一.什么是生产者消费者模型?
生产者消费者模型是一种常用的并发编程模式,它可以解决生产数据和消费数据的速度不匹配的问题。在这个模式中,有两类线程或进程:生产者和消费者。生产者负责生成数据并放入一个共享的缓冲区,消费者负责从缓冲区中取出数据并进行处理。缓冲区可以是一个队列、栈、环形缓冲区等任何有限的数据结构。
二.生产者消费者模型的优点
可以平衡生产和消费的速度,避免过快或过慢导致资源浪费或堵塞。
可以提高程序的整体性能,利用多核CPU和I/O多路复用等技术实现高效的并发处理。
可以解耦生产和消费的逻辑,提高代码的可读性和可维护性。
三.Python如何实现生产者消费者模型
Python提供了多种方法来实现生产者消费者模型,例如:
1- 使用标准库中的`queue`模块和`threading`模块。
2- 使用标准库中的`multiprocessing`模块和`Queue`类。
3- 使用第三方库如`celery`或`gevent`等。
下面我们主要介绍第一种,并给出示例代码。使用queue和threading
Python标准库中提供了一个线程安全的队列类`queue.Queue`,它可以作为缓冲区来存储数据。同时,Python也提供了一个线程管理类`threading.Thread`,它可以创建并启动线程,并传入一个函数作为线程执行的任务。
使用这两个类,我们可以很容易地实现一个简单的生产者消费者模型,生产者和消费者线程分别生产数据和消费数据,先生产后消费。采用 task_done 和 join 确保处理信息在多个线程间安全交换,生产者生产的数据能够全部被消费者消费掉。
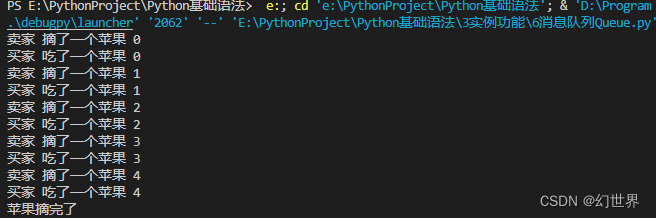
1.生产者
#生产者线程
class Producer(threading.Thread):
def __init__(self,t_anme,queue):
threading.Thread.__init__(self,name = t_anme)
self.data = queue
def run(self):
for i in range(5):
print(self.name, "摘了一个苹果",i)
self.data.put(i)#把苹果放入队列篮子
time.sleep(2)
print("苹果摘完了")2.消费者
#消费者线程
class Consumer(threading.Thread):
def __init__(self,t_name,queue):
threading.Thread.__init__(self,name=t_name)
self.data= queue
def run (self):
while True:
if self.data.qsize()>0 :
var = self.data.get()
print(self.name,"吃了一个苹果",var)
self.data.task_done()3.主线程
#主线程
def main():
q = queue.Queue()
producer = Producer("卖家",q)
consumer = Consumer("买家",q)
producer.start()
consumer.start()
q.join() # 阻塞,直到生产者生产的数据全都被消费掉
producer.join() # 等待生产者线程结束
consumer.join() # 等待消费者线程结束
print ('结束')
main()
sys.exit()