使用过CANoe的都知道,无论是TestModule的方式开发脚本还是通过vTESTstudio的平台开发脚本,最终都是要放在CANoe软件上进行自动化执行并生成测试报告,我们常见的测试报告主要是html,但是同时也会看到一个同名的xml文件,里面同样是我们的测试报告;同时还有另外一种报告格式vtestreport,这种是vector为了方便打开特大内存的报告所提供的专用报告类型,可以使用Vector CANoe Test Report Viewer。不过如果说是最容易解析的,个人认为还是xml格式的,无论是Python库的支持,还是xml的格式,都是上上之选,今天我们要说的也是通过Python解析xml报告。

如果想要解析xml文件,第一步我们要搞清楚里面的格式是什么样的,对于大部分初次看xml报告的人来说,每个报告中的格式都是有差异的,但是真的无法搞出来一个模板使用所有的测试报告吗?答案是肯定的,下面我们就来看下:
XML报告概览:
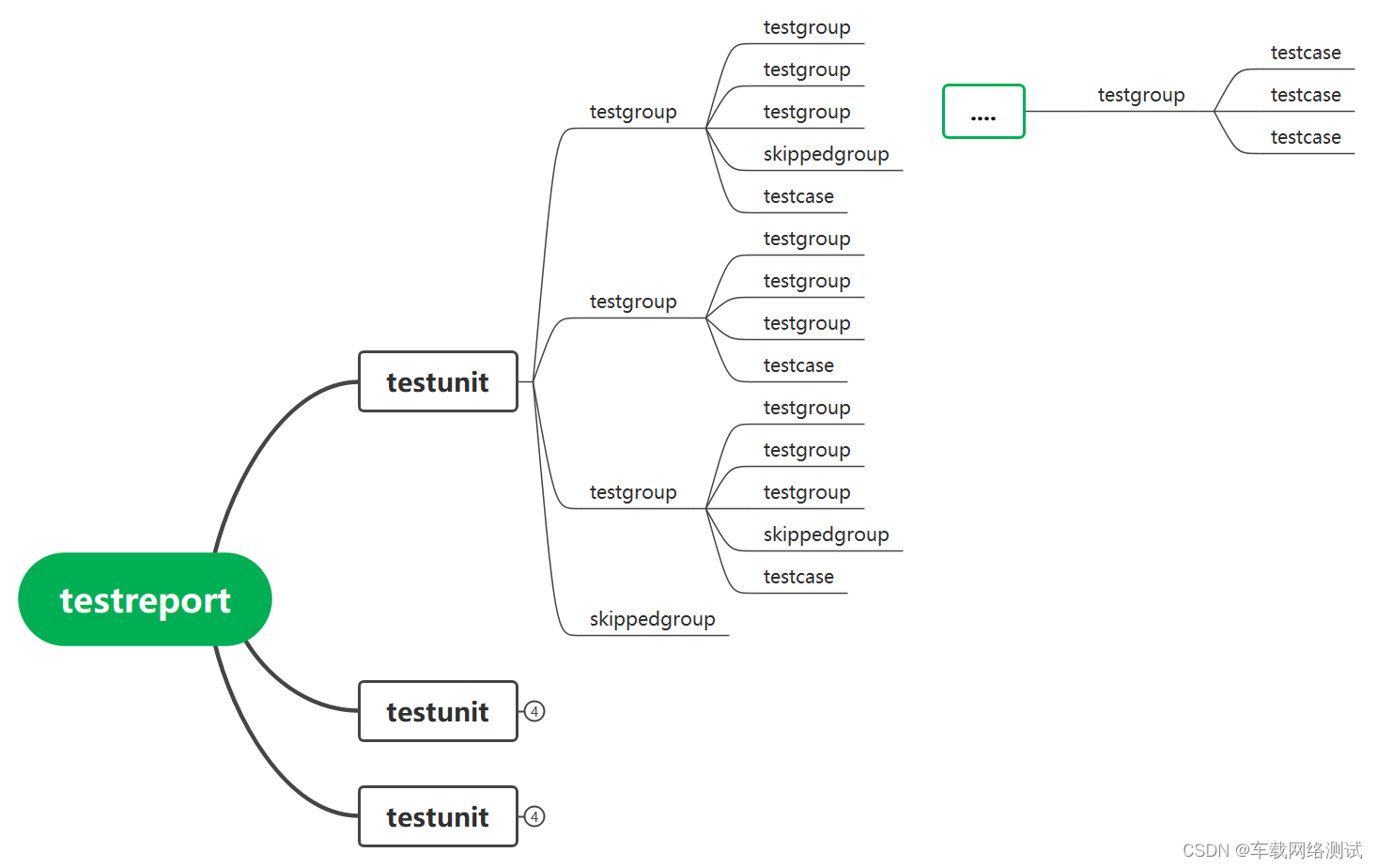
从上面的思维导图中我们能够看到,前面2层是确定的,testreport一定是在最外层,这个是xml报告最大的一个层级,然后下一步就是testunit层级,这一层代表我们的一个报告中可以包含多个testunit,也就是在我们的Test Configuration下添加多个.vtuexe文件(每个.vtuexe文件代表一个testunit);

