文章目录
第一部分
商店数据来自天池口碑商家客流量预测比赛,这里只筛选了一部分数据。“shop_payNum_new.csv”的数据各个字段的含义如下表所示:

绘制所有便利店的10月的客流量折线图
数据探索
我们首先导入数据,看看数据的情况如何
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import warnings
import random
import pylab as mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
warnings.filterwarnings('ignore')
data_shop=pd.read_csv('dataset/shop_payNum_new.csv')
data_shop

接着,我们采用字符串分割的方法得到所有十月份的数据,并且按照便利店的id进行group分组,然后我们计算并绘制每个商家的数据所含日期数
# 提取出十月份的数据
data_sep=data_shop[data_shop['time_stamp'].str.split('-',expand=True)[1]=='10']
# 按商家id分组
shop_list=list(data_sep.groupby('shop_id'))
xvalues=list(range(41))
plt.figure(figsize=[16,8])
plt.xlabel('商家')
plt.xticks(range(len(xvalues)),xvalues)
plt.ylabel('商家的日期数据数')
plt.title('商家的数据缺失情况')
plt.plot(np.array([shop_list[i][1].shape[0] for i in range(len(shop_list))]))
通过下图我们可以发现,很多的商家是有数据缺失的,我们考虑用0值填充

残缺值处理
由于部分便利店的数据有缺失(某些日期的数据缺失),我们首先生成一个datestamp数据,然后将其转化为dataframe,并与原数据进行merge,最后用0值对数据进行填充,在完成数据的填充之后,我们再次绘图查看数据情况
def fix_df(df,T_df):
df['time_stamp']=df['time_stamp'].astype('datetime64')
df=df.merge(T_df,how='right',sort=True)
df.fillna(0,inplace=True)
return df
# 将元组转换为list
shop_list=[list(shop_list[i]) for i in range(len(shop_list))]
t_index = pd.date_range('2016-10-01', '2016-10-31', freq='D')
T_df=pd.DataFrame(t_index,columns=['time_stamp'])
# 处理残缺值
for i in range(len(shop_list)):
if shop_list[i][1].shape[0]!=31:
shop_list[i][1]=fix_df(shop_list[i][1],T_df)
xvalues=list(range(41))
plt.figure(figsize=[16,8])
plt.xlabel('商家')
plt.xticks(range(len(xvalues)),xvalues)
plt.ylabel('商家的日期数据数')
plt.title('商家的数据缺失情况')
plt.plot(np.array([shop_list[i][1].shape[0] for i in range(len(shop_list))]))

我们可以发现,现在所有的数据都已经填充完毕,可以进行可视化了
绘制图像
由于我想要在同一幅图中可视化所有商家的10月份的客运量,所以我采取三维趋势图来可视化所有商家在10月份的客运量曲线图
fig = plt.figure(figsize=[15,15])
ax = fig.add_subplot(111, projection='3d')
lens=shop_list[0][1].shape[0]
xs = list(range(lens)) #数据在x轴上的坐标
for z in range(len(shop_list)):#这里我们设置z=0到2,代表周一到周三
# ys = np.random.rand(24)*100 #数据在y轴上的坐标
ys=shop_list[z][1]['pay_num']
# color = plt.cm.Set2(random.choice(range(plt.cm.Set2.N))) #得到一个随机的颜色用于下面绘制该条折线图
ax.plot(xs, ys, zs=z, zdir='y',marker='o', alpha=0.6,linewidth=3)
font1 = {
'weight' : 'normal',
'size' : 23,
}
#在设置zdir = 'y'的情形下,其实y轴才是z轴,然后z轴变成了y轴
ax.set_xlabel('日期',font1)
ax.set_ylabel('商家',font1)
ax.set_zlabel('客流量',font1)
ax.view_init(elev=30,azim=60)
plt.show()

采取这种可视化方式可以很好的看出各个商家的客运量关系
选择一个商家,统计每月的总客流量,绘制柱状图
数据处理
我们首先选择id为14的商家,并利用字符串拼接得到新的属性:月份
# 选择商家id==14,添加新属性: 月
data_14=data_shop[data_shop.shop_id==14]
data_14['month']=data_14['time_stamp'].str.split('-',expand=True)[1].astype(int)
data_14

