一、MongoDB 索引
MongoDB提供了多样性的索引支持,索引信息被保存在 system.indexes 中,且默认总是为_id创建索引,它的索引使用基本和 MySQL 等关系型数据库一样。其实可以这样说说,索引是凌驾于数据存储系统之上的另一层系统,所以各种结构迥异的存储都有相同或相似的索引实现及使用接口并不足为奇。
1、基础索引
在字段 age 上创建索引,1(升序)、-1(降序):
> db.t3.ensureIndex({age:1}) // db.t3.ensureIndex({age:-1}) 降序索引
> db.t3.getIndexes();
[
{
"name" : "_id_",
"ns" : "test.t3",
"key" : {
"_id" : 1
},
"v" : 0
},
{
"_id" : ObjectId("4fb906da0be632163d0839fe"),
"ns" : "test.t3",
"key" : {
"age" : 1
},
"name" : "age_1",
"v" : 0
}
]
>上例显示出来的一共有 2 个索引,其中_id 是创建表的时候自动创建的索引,此索引是不能够删除的。
和mysql不同的是,mongodb在建立索引的时候可以决定为一个字段建立升序还是降序的索引。而mysql没有能指定升序还是降序的参数,默认都是升序索引。
当然,这里只是为了演示,在生产环境下上为一个单字段索引同时加升序索引和降序索引是没有意义的,反而还浪费空间,升序索引在根据单个字段升序排序或降序排序时都能用到,MongoDB可以在任一方向上遍历索引。
只有在创建符合索引并根据复合索引排序时,这时候同时建立升序索引和降序索引才有用。
需要注意的是,mongdb在建立索引时会阻塞对数据库的读和写请求。如果希望数据库在创建索引的同时仍然能够处理读写请求,可以在创建索引时指定background选项。这样在创建索引时,如果有新的数据库请求需要处理,创建索引的过程就会暂停一下,但是仍然会对应用程序性能有比较大的影响。而且background后台创建索引比前台创建索引慢得多。
当系统已有大量数据时,创建索引就是个非常耗时的活,我们可以在后台执行,只需指定“backgroud:true”即可。
> db.t3.ensureIndex({age:1} , {backgroud:true})2、文档索引
索引可以任何类型的字段,甚至文档。
为内嵌文档内部字段创建索引:
db.worker.createIndex({"score.f1" : 1}) // 为score.f1创建升序索引,score就是一个内嵌文档为整个内嵌文档字段创建索引:
db.worker.createIndex({"score" : 1}) // 为score字段创建升序索引,score就是一个内嵌文档需要注意的是:
当为整个内嵌文档创建索引后,在嵌入文档上执行相等匹配的查询时,字段顺序很重要,内嵌文档必须精确匹配,否则无法使用到索引。
例如上面的例子中,如果这样查是用到了score索引的:
db.worker.find({score:{f1:1, f2:2})但是如果这样查是没有用到索引的:
db.worker.find({score:{f2:2, f1:1})3、组合索引
跟其它数据库产品一样,MongoDB 也是有组合索引的,下面我们将在 addr.city 和 addr.state上建立组合索引。当创建组合索引时,字段后面的 1 表示升序,-1 表示降序,是用 1 还是用 -1 主要是跟排序的时候或指定范围内查询 的时候有关的。
创建组合索引:
db.users.createIndex({"age" : 1, "username" : 1})这里就相当于创建了一个 age_username 的索引,请分析以下查询是否用到这个复合索引:
db.users.find({"age" : 21}) // 用到索引
db.users.find({"age" : 21, "username":"user111"}) // 用到索引
db.users.find({"age" : 21}).sort({"username" : -1}) // 用到索引
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}) // 用到索引
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}).sort({"username":1}) // age的查询用到索引,但username的排序没用到索引(因为在B树上,age从21到30之间的username是无序的,如果是age为某个值下的username才是有序的),需要在内存中排序
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}).sort({"age" : 1, "username" : 1}) // 查询和排序都用到了索引
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}).sort({"username" : 1, "age" : 1}) // 查询用到了索引,排序没有用到,因为username和age的顺序不对,这里先按username排序,而B数节点从左到右的的username字段是无序的
db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}).sort({"age" : 1, "username" : -1}) // 查询用到了索引,排序没有用到如果希望sort({"age" : 1, "username" : -1})或者sort({"age" : -1, "username" : 1})能够用到索引则我们可以多创建一个复合索引:db.users.createIndex({"age" : 1, "username" : -1}),这个索引和db.users.createIndex({"age" : 1, "username" : 1})是不同的两个索引(会创建两个索引文件),前者是在age相同的情况下对username倒序排序的。
所以之前我们讲过,创建单字段索引的时候,键的排序顺序(1和-1)无关紧要,因为MongoDB可以在任一方向上遍历索引。但是,对于复合索引,键的排序顺序决定了索引是否支持结果集的排序。
对于mongodb复合索引的使用以及判定是否用到了索引,和mysql的索引规则以及判定基本相同。
另外要善用覆盖索引,当我们不查询所有的字段,而只查询特定的几个字段时,如果一个索引包含用户需要请求的所有字段,可以认为这个索引覆盖了本次查询。
在实际中,应该优先使用覆盖索引,而不是去获取实际的文档。
需要注意的是:不能创建具有hashed索引类型的复合索引。如果试图创建包含hashed索引字段的复合索引,将收到一个错误。
使用索引是有代价的:对于添加的每一个索引,每次写操作(插入、更新、删除)都将耗费更多的时间。这是因为,当数据发生变动时,MongoDB不仅要更新文档,还要更新集合上的索引。因此,MongoDB限制每个集合上最多只能有64个索引。通常,在一个特定的集合上,不应该拥有两个以上的索引。
4、为数组字段创建索引(多键索引)
例如有一个形如这样的集合(文章表),其中的comments(评论字段)是一个数组字段。我们可以为comments中的元素的某一个内部字段(name或email或content字段)建立索引。
{
"_id" : ObjectId("4b2d75476cc613d5ee930164"),
"title" : "A blog post",
"content" : "...",
"comments" : [
{
"name" : "joe",
"email" : "[email protected]",
"content" : "nice post."
},
{
"name" : "bob",
"email" : "[email protected]",
"content" : "good post."
},
{
"name" : "bob",
"email" : "[email protected]",
"content" : "good post.11111"
}
]
}对数组(中的字段)建立索引,实际上是对数组的每一个元素建立一个索引条目(无论数组里面是内嵌文档还是普通的数字或字符串),所以如果一篇文章有20条评论,那么它就拥有20个索引。
因此数组索引的代价比单值索引高:对于单次插入、更新或者删除,每一个数组条目可能都需要更新(可能有上千个索引条目)。
注意事项:
- 无法将整个数组作为一个实体建立索引:我们这里说的对数组建立索引,实际上是对数组中的每个元素建立索引,而不是对数组本身建立索引。(之后文章出现“数组索引”字样默认是指数组中元素的某一字段的索引);
- 无法使用数组索引查找特定位置的数组元素,比如"comments.4" ;
- 一个复合索引中的数组字段最多只能有一个。这是为了避免在多键索引中索引个数爆炸性增长:每一对可能的元素都要被索引,这样导致每个文档拥有n*m 个索引条目。假如有一个这样的索引{"x" : 1, "y" : 1} :
> // x是一个数组—— 这是合法的
> db.multi.insert({"x" : [1, 2, 3], "y" : 1})
>
> // y是一个数组——这也是合法的
> db.multi.insert({"x" : 1, "y" : [4, 5, 6]})
>
> // x和y都是数组——这是非法的!
> db.multi.insert({"x" : [1, 2, 3], "y" : [4, 5, 6]})
cannot index parallel arrays [y] [x]如果MongoDB要为上面的最后一个例子创建索引,它必须要创建这么多索引条目:{"x" : 1, "y" : 4} 、{"x" : 1, "y" : 5} 、{"x" : 1, "y" : 6} 、{"x" : 2, "y" : 4} 、{"x" : 2, "y" : 5} ,{"x" : 2, "y" : 6} 、{"x" : 3, "y" : 4} 、{"x" : 3, "y" : 5} 和{"x" : 3, "y" : 6} 。
所以如果x,y都是一个数组字段,那么我们就不能建立一个包含x和y的复合索引{"x" : 1, "y" : 1}
PS:我们可以查询命令后面接.explain()方法来分析查询语句的性能。
可以得到如这样的内容:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "zbp.worker",
"indexFilterSet" : false,
"parsedQuery" : {
"username" : {
"$eq" : "user1001"
}
},
"queryHash" : "379E82C5",
"planCacheKey" : "965E0A67",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"username" : 1
},
"indexName" : "username_1", // 使用了username这个索引
"isMultiKey" : false, // 不是多键索引
"multiKeyPaths" : {
"username" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"username" : [
"[\"user1001\", \"user1001\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "DESKTOP-1DHFFH1",
"port" : 27017,
"version" : "4.4.4",
"gitVersion" : "8db30a63db1a9d84bdcad0c83369623f708e0397"
},
"ok" : 1
}注意:
有些情况下,一个值可能无法被索引。索引储桶(index bucket)的大小是有限制的,如果某单个索引条目超出了它的单个索引大小的限制,那么这个条目就不会包含在索引里。这样会造成使用这个索引进行查询时会有一个文档凭空消失不见了。所有的字段值都必须小于1024字节,才能包含到索引里。
如果一个文档的字段由于太大不能包含在索引里,MongoDB不会返回任何错误或者警告(这段话的意思是某个字段的字段值如果内容太长超过了1024字节,这个值就不会被存到索引中)。
5、唯一索引
只需在 ensureIndex 命令中指定”unique:true”即可创建唯一索引。例如,往表 t4 中插入 2 条记录。
db.t4.insert({firstname: "wang", lastname: "wenlong"});
db.t4.insert({firstname: "wang", lastname: "wenlong"});在 t4 表中建立唯一索引:
> db.t4.ensureIndex({firstname: 1, lastname: 1}, {unique: true});
E11000 duplicate key error index: test.t4.$firstname_1_lastname_1 dup key: { : "wang", :
"wenlong" }可以看到,当建唯一索引时,系统报了“表里有重复值”的错,具体原因就是因为表中有 2 条一模一模的数据,所以建立不了唯一索引。
如果对某个字段设置了唯一索引,但是插入文档时没有设置这个字段,索引会将其作为null存储。所以,如果对某个键建立了唯一索引,但插入了多个缺少该索引键的文档,由于集合已经存在一个该索引键的值为null 的文档而导致插入失败。
例如有一个集合中的文档如下:
{
"_id" : ObjectId("603704f5d48efa1f174ac2a5"),
"name" : {
"first" : "Joe",
"last" : "Schmoe"
},
"age" : 45
}我对name.first建立唯一索引:
p.createIndex({"name.first":1},{"unique":1})然后插入两次下面的文档(缺少name.first),第一次插入成功,第二次失败。
{
"_id" : ObjectId("6040301f8c4860ff45dc085d"),
"name" : {
"last" : "gaogao"
},
"age" : 20
}如果插入的某个字段值(该字段值建立了唯一索引),但是这个字段值大小超过单个索引限制的最大大小,他就不会被假如到索引中。也就是说,那么此时就可以重复插入该字段值,因为该值没有被加到索引中。
在已有的集合上创建唯一索引时可能会失败,因为集合中可能已经存在重复值了。
在极少数情况下,可能希望直接删除重复的值再建立唯一索引。创建索引时使用"dropDups"选项,如果遇到重复的值,第一个会被保留,之后的重复文档都会被删除。
db.people.createIndex({"username" : 1}, {"unique" : true, "dropDups" : true})"dropDups" 会强制性建立唯一索引,但是这个方式太粗暴了:你无法控制哪些文档被保留哪些文档被删除。
也可以创建复合的唯一索引。创建复合唯一索引时,单个键的值可以相同,但所有键的组合值必须是唯一的。
如果有一个{"username" : 1, "age" : 1} 上的唯一索引,下面的插入是合法的:
db.users.insert({"username" : "bob"})
db.users.insert({"username" : "bob", "age" : 23})
db.users.insert({"username" : "fred", "age" : 23})如果试图再次插入这三个文档中的任意一个,都会导致键重复异常。(重复插入第一个相当于重复插入{"username" : "bob","age":null})。
6、强制使用索引
hint 命令可以强制使用某个索引:
> db.t5.insert({name: "wangwenlong",age: 20})
> db.t5.ensureIndex({name:1, age:1})
> db.t5.find({age:{$lt:30}}).explain()
{
"cursor" : "BasicCursor",
"nscanned" : 1,
"nscannedObjects" : 1,
"n" : 1,
"millis" : 0,
"nYields" : 0,
"nChunkSkips" : 0,
"isMultiKey" : false,
"indexOnly" : false,
"indexBounds" : { --并没有用到索引
}
}
> db.t5.find({age:{$lt:30}}).hint({name:1, age:1}).explain() --强制使用索引
{
"cursor" : "BtreeCursor name_1_age_1",
"nscanned" : 1,
"nscannedObjects" : 1,
"n" : 1,
"millis" : 1,
"nYields" : 0,
"nChunkSkips" : 0,
"isMultiKey" : false,
"indexOnly" : false,
"indexBounds" : { --被强制使用索引了
"name" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
],
"age" : [
[
-1.7976931348623157e+308,
30
]
]
}
}
>7、删除索引
db.collection.dropIndexes(IndexObj)删除索引分为删除某张表的所有索引和删除某张表的某个索引,具体如下:
//删除 t3 表中的所有索引
db.t3.dropIndexes()
//删除 t4 表中的 firstname 索引
db.t4.dropIndex({firstname: 1})8、获取索引
我们可以通过getIndexes()获取所有的索引和他们的名称。在创建索引的时候也可以为索引指定名称,比如:
db.t4.createIndex({"a" : 1, "b" : 1, "c" : 1, ..., "z" : 1},{"name" : "alphabet"})索引的名称默认是,字段名1_1_字段名2_1 的形式。
9、稀疏索引
MongoDB中的稀疏索引(sparse index)与关系型数据库中的稀疏索引是完全不同的概念。
如果使用了稀疏索引,索引的稀疏属性可确保索引仅包含具有索引字段的文档的条目。索引会跳过没有索引字段的文档。也就是说,如果给一个name字段建立索引的时候添加了稀疏属性,那么只有name为非null的值会被添加到name索引中,而name为null的值不记录到name索引中。
可以将稀疏索引与唯一索引结合使用,以防止插入索引字段值重复的文档,并跳过索引缺少索引字段的文档。
使用sparse 选项就可以创建稀疏索引。例如,如果有一个可选的email地址字段,如果提供了这个字段,那么它的值必须是唯一的。
db.createIndex({"email" : 1}, {"unique" : true, "sparse" : true})稀疏索引不必是唯一的。只要去掉unique 选项,就可以创建一个非唯一的稀疏索引。
下面这个例子展现了使用稀疏属性和没有使用稀疏属性的索引在查询行为上的差异:
p.createIndex({"age":1},{"sparse":1}) // 对age建立稀疏索引
p.insert({ "name" : { "first" : "Joe", "last" : "111" }, "age" : 20 })
p.insert({ "name" : { "first" : "Joe", "last" : "111" }, "age" : 20 })
p.insert({ "name" : { "first" : "Joe", "last" : "111" }, "age" : 21 })
p.insert({ "name" : { "first" : "Joe", "last" : "111" }})
p.insert({ "name" : { "first" : "Joe", "last" : "111" }})
d = p.find({"age":{"$ne":20}}).toArray() // 结果为后3条,此时我们用explain分析发现他是没有用到age索引的(如果使用了索引就不可能查询到age为null的数据了)
d2 = p.find({"age":{"$ne":20}}).hint({"age":1}).toArray() // 强制使用age这个索引进行查询,结果只要1条(第三条),因为age为null没有存在age索引文件中10、固定集合
MongoDB中有一种不同类型的集合叫做固定集合,固定集合的大小是固定的(固定的数据量大小或者固定的行数),如果向一个已经满了的固定集合中插入数据会怎么样?