在testunit下去后,基本就是我们在vTESTstudio工程中开发的脚本层级了,这里就到了testgroup层级;从这里开会下面可能会出现testgroup和testcase在同一层级的情况,亦或是testgroup叠加出现的情况,因此从这里开始我们就可以使用迭代的方式去不断的循环,直至找到所有的testcase。下图中在testunit下直接就是testcase,而没有testgroup,这也是一种情形,这种情况下,即可直接获取所有的testcase,而无需乡下循环查找了。(这里建议使用Python中的迭代方法实现)

以上就是vTESTstudio下开发的脚本在CANoe中执行生成的xml测试报告,层级很简单并且很清晰;当然对于初次看到xml报告的人来说,可能会出现有点懵的情况,不过如果能够结合CAPL脚本的话,很快就能够找到这个规律。
Python解析报告
获取全部的 testcase结果,并汇总
解析xml报告,将testunit中的所有testgroup组提取出来,为下一步处理提供前提条件;
def get_xml_elements(report_path_list):
for report_path in report_path_list:
result_list = list()
sources_report = Elements.parse(report_path)
report_unit = sources_report.getroot()
for test_units in report_unit:
if test_units.tag in "testunit":
for test_unit in test_units:
if test_unit.tag in "testgroup":
self.get_test_group_info(test_unit)
else:
test_module_name = report_path.split(" ")[-1][: -4]
result = f"{test_module_name} result number {self.pass_num+self.fail_num} pass {self.pass_num} fail {self.fail_num}"
self.result_all = self.result_all + result
print("%s result number %d pass %d fail %d" %
(report_path.split("\\")[-1][: -4], self.pass_num + self.fail_num, self.pass_num, self.fail_num))
break获取所有testgroup中的testcase结果
解析testgroup,循环去除每一条testcase,其中testgroup可能会出现迭代出现的情况,大家可以使用Python中迭代实现,或者根据实际情况循环取出都可以。
def get_test_group_info(self, test_group_unit):
for test_groups in test_group_unit:
if test_groups.tag in "testcase":
for test_case in test_groups:
self.get_test_case_info(test_case)
elif test_groups.tag in "testgroup":
for test_group in test_groups:
if test_group.tag in "testcase":
for test_case in test_group:
self.get_test_case_info(test_case)获取单个testcase中的 测试结果
并将testcase中的需要使用的内容进行提取并保存放在不同的列表中,以供后续使用。
def get_test_case_info(self, test_case):
if test_case.tag in "verdict":
if test_case.attrib.get('result') in "pass":
self.pass_num += 1
else:
self.fail_num += 1
self.testcase_result_list.append(test_case.attrib.get('result'))
elif test_case.tag in "title":
self.testcase_name_list.append(test_case.text)以上就是我们通过Python将xml文件进行解析,并将里面的pass、fail结果进行汇总输出,最终拿到一个整体测试结果概览,这样能够快速的给到测试人员进行快速的排查问题,而不用一个个报告打开进行确认,我们只需要打开需要确认的最终测试结果的报告即可。当然如果我们需要进一步将每个testunit、testgroup、testcase用例编号、用例描述都进行整理,也是可以的,只需要将他们添加到对应列表然后写入xls文件即可,这样就能最快速度的得到一个测试报告;
测试报告概览

测试模块 |
用例总数 |
Pass |
fail |
通过率 |
诊断层 |
1666 |
1532 |
134 |
91.96% |
通信层 |
321 |
298 |
23 |
92.83% |
DoIP |
222 |
196 |
26 |
88.29% |
SomeIP |
368 |
333 |
35 |
90.49% |
网络管理 |
99 |
88 |
11 |
88.89% |
汇总 |
2676 |
2447 |
229 |
91.44% |
通过这种方法,我们想象一下如何对于每条测试结果进行自动化分析???