0. 前言:
自己的专栏越开越多,而对算法的学习一下子成为了最紧要的事情,这是因为在写商业计划书的过程中明确了自己接下来的技术栈是什么,就是区块链技术,而区块链技术离不开算法,只有深刻理解了算法,才能彻底掌握区块链技术,所以这个专栏将记录对算法的学习和实践过程.
在时间分配上,将每天上午的时间用在对算法的专研上,其余时间做其他事情,直到自己掌握区块链技术核心为止.
参考书籍:<算法导论>第三版
学习目标:
- 一周掌握算法入门知识
1.插入排序
因为学习时间紧迫,所以直入学习主题,排序问题:
输入:n个数的一个序列(a1,a2,…,an)
输出:输入序列的一个排列<a’1 , a’2,…,a’n>,满足a’1 <= a’2<=…<=a’n
排列的数称为关键词,关键词组成数组.实现代码使用UE5 C++,因为这是笔者现在使用的,所以最为便利.
插入排序就是字面意思,就是按照目标顺序将要排列的关键词放到对应的位置.
1.1 创建一个控制台程序
打开UE5编辑器,新建一个C++类继承Actor,命名为IntroductionToAlgorithm,打开代码编辑器,笔者使用Rider,其他的IDE,例如VS都是差不多的,创建好之后的代码如下:
// Copyright CloudHu. All Rights Reserved.
#pragma once
#include "CoreMinimal.h"
#include "GameFramework/Actor.h"
#include "IntroductionToAlgorithm.generated.h"
//日志目录声明
MYTESTPROJECT_API DECLARE_LOG_CATEGORY_EXTERN(LogIntroductionToAlgorithm, Log, All);
UCLASS()
class MYTESTPROJECT_API AIntroductionToAlgorithm : public AActor
{
GENERATED_BODY()
public:
// Sets default values for this actor's properties
AIntroductionToAlgorithm();
protected:
// Called when the game starts or when spawned
virtual void BeginPlay() override;
};
这个插入法其实和冒泡法很相似,实现算法代码如下:
void AIntroductionToAlgorithm::InsertionSort(TArray<int>& ArraySrc)
{
for (int j = 1; j < ArraySrc.Num(); ++j)
{
const int Key = ArraySrc[j];
int i = j - 1;
while (i > -1 && ArraySrc[i] > Key)
{
ArraySrc[i + 1] = ArraySrc[i];
i--;
}
ArraySrc[i + 1] = Key;
}
}
再声明一个数组来调用该方法进行排序:
void AIntroductionToAlgorithm::BeginPlay()
{
Super::BeginPlay();
TArray<int> ArrayTest{
2, 100, 4, 33, 0, 9, 1, 88, 12, 77, 3};
InsertionSort(ArrayTest);
for (auto& i : ArrayTest)
{
UE_LOG(LogIntroductionToAlgorithm, Log, TEXT("LogIntroductionToAlgorithm:%i"), i);
}
}
编译通过之后在编辑器中派生一个蓝图类,将该蓝图子类放到任意场景,然后运行,打开日志可以看到:
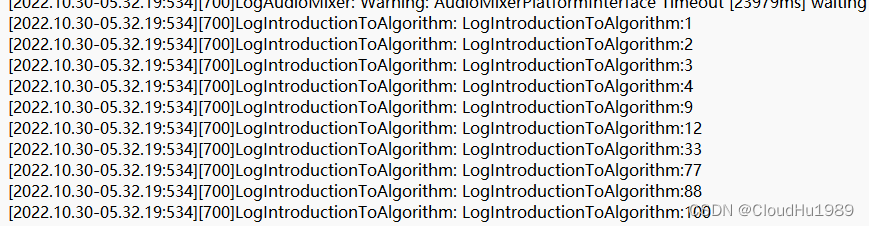
排序正确,说明算法没有问题.
冒泡法是比赛常用的方式,是将所有队伍进行分组,然后两两PK,晋级的进入上一个分组,阶梯一样往上晋级,直到决出最强.
这个插入法不是分组PK,而是逐个PK,直接将最小值或最大值插入到前排,个人觉得插入排序对比赛更公平些,因为不会出现死亡小组的情况,所以更公平.
大家如果经常看电子竞技就会发现分组的时候常常出现死亡小组,所谓的死亡小组就是那种必淘汰一个队伍的小组,弱队遇上是必死的,强强对决又会导致两个强队必然淘汰一个的局面,强队提前被淘汰是大家都不希望看到的,但是强强对决又特别精彩.
而插入排序来办比赛的话,每个队伍都要PK一次,效率固然低了,但是不会导致强队提前淘汰,原本这个强队的可以拿更好的名次,结果因为进了死亡小组导致提前淘汰,名次就比实际的实力低了.
但是我们实际上在比赛中都是采用冒泡法,这就是现实,效率比公平更重要.
冒泡法因为效率更佳,所以适合找到最大值和最小值,而这个插入排序适合对每一个元素进行排序,确保序列正确.
2. 分治法
所谓的分治法就是对复杂算法进行拆分,使其变成简单的算法,然后利用递归将简单算法的结果汇聚出来,从而解决复杂问题,这个很符合中国人大事化小的思维模式.
分治模式在每层递归时都有三个步骤:
- 分解:将复杂问题拆分成若干子问题,这些子问题是原问题较小规模的实例;
- 解决:递归解决子问题;
- 合并:将子问题的解合并成原问题的解.
2.1 归并排序
归并排序是完全遵循分治法的排序算法,操作如下:
- 分解:将待排序的n个元素的序列成各具n/2个元素的两个子序列,有点像切蛋糕;
- 解决:使用归并排序递归地排序两个子序列;
- 合并:合并两个已经排序的子序列,以产生排序的答案.
先写合并的函数,代码如下所示:
void AIntroductionToAlgorithm::Merge(TArray<int>& ArraySrc, const int Start, const int Mid, const int End)
{
//0.计算两个被拆分的子数组长度
const int Length1 = Mid - Start + 1;
const int Length2 = End - Mid;
//1.声明两个被拆分的子数组
TArray<int> TmpArr1;
TArray<int> TmpArr2;
//2.子数组的长度要比设计的更长一位,用来存储一个最大值
TmpArr1.SetNum(Length1 + 1);
TmpArr2.SetNum(Length2 + 1);
//3.将原本的数组一分为二,分别放进两个子数组
for (int i = 0; i < Length1; ++i)
{
TmpArr1[i] = ArraySrc[Start + i];
}
for (int i = 0; i < Length2; ++i)
{
TmpArr2[i] = ArraySrc[Mid + i + 1];
}
//4.设置一个最大值来阻断遍历到子数组的最末尾
TmpArr1[Length1] = 999;
TmpArr2[Length2] = 999;
//5.在遍历过程中对两个数组的值进行对比,取较小值放进原数组
int K1 = 0;
int K2 = 0;
for (int k = Start; k <= End; ++k)
{
if (TmpArr1[K1] <= TmpArr2[K2])
{
ArraySrc[k] = TmpArr1[K1];
K1++;
}
else
{
ArraySrc[k] = TmpArr2[K2];
K2++;
}
}
}
再写合并排序的函数:
void AIntroductionToAlgorithm::MergeSort(TArray<int>& ArraySrc, const int Start, const int End)
{
if (Start < End)
{
//计算分割原数组的中间值,然后递归对其进行排序
int Mid = (Start + End) / 2;
MergeSort(ArraySrc, Start, Mid);
MergeSort(ArraySrc, Mid + 1, End);
//合并最终结果
Merge(ArraySrc, Start, Mid, End);
}
}