点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:CVHub

Title: FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
Paper: https://arxiv.org/abs/2303.14189
导读
本文介绍了一种新颖的混合视觉架构——FastViT,其有机的结合了CNNs和Transformer,无论在精度或者运行效率上均有了稳定的提升。FastViT的主要贡献是引入了一种新的Token混合算子,命名为叫做RepMixer,听名字就知道结合结构重新参数化技术啦。该算子的作用原理是通过消除网络中的skip connection来降低内存访问成本。与此同时,本文还采用了traintime overparametrization和大内核卷积等技术来提高精度。
实验结果表明,FastViT:
在移动设备上的速度比最近的混合
Transformer架构CMT快3.5倍!在
ImageNet数据集上的精度相同,但速度比EfficientNet快4.9倍且比ConvNeXt快1.9倍!在相似的延迟下,
FastViT在ImageNet上的Top-1精度比MobileOne高出4.2%!
就问你服不服?总而言之,FastViT在多个任务(图像分类、检测、分割甚至是 3D 网格回归)上的表现均优于竞争对手,特别是在移动设备和桌面GPU上都有显着的延迟改进。此外,FastViT模型能够较好的适应域外和破损数据,相较于其它SOTA架构具备很强的鲁棒性和泛化性能。说得我都想赶紧替换上去了,真香!
方法

上图为FastViT的整体框架图,如上所述,这是一种混合Transformer模型,其架构是基于CVPR'2022 Oral上的一篇工作PoolFormer改进的:

PoolFormer is instantiated from MetaFormer by specifying the token mixer as extremely simple operator, pooling. PoolFormer is utilized as a tool to verify MetaFormer hypothesis "MetaFormer is actually what you need" (vs "Attention is all you need").
时间宝贵,我们参照上面示意图快速过一下。
上述框架图中最左侧的部分是整体的模块示意图,共包含一个Stem层和四个Stage,分别作用在不同的尺度上,最后是接入一个 的深度可分离MobileOne块和一个平均池化层直接套个全连接输出最终的分类结果。
首先,从上往下观察,Stem部分在右上角那里,同其余Stage内的模块一样,都是套用了结构参数化技术,常规套路,用于推理时融合算子加速用的。其次,可以看到,针对每个Stage的不同特性,这里采用不同的结构去捕获不同层级的特征。具体的,看下图(a)先,这里主要引入了
可以看到,针对每个Stage的不同特性,这里采用不同的结构去捕获不同层级的特征,但整体范式上还是套用了结构参数化技术,常规套路。先看下图(a)部分,此处主要采用了分解机制。图(c)部分眼熟的小伙伴一眼就闻到了ConvNeXt的味道,(⊙o⊙)…。重点可能是放在图(d),也就是本文反复强调的RepMixer,跟MetaFormer一样,也是一种Token混合算子,主要功效是对跳跃连接进行重参数化改造,有助于减轻内存访问成本。
类似于ConvNeXt,FastViT也是由里而外逐步做实验去优化的,具体的改进方案如下所示:

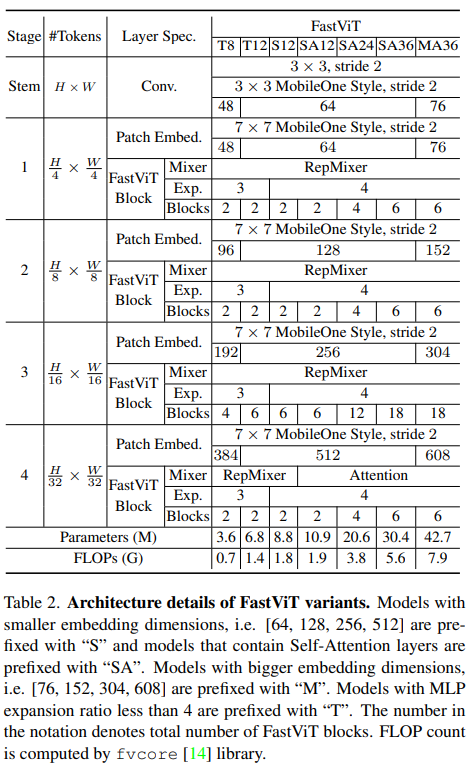
下表给出它的不同配置:
为了验证重参数化跳跃连接的好处,作者对MetaFormer架构中最高效的Token混合算子之一,即Pooling和RepMixer进行了相关实验:
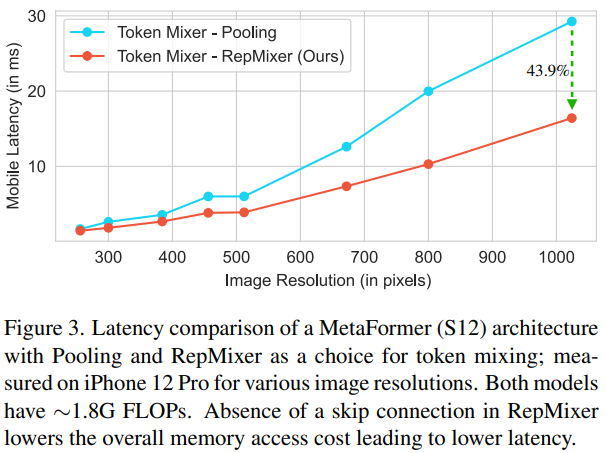
其中,两个压缩过的模型都具有约1.8G FLOPs。实验环境是在iPhone 12 Pro移动设备上对各种输入分辨率的模型进行时间测量,分辨率从224×224到1024×1024逐步缩放。从图中可以看出,RepMixer显著优于Pooling算子,尤其是在更高的分辨率下。观察下384×384这里,使用RepMixer可以使延迟降低25.1%,而在更大的分辨率例如1024×1024下,延迟直接降低至43.9%,Cool!
为了进一步提高效率(参数数量、FLOPs 和延迟),本文设计了一种分解版本替换了所有的密集卷积(如)。但是,参数量低了性能肯定会受影响啦。所以,为了增加拟合能力,作者执行线性训练时超参数化,具体可参考MobileOne论文。
此外,在卷积的初始阶段、Patch Embedding和投影层中进行MobileOne风格的超参数化有助于提高性能,如下表所示:
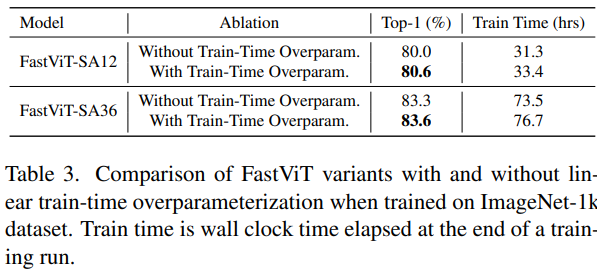
可以看出,训练时超参数化可以使FastViT-SA12模型在ImageNet上的Top1精度直接提高0.6%。哪怕是在较小的FastViT-S12变体中,Top-1精度也能提高0.9%。