答案是,固定集合的行为类似于循环队列。如果已经没有空间了,最老的文档会被删除以释放空间,新插入的文档会占据这块空间(即新文档会覆盖旧文档)。
固定集合不能被分片,固定集合可以用于记录日志。虽然可以在创建时指定集合大小,但无法控制什么时候数据会被覆盖。
创建一个固定集合:
db.createCollection("my_collection", {"capped":true, "size":100000});创建了一个名为my_collection,大小为100 000字节的固定集合。
除了大小,createCollection还能够指定固定集合中文档的数量,但同时也必须指定size大小:
db.createCollection("my_collection2", {"capped" : true, "size" : 100000, "max" : 100});不管先达到哪一个限制,之后插入的新文档就会把最老的文档挤出集合。
固定集合创建之后,就不能改变了(如果需要修改固定集合的大小,只能将它删除之后再重建)。
可以将已有的某个常规集合转换为固定集合,可以使用convertToCapped命令实现。
下面的例子将test集合转换为一个大小为10 000字节的固定集合:
db.runCommand({"convertToCapped" : "test", "size" : 10000});但是无法将固定集合转换为非固定集合(只能将其删除)。
11、TTL索引
TTL索引是有生命周期(有超时时间)的索引,这种索引允许为每一个文档设置一个超时时间。
一个文档到达预设置的超时时间之后就会被删除,不过前提是设置了TTL索引的字段必须是一个日期类型而且该文档必须有这个字段才能自动删除。这种类型的索引对于缓存问题(比如会话的保存)非常有用。
在createIndex中指定expireAfterSeconds属性就可以创建一个TTL索引。例如:
test.createIndex({lastUpdated:1}, {"expireAfterSeconds":60})这样就在"lastUpdated"字段上建立了一个TTL索引。如果一个文档的"lastUpdated"字段存在并且它的值是日期类型,当服务器时间比文档的"lastUpdated"字段的时间晚expireAfterSeconds秒时,文档就会被删除。但是如果我们在文档被删除之前更新lastUpdated字段使得lastUpdated字段的时间与设置TTL索引时的时间差小于expireAfterSeconds的话,那么该文档就不会被删除(如果之后不更新lastUpdated字段的时间的话,那么之后还是会被删的)。
在一个给定的集合上可以有多个TTL索引。TTL索引不能是复合索引,但是可以像“普通”索引一样用来优化排序和查询。
- _id列不支持TTL索引;
- 固定集合(capped collection)不支持TTL索引;
如果一个列已经存在索引,则需要先将该索引drop后才能重建为TTL索引,不能直接转换。
如果一个字段已经建立了TTL索引,但是想要修改该索引的过期时间,此时可以使用collMod命令修改:
db.runCommand({"collMod":"test", index:{keyPattern:{lastUpdated:1}, "expireAfterSeconds" : 5}})注意:
有些情况下,一个值可能无法被索引。索引储桶(index bucket)的大小是有限制的,如果某单个索引条目超出了它的单个索引大小的限制,那么这个条目就不会包含在索引里。这样会造成使用这个索引进行查询时会有一个文档凭空消失不见了。
所有的字段值都必须小于1024字节,才能包含到索引里。如果一个文档的字段由于太大不能包含在索引里,MongoDB不会返回任何错误或者警告(这段话的意思是某个字段的字段值如果内容太长超过了1024字节,这个值就不会被存到索引中)。
有一些查询完全无法使用索引,也有一些查询能够比其他查询更高效地使用索引。这里将讲述MongoDB对各种不同查询操作符的处理。
A. 低效率的操作符
- $where:完全无法使用索引
- $exists:无法使用索引,如查询有key1这个字段的所有文档({"key1" : {"$exists" : true}})
- $ne:可以使用索引,但并不是很有效。因为必须要查看所有的索引条目,而不只是"$ne" 指定的条目,不得不扫描整个索引。
例如:
db.example.find({"i" : {"$ne" : 3}}) 它确实使用了索引,但是他要扫描i>3和i<3的所有索引条目,并返回i>3和i<3的所有文档,假如集合的文档个数有几十万条,那么就和不使用索引没什么区别。
- $not:有时能够使用索引(对基本的范围(比如将{"key " : {"$lt" : 7}} 变成 {"key " : {"$gte" : 7}} )和正则表达式进行反转),但大多数使用"$not" 的查询都会退化为进行全表扫描
B. OR查询
如果你在{"x" : 1} 上有一个索引,在{"y" : 1} 上也有一个索引,使用条件{"x" : 123, "y" : 456} 进行查询(相当于是and查询)时,MongoDB会使用其中的一个索引,而不是两个一起用。因为MongoDB在一次查询中只能使用一个索引。
"$or" 是个例外,"$or" 可以对每个子句都使用索引,因为"$or" 实际上是执行两次查询然后将结果集合并。
虽然$or能够用到索引,但是$or的性能没有$in高,因为$or毕竟是多次查询(相当于mysql中的union),因此能用in的情况下尽量用in代替or。
如果or连接的多个条件匹配到重复的文档,MongoDB会检查每次查询的结果集并且从中移除重复的文档。
二、MongoDB 聚合
如果你有数据存储在MongoDB中,你想做的可能就不仅仅是将数据提取出来那么简单了;你可能希望对数据进行分析并加以利用。
1、聚合框架
使用聚合框架可以对集合中的文档进行变换和组合。基本上,可以用多个构件创建一个管道(pipeline),用于对一连串的文档进行处理。这些构件包括筛选(filtering)、投射(projecting)、分组(grouping)、排序(sorting)、限制(limiting)和跳过(skipping)。
如果有一个test集合,里面有以下文档:
{ "_id" : ObjectId("60445f35b6e04e8e7e360e2e"), "name" : "zbp", "age" : 24, "job" : "programme" }
{ "_id" : ObjectId("60445f48b6e04e8e7e360e2f"), "name" : "zbp1", "age" : 23, "job" : "job1" }
{ "_id" : ObjectId("60445f55b6e04e8e7e360e30"), "name" : "yf", "age" : 25, "job" : "programme" }
{ "_id" : ObjectId("60445f68b6e04e8e7e360e31"), "name" : "ww", "age" : 36, "job" : "manager" }
{ "_id" : ObjectId("60445f79b6e04e8e7e360e32"), "name" : "zbp", "age" : 24, "job" : "job3" }现在我希望获取job字段统计,获取每种job的数量count并将结果按count倒序排序,只显示5条结果。
test.aggregate(
{"$project":{"job":1}}, // 投射
{"$group":{"_id":"$job", "count":{"$sum":1}}}, //分组
{"$sort":{"count":-1}},
{"$limit":5}
)结果为:
{ "_id" : "programme", "count" : 2 }
{ "_id" : "job3", "count" : 1 }
{ "_id" : "manager", "count" : 1 }
{ "_id" : "job1", "count" : 1 }aggregate()就是聚合管道函数。
上面的操作其实很像是linux中的管道操作,这里使用了4个管道操作符($project、$group、$sort和$limit),每个操作符都会接受一连串的文档,对这些文档做一些处理和转换,最后将处理后的文档作为结果传递给下一个操作符(对于最后一个管道操作符,是将结果返回给客户端)。
2、管道操作符
1. $match
用于对文档集合进行筛选,之后就可以在筛选得到的文档子集上做聚合。相当于where和having条件查询,只不过$match是用在聚合中的条件筛选。
例如,上面的例子中,我希望统计年龄在25岁以下的job的情况,就可以使用:
test.aggregate(
{"$match":{"age":{"$lt":25}}},
{"$project":{"job":1}},
{"$group":{"_id":"$job", "count":{"$sum":1}}}, {"$sort":{"count":-1}}, {"$limit":5}
);在实际使用中应该尽可能将"$match"放在管道的前面位置。这样做有两个好处:
- 一是可以快速将不需要的文档过滤掉,以减少管道的工作量;
- 二是如果在投射和分组之前执行"$match"(相当于where,如果是在分组之后执行$match,那么就相当于having),查询可以使用到索引(也就是说如果在分组和投射之后的条件筛选是用不到索引的);
2. $project
$project操作(投射操作)是从文档中选择想要的字段。可以指定查询结果中显示或者不显示一个字段,还可以为字段起别名。
例如:
test.aggregate({"$project":{"job":1}});结果为:
{ "_id" : ObjectId("60445f35b6e04e8e7e360e2e"), "job" : "programme" }
{ "_id" : ObjectId("60445f48b6e04e8e7e360e2f"), "job" : "job1" }
{ "_id" : ObjectId("60445f55b6e04e8e7e360e30"), "job" : "programme" }
{ "_id" : ObjectId("60445f68b6e04e8e7e360e31"), "job" : "manager" }
{ "_id" : ObjectId("60445f79b6e04e8e7e360e32"), "job" : "job3" }只显示了job字段,没有显示name和age字段。
_id字段是默认显示的,如果希望不显示_id可以这样:
test.aggregate({"$project":{"job":1,"_id":0}})将投射的字段进行重命名:
test.aggregate({"$project":{"career":"$job","_id":0}});这里将job字段重命名为career,这里的"$fieldname"语法是为了在聚合框架中引用fieldname字段(上面的例子中是"job")的值。
例如,"$age"会被替换为"age"字段的内容(可能是数值,也可能是字符串),"$tags.3"会被替换为tags数组中的第4个元素。所以,上面例子中的"$job"会被替换为进入管道的每个文档的"job"字段的值。
可以使用这种技术生成字段的多个副本,以便在之后的"$group"中使用。如果在"job"字段上有一个索引,但是使用了career为job重命名后,聚合框架无法在下面的排序操作中使用这个索引。
所以,应该尽量在修改字段名称之前使用索引(例如将$sort放在$project前)。
除了上面的基本用法,$project还可以接表达式例如:
db.employees.aggregate(
{
"$project" : {
"totalPay" :{
"$add" : ["$salary", "$bonus"]
}
}
})将salary和bonus字段的值相加得到totalPay字段。
数字表达式-加减乘除:
"$add" : [expr1[, expr2, , exprN]]
"$subtract" : [expr1, expr2]
"$multiply" : [expr1[, expr2, , exprN]]
"$divide" : [expr1, expr2]还能组合使用:
db.employees.aggregate(
{
"$project" : {
"totalPay" : {
"$subtract" : [{"$add" : ["$salary", "$bonus"]}, "$wh"]
}
}
})
// salary+bonus-wh3. 日期表达式
聚合框架中包含了一些用于提取日期信息的表达式:"$year"、“$month”、"$week"、"$dayOfMonth"、"$dayOfWeek"、"$dayOfYear"、"$hour"、"$minute"和"$second"只能对日期类型(Date类型)的字段进行日期操作,不能对数值类型字段做日期操作。
例如:
db.employees.aggregate(
{
"$project" : {
"hiredIn" : {"$month" : "$hireDate"}
}
})hireDate字段必须是日期类型,得到的hireIn字段是hireDate字段的月份部分。
又例如:
db.employees.aggregate(
{
"$project" : {
"tenure" : {
"$subtract" : [{"$year" : new Date()}, {"$year" : "$hireDate"}]
}
}
})用当前时间的年减去hireDate的年。
字符串表达式:
// 字符串截取(这里截取的是字节而不是字符)
"$substr" : [expr, startOffset, numToReturn]
// 连接多个字符串字段
"$concat" : [expr1[, expr2, , exprN]]
// 大小写
"$toLower" : expr
"$toUpper" : expr例如:
db.employees.aggregate(
{
"$project" : {
"email" : {
"$concat" : [
{"$substr" : ["$firstName", 0, 1]},
".",
"$lastName",
"@example.com"
]
}
}
})其实我建议如果可以的话把数字运算,字符串操作和逻辑运算放在代码中做,而不是交给mongodb中做。
4. $group
$group操作可以将文档依据特定字段的不同值进行分组。
如果选定了需要进行分组的字段,就可以将选定的字段传递给"$group"函数的"_id"字段。
例如:
{"$group" : {"_id" : "$day"}} // 对day字段分组
{"$group" : {"_id" : "$grade"}} // 对grade字段分组
{"$group" : {"_id" : {"state" : "$state", "city" : "$city"}}} //对state和city字段分组分组时我们一般会做一些统计的计算。
- "$sum" 求和;
- "$average" 均值;
db.sales.aggregate(
{
"$group" : {
"_id" : "$country",
"totalRevenue" : {"$sum" : "$revenue"}
}
})如果使用 "$sum":1,相当于mysql中的count(*),即获取每个分类下的记录行数。
// 最大最小值
"$max" :expr
"$min" :expr
// 返回分组的第一个/最后一个值,忽略后面所有值。只有排序之后,明确知道数据顺序时这个操作才有意义。
"$first" :expr
"$last" :expr$max"和"$min"会查看每一个文档,以便得到极值。因此,如果数据是无序的,这两个操作符也可以有效工作;如果数据是有序的,这两个操作符就会有些浪费。假设有一个存有学生考试成绩的数据集,需要找到其中的最高分与最低分。
db.scores.aggregate(
{
"$group" : {
"_id" : "$grade",
"lowestScore" : {"$min" : "$score"},
"highestScore" : {"$max" : "$score"}
}
})另一方面,如果数据集是按照希望的字段排序过的,那么"$first"和"$last"操作符就会非常有用。
下面的代码与上面的代码可以得到同样的结果:
db.scores.aggregate(
{
"$sort" : {"score" : 1}
},
{
"$group" : {
"_id" : "$grade",
"lowestScore":{"$first" :"$score"},
"highestScore" : {"$last" : "$score"}
}
})如果数据是排过序的,那么$first和$last会比$min和$max效率更高。如果不准备对数据进行排序,那么直接使用$min和$max会比先排序再使用$first和$last效率更高。
需要注意:
在分片的情况下"$group"会先在每个分片上执行,然后各个分片上的分组结果会被发送到mongos再进行最后的统一分组,剩余的管道工作(也就是$group之后的管道操作符操作)也都是在mongos(而不是在分片)上运行的。
5. $unwind
拆分(unwind)可以将数组中的每一个值拆分为单独的文档。
例如,如果有一篇拥有多条评论的博客文章,可以使用$unwind将每条评论拆分为一个独立的文档:
> db.blog.findOne()
{
"_id" : ObjectId("50eeffc4c82a5271290530be"),
"author" : "k",
"post" : "Hello, world!",
"comments" : [
{
"author" : "mark",
"date" : ISODate("2013-01-10T17:52:04.148Z"),
"text" : "Nice post"
},
{
"author" : "bill",
"date" : ISODate("2013-01-10T17:52:04.148Z"),
"text" : "I agree"
}
]
}> db.blog.aggregate({"$unwind" : "$comments"})
{
"results" :
{
"_id" : ObjectId("50eeffc4c82a5271290530be"),
"author" : "k",
"post" : "Hello, world!",
"comments" : {
"author" : "mark",
"date" : ISODate("2013-01-10T17:52:04.148Z"),
"text" : "Nice post"
}
},
{
"_id" : ObjectId("50eeffc4c82a5271290530be"),
"author" : "k",
"post" : "Hello, world!",
"comments" : {
"author" : "bill",
"date" : ISODate("2013-01-10T17:52:04.148Z"),
"text" : "I agree"
}
}
],
"ok" : 1
}如果希望在查询中得到特定的子文档,这个操作符就会非常有用:先使用"$unwind"得到所有子文档,再使用"$match"得到想要的文档。
例如,如果要得到特定用户的所有评论(只需要得到评论,不需要返回评论所属的文章),使用普通的查询是不可能做到的。但是,通过提取、拆分、匹配,就很容易了。
db.blog.aggregate(
{"$project" : {"comments" : "$comments"}}, // 提取comments字段
{"$unwind" : "$comments"}, // 将comments数组中的每一个元素拆分为一行
{"$match" : {"comments.author" : "Mark"}} // 条件匹配所有评论的作者为Mark的评论
)如果经常需要查询特定作者的所有评论,建议对comments.author建立嵌套索引,然后在聚合的时候将$match放在最前面,这样可以用到索引:
db.blog.aggregate(
{"$match" : {"comments.author" : "Mark"}} // 条件匹配所有评论的作者为Mark的评论
{"$project" : {"comments" : "$comments"}}, // 提取comments字段
{"$unwind" : "$comments"}, // 将comments数组中的每一个元素拆分为一行
)6. $sort
和$match一样,如果在投射$project和分组$group之前使用$sort排序,这时的排序操作可以使用索引,否则,排序过程就会比较慢,而且会占用大量内存。
db.employees.aggregate(
{
"$project" : {
"compensation" : {
"$add" : ["$salary", "$bonus"]
},
"name" : 1
}
},
{
"$sort" : {"compensation" : -1, "name" : 1}
}
)这个例子会对员工排序,最终的结果是按照报酬从高到低,姓名从A到Z的顺序排列。排序方向可以是1(升序)和-1(降序)。
与前面讲过的"$group"一样,"$sort"在分片环境下,先在各个分片上进行排序,然后将各个分片的排序结果发送到mongos做进一步处理。
7. $limit
$limit会接受一个数字n,返回结果集中的前n个文档。
8. $skip
$skip也是接受一个数字n,丢弃结果集中的前n个文档,将剩余文档作为结果返回。在“普通”查询中,如果需要跳过大量的数据,那么这个操作符的效率会很低。在聚合中也是如此,因为它必须要先匹配到所有需要跳过的文档,然后再将这些文档丢弃。
应该尽量在管道的开始阶段(执行"$project"、"$group"或者"$unwind"操作之前)就将尽可能多的文档和字段过滤掉($match)。因为管道如果不是直接从原先的集合中使用数据,那就无法在筛选和排序中使用索引。如果可能,聚合管道会尝试对操作进行排序,以便能够有效使用索引。
MongoDB不允许单一的聚合操作占用过多的系统内存:如果MongoDB发现某个聚合操作占用了20%以上的内存(比如由于聚合分组和排序而产生了临时集合,即类似于mysql中的临时表),这个操作就会直接输出错误。允许将输出结果利用管道放入一个集合中是为了方便以后使用(这样可以将所需的内存减至最小)。
如果能够通过"$match"操作迅速减小结果集的大小,就可以使用管道进行实时聚合。由于管道会不断包含更多的文档,会越来越复杂,所以几乎不可能实时得到管道的操作结果。
有些问题过于复杂,无法使用聚合框架的查询语言来表达,这时可以使用MapReduce。
MapReduce使用代码块中的操作作为“查询”,因此它能够表达任意复杂的逻辑。然而,这种强大是有代价的:MapReduce非常慢,不应该用在实时的数据分析中。
三、内嵌数据和引用数据
1、内嵌数据和引用数据之间的权衡
数据表示的方式有很多种,其中最重要的问题之一就是在多大程度上对数据进行范式化。
范式化(normalization)是将不同业务数据分散到多个不同的集合,不同集合之间可以相互引用数据。虽然很多文档可以引用某一块数据,但是这块数据只存储在一个集合中。所以,如果要修改这块数据,只需修改保存这块数据的那一个文档就行了。但是,MongoDB没有提供连接(join)工具,所以在不同集合之间执行连接查询需要进行多次查询。
举个例子,现在业务上假设mysql有一个文章表和评论表,我要查询和“python”相关的文章及其相关评论,在mysql中我可以执行一个join查询sql就达到目的。但是如果在mongdb中,假如我们的存储方式也像在mysql中的一样,将文章存到一个文章集合,将评论存到一个评论集合,那么我们需要执行2次查询,第一次先根据“python”关键词在文章集合中查到文章的id,再根据文章id到评论集合查到评论的内容。这是因为mongdb并不支持join查询。
反范式化(denormalization)与范式化相反:将每个文档所需的数据都嵌入在文档内部。每个文档都拥有自己的数据副本,而不是所以文档共同引用同一个数据副本。这意味着,如果信息发生了变化,那么所有相关文档都需要进行更新,但是在执行查询时,只需要一次查询,就可以得到所有数据。
还是上面的例子,反范式化就是将某个文章下所有评论内嵌到文章这个文档内部。这么一来就能只查询文章集合就得到文章和评论的内容。
决定何时采用范式化何时采用反范式化是比较困难的。范式化能够提高数据写入速度,反范式化能够提高数据读取速度。需要根据自己应用程序的实际需要仔细权衡。
例子1:
假设要保存学生和课程信息(每个学生要学的课是不同的,是个多对多关系)。一种表示方式是使用一个students集合(每个学生是一个文档)和一个classes课程集合(每门课程是一个文档)。然后用第三个集合studentClasses保存学生和课程之间的联系。
db.studentClasses.findOne({"studentId" : id})
{
"_id" : ObjectId("512512c1d86041c7dca81915"),
