论文:SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
代码:https://github.com/Visual-Attention-Network/SegNeXt
出处:NIPS 2022
贡献点:
- 证明了使用简单的卷积 encoder (深度可分离条状卷积)仍可以达到比使用 vision transformer 更好的效果,且对细节处理更好,计算量也更少
- 在 ADE20K, Cityscapes,COCO-stuff,Pascal VOC,Pascal Context,iSAID 的语义分割任务上都取得了很好的效果
一、背景

虽然 Transformer 相关方法占据了语义分割榜首,但本文作者就是要证明卷积网络依然能打,依然高效且效果好,能够比 Transformer 使用自注意力实现的编码网络更能提取上下文信息。
回顾一下之前表现较好的语义分割方法,如表 1 所示,作者认为一个好的方法要具有如下几个特征:
- 一个强的 backbone 作为 encoder:和 CNN 相比,Transformer 方法的 backbone 更强一些
- 多尺度信息交互:语义分割作为一个密集预测任务,需要处理不同尺度的目标
- spatial attention:空间 attention 能够让模型通过语义区域内的区域优先级进行分割(也就是寻找空间中不同像素的关系来指导分割)
- 低计算复杂度:尤其是处理高分辨率图像(如遥感、城市场景),低分辨率图很重要
基于上述讨论,本文作者重新思考了卷积中的 attention,并且提出了一个更高效的 encoder-decoder 结构 MSCA(multi-scale convolutional attention)。

语义分割模型一般可以分为两部分:encoder 和 decoder
- Encoder:前期一般使用如 ResNet、ResNeXt、DenseNet 等分类网络,但由于分割是密集预测任务,所以后面就有了 Res2Net、HRNet、SETR、SegFormer、HRFormer、MPViT、DPT 等专门为语义分割设计的网络
- Decoder:使用 decoder 可以从 encoder 编码特征中恢复更好的特征,会从多尺度感受野、多尺度语义特征、扩大感受野、加强边界信息、捕捉全局上下文等角度出发来实现
二、方法