然后通过groupby函数和聚合函数sum便可计算出这个商家每月的总客流量
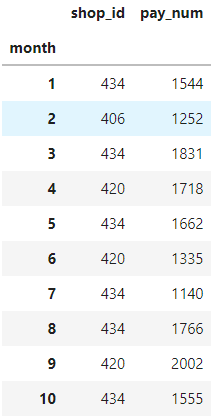
data_mean=data_14.groupby('month').sum()
data_mean
绘图
在设置好绘图风格之后,我们便可绘制柱状图
# 设置绘图风格
plt. style.use("ggplot")
# 设置中文编码和符号的正常显示
plt.rcParams["font.sans-serif"] = "KaiTi"
plt.rcParams["axes.unicode_minus"] = False
font1 = {
'family':'SimHei',
'weight' : 'normal',
'size' : 15,
}
fig_total=data_mean.plot(kind='bar',y=['pay_num'],figsize=[16,8])
fig_total.set_title('商家(id=14)每月的总客流量',font1)
fig_total.set_xlabel('月份',font1)
fig_total.set_ylabel('总客流量',font1)

选择一个商家,统计某个月中,周一到周日的每天平均客流量,并绘制柱状图
数据处理
根据我的调查,2016-01-01为星期五,于是我们根据一定的计算,为数据集添加了一个新属性:礼拜天(周一,周二,。。),然后,我们便可以根据礼拜天进行groupby分组和mean聚合计算,得到了id=14的商家在一月份的,(周一,周二,。。)各自的平均客流量,然后我们绘制柱状图
# 据调查,2016-01-01为星期五
# 选择id=14的商家
data_14=data_shop[data_shop.shop_id==14]
# 设置月份
data_14['month']=data_14['time_stamp'].str.split('-',expand=True)[1].astype(int)
# 选择1月份
data_14=data_14[data_14.month==1]
# 添加周几的属性
day_14=pd.DataFrame({
'day':[(x+5-1)%7+1 for x in list(range(31))]})
data_14['day']=day_14
data_14

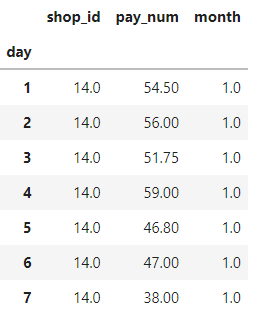
day_mean=data_14.groupby('day').mean()
day_mean
绘图
font1 = {
'family':'SimHei',
'weight' : 'normal',
'size' : 15,
}
fig_mean=day_mean.plot(kind='bar',y=['pay_num'],figsize=[16,8])
fig_mean.set_title('商家(id=14)一月份每周的平均客流量',font1)
fig_mean.set_xlabel('工作日',font1)
fig_mean.set_ylabel('平均客流量',font1)

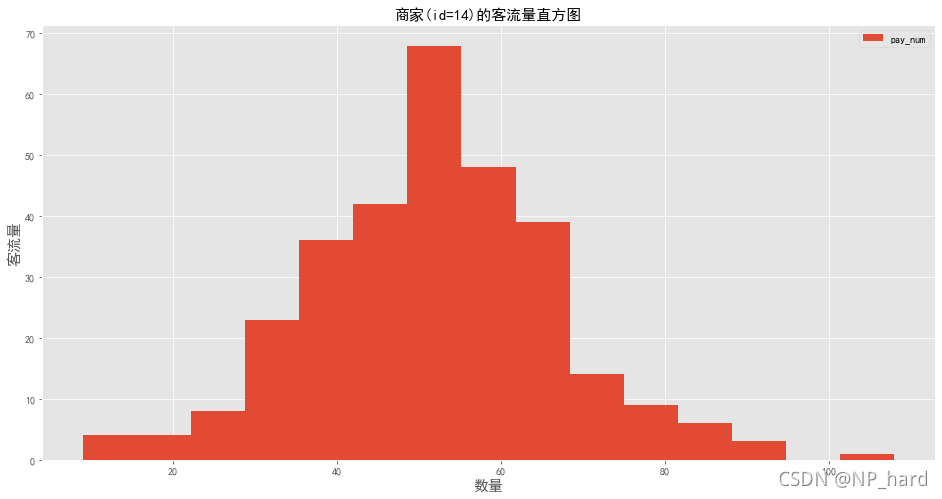
选择一个商家,绘制客流量直方图
我们选择了商家(id=14)来绘制客流量直方图
font1 = {
'family':'SimHei',
'weight' : 'normal',
'size' : 15,
}
data_14=data_shop[data_shop.shop_id==14]
fig_hist=data_14.plot(y=['pay_num'], kind='hist',figsize=[16,8],bins=15)
fig_hist.set_title('商家(id=14)的客流量直方图',font1)
fig_hist.set_xlabel('数量',font1)
fig_hist.set_ylabel('客流量',font1)
选择一个商家,绘制客流量密度图
我们选择了商家(id=14)来绘制客流量直方图
font1 = {
'family':'SimHei',
'weight' : 'normal',
'size' : 15,
}
data_14=data_shop[data_shop.shop_id==14]
fig_hist=data_14.plot(y=['pay_num'], kind='kde',figsize=[16,8])
fig_hist.set_title('商家(id=14)的客流量密度图',font1)
fig_hist.set_xlabel('数量',font1)
fig_hist.set_ylabel('客流量密度',font1)