"studentId" : ObjectId("512512a5d86041c7dca81914"),
"classes" : [
ObjectId("512512ced86041c7dca81916"),
ObjectId("512512dcd86041c7dca81917"),
ObjectId("512512e6d86041c7dca81918"),
ObjectId("512512f0d86041c7dca81919")
]
}这就是一种范式化设计。
假设要找到一个学生所选的课程详情和学生详情。需要先查找students集合找到学生信息,然后根据学生id查询studentClasses找到课程"_id",最后再查询classes集合才能得到想要的信息。为了找出课程信息,需要向服务器请求三次查询。
可如果我们这样存储,将课程id嵌入在学生文档中,那么上面的需求就只需要2次查询:
{
"_id" : ObjectId("512512a5d86041c7dca81914"),
"name" : "John Doe",
"classes" : [
ObjectId("512512ced86041c7dca81916"),
ObjectId("512512dcd86041c7dca81917"),
ObjectId("512512e6d86041c7dca81918"),
ObjectId("512512f0d86041c7dca81919")
]
}如果需要进一步优化读取速度,可以将数据完全反范式化,将课程信息作为内嵌文档保存到学生文档的"classes"。
字段中,这样只需要一次查询就可以得到学生的课程信息了:
{
"_id" : ObjectId("512512a5d86041c7dca81914"),
"name" : "John Doe",
"classes" : [
{
"class" : "Trigonometry",
"credits" : 3,
"room" : "204"
},
{
"class" : "Physics",
"credits" : 3,
"room" : "159"
},
{
"class" : "Women in Literature",
"credits" : 3,
"room" : "14b"
},
{
"class" : "AP European History",
"credits" : 4,
"room" : "321"
}
]
}上面这种方式的优点是只需要一次查询就可以得到学生的课程信息,缺点是会占用更多的存储空间,而且数据同步更困难。例如,如果物理学的学分变成了4分(不再是3分),那么选修了物理学课程的每个学生文档都需要更新,而不只是更新“物理课”这一个文档。
最后,也可以混合使用内嵌数据和引用数据:将课程的常用信息嵌入到学生表中,需要查询更详细的课程信息时通过引用找到实际的文档:
{
"_id" : ObjectId("512512a5d86041c7dca81914"),
"name" : "John Doe",
"classes" : [
{
"_id" : ObjectId("512512ced86041c7dca81916"),
"class" : "Trigonometry"
},
{
"_id" : ObjectId("512512dcd86041c7dca81917"),
"class" : "Physics"
},
{
"_id" : ObjectId("512512e6d86041c7dca81918"),
"class" : "Women in Literature"
},
{
"_id" : ObjectId("512512f0d86041c7dca81919"),
"class" : "AP European History"
}
]
}也就是说,放入到内嵌文档中的应该是不经常修改,却经常查询的字段。
需要考虑信息更新更频繁还是信息读取更频繁,如果这些数据会定期更新,那么范式化(关联的方式)是比较好的选择。如果数据变化不频繁,反范式化是比较好的选择。
例如:范式化的一个例子可能会将用户和用户地址保存在不同的集合中。但是,人们几乎不会改变住址,所以不应该为了这种概率极小的情况(某人改变了住址)而牺牲每一次查询的效率。在这种情景下,应该将地址内嵌在用户文档中。
如果决定使用内嵌文档,更新文档时,需要设置一个定时任务(cron job),以确保所做的每次更新都成功更新了所有文档。例如,我们试图将更新扩散到多个文档,在更新完所有文档之前,服务器崩溃了。需要能够检测到这种问题,并且重新进行未完的更新。
一般来说,数据生成越频繁,就越不应该将这些数据内嵌到其他文档中。如果内嵌字段或者内嵌字段数量是无限增长的,那么应该将这些内容保存在单独的集合中,而不是内嵌到其他文档中。评论列表或者活动列表等信息应该保存在单独的集合中,不应该内嵌到其他文档中。
最后,如果某些字段是文档数据的一部分,那么需要将这些字段内嵌到文档中。如果在查询文档时经常需要将某个字段排除,那么这个字段应该放在另外的集合中,而不是内嵌在当前的文档中(也就是垂直分表的概念)。
使用内嵌数据与引用数据的比较:

如何设计一个存储方案以达到范式化和反范式化的平衡很重要。一旦初始规划错误,那么后面对表的维护会很麻烦。
以上原则不仅适用于mongdb,也同样适用于所有非关系型数据库的业务数据存储设计原则。
2、基数
一个集合中包含的对其他集合的引用数量叫做基数。常见的关系有一对一、一对多、多对多。
假如有一个博客应用程序。每篇博客文章(post)都有一个标题(title),这是一个一对一的关系。每个作者(author)可以有多篇文章,这是一个一对多的关系。每篇文章可以有多个标签(tag),每个标签可以在多篇文章中使用,所以这是一个多对多的关系。
在MongoDB中,many(多)可以被分拆为两个子分类:many(多)和few(少)。
例如,作者和文章之间可能是一对少的关系:每个作者只发表了为数不多的几篇文章。博客文章和标签可能是多对少的关系:文章总量实际上很可能比标签总量多。博客文章和评论之间是一对多的关系:每篇文章都可以拥有很多条评论。
只要确定了少与多的关系,就可以比较容易地在内嵌数据和引用数据之间进行权衡。通常来说,基数“少”的内容使用内嵌的方式会比较好,基数“多”的内容使用引用的方式比较好。
3、一些优化技巧
1. 优化文档增长
更新数据时,需要明确更新是否会导致文件体积增长,以及增长程度。如果增长程度是可预知的,可以为文档预留足够的增长空间,这样可以避免文档移动,可以提高写入速度。检查一下填充因子:如果它大约是1.2或者更大,可以考虑手动填充。
如果要对文档进行手动填充,可以在创建文档时创建一个占空间比较大的字段,文件创建成功之后再将这个字段移除。这样就提前为文档分配了足够的空间供后续使用。
假设有一个餐馆评论的集合,其中的文档如下所示:
{
"_id" : ObjectId(),
"restaurant" : "Le Cirque",
"review" : "Hamburgers were overpriced."
"userId" : ObjectId(),
"tags" : []
}
"tags"字段会随着用户不断添加标签而增长,应用程序可能经常需要执行这样的更新操作。可以在文档最后添加一个大字段(随便用什么名字)进行手工填充,如下所示:
{
"_id" : ObjectId(),
"restaurant" : "Le Cirque",
"review" : "Hamburgers were overpriced." "userId" : ObjectId(),
"tags" : [],
"garbage" : "........................................................"+
"................................................................"+
"................................................................"
}可以在第一次插入文档时这么做,也可以在upsert时使用"$setOnInsert"创建这个字段。
更新文档时,总是用"$unset"移除"garbage"字段。
db.reviews.update({"_id" : id},{"$push" : {"tags" : {"$each" : ["French", "fine dining", "hamburgers"]}}}, "$unset" : {"garbage" : true}})如果"garbage"字段存在,"$unset"操作符可以将其移除;如果这个字段不存在,"$unset"操作符什么也不做。
如果文档中有一个字段需要增长,应该尽可能将这个字段放在文档最后的位置("garbage"
之前)。这样可以稍微提高一点点的性能,因为如果"tags"字段发生了增长,MongoDB不需要重写"tags"后面的字段(不需要移动tags之后字段的位置)。
2. 删除旧数据
有些数据只在特定时间内有用:几周或者几个月之后,保留这些数据只是在浪费存储空间。有三种常见的方式用于删除旧数据:使用固定集合,使用TTL集合,或者定期删除集合。
使用固定集合:将集合大小设为一个比较大的值,当集合被填满时,将旧数据从固定集合中挤出。但是,固定集合会对操作造成一些限制,而且在密集插入数据时会大大降低数据在固定集合内的存活期。
使用TTL集合:TTL集合可以更精确地控制删除文档的时机。但是,对于写入量非常大的集合来说这种方式可能不够快:它通过遍历TTL索引来删除文档。如果TTL集合能够承受足够的写入量,使用TTL集合删除旧数据可能是最简单的方式了。
使用多个集合(分表):例如,每个月的文档单独使用一个集合。每当月份变更时,应用程序就开始使用新月份的集合(初始是个空集合),查询时要对当前月份和之前月份的集合都进行查询。对于6个月之前创建的集合,可以直接将其删除。这种方式可以应对任意的操作量,但是对于应用程序来说会比较复杂,因为需要使用动态的集合名称(或者数据库名称),也要动态处理对多个数据库的查询。
使用多个数据库时有一些限制:MongoDB通常不允许直接将数据从一个数据库移到另一个数据库。
例如,无法将在A数据库上执行MapReduce的结果保存到B数据库中,也无法使用renameCollection命令将集合从一个数据库移动到另一个数据库(比如,可以将foo.bar重命名为foo.baz,但是不能将foo.bar重命名为foo2.baz)。
3. 一致性管理
mongodb服务器为每个数据库连接维护一个请求队列。客户端每次发来的新请求都会添加到队列的末尾。入队之后,这个连接上的请求会依次得到处理。一个连接拥有一个一致的数据库视图,可以总是读取到这个连接最新写入的数据。
每个列队只对应一个连接:如果打开两个shell,连接到相同的数据库,这时就存在两个不同的连接,两个请求队列。如果在其中一个shell中执行插入操作,紧接着在另一个shell中执行查询操作,新插入的数据可能不会出现在查询结果中。
但是,如果是在同一个shell中,插入一个文档然后执行查询,一定能够查询到刚插入的文档。想手动重现这种问题是很困难的,但是在一个频繁执行插入和查询的服务器上很可能会发生。
经常会有一些开发者使用一个线程插入数据,然后使用另一个线程检查数据是否成功插入(两个连接,两个请求队列)。片刻之后,刚刚的数据看上去好像并没有成功插入,但是这些数据忽然就出现了。
使用Ruby、Python和Java驱动程序时尤其要注意这个问题,因为这三种语言的驱动程序都使用了连接池(connection pool)。为了提高效率,这些驱动程序会建立多个与服务器之间的连接(也就是一个连接池),将请求通过不同的连接发送到服务器。但是它们都有各自的机制来保证一系列相关连的请求会被同一个连接处理。
4. 不适合使用MongoDB的场景
MongoDB不支持下面这些应用场景:
- MongoDB不支持事务(transaction),对事务性有要求的应用程序不建议使用MongoDB(其实在新版的mongodb中已经能够支持事务操作)。如果非要使用事务将多个db操作打包为一个原子操作,可以在应用程序中使用锁来自己实现事务。
- 在多个不同维度上对不同类型的数据进行连接,这是关系型数据库善长的事情。MongoDB不支持这么做,以后也很可能不支持。
四、MongoDB 副本集
MongoDB复制功能指mongodb服务将部署到多个节点(一般来说一个节点会单独部署到一条机器)上,这些节点包含一个主节点和多个从节点,主节点接收客户端的写请求,从节点则复制和同步主节点的数据,从而使得每个节点都有完整数据集的所有数据,即使一个或多个节点出错崩溃,也可以保证应用程序正常运行和数据安全。
在MongoDB中,创建一个副本集之后就可以使用复制功能了。
副本集是一组服务,其中有一个主服务(primary),用于处理客户端请求(主节点)。还有多个备份服务(secondary),用于保存主服务的数据副本(从节点)。如果主服务崩溃了,备份服务会自动将其中一个成员升级为新的主服务。
1、创建单机MongoDB副本集
下面正式实操一个mongodb的副本集例子(需要以/data/db为数据的存储路径,请确保该路径存在却权限为777)。
通过执行下面的命令就可以创建一个副本集,由于使用的是ReplSetTest测试类,因此该副本集的所有节点都在同一台机器上。
PS:ReplSetTest是用于测试mongodb的复制和副本功能的类,上线时创建副本集并不适用此命令。这些设置不适用于生产环境,但是可以让你熟悉复制功能以及相关的各种配置。
replicaSet = new ReplSetTest({"nodes" : 3})这行代码可以创建一个包含三个mongodb服务的副本集:一个主节点和两个备份节点。
执行下面两个命令之后mongod服务才会真正启动:
replicaSet.startSet() // 启动3个mongod进程
replicaSet.initiate() // 配置复制功能现在已经有了3个mongod进程,分别运行在2000、20001和20002端口。其中,主节点2000接收写请求,其他两个节点会同步主节点2000的数据,因此整个副本集会保持有3份独立完整的数据。
这3个进程都会把各自的日志输出到当前shell中,这会让人很混乱。所以要开启一个新的shell用于工作。
在第二个shell中连接到运行在20000端口的mongod:
> conn1 = new Mongo("localhost:31000")
connection to localhost:31000
> primaryDB = conn1.getDB("test") // 从conn1这个连接的节点中获取test这个库。当前shell连接的其实还是27017端口的那个mongod服务,此时db变量其实也还是27017的库。primaryDB才是20000服务下的库
test可以看到副本集的状态:
> primaryDB.isMaster()
{
"topologyVersion" : {
"processId" : ObjectId("604968c1f3cc49361376e293"),
"counter" : NumberLong(8)
},
"hosts" : [
"VM-0-13-centos:20000",
"VM-0-13-centos:20001",
"VM-0-13-centos:20002"
],
"setName" : "__unknown_name__",
"setVersion" : 3,
"ismaster" : true,
"secondary" : false,
"primary" : "VM-0-13-centos:20000",
"me" : "VM-0-13-centos:20000",
"electionId" : ObjectId("7fffffff0000000000000001"),
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(1615423820, 1),
"t" : NumberLong(1)
},
"lastWriteDate" : ISODate("2021-03-11T00:50:20Z"),
"majorityOpTime" : {
"ts" : Timestamp(1615423820, 1),
"t" : NumberLong(1)
},
"majorityWriteDate" : ISODate("2021-03-11T00:50:20Z")
},
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 100000,
"localTime" : ISODate("2021-03-11T00:55:54.169Z"),
"logicalSessionTimeoutMinutes" : 30,
"connectionId" : 22,
"minWireVersion" : 0,
"maxWireVersion" : 9,
"readOnly" : false,
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1615423820, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1615423820, 1)
}"ismaster" : true指明了这是一个主节点,副本集中还有一个hosts列表。
"ismaster" : false,也是正常的。可以从"primary"字段获知主节点是哪一个,然后重新连接到主节点所在的主机/端口就可以了。
既然已经连接到主节点,就做一些写入操作看看会有什么发生吧!
首先,插入1000个文档:
> primarydb.createCollection("zbp")
> zbp = primarydb.zbp
> for(i=0;i<1000;i++){zbp.insert({count:i})}
> zbp.count() // 1000此时再连接到20001这个服务,并查看信息:
conn2 = new Mongo("localhost:20001")
secondarydb = conn2.getDB("test")
secondarydb.isMaster() // ismaster为false,是从节点
zbp2 = secondarydb.zbp
zbp2.find() // 尝试在从节点查询刚刚在主节点插入的数据结果返回报错:
error: {
"$err" : "not master and slaveok=false",
"code" : 13435
}报错的原因是:为防止备份节点(的数据)可能会落后于主节点,从而导致应用程序意外拿到过期的数据,备份节点在默认情况下会拒绝读取请求。
如果希望从备份节点读取数据,需要设置“从备份节点读取数据没有问题”标识,如下所示:
> conn2.setSecondaryOk()slaveOk是对连接(例子中是conn2)设置的,不是对数据库(secondaryDB)设置的,因此如果你用一个新的连接读取数据时需要再调用一次setSecondaryOk()方法。现在就可以从这个备份节点中读取数据了。
现在试着在conn2上执行写入操作:
secondaryDB.coll.insert({"count" : 1001})结果报错:
WriteCommandError({
"topologyVersion" : {
"processId" : ObjectId("604968c176e0e68c94537666"),
"counter" : NumberLong(4)
},
"operationTime" : Timestamp(1615424461, 107),
"ok" : 0,
"errmsg" : "not master",
"code" : 10107,
"codeName" : "NotWritablePrimary",
"$clusterTime" : {
"clusterTime" : Timestamp(1615424461, 107),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
})可以看到,不能对备份节点执行写操作。备份节点只通过复制功能写入数据,不接受客户端的写入请求。
mongodb的副本集能够自动故障转移,如果主节点挂了,其中一个备份节点会自动选举为主节点。接下来我们模拟下这个过程:
primarydb.adminCommand({"shutdown":1}) // 关闭20000的主节点
> secondaryDB.isMaster() // 此时20001晋升主节点第一个检测到主节点挂了的备份节点会成为新的主节点。
现在回到第一个shell,执行下面的命令关闭副本集(这个shell中现在应该充满了大量的副本集成员输出日志,不过敲几次Enter键之后就可以看到命令提示符了)。
> replicaSet.stopSet()有几个关键的概念需要注意:
客户端在任意一个节点上可以执行的请求,都可以发送到主节点执行(如读、写、执行命令、创建索引等)。
客户端不能在备份节点上执行写操作。
默认情况下,客户端不能从备份节点中读取数据。在备份节点上显式地执行setSecondaryOk之后,客户端就可以从备份节点中读取数据了。
2、创建多机MongoDB副本集
上面的例子是在一台机器上部署多个副本集,下面我们会在多台机器上建立复制功能。
只有一台机器的朋友可以在一个机器上开启多个mongd进程来模拟多机器的mongd副本集,但是多个mongd进程需要绑定不同的接口(27017,27018,...),而且指定不同的数据目录(/data/db1,/data/db2,...),否则在启动服务时会报错。同一机器上两个端口不同的mongd进程不能共用一个数据目录。
假设你有一个运行在server-1:27017上的单个mongod实例(或者没有也可以),使用--replSetname选项重启server-1的mongodb服务。
# mongod --port "YOUR_PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "YOUR_REPLICA_SET_INSTANCE_NAME" -f mongod.conf --fork
mongod --replSet zbpset --fork --logpath=/var/log/mongodb/mongod.log通过上述命令,我们在server-1这台机器上启动了一个名为 zbpset 的副本集,当然这条命令只启动了副本集的一个mongodb节点。
其中 --fork 表示后台运行(用--fork的时候必须使用--logpath指定日志的位置),当然是用 nohup &也可以后台运行。 --relSet 后接自定义的集合实例名称。mongodb的配置文件路径在yum安装下一般是/etc/mongod.conf。
使用同样的replSet和集合实例名称启动另1个服务器(下面会把它称作机器server-2)作为副本集中的其他成员。
如果不想在命令行添加那么多选项,可以将这些选项写在配置文件中。
# /root/mongdb.conf
logpath=/var/log/mongodb/mongod.log
logappend=true
port=27017
fork=true
dbpath=/data/db
replSet=zbpset
auth=true # 要进行密码权限验证
keyFile=/root/keyfile # 用于密码和权限验证的证书,可以通过openssl rand -base64 90 -out /root/keyfile生成,设置权限为600
bind_ip=0.0.0.0 # 允许其他ip远程连接(否认节点与节点之间同步会失败),不过一定要设置新用户的密码和权限验证,否则可能被攻击此时只需在启动时指定配置文件即可加载所有配置项即可。
mongod --config=/root/mongdb.conf现在应该有2个分别运行在不同服务器上的mongod实例了。但是,每个mongod都不知道有其他mongod存在,而且也没有区分谁是主节点谁是从节点。
为了让每个mongod能够知道彼此的存在,需要创建一个用于同步的配置文件,在配置文件中列出每一个成员,并且将配置文件发送给server-1,然后server-1会负责将配置文件传播给其他成员。(此时server-1和server-2有相同的keyfile,因此二者同步的时候会自动校验权限。即使不设置新用户二者也可以成功同步,但是不设置新用户且bind_ip=0.0.0.0的话,就很可能被攻击)。
首先创建这个用于同步的副本集配置文件。在server-1的mongo shell中,创建一个如下所示的副本集配置:
config = {
"_id" : "zbpset", // 副本集名称
"members" : [
// 下面server-1和server-2请替换为自己的机器ip
{"_id" : 0, "host" : "server-1:27017"},
{"_id" : 1, "host" : "server-2:27017"},
]
}
rs.initiate(config) // 对副本集进行初始化
rs.status() // 查看副本集的状态
rs.config() // 查看副本集的配置server-1会解析这个配置对象,然后向其他成员发送消息,提醒它们使用新的配置。所有成员都配置完成之后,它们会自动选出一个主节点,然后就可以正常处理读写请求了。
如何区分哪个服务是主节点呢?
