- 以
uer/roberta-base-finetuned-jd-binary-chinese为例,搜索
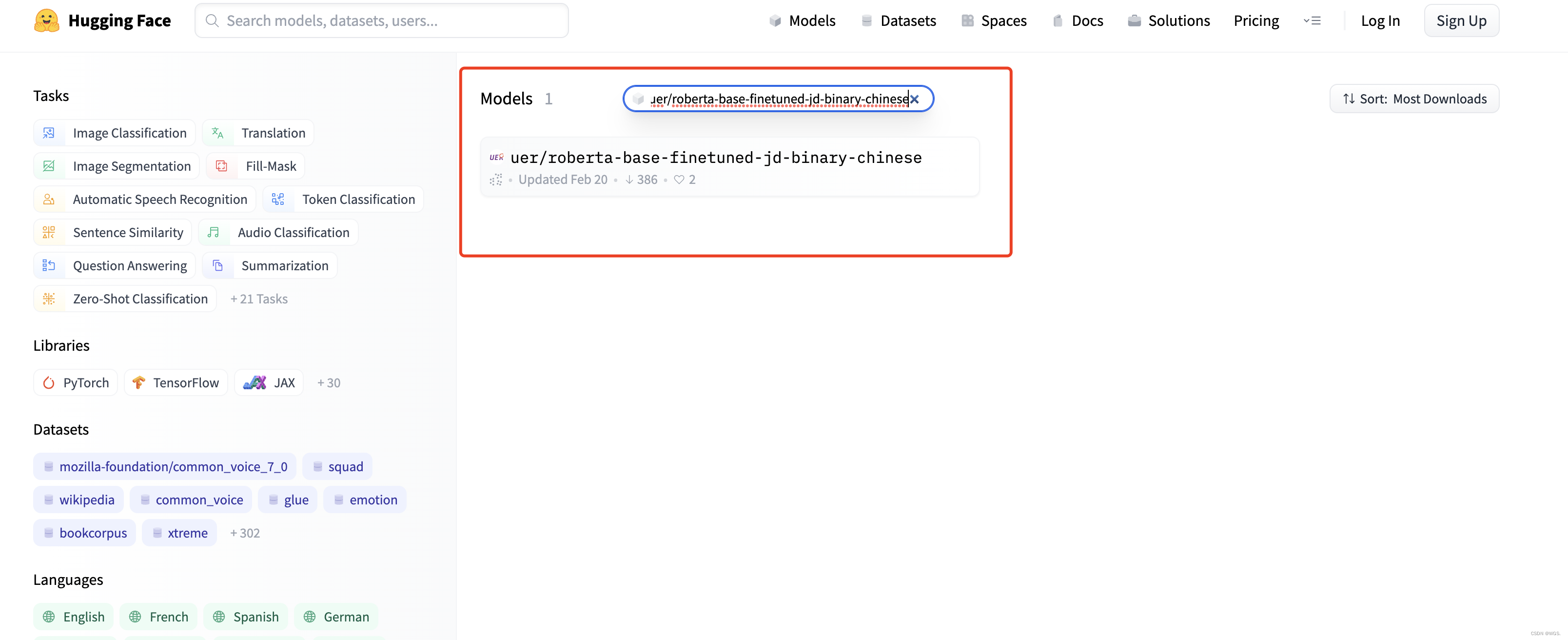
- 对于torch而言,下载下图所选文件即可
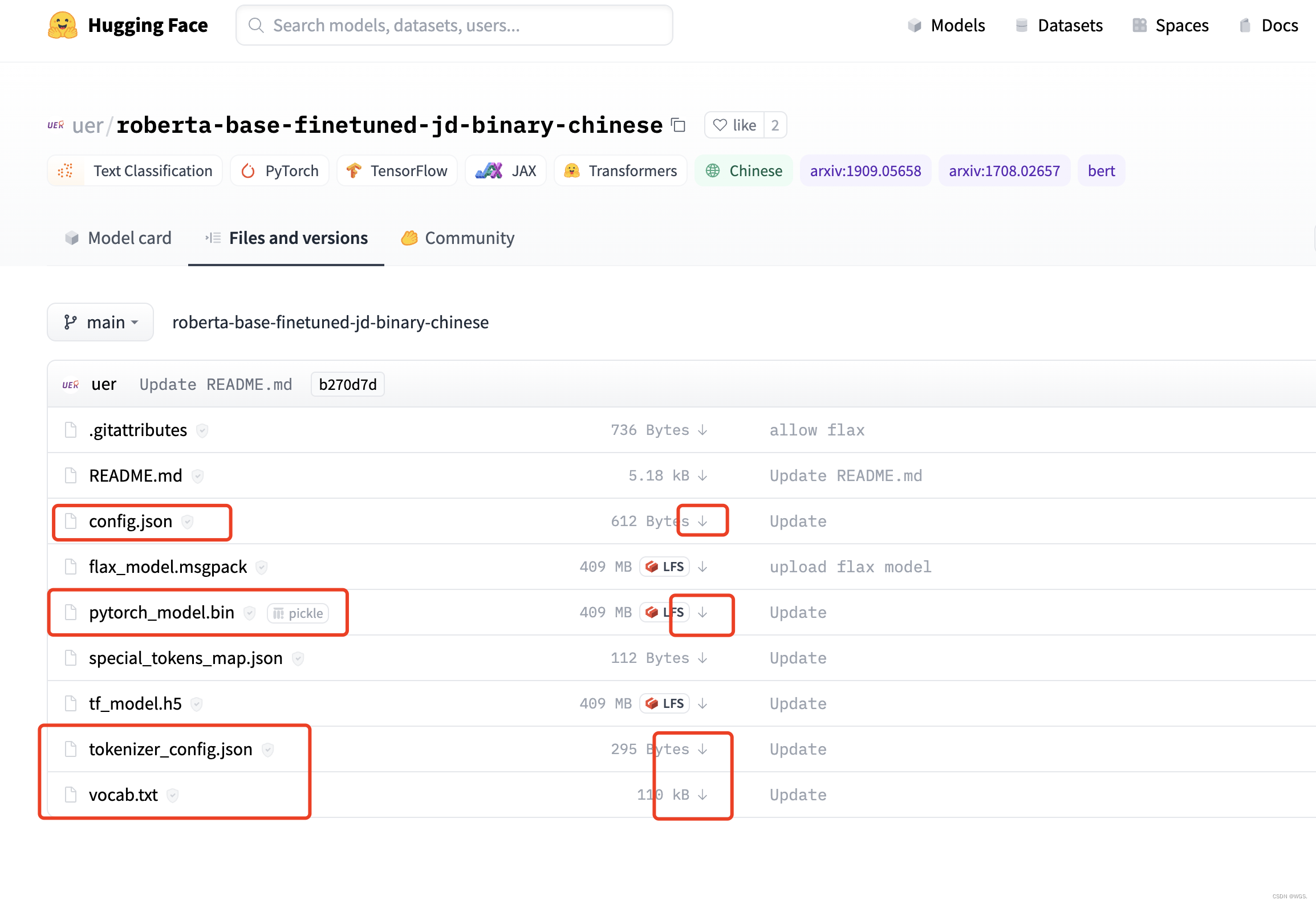
- 分词器和模型加载要一致:
# 上面下载的几个文件放在同一个目录下,目录名就起了模型名
pretrained_model_path = './bert_pretrain/roberta-base-finetuned-jd-binary-chinese'
self.tokenizer = BertTokenizer.from_pretrained(pretrained_model_path)
self.bert = BertModel.from_pretrained(pretrained_model_path, output_hidden_states=True, output_attentions=True, return_dict=False)