2.1 Convolutional Encoder
Encoder 的结构类似 ViT,但还有些不同,没有使用 self-attention,使用了多尺度卷积 attention(multi-scale convolutional attention, MSCA, module)。
MSCA 的结构如图 2a 所示,包含三个部分:
- 深度可分离卷积来聚合局部特征
- 多分支深度可分离条状卷积,来捕捉多尺度上下文特征
- 1x1 卷积来建立不同分支之间的关系,1x1 卷积的输出作为 attention weights 来对 MSCA 的输入进行加权
MSCA 的公式如下:
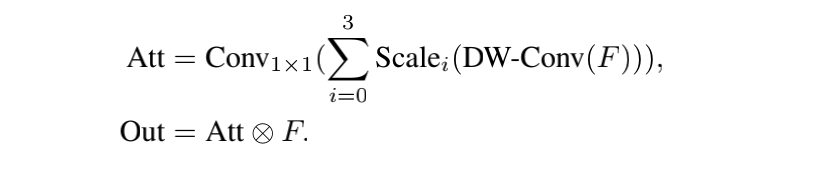
- F 是输入特征
- att 和 out 表示 attention map 和 output
- i 表示第 i 个分支,如图 2b,Scale0 表示恒等连接
- 在每个分支,使用两个 depth-wise strip convolution 来近似标准的大核 depth-wise convolution ,每个分支的卷积核大小分别为 7、11、21
为什么选择 depth-wise strip convolution 呢:
- strip conv 很轻量,标准的 7x7 卷积,可以使用一对儿 1x7 和 7x1 的卷积来实现
- 目标中有很多条状目标,如行人、电线杆等,strip conv 能够帮助提取条状目标特征
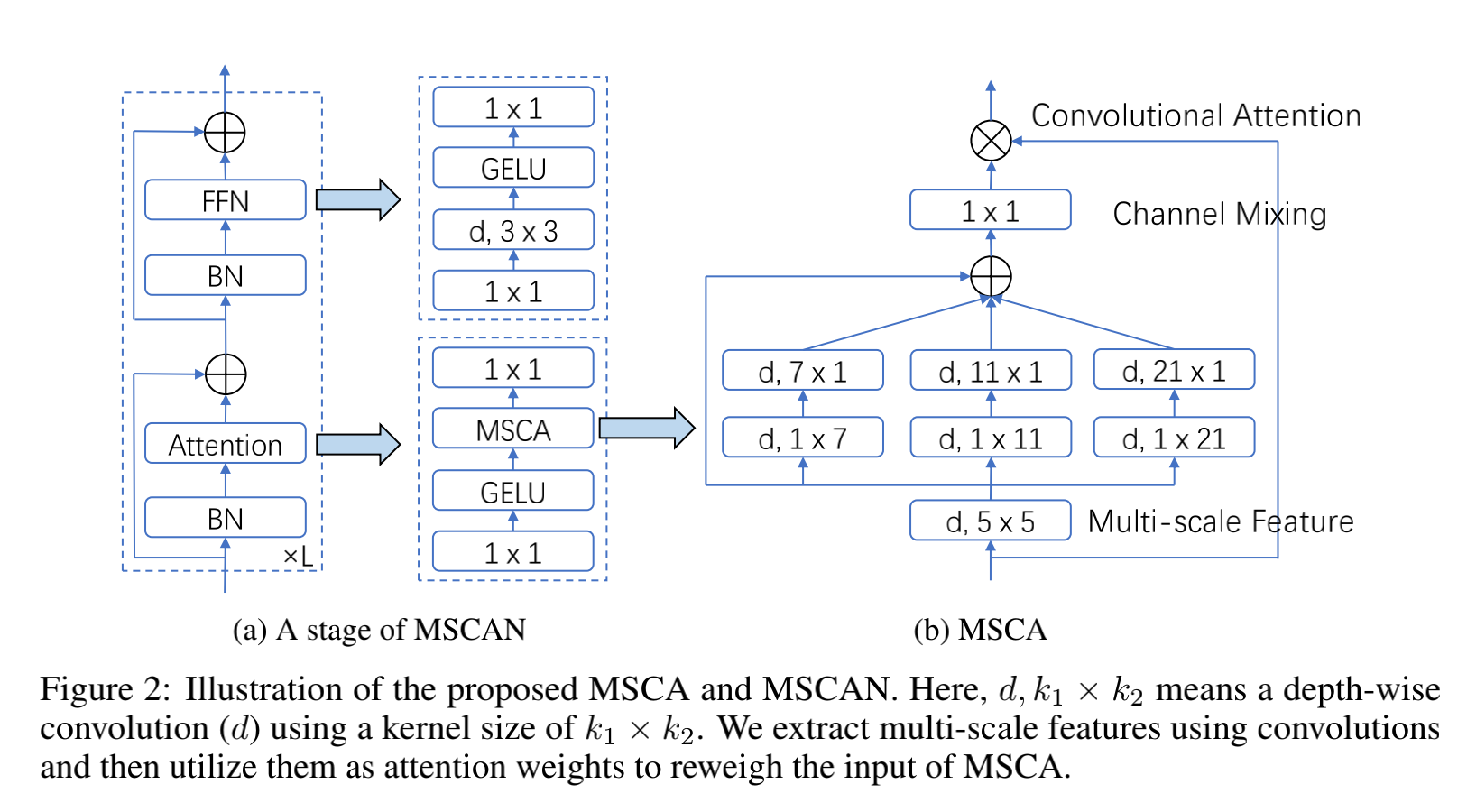