只要看到命令行的标头就行:
zbpset:SECONDARY> 从节点
zbpset:PRIMARY> 主节点从节点不能进行写操作。而且想要在从节点进行读取,必须先执行rs.secondaryOk(),否则从节点也是不能读取的。
副本集所有的成员都可以接受读操作。但是,默认情况下,读请求都是会将读操作直接定向至主节点。
几个注意点:
- 在启动副本集的mongd服务之前,先起一个普通的(非副本集内的)mongd服务,然后设置新用户用于权限验证(如果已经有可以用于权限验证的用户可以忽略这条)。然后再执行mongd --config=/root/mongdb.conf启动副本集的mongd服务,并用db.auth()进行登录。另外登录的时候,需要在你创建用户的库登录,例如如果你是在admin这个库创建的用户A,那么下次进入命令行并希望读写test库的内容时,必须先切到admin这个库用用户A登录(在test库登录会失败,因为test库没有A这个用户),再切回test库进行操作才能成功。
- 启动mongd后,请用ps和netstat命令查看mongd是否正常启动,有时候用ps命令看到mongd进程已经起来了,但是用netstat查看27017并没有被占用,那么其实mongd还是没有正常开启。如果mongd没有正常开启请查看错误原因,一般错误原因errmsg会直接在命令行显示,但是如果使用了--fork选项,就只能在日志文件(该日志文件的位置是自定义的)查看。
- 必须使用mongo shell来配置副本集。没有其他方法可以基于文件对副本集进行配置。
- 如果多个节点所在的机器都设置了keyfile和bind_ip=0.0.0.0的情况下没有通信成功,此时可能是各自mongd进程的端口没有对外开放,只需开放mongd进程的端口的防火墙即可。
rs辅助函数
注意上面的rs.initiate()命令中的rs。rs是一个全局变量,其中包含与复制功能相关的辅助函数(可以执行rs.help()查看可用的辅助函数)。
副本集内的每个成员都必须能够连接到其他所有成员(包括自身)。
另外,副本集的配置中不应该使用localhost作为主机名而应该使用ip作为主机名。如果所有副本集成员都运行在同一台机器上,那么localhost可以被正确解析,但是运行在一台机器上的副本集意义不大;如果副本集是运行在多台机器上的,那么localhost就无法被解析为正确的主机名。
修改副本集配置
可以随时修改副本集的配置:可以添加或者删除成员,也可以修改已有的成员。
rs.add("server-4:27017") // 添加节点
rs.remove("server-1:27017") // 删除节点,该操作可能会导致整个副本集短暂的无法连接或写入也可以以文档的形式为新成员指定更复杂的配置:
rs.add({"_id" : 5, "host" : "spock:27017", "priority" : 0, "hidden" : true})删除成员时(或者是除添加成员之外的其他改变副本集配置的行为),会在shell中得到很多无法连接数据库的错误信息。这是正常的,这实际上说明配置修改成功了。重新配置副本集时,作为重新配置过程的最后一步,主节点会关闭所有连接。因此,shell中的连接会短暂断开,然后重新自动建立连接。
重新配置副本集时,主节点需要先退化为普通的备份节点,以便接受新的配置,然后会恢复。要注意,重新配置副本集之后,副本集中会暂时没有主节点,之后会一切恢复正常。
可以在shell中执行rs.config()来查看配置修改是否成功:
> rs.config()
{
"_id" : "testReplSet", "version" : 2,
"members" : [
{
"_id" : 1,
"host" : "server-2:27017"
},
{
"_id" : 2,
"host" : "server-3:27017"
},
{ "_id" : 3,
"host" : "server-4:27017"
}
]
}每次修改副本集配置时,"version"字段都会自增,它的初始值为1。
除了对副本集添加或者删除成员,也可以修改现有的成员。为了修改副本集成员,可以在shell中创建新的配置文档,然后调用rs.reconfig。假设有如下所示的配置:
> rs.config()
{
"_id" : "testReplSet",
"version" : 2,
"members" :
[
{
"_id" : 0,
"host" : "server-1:27017"
},
{
"_id" : 1,
"host" : "10.1.1.123:27017"
},
{
"_id" : 2,
"host" : "server-3:27017"
}
]
}其中"_id"为1的成员地址用IP而不是主机名表示,需要将其改为主机名表示的地址。
首先在shell中得到当前使用的配置,然后修改相应的字段:
> var config = rs.config()
> config.members[1].host = "server-2:27017"
> rs.reconfig(config) // 需要使用rs.reconfig辅助函数将新的配置文件发送给数据库对于复杂的数据集配置修改,rs.reconfig通常比rs.add和rs.remove更有用,比如修改成员配置或者是一次性添加或者删除多个成员(add和remove只能增加和删除1个节点,不能是多个)。
可以使用rs.reconfig命令做任何合法的副本集配置修改:只需创建想要的配文档然后对其调用rs.reconfig。
3、选举机制
当一个备份节点无法与主节点连通时,它就会联系并请求其他的副本集成员将自己选举为主节点。其他成员会做几项理性的检查:自身是否能够与主节点连通?希望被选举为主节点的备份节点的数据是否最新?有没有其他更高优先级的成员可以被选举为主节点?
如果要求被选举为主节点的成员能够得到副本集中“大多数”成员的投票,它就会成为主节点。即使“大多数”成员中只有一个否决了本次选举,选举就会取消。如果成员发现任何原因,表明当前希望成为主节点的成员不应该成为主节点,那么它就会否决此次选举。
在日志中可以看到得票数为比较大的负数的情况,因为一张否决票相当于扣掉10000张赞成票。如果某个成员投赞成票,另一个成员投否决票,那么就可以在消息中看到选举结果为-9999或者是比较相近的负数值。
每个成员都只能要求自己被选举为主节点。简单起见,不能推荐其他成员被选举为主节点,只能为申请成为主节点的候选人投票。
1. 成员配置选项
有时我们并不希望每个成员都完全一样。你可能希望让某个成员拥有优先成为主节点的权力,或者是让某个成员对客户端不可见,这样便不会有读写请求发送给它。在副本集配置的子文档中可以为每个成员指定这些选项。
2. 选举仲裁者
一般而言,副本集中的节点数会在3及以上,2个节点的副本集在选举上会有一定的缺陷。如果我们的应用对复制的要求不高,真的只用2台节点存储数据的话,我们可以设置一个“仲裁者”节点来帮助选举。仲裁者的唯一作用就是参与选举。仲裁者并不保存数据,也不会为客户端提供服务,所以可以将仲裁者作为轻量级进程,运行在配置比较差的服务器上。
启动仲裁者与启动普通mongod的方式相同,使用"--replSet 副本集名称"和空的数据目录。再使用rs.addArb()辅助函数将仲裁者添加到副本集中:
rs.addArb("server-5:27017")也可以不用rs.addArb(),而是用rs.add()并指定arbiterOnly选项,这与上面的效果是一样的:
rs.add({"_id" : 4, "host" : "server-5:27017", "arbiterOnly" : true})成员一旦以仲裁者的身份添加到副本集中,它就永远只能是仲裁者:无法将仲裁者重新配置为非仲裁者,反之亦然。
使用仲裁者的另一个好处是:如果你拥有的节点数是偶数,那么可能会出现一半节点投票给A,但是另一半成员投票给B的情况。仲裁者这时就可以投出决定胜负的关键一票。
使用仲裁者的注意点:
只有在mongodb的节点数为偶数是才需要设置仲裁者,因为仲裁者的设置目的就是为了帮助选举,而奇数数量的节点不会有选举困难,因此不需要仲裁者节点。仲裁者的目的应该是避免出现平票,而不是导致出现平票。
而且最多只能使用一个仲裁者。
一个副本集最多可以有50个成员,但仅能有7个可投票成员。如果一个副本集的成员个数大于6的情况下为偶数其实也不会造成选举困难,因为如果成员数为偶数,可投票成员也会只有7个。
建议:尽量避免使用仲裁者,而是使用奇数的副本集。
3. 优先级
优先级用于表示一个成员渴望成为主节点的程度。
优先级的取值范围可以是0~100,默认是1。
将优先级设为0有特殊含义:优先级为0的成员永远不能够成为主节点只能作为备份节点或从节点。这样的成员称为被动成员(passive member)。
拥有最高优先级的成员会优先选举为主节点(但前提是它的数据是最新的,如果一个优先级低的成员比一个优先级高的成员的数据新那么这个优先级低的成员会成为主节点)。
另外,只有主节点down掉的时候从节点才会开始选举新的主节点(但是有时候可能是主节点没down掉,但是由于网络原因从节点无法及时和主节点通信,从节点也会认为主节点down掉而开始选举)。
假如在副本集中添加了一个优先级为1.5的成员:
> rs.add({"_id" : 4, "host" : "server-4:27017", "priority" : 1.5})假设其他成员的优先级都是1,只要server-4拥有最新的数据,那么当前的主节点就会自动退位,server-4会被选举为新的主节点。
如果server-4的数据不够新,那么当前主节点就会保持不变。设置优先级并不会导致副本集中选不出主节点,也不会使数据不够新的成员成为主节点。
4. 隐藏成员
很多人会将不够强大的服务器或者备份服务器隐藏起来成为隐藏成员,隐藏成员无法接收读请求,但是可以同步数据作为备份服务。客户端不会向隐藏成员发送请求,隐藏成员也不会作为复制源(尽管当其他复制源不可用时隐藏成员也会被使用)。
假设有一副本集如下所示:
> rs.isMaster()
{
"hosts" : [
"server-1:27107",
"server-2:27017",
"server-3:27017"
],}为了隐藏server-3,可以在它的配置中指定hidden : true。只有优先级为0的成员才能被隐藏(不能将主节点隐藏):
> var config = rs.config()
> config.members[2].hidden = 0
> config.members[2].priority = 0
> rs.reconfig(config)现在,执行isMaster()。
可以看到:
> rs.isMaster()
{
"hosts" : [
"server-1:27107",
"server-2:27017"
],
}使用rs.status()和rs.config()能够看到隐藏成员,隐藏成员只对isMaster()不可见。
客户端连接到副本集时,会调用isMaster()来查看可用成员。因此,隐藏成员不会收到客户端的读请求(隐藏成员只能作为备份节点而不接收读请求)。
要将隐藏成员设为非隐藏,只需将配置中的hidden设为false就可以了,或者删除hidden选项。
5. 延迟备份节点
数据可能会因为人为错误而遭受毁灭性的破坏:例如可能有人不小心删除了主数据库(此时从节点因为同步,也会删掉数据)。
为了防止这类问题,可以使用slaveDelay设置一个延迟的备份节点。
延迟备份节点的数据会比主节点延迟指定的时间(单位是秒),这是有意为之。这样,如果有人不小心摧毁了你的主集合,还可以将数据从先前的备份中恢复过来。
slaveDelay要求成员的优先级是0。而且最好应该将延迟节点用hidden隐藏掉,否则当读请求被路由到延迟节点时就会查到延迟的数据而导致数据不一致问题。
6. 备份节点不创建索引
有时,备份节点并不需要与主节点拥有相同的索引,甚至可以没有索引。
如果某个备份节点的用途仅仅是处理数据备份或者是离线的批量任务,那么你可能希望在它的成员配置中指定"buildIndexs" : false。这个选项可以阻止备份节点创建索引。
这是一个永久选项,指定了"buildIndexes" : false的成员永远无法恢复为可以创建索引的“正常”成员。如果确实需要将不创建索引的成员修改为可以创建索引的成员,那么必须将这个成员从副本集中移除,再删除它的所有数据,最后再将它重新添加到副本集中,让它重新进行数据同步。
另外,这个选项也要求成员的优先级为0。
4、副本集的复制原理
1. Oplog
MongoDB的复制功能是通过操作日志oplog实现的,操作日志包含了主节点的每一次写操作。oplog是主节点的local数据库中的一个固定集合。备份节点通过查询主节点的这个集合就可以知道需要进行复制的写操作。
每个备份节点都维护着自己的oplog,记录着每一次从主节点复制数据的操作。这样,每个成员都可以作为同步源提供给其他成员使用(也就是说一个从节点不仅可以通过主节点的oplog同步数据,也能通过其他从节点的oplog同步数据,主节点和从节点都可以成为同步源),默认是以主节点作为同步源。
备份节点从当前使用的同步源中获取需要执行的操作,然后在自己的数据集上执行这些操作,最后再将这些操作写入自己的oplog(先执行操作,再写入自己的oplog)。如果遇到某个操作失败的情况(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),那么备份节点就会停止从当前的同步源复制数据。
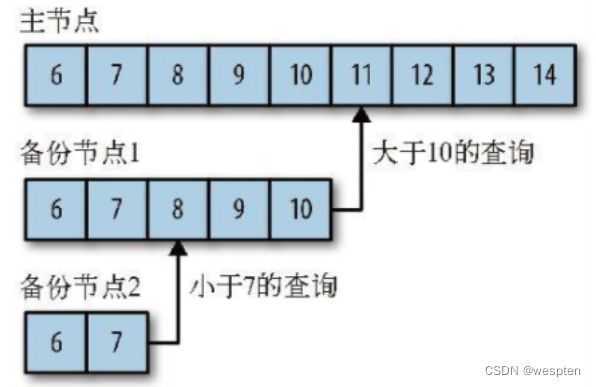
如上图所示,上面的3个链表(循环链表)就是oplog日志,里面的每一个元素就是一次写操作。
oplog中按顺序保存着所有执行过的写操作。每个成员都维护着一份自己的oplog,每个成员的oplog都应该跟主节点的oplog完全一致(尽管可能会有延迟)。
节点1以主节点作为同步源进行同步,他只会复制主节点的oplog的id号大于节点2的id号的操作。节点2则以节点1为同步源。
由于oplog大小是固定的,它只能保存特定数量的操作日志。但从MongoDB 4.0开始,oplog还是固定集合但可以其内容超过其配置的大小限制。
通常oplog使用空间的增长速度与系统处理写请求的速率近乎相同:如果主节点上每分钟处理了1 KB的写入请求,那么oplog很可能也会在一分钟内写入1 KB条操作日志。
但是有一些例外情况:如果单次请求能够影响到多个文档(比如删除多个文档或者是多文档更新),oplog中就会出现多条操作日志,每个受影响的文档都会对应oplog中的一条日志。因此,如果执行db.coll.remove()删除了1 000 000个文档,那么oplog中就会有1 000 000条操作日志,每条日志对应一个被删除的文档。如果执行大量的批量操作,oplog很快就会被填满。
2. 同步流程
1)初始化同步
首先一个成员会选择其他的一个成员作为同步源,在local.me中为自己创建一个标识符,删除所有已存在的数据库,以一个全新的状态开始进行同步。在这个过程中,所有现有的数据都会被删除。
然后是克隆,将同步源的除local数据库的所有库的所有记录全部复制到本地(全量复制)。这通常是整个过程中最耗时的部分。克隆过程中的所有操作都会被记录到oplog中。
克隆完成后,会开始在从节点建立索引。
在全量复制和建立索引的过程中(由于这个过程会很久),同步源如果执行了新的操作,新成员是无法在这个过程中同步这些新操作的,只能在新成员完成了全量复制和建立索引之后才能同步这些新操作。这会导致新成员的数据同步速度赶不上同步源的变化速度,产生数据不一致问题。这个问题被称为脱节。而且在全量复制的过程中,读写请求会变慢,所以为了避免脱节和初始化复制带来的性能下降的影响,尽可能在夜深人静的时候完成这一步(在夜深人静的时候添加新节点)。
PS:在3.4版本以后,初始化同步会获取在数据复制期间新增的oplog记录,因此即使在初始化同步过程中同步源执行了新的操作,这些操作也能被同步,不过要确保oplog足够大。
当完成全初始化同步之后,备份节点就会开始同步同步源的oplog日志(相当于增量复制)。
2)复制
从节点成员在初始化同步之后会不断地复制数据。从节点成员从同步源复制oplog ,并以异步的方式应用这些操作。从节点可以根据ping时间和其他成员复制状态的变化,按需来自动调整它们的同步源,但是从节点应避免从延迟成员和隐藏成员中同步数据。
如果一个从节点成员的参数members[n].buildIndexes 设置为true,它只能从其他参数buildIndexes设置为true的成员同步数据。参数buildIndexes设置为false的成员可以从任何其他节点同步数据。参数buildIndexes默认为true。
3)陈旧的从节点
如果备份节点远远落后于同步源当前的操作(同步源的oplog已经优先了备份节点整整一轮以上,即同步源oplog与备份节点oplog已经没有任何重合的情况),那么这个备份节点就是陈旧的。
导致备份节点陈旧的原因:
由于网络原因导致备份节点较长时间内无法同步同步源。或者备份节点由于故障较长时间的停机。
由于读请求过于频繁导致同步不及时。
当一个备份节点陈旧之后,它会查看副本集中的其他成员的oplog,如果其他成员的oplog足够详细可以补足该备份节点拉(la)下的操作,就会从这个成员进行同步。如果任何一个成员的oplog都没有参考价值,那么这个备份节点的复制操作就会中止,需要重新进行完全同步(这样会消耗大量时间和额外的系统性能)。
为了避免陈旧备份节点的出现和重新完全同步,可以让主节点使用比较大的oplog固定集合保存足够多的操作日志。
4)心跳
每个成员都需要知道其他成员的状态:哪个是主节点?哪个可以作为同步源?哪个挂掉了?为了能和其他成员通信,每个成员每隔2秒钟就会向其他成员发送一个心跳请求。心跳请求的信息量非常小,用于检查每个成员的状态。
发送的心跳请求会将自身的状态告诉其他成员,会有以下几种状态:
STARTUP:成员刚启动时处于这个状态。
STARTUP2:整个初始化同步过程都处于这个状态。在这个状态下,MongoDB会创建几个线程,用于处理复制和选举,然后就会切换到RECOVERING状态。
RECOVERING:这个状态表明成员运转正常,但是暂时还不能处理读取请求。脱节时,也会进入RECOVERING状态。
ARBITER:仲裁者应该始终处于ARBITER状态。
DOWN:如果一个正常运行的成员变得不可达,它就处于DOWN状态(可能是由于故障停机或网络原因无法与其他成员通信)。
UNKNOWN:同DOWN
REMOVED:当成员被移出副本集时,它就处于这个状态。如果被移出的成员又被重新添加到副本集中,它就会回到“正常”状态。
ROLLBACK:成员正在进行数据回滚
FATAL:如果一个成员发生了不可挽回的错误,也不再尝试恢复正常的话,它就处于FATAL状态。
这时,通常应该重启服务器,进行重新同步。
5)选举
当一个成员无法到达主节点时(如主节点故障或网络原因导致成员无法接收到主节点的心跳),它就会申请被选举为主节点。
希望被选举为主节点的成员,会向它能到达的所有成员发送通知。如果这个成员不符合候选人要求,如这个成员的数据落后于副本集,或者是已经有一个运行中的主节点。在这些情况下,其他成员不会允许其进行选举。
另外,副本集被重新配置也会导致主节点退位。
假如网络状况良好,“大多数”服务器也都在正常运行,那么选举过程是很快的。如果主节点不可用,2秒钟(之前讲过,心跳的间隔是2秒)之内就会有成员发现这个问题,然后会立即开始选举,整个选举过程只会花费几毫秒。
