论文:PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection
代码:https://github.com/ligang-cs/PseCo
出处:ECCV 2022 | 南京科技大学 商汤
一、背景
现阶段图像分类、目标检测等任务的效果都取得了很大的进展,这很大程度上依赖于大量标注好的数据。
但是大量的数据标注非常耗时且昂贵,尤其是目标检测任务,需要很严格精细的标注。
所以,使用未标注的数据来提升模型效果的半监督学习就被提出来,可以同时使用标注数据和未标注数据来进行模型训练。
半监督图像分类(Semi-Supervised for Image Classification,SSIC),对未标记数据的学习可以分为两类:
- 伪标记 [7,18]
- 一致性训练 [24,22]
还有一些方法如 FixMatch [19],FlexMatch [28] 试图将这两种技术结合到一个框架中来提升效果
半监督目标检测( Semi-Supervised Object DetectionS,SOD)中,一些工作借鉴了 SSIC 的关键技术(如伪标记、一致性训练),并将其直接应用于SSOD,但效果不尽如意。原因主要有两点:
- 一方面,与图像分类相比,目标检测的伪标签更加复杂,既包含类别信息,又包含位置信息。
- 另一方面,目标检测需要捕获比图像分类更强的尺度不变能力,因为它需要仔细处理具有丰富尺度的目标
本文的贡献:
- 提出了一个 SSOD 框架(PSEudo labeling and COnsistency training,PseCo),将目标检测属性集成到 SSOD 中,使得伪标签和一致性训练能更好的用于目标检测任务
二、方法
PseCo 的整体架构如图 2 所示,在未标记的数据中,PseCo 由以下两部分构成:
- 带噪声的伪框学习(Noisy Pseudo box Learning,NPL)
- 多视图尺度不变学习(Multi-view Scale-invariant Learning,MSL)

2.1 基础框架结构
本文使用 Faster RCNN 作为基础检测框架
使用 Teacher-student 训练模式,教师模型是通过对学生模型进行指数移动平均(Exponential Moving Average,EMA)得到的,教师网络和学生网络的结构完全相同。学生网络使用梯度更新来训练,教师网络根据学生网络来更新且无需参与训练。
整体过程如下:
- 使用定义好的采样率来从标注数据和未标注数据中采用,得到一个 batch 的数据输入网络进行训练
- 对标注数据:送入学生网络进行学习,并得到监督学习 loss, L l = L c l s l + L r e g l L_l=L^l_{cls} + L^l_{reg} Ll=Lclsl+Lregl
- 对未标注数据:
- 进行弱数据增强后送入教师网络进行学习,生成伪标签
- 进行强数据增强后送入学生网络进行学习,学习伪标签
- 根据学生网络和教师网络的预测结果,得到半监督学习 loss: L u = L c l s u L_u = L^u_{cls} Lu=Lclsu
- 然后计算总体的 loss: L = L l + L u L = L_l + L_u L=Ll+Lu,用于指导梯度更新来更新学生网络的权重
- 最后,使用指数移动平均来更新教师网络权重
每次训练根据抽取比例进行随机抽取标注数据和未标注数据:
-
对标注数据:
- student model 按正常模式训练,用 gt box 来监督其训练, L l = L c l s l + L r e g l L^l = L_{cls}^l+L_{reg}^l Ll=Lclsl+Lregl
-
对未标注数据:
弱数据增强后送入教师模型生成伪标签,强数据增强后送入学生网络学习伪标签,且由于作者认为分类和回归没有强联系,即分类好不一定回归好,则对未标注数据舍弃了回归 loss,只使用分类 focal loss: L u = L c l s u L^u = L^u_{cls} Lu=Lclsu
-
首先,使用弱数据增强(水平翻转、随机调整大小等),然后输入教师模型进行伪标签生成(也就是让教师模型输出预测结果,毕竟教师模型是比较大的,能力较强,对学生网络有很大的指导作用的)。此外,考虑到在使用了 NMS 后的伪标签(检测框)也会很密集,故此又设置了一个分数阈值 τ \tau τ,只保留分数高于阈值的框作为伪标签
-
之后,对输入训练数据进行强增强(如切割、旋转、亮度抖动等),生成学生模型的训练样本,对学习模型进行训练
-
最后,由于好的分类和好的定位没有强关联,所以作者不对未标记数据进行位置回归,而且实验也能证明对未标记的数据进行位置回归的话也会导致训练不稳定,所以作者对无标签数据没有使用回归 loss,只使用了分类 Focal loss
-
前景和背景的数量不平衡问题:
- 前景-背景不平衡在目标检测中普遍存在,在半监督情况下更加严重
- 上面提到的过滤 NMS 保留下来的伪标签的得分阈值 τ \tau τ 虽然可以提高伪标签的精度,但也会导致伪标签数量减少,使得模型容易学习优势类别,导致偏倚的预测
如何解决前景和背景的数量不平衡问题:
-
对未标记的数据,分类 loss 使用类似于 Unbiased Teacher[14] 中的方法,将 CE loss 替换成 Focal loss,且 α t \alpha_t αt 和 γ \gamma γ 和原始论文中一样
-
标记数据和未标记数据的总体 loss 为 L = L l + β L u L = L^l+\beta L^u L=Ll+βLu,其中 β \beta β 被用于控制未标记数据的权重
2.2 带噪声的伪边界框学习
Noisy Pseudo Box Learning
在 SSOD 中,伪标签包含类别和位置两种信息
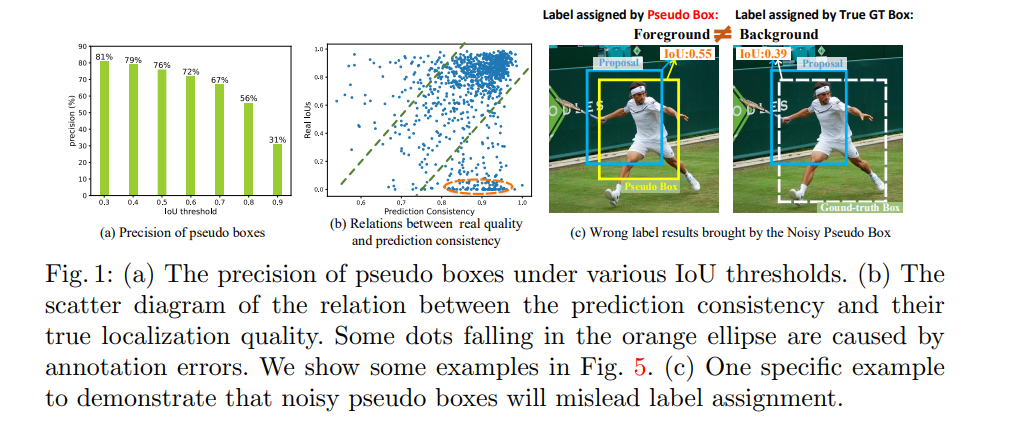
伪标签的类别得分只能表示其类别的置信度,无法保证框位置的质量,如果伪标签的框位置不精确的话就会拉低模型的效果,所以本文使用下面两种方法来减少位置对 label assign 和回归任务的损害:
- Prediction-guided Label Assignment
- Positive-proposal Consistency Voting
1、Prediction-guided Label Assignment
Faster RCNN 中的 label assignment 是基于 IoU 的方法,将和 gt 的 IoU 大于阈值(0.7)的 box 置位正样本。
在半监督学习中,gt 就是生成的伪标签。
该做法的前提是假设 gt 的框位置非常的准确,所以方法不适合于未标记的数据,可能会导致一些低质量的 proposal 被分配为正样本。
一个示例如图 1c 所示,一个和真实 gt 的 IoU 为 0.39 的 proposal 被分配为正样本了。
为了解决这个问题,作者提出了 PLA(Prediction-guided Label Assignment):
- 将教师模型的预测作为辅助信息,且降低对 IoU 的依赖
- 在 Teacher-Student 训练模式下,不仅仅教师网络预测结果 NMS 之后的框可以做伪标签,NMS 之前的框也可以做伪标签,用于指导学生模型的训练。
- 作者将教师网络生成的 RPN 和学生网络共享,那么教师网络在这些 proposal 上的预测结果就可以很方便的迁移到学生网络
- 为了更好的衡量 proposal 的质量 q,同时使用教师网络的分类得分和定位预测来作为衡量方法,即 q = s α × u 1 − α q = s^{\alpha} \times u^{1-\alpha} q=sα×u1−α,s 是 RPN 输出的前景得分,u 是 RPN 预测的 proposal 和 gt 的 IoU。 α \alpha α 控制 s 和 u 对结果的贡献程度。
如何在未标记数据上使用呢:
- 首先,使用传统的基于 IoU 的方法为每个 gt 生成一系列候选框,且 IoU 阈值设置为比较低的值(0.4)来保证包含更多的候选框
- 对于这些候选框,按质量 q 进行降序排序,将 top-N 的框看做正样本,其余为负样本,N 是基于 OTA 方法中的 dynamic k 估计得到的
PLA 的优势:
- 减轻了对 IoU 的强烈依赖,减轻了定位较差的框带来的负面影响
- 标签分配策略将更多的教师知识整合到了学生模型的训练中,实现了更好的知识蒸馏

2、Positive-proposal Consistency Voting
由于分类得分不能很好的表示定位的质量,所以作者还提测了一个方法来衡量定位质量——PCV
基于 CNN 的模板检测器一般都是会将多个 proposal 分配给一个 gt(或 pseudo box),这些 proposal 回归结果的一致性能反映其对应的这个伪边界框的质量。
则第 j 个伪边界框的回归一致性 σ i \sigma_i σi 表示为:
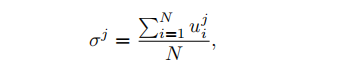
- 其中,u 是预测框和伪边界框的 IoU
- N 是分配给第 j 个伪边界框的正 proposal 的数量
得到了 σ i \sigma_i σi 后,使用 instance-wise 的回归:

- reg 是回归的输出
- reg^ 是 gt
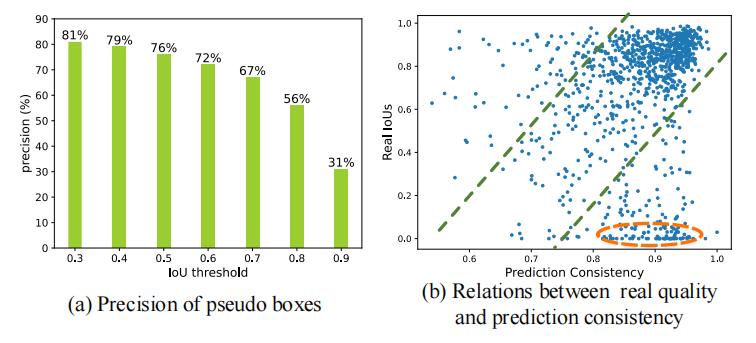
如图 1b 所示,其中描述了伪边界框的预测一致性和其真实 IoU 之间的关系散点图,可以看出:
- 一致性和 IoU 正相关
- 橘色圆中的是标注错误引起的
如图 5,展示了伪边界框也可以准确的指导模型预测

2.3 多视图尺度不变性学习
不同于图像分类,目标检测中的目标尺度变化较大,故难以在每个尺度上都表现较好。
所以,从未标记数据中学习尺度不变的表示对 SSOD 相当重要。
在一致性训练中,强数据增强为提高模型性能起到了很重要的作用。
通过在输入图像中注入强扰动,能使模型对各种变化都保持鲁棒性。
标签级一致性:
从尺度不变性角度来看,将常见的数据增强(如随机调整大小)看做标签级一致性,因为其能根据输入图像尺度的变化来调整标签的大小。
特征级一致性:
由于检测网络通常有丰富的特征金字塔设计,因此特征级的一致性也很容易在配对输入之间实现。
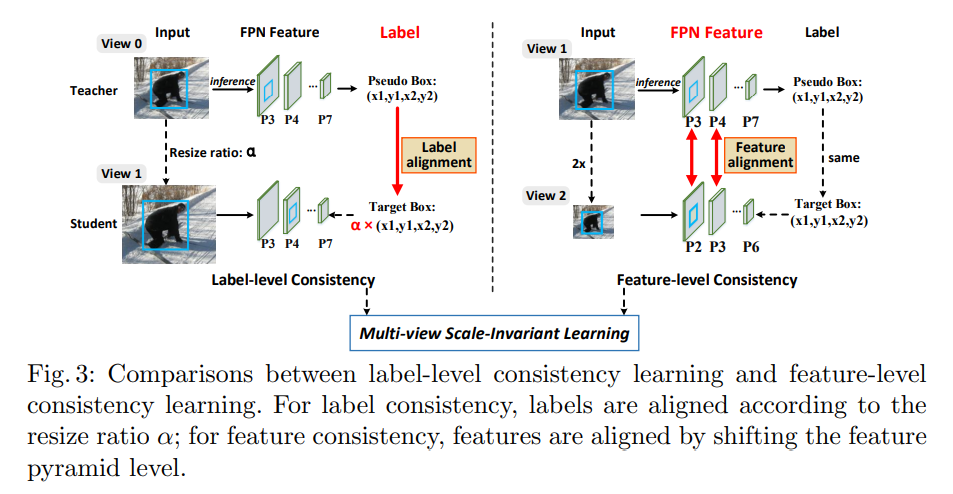
所以,本文中提测了多视图尺度不变学习,将标签级和特征级的一致性组合到一个框架中,特征一致性通过对齐两个内容相同但尺度不同的图像之间的金字塔特征来实现的。
过程:
- 两个视图(两个图像)分别为 V 1 V_1 V1 和 V 2 V_2 V2,用于训练 MSL 中的学生网络
- 教师模型的输入图像为 V 0 V_0 V0
- V 1 V_1 V1 和 V 2 V_2 V2 会被结合起来分别学习标签级和特征级的一致性
- V 1 V_1 V1 是使用随机缩放得到的,也就是将 V 0 V_0 V0 和伪边界框进行随机的缩放,缩放尺度在 [0.8, 1.3]。
- V 2 V_2 V2 是将 V 1 V_1 V1 下采样 2 倍得到的
- V 1 V_1 V1 和 V 2 V_2 V2 构成一组图像对儿
- V 1 V_1 V1 的 FPN 的 P3-P7 层可以刚好和 V 2 V_2 V2的 P2-P6 层大小对应,如图 3 所示
三、实验
1、数据集
使用 MS COCO,包括两个训练集:
- train2017,包含 118k 标注数据
- unlabeled2017,包含 123k 未标注数据
Partially Labeled Data:
- 随机选择 train2017 中的 1%,2%,5%,10% 作为标注数据,其他的作为未标注数据
- 在每个采样率下,对比了 5 种不同倍的均值和方法
Fully Labeled Data:
- 使用 train2017 作为带标签的训练数据,unlabeled2017 作为无标签的训练数据
2、实验细节
使用 Faster RCNN with FPN 作为检测框架,backbone 为 Res50
伪标签分类阈值为 0.5
伪标签 loss 权重 β = 4.0 \beta=4.0 β=4.0
Partially Labeled Data:
- 在 8 GPU 上训练 180k iters
- 初始学习率为 0.01,在 120k、160k iters 分别降低 10 倍
- 每个 GPU 的每个 batch 有 5 张图,无标签:有标签=4:1
Fully Labeled Data:
- 在 8 GPU 上训练 720k iters
- 每个 GPU 每个 batch 为 8 张图,有标签:无标签=1:1
- 初始学习率为 0.01,在 480k、680k iters 分别降低 10 倍
3、和 SOTA 的对比(COCO val2017)
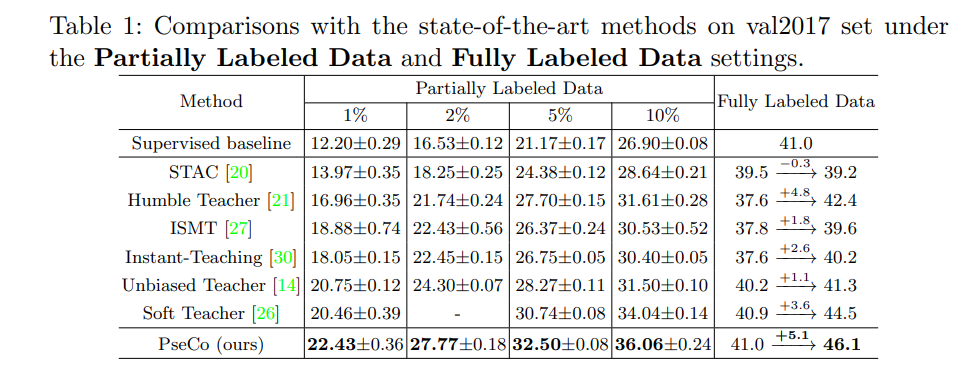
Partially Labeled Data:
- 当有标注的数据比较少时(1% 或 2% 采样率),本文方法超越 Unbiased Teacher 分别为 1.7% 和 3.5%
- 当有标注的数据增多时(5% 或 10% 采样率),本文方法比最强的 Soft Teacher 分别高 1.8% 和 2.0%
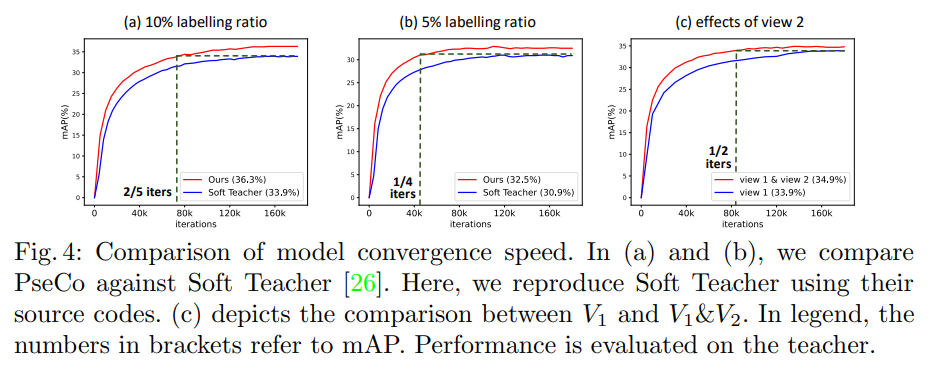
- 本文方法和 Soft Teacher 的收敛速度如图 4 所示,可见本文方法收敛速度更快
Fully Labeled Data:
- 本文方法获得了 46.1 mAP,是 SOTA 的效果
- 定性的可视化如图 5 所示

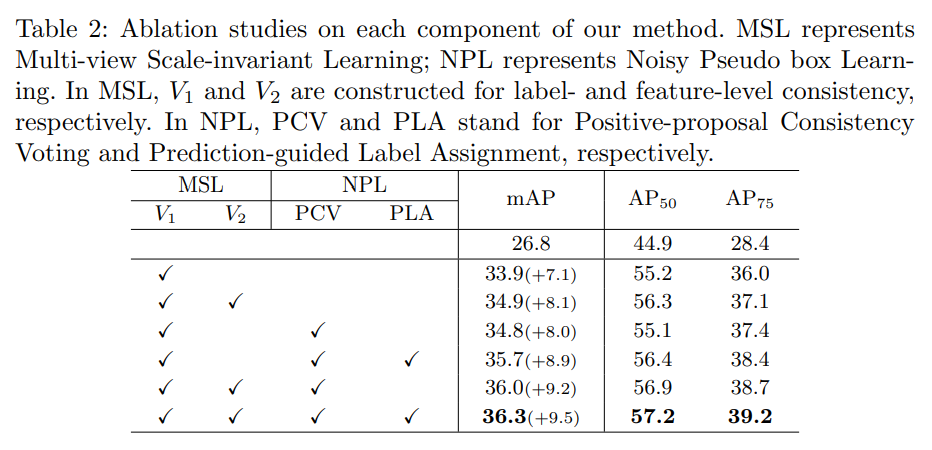
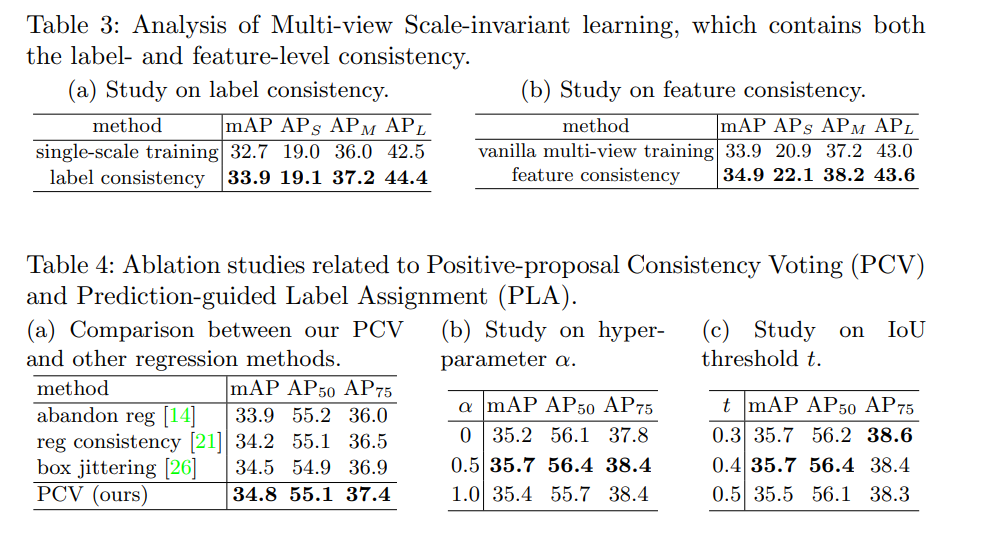
4、消融实验