将一系列 MSCA 堆叠起来后,就得到了 MSCAN,使用的层级结构,包括 4 个 stage,每个 stage 的空间分辨率分别为 H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W、 H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H×8W、 H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W、 H 32 × W 32 \frac{H}{32} \times \frac{W}{32} 32H×32W,下采样是通过 3x3 s=2 的卷积 + BN 来实现的。
注意:MSCAN 里边都使用的 BN 而非 LN,也是经过实验证明 BN 效果更好
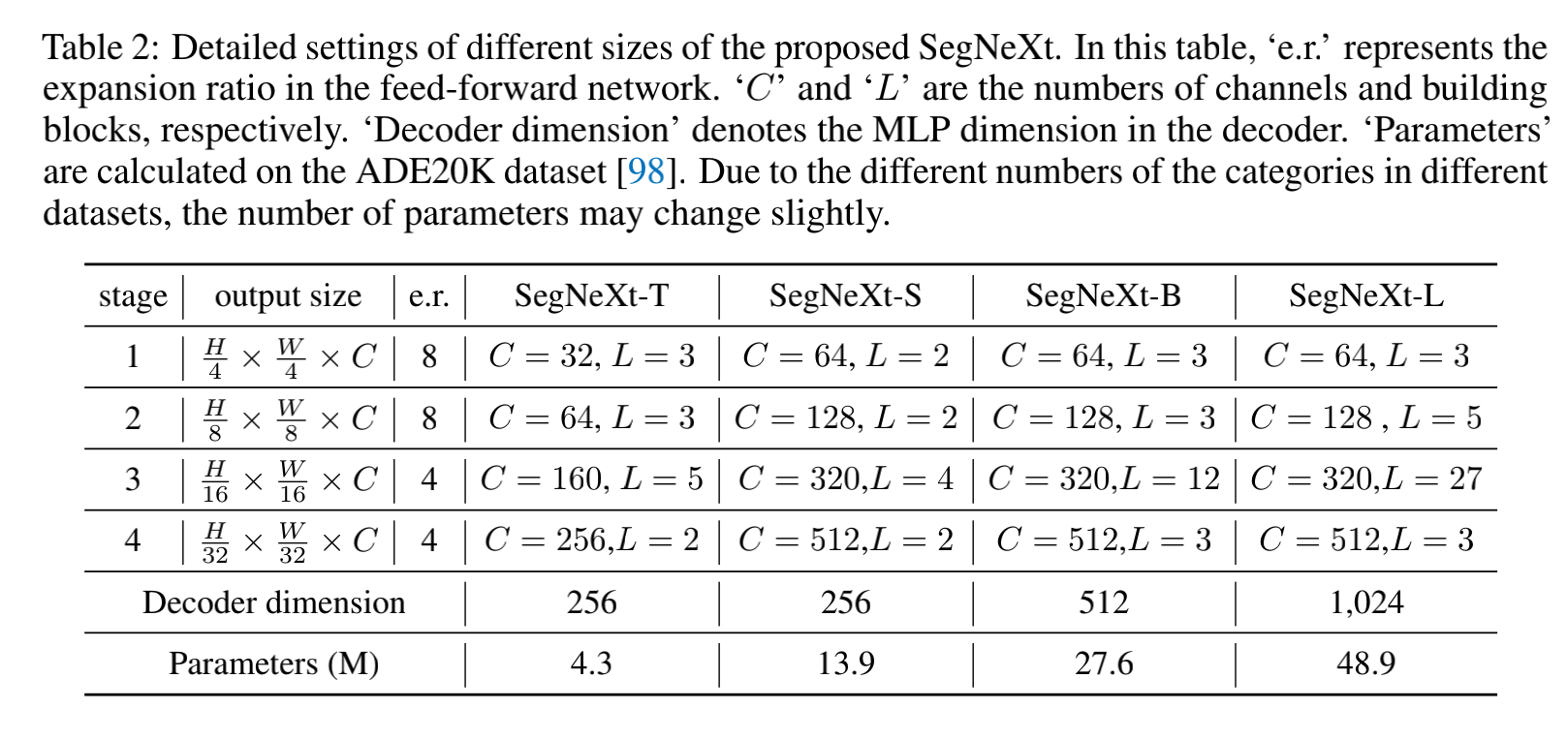
不同尺寸的模型结构如下:
2.2 Decoder
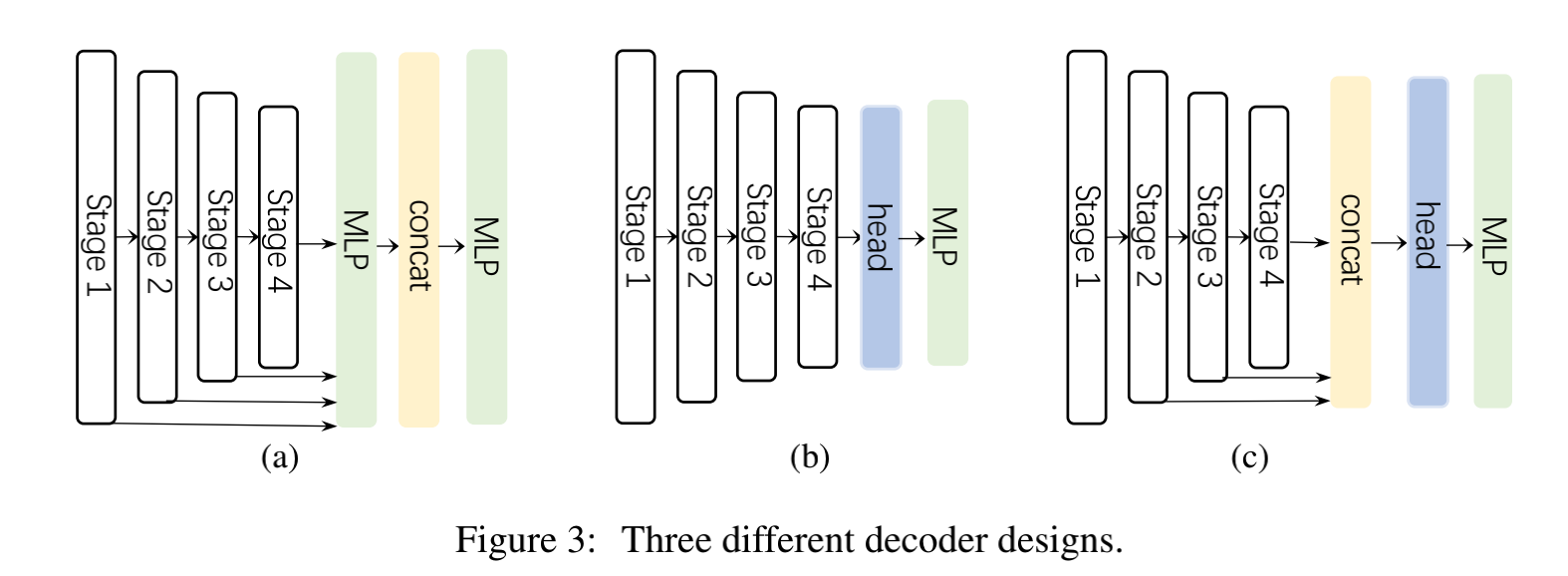
图 3 展示了 3 种不同的 decoder 结构:
- a:SegFormer 结构,是 MLP-based 结构
- b:CNN-based 结构,这种结构的输出一般直接作为其他解码头的输入,如 ASPP、PSP 等
- c:SegNeXt 结构:将 3 个 stage 的输入进行组合,然后提提取全局上下文特征。这里只使用了后三个 stage 的结果,这是因为 SegNeXt 是基于卷积的,第一个 stage 包含更多的低层特征,会影响效果,而且增加计算量。