但是,实际情况可能不会这么理想:网络问题,或者是服务器过载导致响应缓慢,都可能触发选举。在这种情况下,心跳会在最多20秒之后超时。如果选举打成平局,每个成员都需要等待30秒才能开始下一次选举。所以,如果有太多错误发生的话,选举可能会花费几分钟的时间。
6)回滚
如果主节点执行了一个写请求之后挂了,但是备份节点还没来得及复制这次操作,然后又选举出来了一个新的主节点,那么新选举出来的主节点就会漏掉这次写操作。
如下所示, A和B处于一个数据中心,CDE处于另一个数据中心,两个数据中心可能处于两个不同的网络环境:

A是主节点,在执行完126操作之后down掉,B同步成功了126,但CDE没有同步到126。
之后,由于DC1这个数据中心只有1个B节点而且由于网络原因B暂时无法和CDE通信,所以B不满足“大多数”的选举条件而无法晋升为主节点(假如B能与CDE通信,那么B会由于拥有最新数据而晋升主节点),于是C晋升为主节点,这个新的主节点会继续处理后续的写入操作。
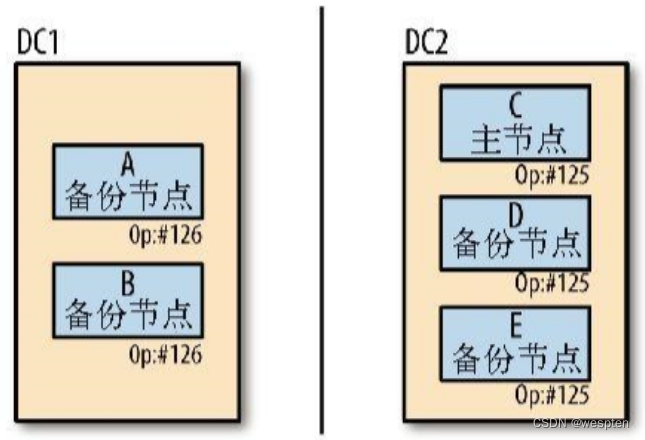
网络恢复之后,左边数据中心的服务器就会C开始同步126之后的操作,但是无法找到这个操作。这种情况发生的时候,A和B会进入回滚(rollback)过程。回滚会将失败之前的126操作撤消,然后定位到AB与C共有的125操作,从125操作继续同步。
这些被回滚的数据并不会丢失,而是会被写入到一个.bson的文件并存到数据目录(/data/db)下的rollback目录中。如果回滚的是一个更新操作(例如126操作是更新了集合col1的id=10005的文档),那么更新后id为10005的文档写入到rollback目录的col1.bson中。然后从C复制id=10005的文档到A和B,然后继续同步C后面的126,127,128...的操作。
回滚过程中,A和B会进入RECOVERING状态,此时AB无法接受读写请求。可以将回滚的操作重新应用到当前主节点C,具体操作可以查阅资料。
如果要回滚的内容太多,MongoDB可能承受不了。如果要回滚的数据量大于300 MB,或者要回滚30分钟以上的操作,回滚就会失败。对于回滚失败的节点,必须要重新同步(全量复制)。
这种情况最常见的原因是原备份节点C远远落后于原主节点A,而这时主节点A却挂了。然后C点成为主节点,这个主节点与旧的主节点相比,缺少很多操作。
为了保证成员A不会在回滚中失败,最好的方式是保持备份节点CDE的数据尽可能最新。
5、客户端连接副本集
连接副本集与连接单台服务器非常像。在驱动程序中使用与MongoClient等价的对象,并且提供一个希望连接到的副本集种子列表。种子是副本集成员。并不需要将所有成员都列出来(虽然可以这么做):驱动程序连接到某个种子服务器之后,就能够得到其他成员的地址。一个常用的连接字符串如下所示:
"mongodb://server-1:27017,server-2:27017"具体可以查看相关的驱动程序文档。
当主节点挂掉之后,驱动程序会尽快自动找到新的主节点。如果没有可达的主节点,应用程序就无法执行写操作。
通常,驱动程序没有办法判断某次操作是否在服务器崩溃之前成功处理,但是用户的应用程序可以自己实现相应的解决方案。比如,如果驱动程序发出插入{"_id" : 1}文档的请求之后收到主节点崩溃的错误,连接到新的主节点之后,可以查询主节点中是否有{"_id" : 1}这个文档然后决定是否重新插入。
将读请求发送到备份节点
默认情况下,驱动程序会将所有的读写请求都路由到主节点。但很有时候我们认为可以将读请求路由到从节点来减轻主节点处理高并发请求的压力(但这种情况下作者更推荐使用分片代替复制来解决服务器分担负载的问题)。
其实作者并不推荐将读请求路由到从节点,但实际上在某些特殊情况下我们还是会这么做。
如何设置从节点能够接收读请求呢?对于mongo客户端,我们设置 rs.secondaryOk() 即可。对于其他的应用程序客户端,如python、php、Nodejs和Java等,我们需要具体查看他们mongodb扩展和api的文档。
1. 出于一致性考虑(不推荐将读请求路由到从节点)
对一致性要求非常高的应用程序不应该从备份节点读取数据。
备份节点通常会落后主节点几毫秒,但是不能保证一定是这样。有时,由于加载问题、配置错误、网络故障等原因,备份节点可能会落后于主节点几分钟、几个小时甚至几天。
如果应用程序需要读取它自己的写操作(例如,先插入一个文档,然后再查询它),那么不应该将读请求发送给备份节点。否则的话,可能会出现应用程序成功执行了一次写操作,却读不到这个值的情况。要知道客户端发送请求的速度可能会比备份节点复制操作的速度要快。
为了能够始终将读请求发送给主节点,需要将读选项设置为Primary(或者不管它,默认就是Primary)。
2. 出于负载的考虑(不推荐将读请求路由到从节点)
许多用户会将读请求发送给备份节点,以便实现负载均衡。这种情况下,设置的从节点数应该在负载极限之上更多一些。例如你的服务器每秒只能处理10 000次查询,而你需要进行30 000次/秒的查询,可能就需要设置4个备份节点,并且让它们分担一些数据加载的工作。此时每个备份节点的负载是75%。
后来,某一个备份节点崩溃了。
现在剩余的每个成员的负载都是100%。如果需要恢复刚刚崩溃的成员,它就需要从其他成员处复制数据(全量复制),这就会导致其他成员过载。服务器过载经常导致性能变慢,副本集性能进一步降低,然后强制其他成员承担更多的负载,导致这些成员变得更慢,这是一个恶性死循环。
此时应该使用5台服务器,而不是4台,这样如果一台服务器崩溃,并不会导致副本集过载。但是,即使你的计划非常完美,仍然需要处理其他服务器负载过大的情况。
一个更好的选择是,使用分片作分布式负载。
3. 故障转移时保证查询可用(推荐将读请求路由到从节点)
在某些情况下,将读请求发送给备份节点是合理的。例如,你可能希望应用程序在主节点挂掉时(而新的主节点被选举出来前)仍然能够执行读操作(而且你并不在意读到的数据是否是最新的)。这是最常见的将读请求发给送备份节点的原因:失去主节的时,应用程序进入只读状态。这种读选项叫做主节点优先(primary preferred)。
primary preferred在主节点正常是会将所有读请求路由到主节点,在主机点down掉时将读请求路由到从节点。
primary是无论主节点是否正常都将读请求路由到主节点。
从备份节点读取数据有一个常见的参数是获得低延迟的数据。可以将读选项设置为Nearest,以便将请求路由到延迟最低的成员(根据驱动程序到副本集成员的ping时间最短的)。
如果应用程序能够接受任何陈旧程序的数据,那就可以使用Secondary或者Secondary preferred读选项。
Secondary始终会将读请求发送给备份节点。如果没有可用的备份节点,请求就会出错,而不是重新将读请求发送给主节点。对于不在乎数据新旧程度并且希望主节点只处理写请求的应用程序来说(读写分离),这是一种可行的方式。如果对于数据新旧程度有要求,不建议使用这种方式。
Secondary preferred会优先将读请求路由到可用的备份节点。如果备份节点都不可用,请求就会被发送到主节点。
有时,读负载与写负载完全不同:读到的数据与写入的数据是完全不同的。为了做离线处理,你可能希望创建很多索引,但是又不想将这些索引创建在主节点上。在这种情况下,可以设置一个与主节点拥有不同索引的备份节点。如果希望以这种方式使用备份节点,最好是使用驱动程序创建一个直接连接到目标备份节点的连接,而不是连接到副本集。
应该根据应用程序的实际需要选择合适的选项。
可以将多个选项组合在一起使用:如果某些读请求必须从主节点读取数据,那就对这些请求使用Primary选项。如果另一些读请求并不要求数据是最新的,那么可以对这些读请求使用Primary preferred选项。如果某些请求对低迟延的要求大过一致性要求,那么可以使用Nearest选项。
上面这些 Primary/Primary preferred/Nearest/Secondary/Secondary preferred 参数也可以在启动mongod服务时通过参数initialSyncSourceReadPreference参数设置(版本4.2.7中的新参数),不过该参数是用来指定选择同步源的策略的。
6、管理副本集
1. 以单机模式启动成员
许多维护工作不能在备份节点上进行(因为要执行写操作),也不能在主节点上进行。此时我们需要将备份节点从集群中脱离出来变成单机模式后再进行维护,这需要重启备份节点所在机器的mongod服务。
在以单机模式重启服务器之前,先看一下服务器的命令行参数:
db.serverCmdLineOpts(){
"argv": ["mongod", "-f", "/var/lib/mongod.conf"],
"parsed": {
"replSet": "mySet",
"port": "27017",
"dbpath": "/var/lib/db"
},
"ok": 1
}重启的时候,一个是不使用replSet选项,二个是监听不同的端口,三个是保持dbpath
的值不变,这样副本集的其他成员就找不到它了。
当在这台服务器上执行完维护工作之后,可以以最原始的参数重新启动它。启动之后,它会自动与副本集中的其他成员进行同步,将维护期间落下的操作全部复制过来。
如果我们通过rs.remove()将需要维护的备份节点移除再进行维护的话,那么在维护完后执行rs.add()将节点添加会集群时会进行重新初始化同步,这样会造成较大的性能消耗和时间浪费,所以建议以单机模式启动需要维护的成员。
2. 副本集配置
副本集配置总是以一个文档的形式保存在local.system.replSet集合中。副本集中所有成员的这个文档都是相同的。绝对不要使用update更新这个文档,应该使用rs辅助函数或者replSetReconfig命令修改副本集配置。
添加新成员:
rs.add("spock:27017")修改副本集成员的配置。修改副本集成员配置时,有几个限制需要注意:
- 不能修改成员的"_id"字段;
- 不能将接收rs.reconfig命令的成员(通常是主节点)的优先级设为0;
- 不能将仲裁者成员变为非仲裁者成员,反之亦然;
- 不能将"buildIndexes" : false的成员修改为"buildIndexes" : true;
需要注意的是,可以修改成员的"host"字段。
1)创建比较大的副本集
副本集最多只能拥有50个成员,其中只有7个成员拥有投票权。这是为了减少心跳请求的网络流量(每个成员都要向其他所有成员发送心跳请求)和选举花费的时间。
如果要创建7个以上成员的副本集,只有7个成员可以拥有投票权,需要将其他成员的投票数量设置为0(在添加节点时设置)。
rs.add({"_id" : 7, "host" : "server-7:27017", "votes" : 0})这样可以阻止这些成员在选举中投主动票,虽然它们仍然可以投否决票。
2)修改成员状态
把主节点变为备份节点,可以使用stepDown。
函数将主节点降级为备份节点:
rs.stepDown()这个命令可以让主节点退化为备份节点,并维持60秒。如果这段时间内没有新的主节点被选举出来,这个节点就可以要求重新进行选举。如果希望主节点退化为备份节点并持续更长(或者更短)的时间,可以自己指定时间(以秒为单位):
rs.stepDown(600) // 10分钟这里设置为10分钟不是说10分钟后它会重新变回主节点,而是说如果10分钟内没有节点被选举为主节点他才会重新进行选举。
注意,无法强制将某个成员变成主节点,除非对副本集做适当的配置(例如提高某台节点的优先级然后让主节点stepDown变为从节点)。
3)阻止选举
如果需要对主节点做一些维护,但是不希望这段时间内将其他成员选举为主节点,那么可以在每个备份节点上执行freeze命令,以强制它们始终处于备份节点状态:
> rs.freeze(10000)这个命令也会接受一个以秒表示的时间,表示在多长时间内保持备份节点状态。
维护完成之后,如果想“释放”其他成员,可以再次执行freeze命令,将时间指定为0即可:
> rs.freeze(0)这样,其他成员就可以在必要时申请被选举为主节点。
也可以在主节点上执行rs.freeze(0),这样可以将退位的主节点重新变为主节点。
4)使用维护模式
当在副本集成员上执行某个非常耗时的操作时,这个成员就人进入维护模式(maintenance mode):强制成员进入RECOVERING状态。有时,成员会自动进入维护模式,比如在成员上做压缩时。不会有读请求发送给进入了维护模式的成员,这个成员也不能再作为复制源。
也可以通过执行replSetMaintenanceMode命令强制一个成员进入维护模式。例如,下面这个脚本会自动检测成员是否落后于主节点30秒以上,如果是,就强制将这个成员转入维护模式:
function maybeMaintenanceMode() {
var local = db.getSisterDB("local");
// 如果成员不是备份节点(它可能是主节点或者已经处于维护状态),就直接返回
if (!local.isMaster().secondary) {
return;
}
// 查找这个成员最后一次操作的时间
var last = local.oplog.rs.find().sort({"$natural" : -1}).next();
var lastTime = last['ts']['t']; // 如果落后主节点30秒以上
if (lastTime < (new Date()).getTime()-30) {
db.adminCommand({"replSetMaintenanceMode" : true});
}
};将成员从维护模式中恢复,可以使用如下命令:
> db.adminCommand({"replSetMaintenanceMode" : false});5)修改节点的复制源
MongoDB根据ping时间选择同步源。一个成员向另一个成员发送心跳请求,就可以知道心跳请求所耗费的时间。但是可能会出现这种情况,B会以A(主节点)作为复制源,C以B为复制源,形成一个A<-B<-C<-D...的复制链条。通常不太可能发生这样的情况,但是并非完全不可能。但这种情况通常是不可取的:复制链中的每个备份节点都要比它前面的备份节点稍微落后一点,复制链条的最后一个节点就会比主节点落后很多。
只要出现这种状况,可以用replSetSyncFrom(或者是它对应的辅助函数rs.syncFrom())命令修改成员的复制源进行修复。
连接到需要修改复制源的备份节点,运行这个命令,为其指定一个复制源:
> secondary.adminCommand({"replSetSyncFrom" : "server0:27017"})可能要花费几秒钟的时间才能切换到新的复制源。
我们可以通过查看rs.status()的"syncingTo"字段查看一个节点的同步源。
当用replSetSyncFrom为成员指定一个并不比它领先的成员作为复制源时,系统会给出警告,但是仍然允许这么做。
6)复制循环
A从B处同步数据,B从C处同步数据,C从A处同步数据,这就是一个复制循环。如果每个成员都是自动选取复制源,那么复制循环是不可能发生的。但是,使用replSetSyncFrom 强制为成员设置复制源时,就可能会出现复制循环。
复制循环带来的恶劣影响是复制循环中的成员(首先他们不可能是主节点,因为主节点不需要同步源)没有以主节点为同步源,无法复制新的写操作,数据会越来越落后。
可以禁用复制链,强制要求每个成员都从主节点进行复制,只需要将"allowChaining"。
设置为false即可(如果不指定这个选项,默认是true):
> var config = rs.config()
> config.settings = config.settings || {} // 如果设置子对象不存在,就自动创建一个空的
> config.settings.allowChaining = false
> rs.reconfig(config)将allowChaining设置为false之后,所有成员都会从主节点复制数据。如果主节点变得不可用,那么各个成员就会从其他备份节点处复制数据。
7)计算延迟
延迟(lag)是指备份节点相对于主节点的落后程度,具体是主节点最后一次操作的时间戳与备份节点最后一次操作的时间戳的差。
可以使用rs.status()查看成员的复制状态,也可以通过在主节点上执行db.printReplicationInfo()(这个命令的输出信息中包括oplog相关信息),或者在备份节点上执行db.printSlaveReplicationInfo()快速得到一份摘要信息。
在备份节点上运行db.printSlaveReplicationInfo(),可以得到当前成员的复制源,以及当前成员相对复制源的落后程度等信息。
db.printSlaveReplicationInfo();
source: server-0:27017
syncedTo: Tue Mar 30 2012 16:44:01 GMT-0400 (EDT)
= 12secs ago (0hrs)这样就可以知道当前成员正在从哪个成员处复制数据。在这个例子中,备份节点比主节点落后12秒。
注意,在一个写操作非常少的系统中,有可能会造成延迟过大的幻觉。假设一小时执行一次写操作。主节点A执行了这次操作后,可能要50毫秒才能同步到从节点B,但是如果我们刚好在这50毫秒内查看延迟,就会发现延迟是1个小时。此时我们只需要多执行几次查看延迟就可以避免这个问题。
8)调整oplog大小
可以将主节点的oplog长度看作维护工作的时间窗。如果主节点的oplog长度(我们一般以时间来描述oplog的长度)是一小时(也就是说一个小时的写操作就会将oplog覆盖掉1次),那么你就只有一小时的时间可以用于修复各种错误,不然的话备份节点可能会落后于主节点太多,导致不得不重新进行完全同步。在oplog被填满之前很难知道它的长度。
PS:我们可以通过db.printSlaveReplicationInfo()查看oplog的长度:
db.printReplicationInfo();
configured oplog size: 10.48576MB
log length start to end: 34secs (0.01hrs)
oplog first event time: Tue Mar 30 2010 16:42:57 GMT-0400 (EDT)
oplog last event time: Tue Mar 30 2010 16:43:31 GMT-0400 (EDT)
now: Tue Mar 30 2010 16:43:37 GMT-0400 (EDT)其中log length start to end(即oplog的第一个文档和最后一个文档的生成时间差)就是oplog的长度。
没有办法在服务器运行期间调整oplog大小。但是,可以依次将每台服务器下线,调整它的oplog,然后重新把它添加到副本集中。记住,每一个可能成为主节点的服务器都应该拥有足够大的oplog,以预留足够的时间窗用于进行维护。
如果要增加oplog大小,可以按照如下步骤:
先将当前服务器以单机模式启动(请参考之前的以单机模式启动的步骤)。
> use local
> // op:"i"表示操作为Insert的文档
> var cursor = db.oplog.rs.find({"op" : "i"})
> var lastInsert = cursor.sort({"$natural" : -1}).limit(1).next() // $natural:-1表示按插入时间倒序排序。这里是获取最后一条插入操作。
> db.tempLastOp.save(lastInsert) // 将最后一条插入的同步操作存到tempLastOp集合中
> // 确保保存成功,这非常重要!
> db.tempLastOp.findOne()
//删除当前的oplog:
> db.oplog.rs.drop()
//创建一个新的oplog:
> db.createCollection("oplog.rs", {"capped" : true, "size" : 10000})
// 将最后一条操作记录写回oplog:
> var temp = db.tempLastOp.findOne()
> db.oplog.rs.insert(temp)
>> // 要确保插入成功
> db.oplog.rs.findOne()最后,将当前服务器作为副本集成员重新启动。注意,由于这时它的oplog只有一条记录,所以在一段时间内无法知道该从节点的oplog的真实长度。另外,这个服务器现在也并不适合作为其他成员的复制源。
PS:重新调整oplog大小时需要先删除之前的oplog再创建新的oplog,因为我们无法直接改变现有oplog集合的大小。为什么要将最后一条oplog操作保留到新的oplog呢?前面我们说过,同步的时候是以从节点oplog的大于等于最后一条数据的id查询同步源的oplog日志来进行同步的。如果新的oplog没有这个最后一条同步操作的文档记录,就会重新进行一次完整同步。
通常不应该减小oplog的大小:即使oplog可能会有几个月那么长,但是通常总是有足够的硬盘空间来保存oplog,oplog并不会占用任何珍贵的资源(比如CPU或RAM)。
9)从延迟备份节点中恢复
假设有人不小心删除了一个数据库,幸好你有一个延迟备份节点。现在,需要放弃其他成员的数据,明确将延迟备份节点指定为数据源。有几种方法可以使用。
下面介绍最简单的方法。
关闭所有其他成员。删除其他成员数据目录中的所有数据。确保每个成员(除了延迟备份节点)的数据目录都是空的。重启所有成员,然后它们会自动从延迟备份节点中复制数据。
这种方式非常简单,但是,在其他成员完成初始化同步之前,副本集中将只有一个成员可用(延迟备份节点)而且这个成员很可能会过载。
根据数据量的不同,第二种方式可能更好,也可能更差。
关闭所有成员,包括延迟备份节点。删除其他成员(除了延迟备份节点)的数据目录。将延迟备份节点的数据文件复制到其他服务器。重启所有成员。
注意,这样会导致所有服务器都与延迟备份节点拥有同样大小的oplog,这可能不是你想要的。
10)创建索引
如果向主节点发送创建索引的命令,主节点会正常创建索引,然后备份节点在复制“创建索引”操作时也会创建索引。但是创建索引是一个需要消耗大量资源的操作,可能会导致成员不可用。如果所有备份节点都在同一时间开始创建索引,那么几乎所有成员都会不可用,一直到索引创建完成。
因此,可能你会希望每次只在一个成员上创建索引,以降低对应用程序的影响。如果要这么做,有下面几个步骤。
关闭一个备份节点服务器。
将这个服务器以单机模式启动。
在单机模式下创建索引。
索引创建完成之后,将服务器作为副本集成员重新启动。
对副本集中的每个备份节点重复上面的操作。
现在副本集的每个成员(除了主节点)都已经成功创建了索引。现在你有两个选择,应该根据自己的实际情况选择一个对生产系统影响最小的方式。
在主节点上创建索引。如果系统会有一段负载比较小的“空闲期”,那会是非常好的创建索引的时机。也可以修改读取首选项,在主节点创建索引期间,将读操作发送到备份节点上。
主节点创建索引时,备份节点仍然会复制这个操作,但是由于备份节点中已经有了同样的索引,实际上不会再次创建索引。
如果要创建唯一索引,需要先确保主节点中没有被插入重复的数据,或者应该首先为主节点创建唯一索引。否则,可能会有重复数据插入主节点,这会导致备份节点复制时出错,如果遇到这样的错误,备份节点会将自己关闭。你不得不以单机模式启动这台服务器,删除唯一索引,然后重新将其加入副本集。
3. 预算有限的情况下进行复制
如果预算有限,不能使用多台高性能服务器,可以考虑将备份节点只用于灾难恢复,这样的备份节点不需要太大的RAM和太好的CPU,也不需要太高的磁盘IO。这样,始终将高性能服务器作为主节点,比较便宜的服务器只用于备份,不处理任何客户端请求(将客户端配置为将全部读请求发送到主节点)。对于这样的备份节点,应该设置这些选项。
- "priority" : 0
优先级为0的备份节点永远不会成为主节点。
- "hidden" : true
将备份节点设为隐藏,客户端就无法将读请求发送给它了。
- "buildIndexes" : false
这个选项是可选的,如果在备份节点上创建索引的话,会极大地降低备份节点的性能。如果不在备份节点上创建索引,那么从备份节点中恢复数据之后,需要重新创建索引。
- "votes" : 0
在只有两台服务器的情况下,如果将备份节点的投票数设为0,那么当备份节点挂掉之后,主节点仍然会一直是主节点,不会因为达不到“大多数”的要求而退位。如果还有第三台服务器(即使它是你的应用服务器),那么应该在第三台服务器上运行一个仲裁者成员,而不是将第三台服务器的投票数量设为0。
更多关于mongdb复制和副本集的内容可以查看mongdb中文文档:
五、MongoDB 分片管理
分片(sharding)是指将数据拆分,将其分散存放在不同的机器上的过程。
1、MongoDB 分片组件
分片:每个shard(分片)包含总数据集中的一个子集。并且每个分片可以被部署为副本集架构(即每个分片不仅能存储本分片的数据,还可以作为其他分片的副本备份其他分片的数据)。
mongos:mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。从MongoDB 4.4开始,mongos可以支持 对冲读取(hedged reads)以最大程度地减少延迟。
config服务器:config servers存储了分片集群的元数据和配置信息。
分片之前要先执行mongos进行一次路由过程。这个路由服务器维护着一个“内容列表”,指明了每个分片包含什么数据内容。应用程序只需要连接到路由服务器,就可以像使用单机服务器一样进行正常的请求了。如图所示,路由服务器知道哪些数据位于哪个分片,可以将请求转发给相应的分片。每个mongod分片对请求的响应都会发送给路由服务器,路由服务器将所有响应合并在一起,返回给应用程序。
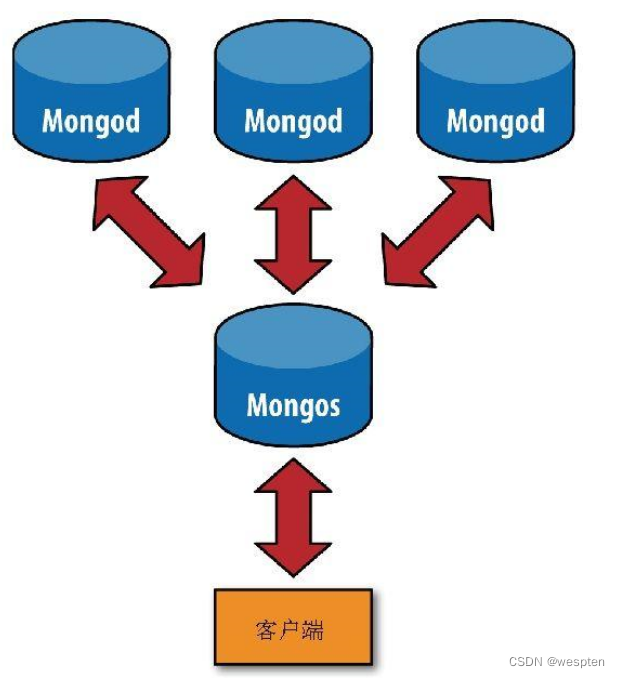
分片的优点:
- 增加可用RAM;
- 增加可用磁盘空间;
- 减轻单台服务器的负载;
- 处理单个mongod无法承受的吞吐量;
2、快速在单台服务器建立一个简单的集群
首先,使用--nodb选项启动mongo shell。
使用ShardingTest类创建集群:
cluster = new ShardingTest({"shards" : 3, "chunksize" : 1}) // 生成3个分片默认情况下,ShardingTest会在30999端口启动mongos(旧版的mongodb是这样,新版的需要查看netstat命令查看mongos绑定的端口)。接下来就连接到这个mongos开始使用集群,在本次例子中,mongos绑定了20006端口。
新开一个客户端:
db = (new Mongo("localhost:20006")).getDB("test") // 连接到mongos插入数据:
for (var i=0; i<100000; i++) {
db.users.insert({"username" : "user"+i, "created_at" : new Date()});
}查看集群状态:
sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("6050036573a19e9dfb6ea4a2")
}
shards:
{ "_id" : "__unknown_name__-rs0", "host" : "__unknown_name__-rs0/VM-0-13-centos:20000", "state" : 1 }
{ "_id" : "__unknown_name__-rs1", "host" : "__unknown_name__-rs1/VM-0-13-centos:20001", "state" : 1 }
{ "_id" : "__unknown_name__-rs2", "host" : "__unknown_name__-rs2/VM-0-13-centos:20002", "state" : 1 }
active mongoses:
"4.4.4" : 1
autosplit:
Currently enabled: no
balancer:
Currently enabled: no
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
{ "_id" : "test", "primary" : "__unknown_name__-rs0", "partitioned" : false, "version" : { "uuid" : UUID("4a59ba73-4cff-4e68-a7bc-8a8ff7fd8457"), "lastMod" : 1 } }sh命令与rs命令很像,是和分片相关的全局变量。
如sh.stats()的输出所示,当前拥有3个分片,2个数据库。
现在mongodb还不能自动将数据分发到不同的分片上,因为它不知道你希望如何分发数据。
要对一个集合分片,首先要对这个集合的数据库启用分片,执行如下命令:
sh.enableSharding("test")现在就可以对test数据库内的集合进行分片了,但是还不能够对具体的某一个集合分片。
对集合分片时,要选择一个片键(shard key)。片键是集合的一个键(即字段),MongoDB根据这个键拆分数据。只有被索引过的键才能够作为片键。
db.users.createIndex({"username" : 1})
sh.shardCollection("test.users", {"username" : 1}) // 以username字段作为片键对users集合进行分片几分钟之后再次运行sh.status()会看到不一样的信息。
在分片之前,集合实际上是一个单一的数据块。分片依据片键将集合拆分为多个数据块,这块数据块被分布在集群中的每个分片上。
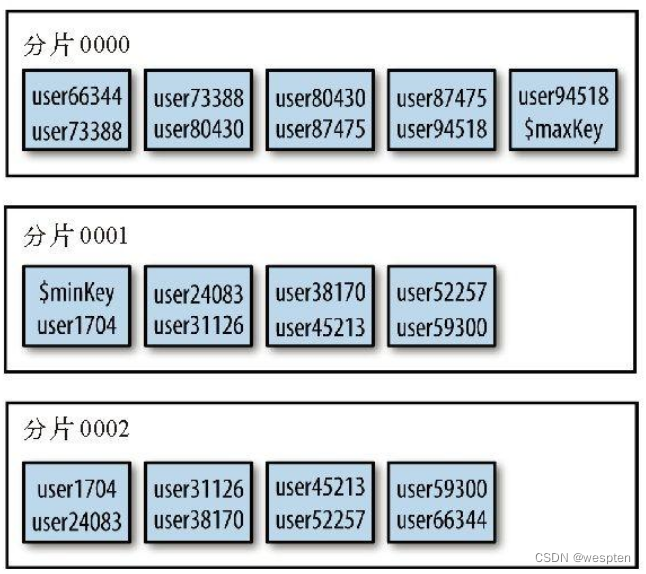
$minkKey和$maxKey是数据块列表开始的键值和结束的键值。可以将$minKey认为是“负无穷”,它比MongoDB中的任何值都要小。类似地,可以将$maxKey认为是“正无穷”,它比MongoDB中的任何值都要大。
此时我们分析一下通过username字段进行单点查询的情况。
db.users.find({username:"user100"}).explain()
{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SINGLE_SHARD",
"shards" : [
{
"shardName" : "__unknown_name__-rs0",
"connectionString" : "__unknown_name__-rs0/VM-0-13-centos:20000",
"serverInfo" : {
"host" : "VM-0-13-centos",
"port" : 20000,
"version" : "4.4.4",
"gitVersion" : "8db30a63db1a9d84bdcad0c83369623f708e0397"
},
"plannerVersion" : 1,
"namespace" : "test.users",
"indexFilterSet" : false,
"parsedQuery" : {
"username" : {
"$eq" : "user100"
}
},
"queryHash" : "379E82C5",
"planCacheKey" : "965E0A67",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "SHARDING_FILTER",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"username" : 1
},
"indexName" : "username_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"username" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"username" : [
"[\"user100\", \"user100\"]"
]
}
}
}
},
"rejectedPlans" : [ ]
}
]
}
},
"serverInfo" : {
"host" : "VM-0-13-centos",
"port" : 20006,
"version" : "4.4.4",
"gitVersion" : "8db30a63db1a9d84bdcad0c83369623f708e0397"
},
"ok" : 1,
"operationTime" : Timestamp(1615858458, 13),
"$clusterTime" : {
"clusterTime" : Timestamp(1615858515, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}输出信息包含两个部分:一个看起来比较普通的explain()输出嵌套在另一个explain()输出中。外层的explain()输出来自mongos:描述了为了处理这个查询,mongos所做的工作。内层的explain()输出来自查询所使用的分片。
由于"username"是片键,所以当使用username作为条件查询时,mongos能够直接将查询发送到正确的分片上。但是如果没有在查询中使用片键,mongos就不得不将查询发送到每个分片。
包含片键的查询(以片键作为条件的查询)能够直接被发送到目标分片或者是集群分片的一个子集,这样的查询叫做定向查询。有些查询必须被发送到所有分片,这样的查询叫做分散-聚集查询:mongos将查询分散到所有分片上,然后将各个分片的查询结果聚集起来。
切换回最初的shell,按几次Enter键以回到命令行。然后运行cluster.stop()就可以关闭整个集群了。接下来,我们正式将分片部署到多台机器上。
何时分片?
通常不必太早分片,因为分片不仅会增加部署的操作复杂度,还要求做出设计决策,而该决策以后很难再改。也不要在系统运行太久之后再分片,因为在一个过载的系统上不停机进行分片是非常困难的。
随着不断增加分片数量,系统性能大致会呈线性增长。但是,如果从一个未分片的系统转换为只有两三个分片的系统,性能通常会有所下降。由于迁移数据、维护元数据、路由等开销,少量分片的系统与未分片的系统相比,通常延迟更大,吞吐量甚至可能会更小。因此,至少应该创建3个或以上的分片(也就是说,如果分片的数量过少,性能反而还比单机的性能要差)。
下面我们开始配置多机分片,为此我们需要准备:配置服务器、分片服务和mongos路由服务。
3、多机分片
1. 配置服务器
配置服务器是一个独立的mongod进程,所以可以像启动“普通的”mongod进程一样启动配置服务器。
配置服务器相当于集群的大脑,保存着集群和分片的元数据,即各分片包含哪些数据的信息。因此,应该首先建立配置服务器,鉴于它所包含数据的极端重要性,必须启用其日志功能,最好配置到单独的物理机器。
因mongos需从配置服务器获取配置信息,因此配置服务器应先于任何mongos进程启动。
操作如下:
首先在三台机器上启动3个配置服务器(没有这么多机器的同学可以开多个端口在一台机器上启动作为模拟,但是要指定不同的端口和不同的数据目录)。
# 3个配置服务器都用下面的命令启动
mongod --replSet zbpSet --configsvr --dbpath /var/lib/mongodb -f /var/lib/config/mongod.confmongos会向所有3台配置服务器发送写请求,以确保3台服务器拥有相同的数据,所以这3台配置服务器都必须是可写的。而且这3个服务必须以副本集启动。
为什么要用3台配置服务器?因为我们需要考虑不时之需,不至于万一某台配置服务器挂掉了之后分片无法正确接收请求。但是,也不需要过多的配置服务器,因为配置服务器上的确认动作是比较耗时的。
--configsvr选项指定mongod为配置服务器。该选项并非必选项,因为它所做的不过是将mongod的默认监听端口改为27019,并把默认的数据目录改为/data/configdb而已(可使用--port和--dbpath选项修改这两项配置)。
但建议使用--configsvr选项,因为它比较直白地说明了所启动的服务是作为配置服务器的。当然,如果不用它启动配置服务器也没问题。
配置服务器并不需要太多的空间和资源。配置服务器的1 KB空间约等于分片中200 MB真实数据,这里说的1KB保存的只是数据的分布信息。由于配置服务器并不需要太多的资源,因此可将其部署在运行着其他程序的机器上,如应用服务器、分片的mongod服务器,或mongos进程的服务器上。
要经常对配置服务器做数据备份。应常在执行集群维护操作之前备份配置服务器的数据。
mongos进程:
三个配置服务器均处于运行状态后,启动一个mongos进程供应用程序连接。mongos进程需知道配置服务器的地址,所以必须使用--configdb选项启动mongos,且需要指定刚刚配置服务的副本集名称。
mongos --configdb zbpSet/config-server-1:27019,config-server-2:27019,config-server-3:27019 --fork --logpath=/var/log/mongodb/mongos.log --port=27021 --bind_ip=0.0.0.0注意,并不需要指定数据目录(mongos自身并不保存数据,它会在启动时从配置服务器加载集群数据)。确保正确设置了logpath,以便将mongos日志保存到安全的地方。
可启动任意数量的mongos进程。
2. 启动分片服务
一个集群中的分片一开始要以副本集的形式启动。有两种可能性:已经有了一个副本集,或是从零开始建立集群。下例假设我们已经拥有了一个副本集。如果是从零开始的话,可先初始化一个空的副本集。
vi /root/mongodb-shard.conf
# mongodb分片服务的配置
logpath=/var/log/mongodb/mongod-shard1.log
logappend=true
port=27017
replSet=zbpShard
fork=true
dbpath=/data/db_shard1
bind_ip=0.0.0.0
shardsvr=true注意:分片服务一定要添加 shardsvr(对应命令行--shardsvr选项)参数用来标识这个mongod服务是用来作为分片的。否则之后addShard会报错。
在3个服务器上启动mongd分片:
mongod --config=/root/mongodb-shard1.conf在mongos服务的客户端下执行下面的命令:
sh.addShard("zbpShard/server-1:27017,server-2:27017,server-4:27017")
sh.status() // 查看分片信息其中zbpShard是分片的副本集名称(需要在addShard之前将这三个分片服务设置成副本集)。
在执行addShard之前,他们还是个副本集,执行了zbpShard之后,他们三个就变成了分片集群。分片的名称就是addShard。
其实addShard时可以不指定副本集中的所有成员。mongos能够自动检测到没有包含在副本集成员表中的成员。
之后应用程序如python,php,go,Java等客户端的mongodb驱动要操作分片(增删改查)的话,可以直接连接mongos服务,向mongos服务发送请求,mongos会将请求路由到正确的分片服务器。另外,应用程序不能向分片直接发送请求,否则分片是无法正确的处理这些请求的。因此应该对分片服务的mongod端口设置防火墙,只开放分片服务器对mongos所在机器的IP的防火墙,防止应用程序直接访问分片。
3. 对数据分片(对数据库和集合分片)
在mongos上执行下面的命令:
sh.enableSharding("test") // 先对库分片
sh.shardCollection("test.users", {"name":1}) // 再对集合分片,指定name字段为分片键集合会按照name键进行分片。如果是对已存在的集合进行分片,那么name键上必须有索引,否则shardCollection()会返回错误。如果出现了错误,就先创建索引(mongos会建议创建的索引作为错误消息的一部分返回),然后重试shardCollection()命令。
如要进行分片的集合还不存在,mongos会自动在片键上创建索引。
shardCollection()命令会将集合拆分为多个数据块(chunk)。MongoDB会均衡地将集合数据分散到集群的分片上。这个过程不是瞬间完成的,对于比较大的集合,可能会花费几个小时才能完成。
4、Mongodb分片的相关细节
1. mongodb的文档分块
每个mongos都必须能够根据给定的片键(比如user_id是一个片键)找到文档的存放位置(在哪个分片上)。为此,MongoDB将文档分组为块(chunk),每个块由给定片键特定范围内的文档(例如user_id为1~100000的文档是一个块,user_id为100001~200000的文档是另一个块)组成。一个块只存在于一个分片上,所以MongoDB用一个比较小的表就能够维护块跟分片的映射。
例如,如用户集合的片键是{"age" : 1},其中某个块可能是由age值为3~17的文档组成的。如果mongos得到一个{"age" : 5}的查询请求,它就可以将查询路由到age值为3~17的块所在的分片。
进行写操作时,块内的文档数量和大小可能会发生改变。插入文档可使块包含更多的文档,删除文档则会减少块内文档的数量。如果我们针对儿童和中小学生制作游戏,那么这个age值为3~17的块可能会变得越来越大。几乎所有的用户都会被包含在这个块内,且在同一分片上。这就违背了我们分布式存放数据的初衷。因此,当一个块增长到特定大小时,MongoDB会自动将其拆分为两个较小的块。在本例中,该块可能会被拆分为一个age值为3~11的块和一个age值为12~17的块。这些小块变大后,会被继续拆分为更小的块,直到包含age的全部域值。
块与块之间的age值范围不能有交集,如3~15和12~17。如果存在交集的话,那么MongoDB为了查询处于交集中的age值(如14)时,则需分别查找这两个块。只在一个块中进行查找效率会更高,尤其是在块分散在集群中时。
一个文档,属于且只属于一个块。这意味着,不可以使用数组字段作为片键,因为MongoDB会为数组创建多个索引条目。例如,如某个文档的age字段值是[5, 26, 83],该文档就会出现在三个不同的块中。
新分片的集合起初只有一个块,所有文档都位于这个块中。此块的范围是负无穷到正无穷,在shell中用$minKey和$maxKey表示。
我们按照之前提到的"age"字段进行分片。所有"age"值为3~17的文档都包含在一个块中:3 ≤ age < 17。该块被拆分后,我们得到了两个较小的块,其中一个范围是3 ≤ age < 12,另一个范围是12 ≤ age < 17。这里的12就叫做拆分点。
块信息保存在config.chunks集合中,查看集合内容,会发现其中的文档如下:
use config
db.chunks.find(criteria, {"min" : 1, "max" : 1})
{
"_id" : "test.users-age_-100.0", // test库,users表,age字段
"min" : {"age" : -100},
"max" : {"age" : 23}
}
{
"_id" : "test.users-age_23.0",
"min" : {"age" : 23},
"max" : {"age" : 100}
}
{
"_id" : "test.users-age_100.0",
"min" : {"age" : 100},
"max" : {"age" : 1000}
}结果显示结合被分为了3个块,分别按照[-100,23), [23,100), [100, 1000)的范围的分割的。
{"_id" : 123, "age" : 50}该文档位于第二个块中。
{"_id" : 456, "age" : 100}该文档位于第三个块中,因为块的边界是左闭右开的。
{"_id" : 789, "age" : -101}该文档不位于上面所示的这些块中。
如果想查看某一个test.users这个集合的分片和块的情况,可以使用:
db.users.stats()主要可以查看它的以下字段:
"ns" : "test.users2",
"count" : 10000, // 文档数
"nindexes" : 2,
"nchunks" : 4, // 使用的块数量还有它的shards字段,描述了users2保存在的每一个分片的信息。
如果想查看test.users这个集合的分片和块的简略情况,可以用:
sh.status()它会包含每一个集合表的分片和块信息。
此外,可使用复合片键,工作方式与使用复合索引进行排序一样。假如在{"username" : 1, "age" : 1}上有一个片键,那么可能会存在如下块范围:
{
"_id" : "test.users-username_MinKeyage_MinKey",
"min" : {
"username" : { "$minKey" : 1 },
"age" : { "$minKey" : 1 }
},
"max" : {
"username" : "user107487",
"age" : 73 }
}
{
"_id" : "test.users-username_\"user107487\"age_73.0",
"min" : {
"username" : "user107487",
"age" : 73
},
"max" : { "username" : "user114978",
"age" : 119
}
}
{
"_id" : "test.users-username_\"user114978\"age_119.0",
"min" : {
"username" : "user114978",
"age" : 119 },
"max" : {
"username" : "user122468",
"age" : 68 // 说明age这个字段是不按顺序的。
}
}如果给定一个用户名,或者给定一个用户名和年龄,mongos可轻易找到其所对应的文档。但如果只给定年龄,mongos就必须查看所有(或者几乎所有)块。如果希望基于age的查询能够被路由到正确的块上,则需使用“相反”的片键:{"age" : 1, "username" : 1}
2. 块拆分
每次收到客户端发起的写请求时,mongos会记录在每个块中插入了多少数据,检查当前块的拆分阈值点,一旦达到某个阈值,就会向分片发起一个针对该拆分点的拆分请求来决定是否对块进行拆分。
如果块确实需要被拆分,mongos就会在配置服务器上更新这个块的元信息。块拆分只需改变块的元数据即可,而无需进行数据移动。进行拆分时,配置服务器会创建新的块文档,同时修改旧的块范围(即max值)。拆分完成后,mongos会重置对原始块的追踪器,同时为新的块创建新的追踪器。
如果一个块中的片键的值相同,那么无论这个块的数据怎么增长都不会拆分,例如一个块中的age字段全是12(age就是片键),此时再添加age为12的文档也不会导致这个分片的拆分,即使这个块已经达到块的最大大小限制(默认64M)。因此,拥有不同的片键值是非常重要的。
如果在mongos试图进行拆分时有一个配置服务器挂了,那么mongos就无法更新元数据(元数据在配置服务器上)从而无法拆分成功,此时mongos会不断向配置服务发起拆分请求,这会拖慢mongos和当前分片。这种mongos不断重复发起拆分请求却无法进行拆分的过程,叫做拆分风暴。防止拆分风暴的唯一方法是尽可能保证配置服务器的可用和健康。
可在启动mongos时指定--nosplit选项,从而关闭块的拆分。
3. 均衡器
均衡器负责数据的迁移。它会周期性地检查分片间是否存在数据不均衡,如果存在,则会开始块的迁移(不是数据在块之间的迁移,而是块在分片之间的迁移)。虽然均衡器通常被看作是单一实体,但每个mongos有时也会扮演均衡器的角色。
每隔几秒钟,mongos就会尝试变身为均衡器。如果没有其他可用的均衡器,mongos就会对整个集群加锁,以防止配置服务器对集群进行修改,然后做一次均衡。均衡并不会影响mongos的正常路由操作(读写请求仍可正常进行),所以使用mongos的客户端不会受到影响。
查看config.locks集合,可得知哪一个mongos是均衡器:
db.locks.findOne({"_id" : "balancer"})mongos成为均衡器后,就会检查每个集合的分块表,从而查看是否有分片达到了均衡阈值。不均衡的表现指,一个分片明显比其他分片拥有更多的块。如果检测到不均衡,均衡器就会开始对块进行再分布,以使每个分片拥有数量相当的块。如果没有集合达到均衡阈值,mongos就不再充当均衡器的角色了。
使用集群的应用程序无需知道数据迁移:在数据迁移完成之前,所有的读写请求都会被路由到旧的块上。如果元数据更新完成,那么所有试图访问旧位置数据的mongos进程都会得到一个错误。这些错误应该对客户端不可见:mongos会对这些错误做静默处理,然后在新的分片上重新执行之前的操作。
PS:配置服务器保存着分片和块之间的元数据(映射表),并在块拆分和块迁移中起着重要作用,如果配置服务器挂掉会导致块拆分和块迁移失败。
块拆分不会移动数据,但是均衡数据会移动数据,后者会产生一定开销和可能影响效率。
4. 分片的数据分发方式
拆分数据最常用的数据分发方式有三种:升序片键、随机分发的片键和基于位置的片键。也有一些其他类型的键可供使用,但大部分都属于这三种类别。
a. 升序片键(默认的分片规则)
升序片键是一种会随着时间稳定增长的字段,例如date或者_id这样的字段。如果基于"_id"分片,那么集合就会依据不同的"_id"范围被拆分为多个块。假设一共有3个分片(ABC),一开始只有一个块1存在于一个分片A上,其他分片没有块,那么当插入数据的时候,数据会写入A,随着时间的推移,A上的块1的数据量越来越多,会拆分为2个块(块1和块2),假设块1的范围是(负无穷, 拆分点1), 块2的范围是[拆分点1, 正无穷)。
我们把包含正无穷的那个块成为最大块(即块2),升序片键的特点就是数据只会写入到最大块中而不会写入到其它块,随着新数据的不断插入,该最大块会不断拆分出新的小块。
块1和块2都在分片A上,因此数据都写在A中。随着分片A中的块数量不断增多,会有一些块被迁移到另外两个分片上。
因此升序片键的特点是:数据只会写入到最大块中,也只会写入到最大块所在的分片上,其他分片如果要分摊保存数据只能通过块迁移。
最大块会不断被拆分,会较多的出现块迁移的情况(数据迁移会消耗额外的性能)。
数据分布会不均衡,大部分数据会存到最大块所在的分片上(分片A),只有块迁移的时候才会将数据分摊到其他节点。
b. 随机分发的片键(需要使用哈希索引)
相比于升序片键只会把数据插入到一个分片上,随机分发就是数据插入时会均匀随机的插入到不同的分片上。随机分发的键可以是用户名、邮件地址、UUID、MD5散列值,或者是数据集中其他一些没有规律的键。
由于写入数据是随机分发的,各分片增长的速度应大致相同,这就减少了需要进行迁移的次数。
c. 基于位置的片键
这里说的位置是用标签tag标示一个位置。
我们需要对某一个分片指定一个或多个tag,并且在为这个tag设定它对应的片键的值范围,插入数据的时候,值范围在这个tag指定的值范围的时候就会将这条数据插入到这个tag对应的分片。
例如,我以IP作为片键,有shard000~shard0001这3个分片,对shard0000和shard0002指定tag:
sh.addShardTag("shard0000", "A")
sh.addShardTag("shard0000", "B")
sh.addShardTag("shard0002", "A")
sh.addTagRange("test.ips", {"ip":"056.000.000.000"}, {"ip":"057.000.000.000"}, "A")里是指对test库的ips这个集合的标签A指定ip片键的范围,那么 56.xxx.xxx.xxx到57.xxx.xxx.xxx的数据最终会被插入到shard0000或者shard0002上,因为这两个分片标注了A这个标签。
但是需要注意,满足A标签的数据可能不是直接插入到这两个分片上,而是由均衡器在移动块的时候,将满足A标签的数据的块迁移到shard0000和shard0002上。
对于没有打标签的ip范围值会被均衡的分发到shard0000~shard0002上。
5. 分片策略
如果追求的是数据加载速度的极致,那么散列片键(Hashed Shard Key)是最佳选择。散列片键可使片键随机分发到任一分片上。
弊端是无法使用散列片键做指定目标的范围查询(因为数据根据片键随机分布到不同分片,如果根据片键做范围查询需要访问到所有的分片)。如无需做范围查询(即点查询),那么散列片键就非常合适(就只会直接路由到一个分片而不会访问所有的分片)。
步骤如下:
创建一个散列片键,首先要创建散列索引(哈希索引)。
db.users.createIndex({"username" : "hashed"})然后对集合分片:
sh.shardCollection("app.users", {"username" : "hashed"})如果在一个不存在的集合上创建散列片键,shardCollection的行为会比较有趣:它假设我们希望对数据块进行均衡分发,所以会立即创建一些空的块,并将这些块分发在集群中(例如有3个分片,如果使用散列片键,那么系统会常见3个块,让每个分片都持有一个块)。
我们可以通过sh.status()返回的chucks字段看到。
现在集合中还没有文档,但当插入新文档时,写请求一开始就会被均衡地分发到不同的分片上。
散列片键不能使用unique唯一键,也不能使用数组字段作为片键。浮点型的值会先被向下取整,然后才会进行散列,所以1和1.999999会得到相同的散列值。
6. 流水策略
如果分片集群中,有分片A所在的机器比其他分片机器性能要好很多,为了降低写延迟(即写操作所花费的时间),我们希望将所有数据都写入到分片A,再让均衡器通过块迁移的方式将块数据移动到其他分片上。
步骤如下:
首先,为分片A(假设分片_id为"shard0000")指定一个标签All。
sh.addShardTag("shard0000", "All")指定All标签的片键值范围为当前值到正无穷,这样之后插入的数据都会写入到All标签对应的shard0000分片。
sh.addTagRange("test.users", {"_id": ObjectId()}, {"_id" : MaxKey}, "All")如果我们不希望光是指望均衡器自动的迁移块以均衡数据,而是主动的均衡数据,可以写一个定时任务,每天定时修改tag的范围值为当前ObjectId()到Maxkey,这样前一天的块就会被均匀的移动到其他分片。
如下:
use config
var tag = db.tags.findOne({"ns" : "test.users", "max" : {"_id":MaxKey}})
tag.min._id = ObjectId() // 把_id最小值设置为当前id,这样当前id以前的id所在的块就会被均衡器迁移
db.tags.save(tag)如果没有高性能服务器来处理插入流水,或者是没有使用标签,那么不要将升序键用作片键。否则,所有写请求都会被路由到同一分片上。
7. 多热点
所谓的热点指的是写请求被路由到的块。多热点指的是多个分片都有写请求命中的块,意味着写请求能被均匀的分布到集群中的每个分片,并且单个块内的数据写入是升序的,此时分片的写入和查询效率就最高的。
为实现这种方式,需使用复合片键。复合片键中的第一个值是一个基数比较小的随机值(比如国家,分类之类的字段),随着插入数据的增多,可将片键第一部分中的每个值大致可以看做为一个块(虽然可能不会被分离得这么整洁),如果继续插入数据,最终同一个随机值则会对应有多个块。此时每一个随机值所代表的最后一个块就是一个热点。但是随机值字段的基数不宜过大,否则热点过多的话,其实写请求就相当于是完全随机的了。
片键的第二个值是个升序键。也就是说,在一个块内,值总是增加的,写请求在每个分片内都是升序的。



一旦热点块被拆分,只有一个新块会成为热点块:其他块实际上会处于一种“死掉”的状态,且不会再继续增长。
使用上述复合主键来构建多热点的一个缺点就是不易扩展,如果以后需要增加新节点的话,这个新节点在较长的一段时间内不会产生热点的块,也不会有写请求。只有等到其他分片的热点块迁移到该节点才会开始有写请求。
8. 片键的选择
片键不可以是数组。向片键插入数组值也是不被允许的。与索引一样,分片在基数比较高的字段上性能更佳。例如,"logLevel"键只拥有"DEBUG"、"WARN"和"ERROR"这几个值。如用其作为片键,则MongoDB最多只能将数据分为三个块(因为片键只拥有三个不同的值)。
9. 分片管理
sh.status() 可查看分片、数据库和分片集合的摘要信息。如果块的数量较少,则该命令会打印出每个块的保存位置。否则它只会简单地给出集合的片键,以及每个分片的块数。sh.status()显示的所有信息都来自config数据库。
如果启动数据库时指定了--noscripting选项,则无法运行sh.status()命令。
集群相关的所有配置信息都保存在配置服务器上config数据库的集合中。可直接访问该数据库。
永远不要直接连接到配置服务器,以防配置服务器数据被不小心修改或删除。应先连接到mongos,然后通过config数据库来查询相关信息。
a. config.shards集合
shards集合记录集群内所有分片的信息。shards集合中的一个典型文档结构如下:
db.shards.findOne()
{
"_id" : "spock", // 副本集名称
"host" : "spock/server-1:27017,server-2:27017,server-3:27017",
"tags" : [
"us-east",
"64gb mem",
"cpu3"
]
}b. config.databases
databases集合记录集群中所有数据库的信息,不管数据库有没有被分片。
db.databases.find()
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test1", "partitioned" : true, "primary" : "spock" }
{ "_id" : "test2", "partitioned" : false, "primary" : "bones" }如果在数据库上执行过enableSharding,则此处的"partitioned"字段值就是true。"primary"是“主数据库”。数据库的所有新集合均默认被创建在数据库的主分片上。
c. config.collections
collections集合记录所有分片集合的信息(非分片集合信息除外)。其中的文档结构如下:
> db.collections.findOne()
{
"_id" : "test.foo",
"lastmod" : ISODate("1970-01-16T17:53:52.934Z"),
"dropped" : false,
"key" : { "x" : 1, "y" : 1 }, // 片键
"unique" : true // 表明片键是一个唯一索引
}d. config.chunks
chunks集合记录有集合中所有块的信息:
{
"_id" : "test.hashy-user_id_-1034308116544453153",
"lastmod" : { "t" : 5000, "i" : 50 },
"lastmodEpoch" : ObjectId("50f5c648866900ccb6ed7c88"),
"ns" : "test.hashy", // 它是哪个表的块
"min" : { "user_id" : NumberLong("-1034308116544453153") },
"max" : { "user_id" : NumberLong("-732765964052501510") },
"shard" : "test-rs2" // 块所属的分片
}e. config.changelog
changelog集合可用于记录集群的操作,因为该集合会记录所有的拆分和迁移操作。
f. config.tags
该集合的创建是在为系统配置分片标签时发生的。每个标签都与一个块范围相关联:
> db.tags.find()
{
"_id" : {
"ns" : "test.ips",
"min" : {"ip" : "056.000.000.000"}
},
"ns" : "test.ips",
"min" : {"ip" : "056.000.000.000"},
"max" : {"ip" : "057.000.000.000"},
"tag" : "USPS"
}g. config.settings
该集合含有当前的均衡器设置和块大小的文档信息。通过修改该集合的文档,可开启或关闭均衡器,也可以修改块的大小。注意,应总是连接到mongos修改该集合的值,而不应直接连接到配置服务器进行修改。
10. mongodb网络连接
查看连接统计:
可使用connPoolStats命令,查看mongos和mongod之间的连接信息,并可得知服务器上打开的所有连接。
db.adminCommand({"connPoolStats":1})
{
"numClientConnections" : 0,
"numAScopedConnections" : 0,
"totalInUse" : 0,
"totalAvailable" : 7,
"totalCreated" : 1251,
"totalRefreshing" : 0,
"pools" : {
"NetworkInterfaceTL-ShardRegistry" : {
"poolInUse" : 0,
"poolAvailable" : 4,
"poolCreated" : 1248,
"poolRefreshing" : 0,
"203.195.164.213:27019" : {
"inUse" : 0,
"available" : 1,
"created" : 109,
"refreshing" : 0
},
"81.71.136.86:27019" : {
"inUse" : 0,
"available" : 2,
"created" : 708,
"refreshing" : 0
},
"81.71.136.86:27020" : {
"inUse" : 0,
"available" : 1,
"created" : 431,
"refreshing" : 0
}
},
"NetworkInterfaceTL-TaskExecutorPool-0" : {
"poolInUse" : 0,
"poolAvailable" : 3,
"poolCreated" : 3,
"poolRefreshing" : 0,
"203.195.164.213:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27018" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
}
}
},
"hosts" : { // 连接到mongos的主机名
"203.195.164.213:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"203.195.164.213:27019" : {
"inUse" : 0,
"available" : 1,
"created" : 109,
"refreshing" : 0
},
"81.71.136.86:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27018" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27019" : {
"inUse" : 0,
"available" : 2,
"created" : 708,
"refreshing" : 0
},
"81.71.136.86:27020" : {
"inUse" : 0,
"available" : 1,
"created" : 431,
"refreshing" : 0
}
},
"replicaSets" : { // 连接到mongos的副本集信息
"zbpSet" : {
"hosts" : [
{
"addr" : "203.195.164.213:27019",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.552
},
{
"addr" : "81.71.136.86:27019",
"ok" : true,
"ismaster" : true,
"hidden" : false,
"secondary" : false,
"pingTimeMillis" : 0.673
},
{
"addr" : "81.71.136.86:27020",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.728
}
]
},
"zbpShard" : { // 连接到mongos的zbpShard分片集群信息
"hosts" : [
{
"addr" : "203.195.164.213:27017",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.533
},
{
"addr" : "81.71.136.86:27017",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.653
},
{
"addr" : "81.71.136.86:27018",
"ok" : true,
"ismaster" : true,
"hidden" : false,
"secondary" : false,
"pingTimeMillis" : 0.563
}
]
}
},
"ok" : 1,
"operationTime" : Timestamp(1616376573, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1616376573, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}available的值表明当前实例的连接池中有多少可用连接。
11. 限制连接数量
当有客户端连接到mongos时,mongos会创建一个连接,该连接应至少连接到一个分片上,以便将客户端请求发送给分片。因此,每个连接到mongos的客户端连接都会至少产生一个从mongos到分片的连接。
如果有多个mongos进程,可能会创建出非常多的连接,甚至超出分片的处理能力:一个mongos最多允许20 000个连接(mongod也是如此),当并发连接数超过2万的时候需要多开几个mongos进程来处理这些连接。所以如果开启了多个mongos进程,最多会发起10万个连接,但是分片集群无法处理这么多的连接。为防止这种情况的发生,可在mongos的命令行配置中使用maxConns选项,这样可以限制mongos能够创建的连接数量。
可使用下列公式计算分片能够处理的来自单一mongos的连接数量:
maxConns =20 000−(mongos进程的数量×3)−(每个副本集的成员数量×3)−(其他/mongos进程的数量)这里的其他指其他可能连接到mongod的进程数量。
5、分片服务器管理
1. 添加服务器
可使用addShard命令。
2. 修改分片的服务器
要修改某分片的成员(比如在一个分片集群中将某个单服务器分片转变为副本集服务器分片,或者反过来将副本集服务器分片变为单服务器分片),需直接连接到分片的主服务器上(而不是通过mongos),然后对副本集进行重新配置。集群配置会自动检测更改,并将其更新到config.shards上。不要手动修改config.shards。
将单机服务器分片修改为副本集分片最简单的方式是添加一个新的空副本集分片,然后移除单机服务器分片。
3. 删除分片
通常来说,不应从集群中删除分片。如果经常在集群中添加和删除分片,会给系统带来很多不必要的压力。如果向集群中添加了过多的分片,最好是什么也不做,系统早晚会用到这些分片,而不应该将多余的分片删掉,等以后需要的时候再将其重新添加到集群中。
删除分片时均衡器会负责将待删除分片的数据迁移至其他分片。
db.adminCommand({"removeShard" : "test-rs3"})4. 修改配置服务器
修改配置服务器是非常困难的,而且有风险,通常还需要停机。注意,修改配置服务器前,应做好备份。
在运行期间,所有mongos进程的--configdb选项(配置服务器选项)值都必须相同。因此,要修改配置服务器,首先必须关闭所有的mongos进程(mongos进程在使用旧的--configdb参数时,无法继续保持运行状态),然后使用新的--configdb参数重启所有mongos进程。
例如,将一台配置服务器增至三台是最常见的任务之一。为实现此操作,首先应关闭所有的mongos进程、配置服务器,以及所有的分片。然后将配置服务器的数据目录复制到两台新的配置服务器上(这样三台配置服务器就可以拥有完全相同的数据目录)。接着,启动这三台配置服务器和所有分片。然后,将--configdb选项指定为这三台配置服务器,最后重启所有的mongos进程。
5. 数据均衡
通常来说,MongoDB会自动处理数据均衡。
在执行几乎所有的数据库管理操作之前,都应先关闭均衡器:
sh.setBalancerState(false)均衡器关闭后,系统则不会再进入均衡过程,但该命令并不能立即终止进行中的均衡过程:迁移过程通常无法立即停止。因此,应检查config.locks集合,以查看均衡过程是否仍在进行中:
> db.locks.find({"_id" : "balancer"})["state"]
0此处的0表明均衡器已被关闭。
均衡过程会增加系统负载:目标分片(要被迁移到的分片)必须查询源分片块中的所有文档,将文档插入目标分片的块中,源分片最后必须删除这些文档(相当于进行了一次块内数据查询 + 数据跨分片的拷贝)。
如果发现数据迁移过程影响了应用程序性能,可在config.settings集合中为数据均衡指定一个时间窗口。执行下列更新语句,均衡则只会在下午1点到4点间发生:
db.settings.update({"_id" : "balancer"},
{"$set" : {"activeWindow" : {"start" : "13:00", "stop" : "16:00"}}},true)注意,均衡器以块的数量(而非数据大小)作为衡量分片间是否均衡的指标。因此,如果A分片只拥有几个较大的数据块,而B分片拥有许多较小的块(但总数据大小比A小),那么均衡器会将B分片的一些块移至A分片,从而实现均衡。
6. 修改块大小
块中的文档数量可能为0,也可能多达数百万。
通常情况下,块越大,迁移至分片的耗时就越长。块的大小默认为64 MB,这个大小的块既易于迁移,又不会导致频繁的块拆分。
有时可能会发现移动64 MB的块耗时过长。可通过减小块的大小,提高迁移速度。使用shell连接到mongos,然后修改config.settings集合,从而完成块大小的修改:
db.settings.findOne({"_id":"chunksize"}) // 查找id为chunksize的文档,该文档就是记录块大小的文档
{ "_id" : "chunksize",
"value" : 64
}
> db.settings.save({"_id" : "chunksize", "value" : 32})如果发现MongoDB频繁进行数据迁移或单个文档的数据量较大,则可能需要增加块的大小。
7. 手动移动块
可在shell中使用moveChunk辅助函数手动移动块:
sh.moveChunk("test.users", {"user_id" : NumberLong("1844674407370955160")},"spock")以上命令会将包含文档user_id为1844674407370955160的块移至名为spock的分片上。必须使用片键来找出所需移动的块(本例中的片键是user_id)。
通常,指定一个块最简单的方式是指定它的下边界,不过指定块范围内的任何值都可以(块的上边界值除外,因为其并不包含在块范围内)。
8. 特大块
我们假设有一个分片集群的某个集合是以date字段(年/月/日)作为分片的。也就是说,mongos一天最多只能创建一个块(因为一天内的data字段值都相同,如果一个块内所有文档的片键的值相同,这个块是不会做块拆分的)。突然有一天业务量暴增导致这天产生的这个块特别的大,MongoDB不允许移动大小超出最大块大小设定值的块,因此如果块的大小超出了config.settings中设置的最大块大小,那么均衡器就无法移动这个块了。这种不可拆分和移动的块就叫做特大块。
出现特大块的表现之一是,某分片的大小增长速度要比其他分片快得多。也可使用sh.status()来检查是否出现了特大块:特大块会存在一个jumbo属性。
为修复由特大块引发的集群不均衡,就必须将特大块均衡地分发到其他分片上。
这是一个非常复杂的手动过程,而且不应引起停机(可能会导致系统变慢,因为要迁移大量的数据)。接下来,我们以from分片来指代拥有特大块的分片,以to分片来指代特大块即将移至的目标分片。注意,如有多个from分片,则需对每个from分片重复下列步骤。
关闭均衡器,以防其在这一过程中出来捣乱:
> sh.setBalancerState(false)MongoDB不允许移动大小超出最大块大小设定值的块,所以要记下特大块的大小,然后将最大块大小设定值调整为比特大块大一些的数值,比如10 000,块大小的单位是MB。
> use config
> db.settings.findOne({"_id" : "chunksize"})
{
"_id" : "chunksize",
"value" : 64
}
> db.settings.save({"_id" : "chunksize", "value" : 10000})使用moveChunk命令将特大块从from分片移至to分片。如担心迁移会对应用程序的性能造成影响,可使用secondaryThrootle选项,放慢迁移的过程,减缓对系统性能的影响:
> db.adminCommand({
"moveChunk" : "acme.analytics",
"find" : {"date" : new Date("10/23/2012")}, // 寻找片键值为10/23/2012的块
"to" : "shard0002", // 迁移到shard0002分片
"secondaryThrottle" : true
})secondaryThrottle会强制要求迁移过程间歇进行,每迁移完一些数据,需等待集群中的大多数分片成功完成数据复制后再进行下一次迁移。该选项只有在使用副本集分片时才会生效。如使用单机服务器分片,则该选项不会生效。
使用splitChunk命令对from分片剩余的块(即使这些块的数据不是很大)进行拆分,这样可以增加from分片的块数(这样做是为了不让其他分片又把他们的块迁移回from分片)。
将块大小修改回最初值:
> db.settings.save({"_id" : "chunksize", "value" : 64})启用均衡器:
> sh.setBalancerState(true)均衡器被再次启用后,仍旧不能移动特大块,不过此时那些特大块都已位于合适的位置了。
9. 防止出现特大块
随着存储数据量的增长,上一节提到的手动过程变得不再可行。因此,如在特大块方面存在问题,应首先想办法避免特大块的出现。
为防止特大块的出现的方法是细化片键的粒度。应尽可能保证每个文档都拥有唯一的片键值,或至少不要出现某个片键值的数据块超出最大块大小设定值(一旦超过块的最大值大小就无法块迁移)的情况。
例如,如使用前面所述的年/月/日片键,可通过添加时、分、秒来细化片键粒度。类似地,如使用粒度较大的片键,如日志级别,则可添加一个粒度较细的字段作为片键的第二个字段,如MD5散列值或UDID。这样一来,即使有许多文档片键的第一个字段值是相同的,但是第二个字段不同(第一个字段相同可以保证该字段相同的值是集中分布在一个或相近的多个块,第二个字段不同可以保证块无法拆分而形成特大块),也可一直对块进行拆分,也就防止了特大块的出现。
10. 刷新配置
最后一点,mongos有时无法从配置服务器正确更新配置。如发现配置有误,mongos的配置过旧或无法找到应有数据,可使用flushRouterConfig。
命令手动刷新所有缓存:
>db.adminCommand({"flushRouterConfig" : 1})如flushRouterConfig命令没能解决问题,则应重启所有的mongos或mongod进程,以便清除所有可能的缓存。