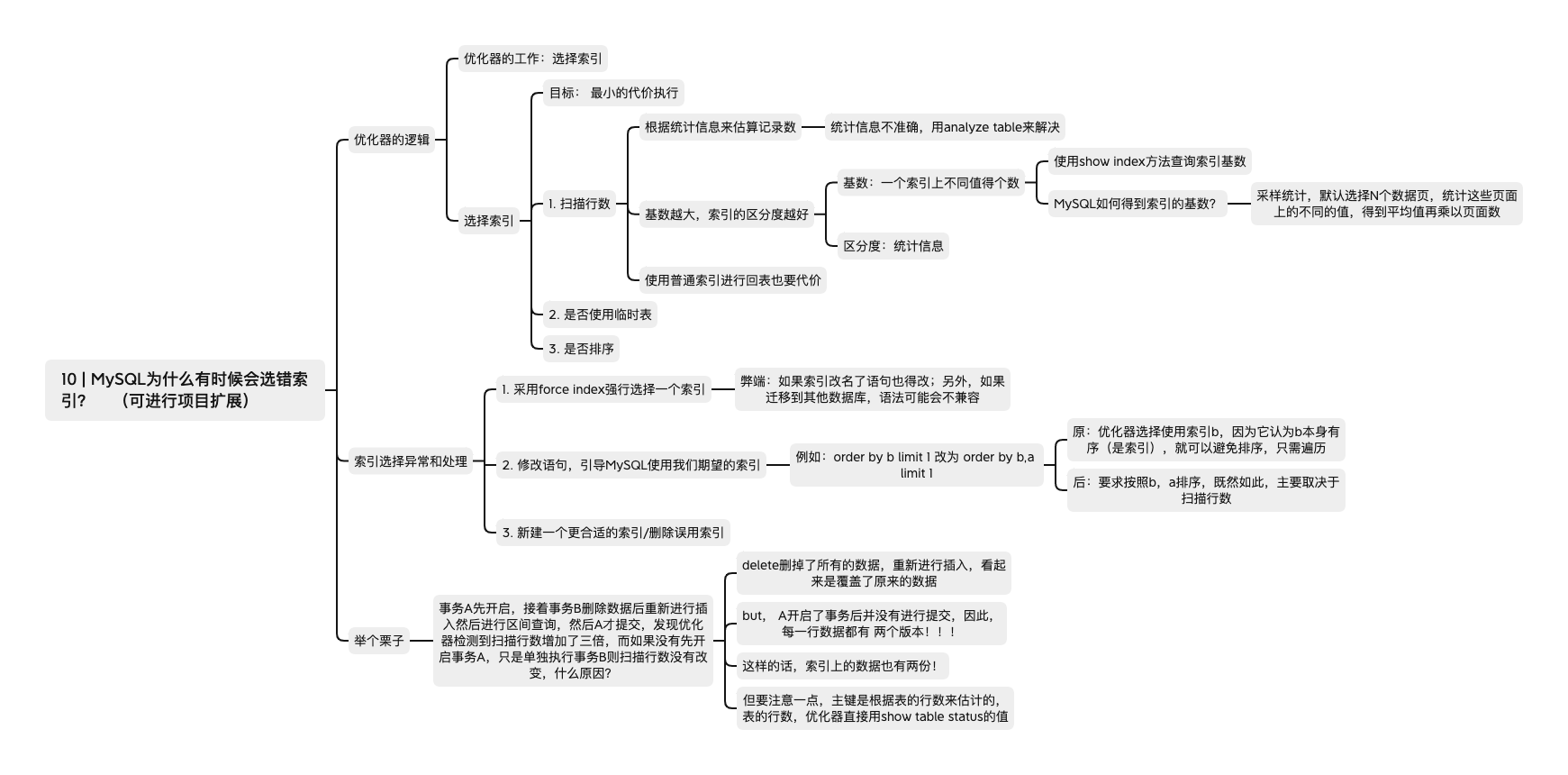
10 | MySQL为什么有时候会选错索引? (可进行项目扩展)
优化器的逻辑
优化器的工作:
选择索引
选择索引
目标: 最小的代价执行
- 扫描行数
-
根据统计信息来估算记录数
- 统计信息不准确,用analyze table来解决
-
基数越大,索引的区分度越好
-
基数:一个索引上不同值得个数
- 使用show index方法查询索引基数
- MySQL如何得到索引的基数?
- 采样统计,默认选择N个数据页,统计这些页面上的不同的值,得到平均值再乘以页面数
-
区分度:统计信息
-
-
使用普通索引进行回表也要代价
-
- 是否使用临时表
- 是否排序
索引选择异常和处理
-
- 采用force index强行选择一个索引
- 弊端:如果索引改名了语句也得改;另外,如果迁移到其他数据库,语法可能会不兼容
-
- 修改语句,引导MySQL使用我们期望的索引
-
例如:order by b limit 1 改为 order by b,a limit 1
- 原:优化器选择使用索引b,因为它认为b本身有序(是索引),就可以避免排序,只需遍历
- 后:要求按照b,a排序,既然如此,主要取决于扫描行数
-
- 新建一个更合适的索引/删除误用索引
举个栗子

扫描二维码关注公众号,回复:
14549830 查看本文章

事务A先开启,接着事务B删除数据后重新进行插入然后进行区间查询,然后A才提交,发现优化器检测到扫描行数增加了三倍,而如果没有先开启事务A,只是单独执行事务B则扫描行数没有改变,什么原因?
delete删掉了所有的数据,重新进行插入,看起来是覆盖了原来的数据
but, A开启了事务后并没有进行提交,因此,每一行数据都有 两个版本!!!
这样的话,索引上的数据也有两份!
但要注意一点,主键是根据表的行数来估计的,表的行数,优化器直接用show table status的值