然而,训练时超参数化会导致由于添加分支所带来的计算开销而增加训练时间(多分支并行的通病)。因此,为了解决此问题,在该架构中,我们只对那些分解层进行超参数化,这些层位于卷积初始阶段、Patch Embedding和投影层中。这些层的计算成本比网络的其余部分要低,因此超参数化这些层不会显著增加训练时间。例如,FastViT-SA12使用训练时超参数化的训练时间比在相同设置下不使用超参数化的训练时间长 6.7%,FastViT-SA36也仅为4.4%。
最后,便是大卷积核的魔力了,笔者先前讲了挺多的,有兴趣的自行去翻阅『CVHub』历史文章:
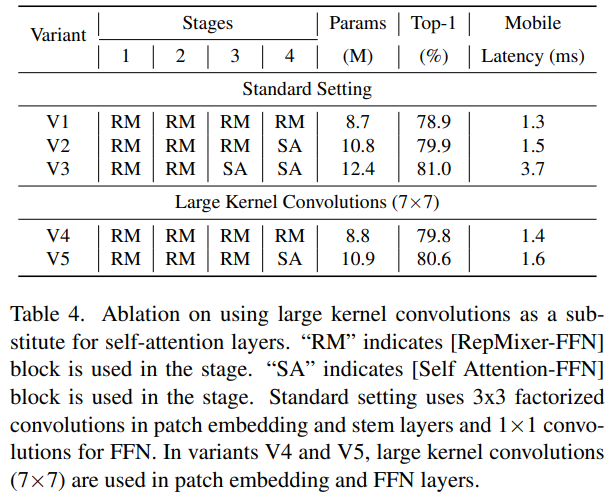
总的来说,随着感受野的增加,大核卷积有助于提高模型的鲁棒性。因此,结合大核卷积是提高模型性能和鲁棒性的有效方法。
效果
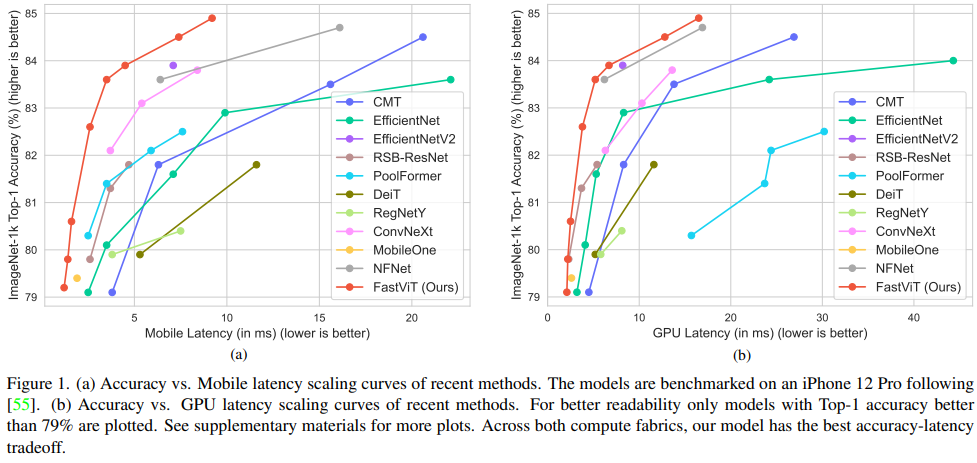
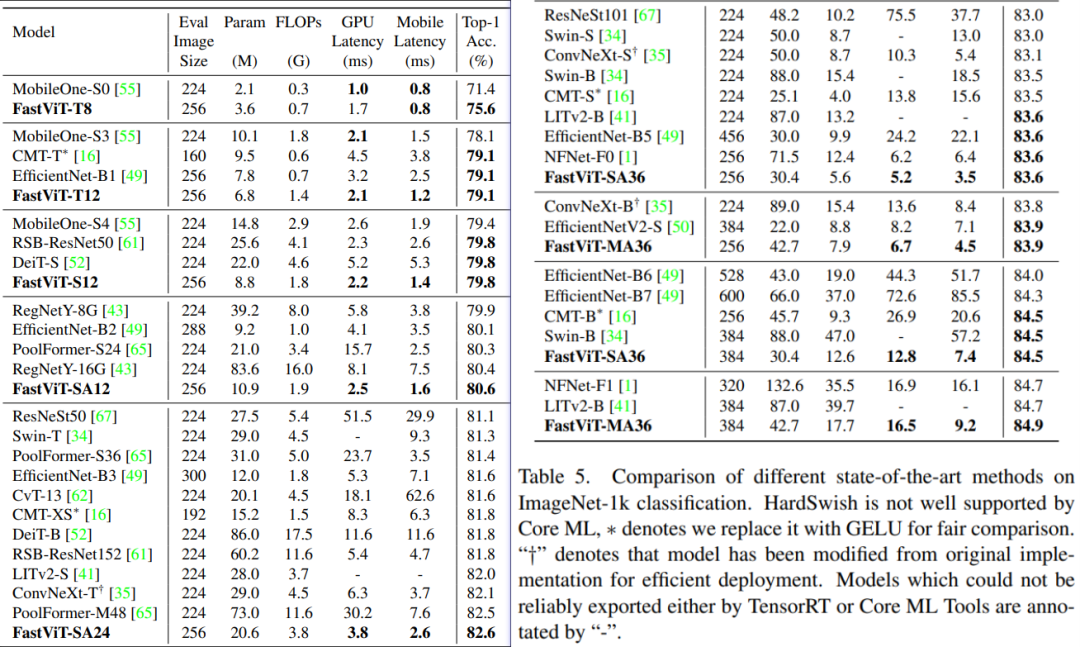
不说了,一句话概括就是又快又强!值得一提的是,作者还将其扩展到 3D 手部网格估计:

这是最终的效果图,看来还是苹果香啊!哈哈哈~~~

总结
本文提出了一种通用的混合视觉转换器,它在多种计算结构上非常高效,包括移动设备和桌面级 GPU。通过结构重参数化,所提模型FastViT显著降低了内存访问成本,尤其是在高分辨率下提速明显。此外,通过进一步的架构优化,最终提高了 ImageNet 分类任务和其他下游任务(如目标检测、语义分割和 3D 手部网格估计)的性能,同时对域外数据和损失数据具备很强的泛化性和鲁棒性!
最新CVPP 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看