统计某个月各个类别商店总客流量占该月总客流量的比例,绘制饼图
我们选择了一月份的数据,接着,我们通过groupby函数按类别分组,最后通过pandas的计算函数得到了各类别的名字list和各个类别的改月份的总客流量,最后绘制饼图
data_cake=data_shop.copy()
data_cake['month']=data_cake['time_stamp'].str.split('-',expand=True)[1].astype(int)
# 提取一月
data_cake1=data_cake[data_cake['month']==1].reset_index(drop=True)
# 计算一月的总客流量和各类别的客流量
group_cake=data_cake1.groupby('cate_2_name').groups
cake_list=[]
for name,ind in group_cake.items():
tmp_sum=data_cake1.iloc[ind,:]['pay_num'].sum()
tmp_dict={
name:tmp_sum}
cake_list.append(tmp_dict)
# 画饼图
label_cake=[list(i.keys())[0] for i in cake_list]
sum_cake=[list(i.values())[0] for i in cake_list]
colors = ['tomato', 'lightskyblue', 'goldenrod', 'green']
explode = (0.15, 0.1, 0.05, 0) # 0.1为第二个元素凸出距离
plt.figure(figsize=(10, 6))
plt.pie(x=sum_cake,labels= label_cake,autopct='%0.2f%%',colors=colors,explode=explode,pctdistance=0.8)
plt.title('各个类别商店总客流量比例')
plt.axis('equal')
plt.legend(loc='upper left')
plt.show()

第二部分
数据来源
“pima.csv”数据前9个字段的含义:
(1)Number of times pregnant
(2)Plasma glucose concentration a 2 hours in an oral glucosetolerancetest
(3)Diastolic blood pressure (mm Hg)
(4)Triceps skin fold thickness (mm)
(5)2-Hour serum insulin (mu U/ml)
(6)Body mass index (weight in kg/(height in m)^2)
(7)Diabetes pedigree function
(8)Age (years)
(9)Class variable (0 or 1)
任选两个字段绘制散点图
数据处理
我们首先读入数据,然后按照类别分为两部分数据(good:class=1,bad:class=0)
data1=pd.read_csv('dataset/pima.csv',header=None)
data1.columns=list('abcdefghi'.upper())
group=data1.groupby('I').groups
good=data1.iloc[group[1],:]
bad=data1.iloc[group[0],:]
bad.shape[0]+good.shape[0]==data1.shape[0]
True
绘图
我们挑选了属性(Body mass index)和(Diabetes pedigree function)来绘制散点图
good_scatter=good.loc[:,['F','G']]
bad_scatter=bad.loc[:,['F','G']]
plt.figure(figsize=[12,8])
plt.title('两个字段的散点图',font1)
plt.xlabel('Body mass index',font1)
plt.ylabel('Diabetes pedigree function',font1)
plt.scatter(good_scatter.iloc[:,0],good_scatter.iloc[:,1])
plt.scatter(bad_scatter.iloc[:,0],bad_scatter.iloc[:,1])
plt.legend('upper',fontsize='medium')

使用全部或者部分特征绘制散布图
from pandas.plotting import scatter_matrix
colors=['orangered','dodgerblue']
fig_scatter=scatter_matrix(data1.loc[:,['A','C','E','F']], figsize=(15, 15), diagonal='kde', marker='o', \
s=40, alpha=0.4,color=data1['I'].apply(lambda x : colors[x]))

绘制调和曲线图
我们选择了属性Number of times pregnant来绘制调和曲线图
from pandas.plotting import andrews_curves
andrews_curves(data1,'A')

我们选择了属性class来绘制调和曲线图
andrews_curves(data1,'I')