三、效果
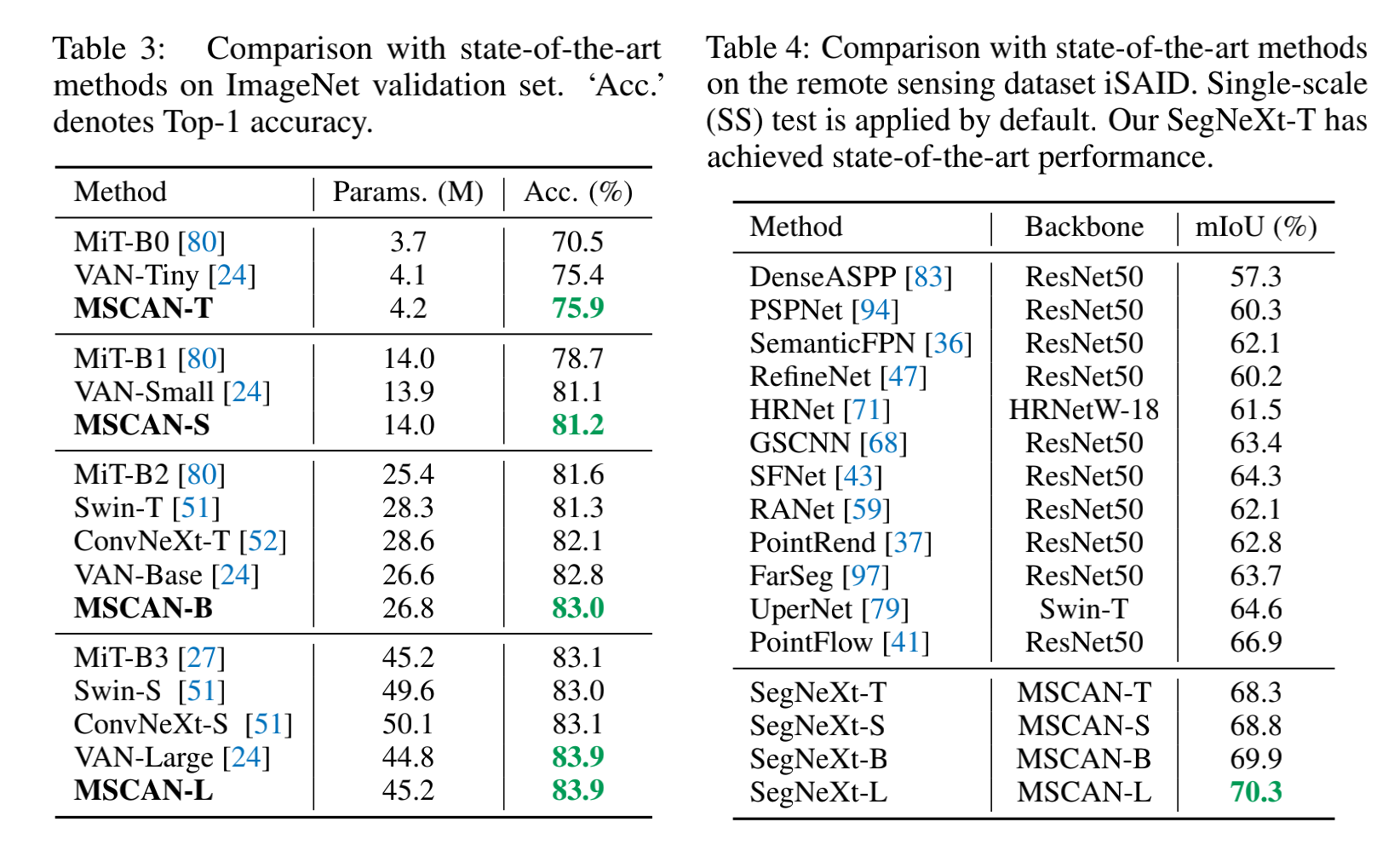
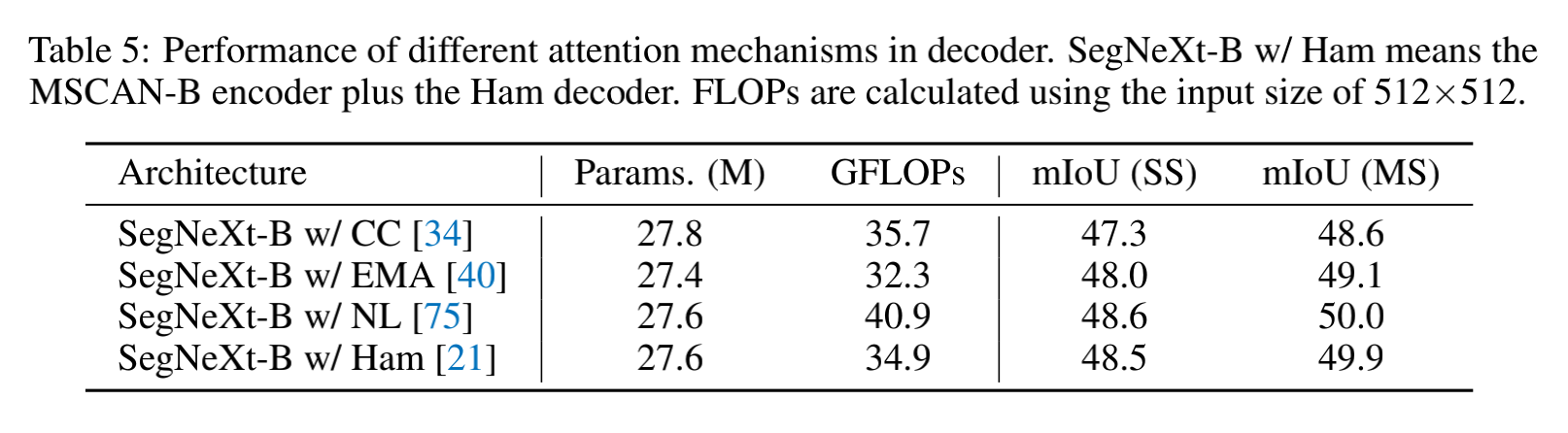
表 6 验证了 MSCA 的设计结构的不同效果:

表 7 验证了是否使用 stage 1 的效果:
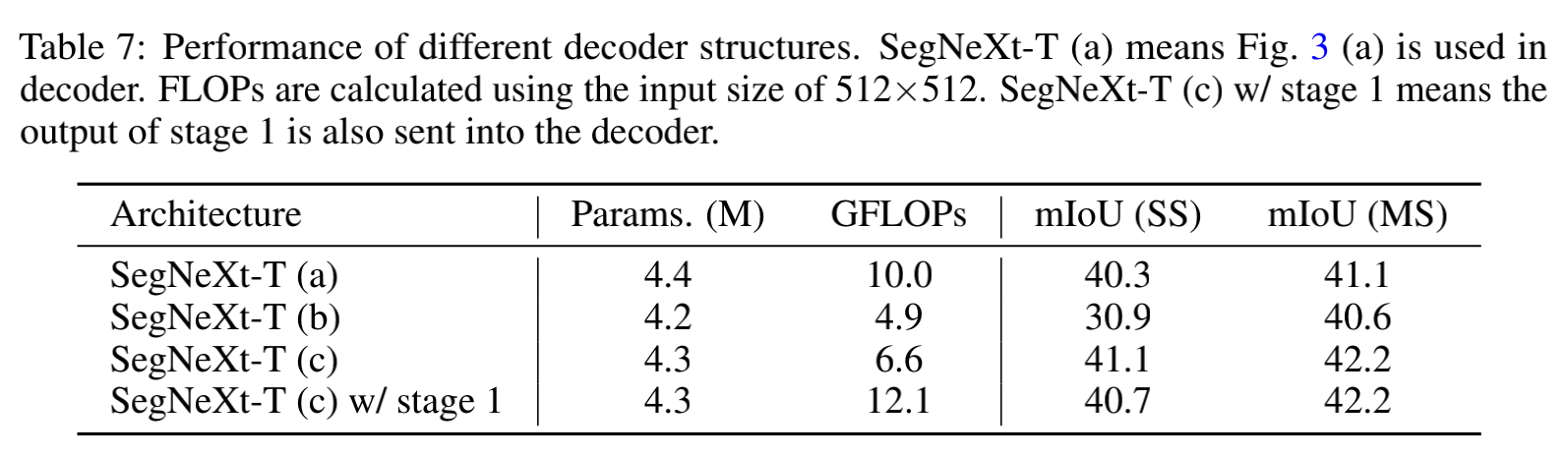
表 8 验证了 MSCA 的效果:

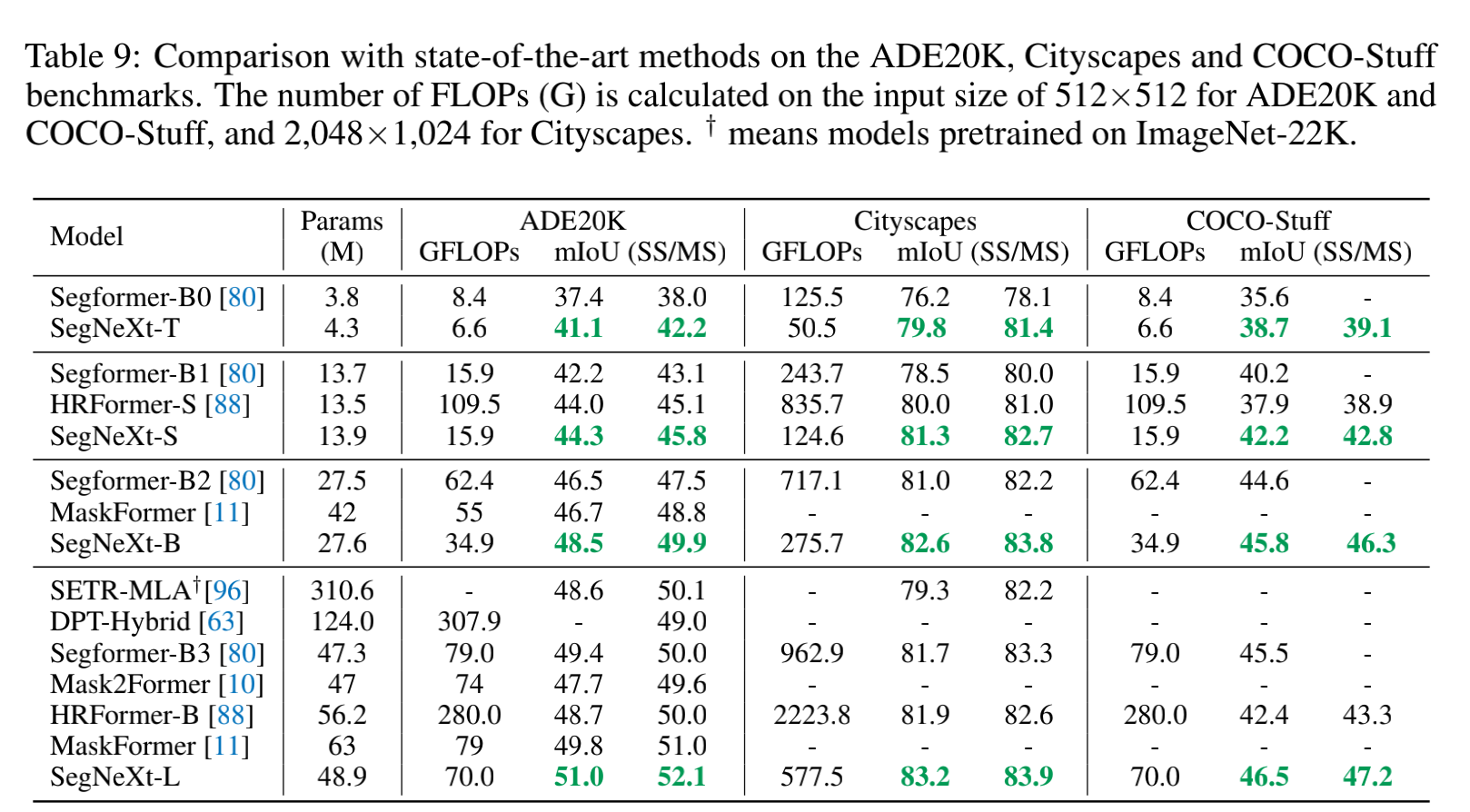
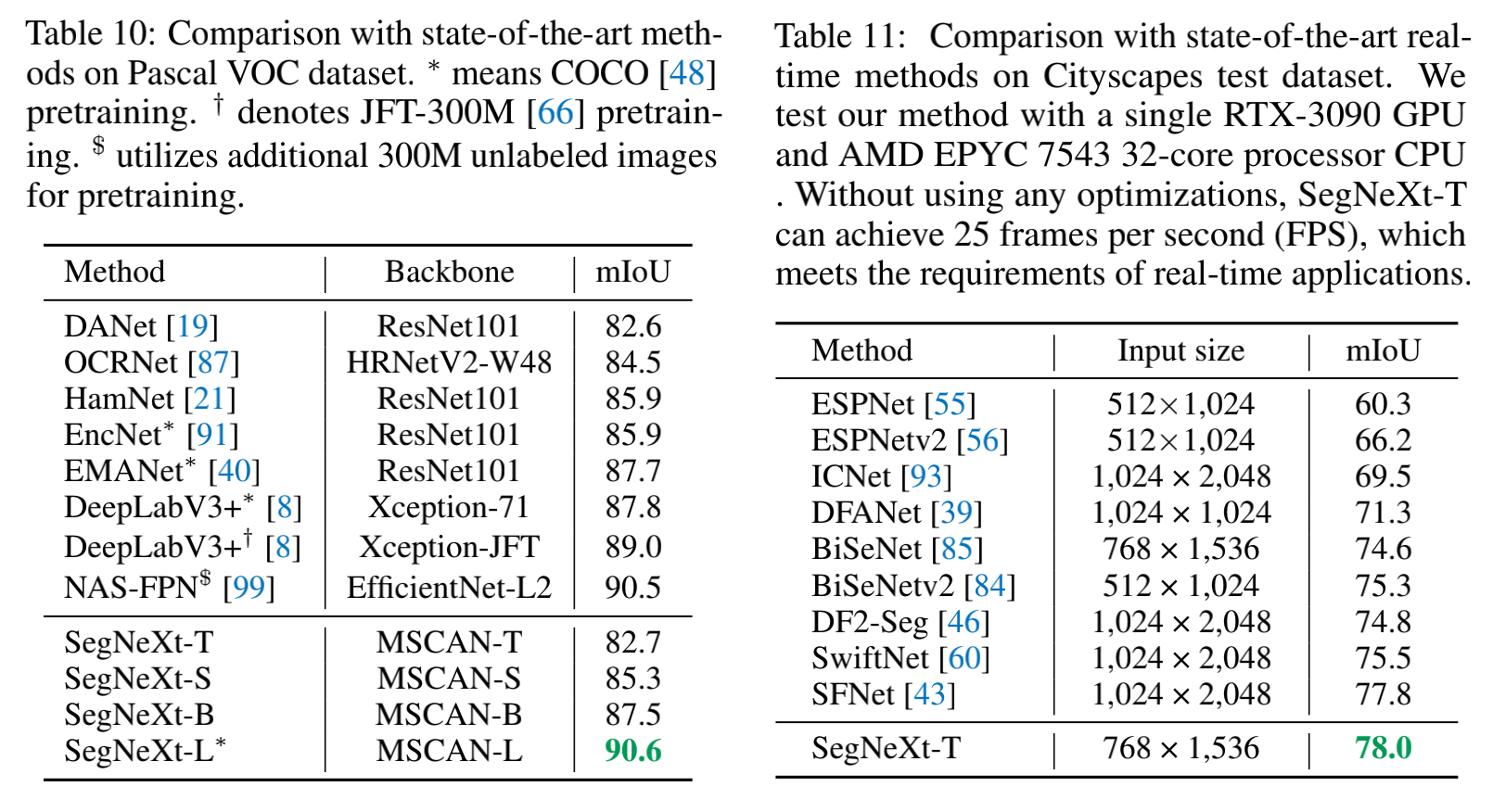
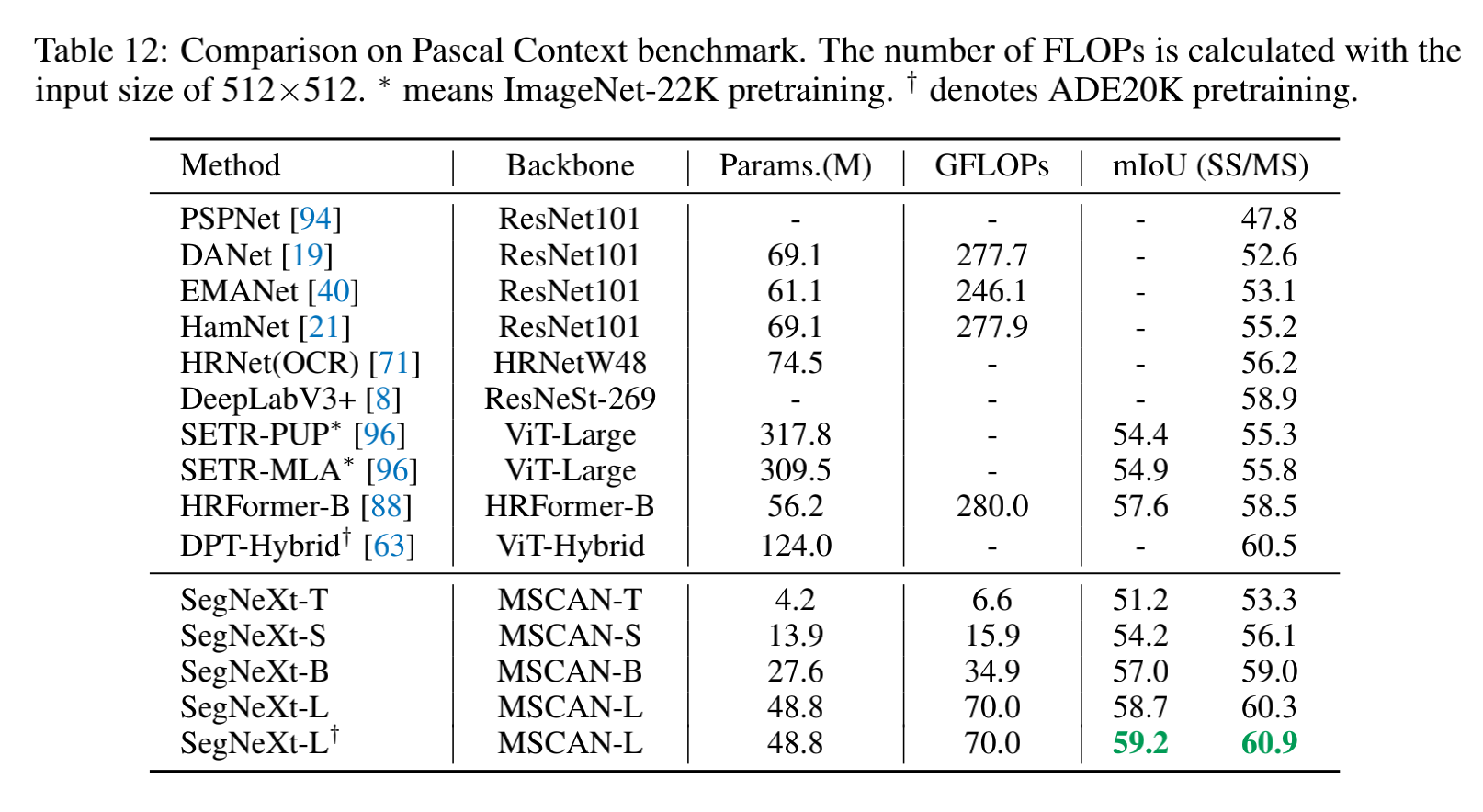
和 SOTA 的对比: