致前行的人:
人生像攀登一座山,而找寻出路,却是一种学习的过程,我们应当在这过程中,学习稳定冷静,学习如何从慌乱中找到生机。

目录
1.程序翻译过程:
程序从文本文件到可执行二进制程序需要经历以下四个阶段:
预处理-E :头文件展开,去注释,宏替换,条件编译
编译-S : 将干净的C语言,编译成为汇编语言
汇编-c :将汇编翻译成为目标二进制文件
链接 :将目标二进制文件与相关库链接,形成可执行程序
本篇重点讲解第一个预处理阶段的所有细节!
2.字符串宏常量
1.字符串没有带双引号,直接报错:
#include<stdio.h>
//#define PATH /user/bin err
#define PATH "/user/bin"
int main()
{
printf("%s\n", PATH);
return 0;
}结论:宏定义代表字符串的时候,一定要带上双引号
2.可以用\续行
#include<stdio.h>
#define PATH "/user/bin/\
test.c"
int main()
{
printf("%s\n", PATH);
return 0;
}3.用宏定义充当注释符号
//当前,我们用BSC充当C++风格的注释
#define BSC //
int main()
{
BSC printf("hello world\n");
return 0;
}在vs上编译运行,发现是直接报错的:

切换平台在Linux上做测试:
直接编译运行:发现也是错误的
 下面不让程序直接编译运行,而是让程序在预处理完之后就停下来
下面不让程序直接编译运行,而是让程序在预处理完之后就停下来
测试发现并没有报错:

打开预处理完之后生成的文件test.i:

倘若,先执行宏替换,那么先得到的代码应该是
int main()
{
//将BSC替换成为‘//’
// printf("hello world\n");
return 0;
}
再执行去注释,那么代码最终的样子,应该是
int main()
{
return 0; //printf被注释掉
}并且,最终运行的时候,应该没有输出
但实际上,并非如此
实际上,是先执行去注释,在进行宏替换
先去掉宏后面的//,因为是注释
#define BSC // //最终宏变成了#define BSC
int main()
{
BSC printf("hello world\n"); //因为BSC是空,所以在进行替换之后,就是printf("hello world\n");
return 0;
}结论:预处理期间:先执行去注释,在进行宏替换
4.用define宏定义表达式
1.用#define定义单条语句:
#define SUM(x) (x)+(x)
int main()
{
printf("%d\n", SUM(10));
return 0;
}
运行截图:

#define定义的表达式是在预处理阶段完成替换的

2.用#define定义多条语句:
//该宏最大的特征是,替换的不是单个变量/符号/表达式,而是多行代码
#define INIT_VALUE(a,b)\
a = 0;\
b = 0;
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag)
INIT_VALUE(a, b);
else
printf("error!\n");
printf("after: %d, %d\n", a, b);
return 0;
}编译运行:直接报错

因为#define是在预处理阶段完成替换的,下面在Linux平台下观察一下预处理完成之后生成的test.i文件:
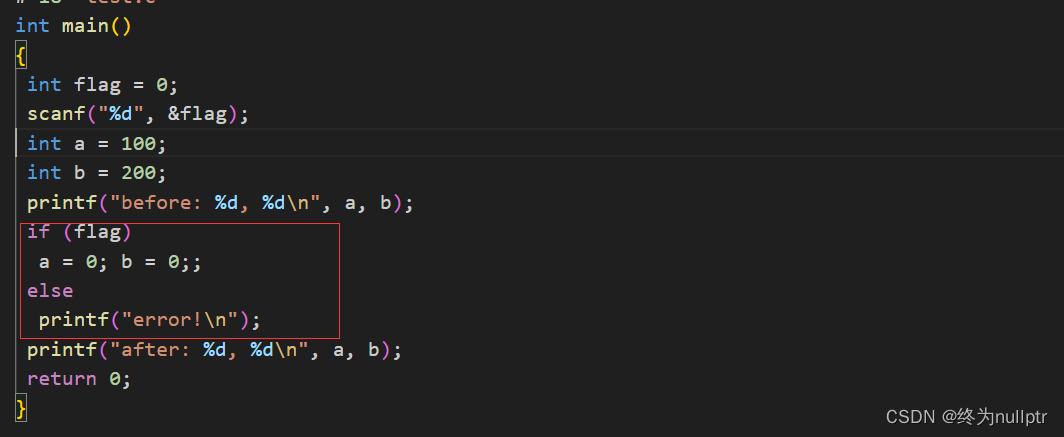
通过观察上图可以发现,完成宏替换之后if后面跟了多条语句,因为if是没有带{}的,所以只能跟一条语句,当有多条语句时,else就匹配失败,出现报错
解决方法1
在编写的时候带上{}:
#define INIT_VALUE(a,b)\
a = 0;\
b = 0;
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag)
{
INIT_VALUE(a, b);
}
else
printf("error!\n");
printf("after: %d, %d\n", a, b);
return 0;
}运行成功:

解决方法2
在编写宏的时候,用do-while-0的结构定义多条语句:
#define INIT_VALUE(a,b)\
do\
{\
a = 0; \
b = 0;\
}while(0)
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag)
INIT_VALUE(a, b);
else
printf("error!\n");
printf("after: %d, %d\n", a, b);
return 0;
}运行截图:

5.宏定义中的空格
#define INC(a) a++ //定义时能带空格
int main()
{
int i = 0;
INC (i); //使用可以带空格,但是严重不推荐(不要处处显得自己不一样哦)
printf("%d\n", i);
}运行截图:

6.宏定义的位置
1.宏只能在main上面定义吗?
答案是否定的,如图所示:可以在不同文件中定义,在使用的时候只需要包含头文件即可

2. 在一个源文件内,宏的有效范围是什么?
答案是:在一个源文件内,宏可以在任意的位置定义,包括函数体内部,全局和局部中,但是从定义出往下有效,往上是无效的
如图所示:test.c
#define M 10
int main()
{
printf("%d, %d\n", M, N);
#define N 100
printf("%d, %d\n", M, N);
return 0;
}test.i:
int main()
{
printf("%d, %d\n", 10, N);
printf("%d, %d\n", 10, 100);
return 0;
}
7.#undef
#undef的作用:
test.c:
#define M 10
int main()
{
#define N 100
printf("%d, %d\n", M, N);
printf("%d, %d\n", M, N);
printf("%d, %d\n", M, N);
#undef M //取消M
#undef N //取消N
printf("%d, %d\n", M, N);
printf("%d, %d\n", M, N);
printf("%d, %d\n", M, N);
return 0;
}test.i:
int main()
{
printf("%d, %d\n", 10, 100);
printf("%d, %d\n", 10, 100);
printf("%d, %d\n", 10, 100);
printf("%d, %d\n", M, N);
printf("%d, %d\n", M, N);
printf("%d, %d\n", M, N);
return 0;
}
结论:undef是取消宏的意思,可以用来限定宏的有效范围。
8.条件编译
8.1条件编译如何使用?
#ifdef - #else - #endif
int main()
{
#ifdef PRINT
printf("hello world!\n");
printf("hello byte!\n");
#else
printf("Non Message!\n");
#endif
return 0;
}当前,PRINT并没有被定义,所以输出#else部分的内容
运行截图:

#ifndef - #else - #endif
int main()
{
#ifndef DEBUG
printf("hello debug\n");
#else
printf("hello release\n");
#endif
return 0;
}当前,DEBUG并没有被定义,所以输出#ifndef部分的内容
运行截图:

同样上述代码,使用#if可以有很多中写法,下面是写法大全
1.单个条件的情况:
#define DEBUG 1
int main()
{
#if DEBUG
printf("hello bit\n");
#endif
return 0;
}2.带else的情况:
//报错
//#define DEBUG
//定义了,为假
#define DEBUG 0
//定义了,为真
//#define DEBUG 1
int main()
{
#if DEBUG
printf("hello world\n");
#else
printf("hello C\n");
#endif
return 0;
}3.多条件的情况:
//#define DEBUG 0
//#define DEBUG 1
//#define DEBUG 2
#define DEBUG 3
int main()
{
#if DEBUG==0
printf("hello C 0\n");
#elif DEBUG==1
printf("hello C 1\n");
#elif DEBUG==2
printf("hello C 2\n");
#else
printf("hello else\n");
#endif
return 0;
}4.#if模拟#ifdef:
#define DEBUG
int main()
{
#if defined(DEBUG)
printf("hello debug\n");
#else
printf("hello release\n");
#endif
return 0;
}5.#if模拟#ifndef:
int main()
{
#if !defined(DEBUG)
printf("hello debug\n");
#else
printf("hello release\n");
#endif
return 0;
}6.其它使用方法:
#define C
#define CPP
int main()
{
#if defined(C) && defined(CPP)
printf("hello c && cpp\n");
#else
printf("hello other\n");
#endif
return 0;
}#define C
//#define CPP
int main()
{
#if defined(C) || defined(CPP)
printf("hello c&&cpp\n");
#else
printf("hello other\n");
#endif
return 0;
}#define C
#define CPP
int main()
{
#if !(defined(C) || defined(CPP))
printf("hello c&&cpp\n");
#else
printf("hello other\n");
#endif
return 0;
}#define C
#define CPP
int main()
{
#if defined(C)
#if defined (CPP)
printf("hello CPP\n");
#endif
printf("hello C\n");
#else
printf("hello other\n");
#endif
return 0;
}8.2为何要有条件编译?
本质认识:条件编译,其实就是编译器根据实际情况,对代码进行裁剪。而这里“实际情况”,取决于运行平台,代码本身的业务逻辑等。
可以认为有两个好处:
1. 可以只保留当前最需要的代码逻辑,其他去掉。可以减少生成的代码大小
2. 可以写出跨平台的代码,让一个具体的业务,在不同平台编译的时候,可以有同样的表现
8.3条件编译都在哪些地方用?
举一个例子吧
我们经常听说过,某某版代码是完全版/精简版,某某版代码是商用版/校园版,某某软件是基础版/扩展版等。其实这些软件在公司内部都是项目,而项目本质是有多个源文件构成的。所以,所谓的不同版本,本质其实就是功能的有无,在技术层面上,公司为了好维护,可以维护多种版本,当然,也可以使用条件编译,你想用哪个版本,就使用哪种条件
进行裁剪就行。
著名的Linux内核,功能上,其实也是使用条件编译进行功能裁剪的,来满足不同平台的软件。
9.文件包含
1. 为何所有头文件,都推荐写入下面代码?本质是为什么?
#ifndef XXX
#define XXX
//TODO
#endif2. #include究竟干了什么?
形成的.i文件,发现文件大小比我们实际的代码要大得多
结论:#include本质是把头文件中相关内容,直接拷贝至源文件中!
那么,在多文件包含中,有没有可能存在头文件被重复包含,乃至被重复拷贝的问题呢?
#ifndef _TEST_H_
#define _TEST_H_ //注意,这里没有包含<stdio.h>防止信息太多干扰我们
void show(); //任意一个函数声明
#endif故意包含两次:
#include"test.h"
#include"test.h"
int main()
{
return 0;
}
去掉条件编译:

void show(); //内容被拷贝第一次
# 2 "test.c" 2
# 1 "test.h" 1
void show(); //内容被拷贝第二次
# 3 "test.c" 2
int main()
{
return 0;
}结论:所有头文件都必须带上条件编译,防止被重复包含!
那么,重复包含一定报错吗??不会!
重复包含,会引起多次拷贝,主要会影响编译效率!
10.#error 预处理
//#define __cplusplus
int main()
{
#ifndef __cplusplus
#error 不是C++
#endif
return 0;
}
结论:核心作用是可以进行自定义编译报错。
12.#line 预处理
本质其实是可以定制化你的文件名称和代码行号,很少使用
#include <stdio.h>
int main()
{
printf("%s, %d\n", __FILE__, __LINE__); //C预定义符号,代表当前文件名和代码行号
#line 60 "hehe.h" //定制化完成
printf("%s, %d\n", __FILE__, __LINE__);
return 0;
}运行截图:

13.#pragma 预处理
#pragma message()作用:可以用来进行对代码中特定的符号(比如其他宏定义)进行是否存在进行编译时消息提醒
#include <stdio.h>
#define M 10
int main()
{
#ifdef M
#pragma message("M宏已经被定义了")
#endif
return 0;
}运行截图:

14.#运算符
首先补充,临近字符串自动连接特性:
int main()
{
printf("hello"" world""\n");
const char* msg = "hello""bit""\n";
printf(msg);
return 0;
}运行截图:

#:可以将数字转换成字符串:
#include<string.h>
#define STR(s) #s
int main()
{
char buf[64] = { 0 };
strcpy(buf, STR(1234));
printf("%s\n", buf);
return 0;
}运行截图:
![]()
15.##预算符
##的作用:将##相连的两个符号,连接成为一个符号
#define CONT(x,n) (x##e##n)
int main()
{
printf("%lf\n", CONT(2, 5));计算浮点数科学计数法,相当于2 * (10^5)
return 0;
}运行截图:
