最简单的解决办法
使用pip install pycrypto安装python这个模块的时候一直报错。网上找了很多办法,虽然有些还是可以解决,但是解决步骤非常复杂

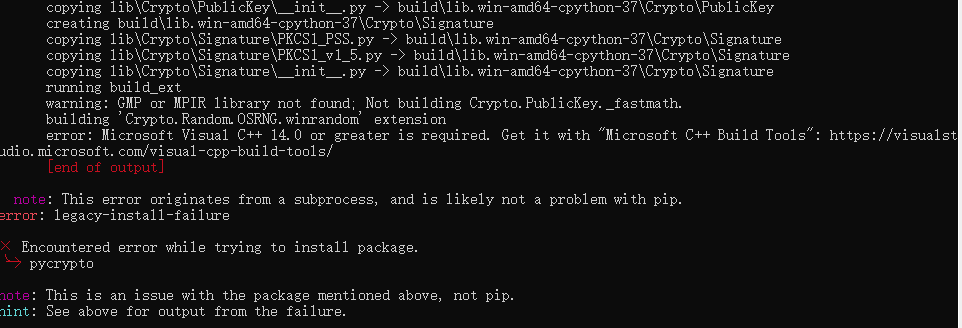
所以在此我们按照另外一个包,pip install pycryptodome,这个安装成功后和pycrypto一样的效果,简单方便,就几秒钟就可以成功完成安装


由于版权问题,下面只展示了某音乐网站的一个加密算法的解密
- 找到未加密的参数 #window.asrsea(参数xxx,参数xxx)
- 先办法把参数进行加密(必须参考网页的逻辑) params => encText,encSecKey =>encSecKey
- 请求网易云,拿到评论信息
处理加密过程
function a(a = 16) {
#返回的随机16为字符
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) #循环16次
e = Math.random() * b.length, #随机数
e = Math.floor(e), #取整
c += b.charAt(e); # 去字符串中的xxx位置
return c
}
这个加密的js代码通过浏览器自带的开发者工具获取
function b(a, b) {
#a是要加密的内容
var c = CryptoJS.enc.Utf8.parse(b) #b是密钥
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) #e是数据
, f = CryptoJS.AES.encrypt(e, c, {
#c加密的密钥
iv: d, # iv 偏移量
mode: CryptoJS.mode.CBC # 用的是cbc这个模式进行加密
});
return f.toString()
}
function c(a, b, c) {
# c里面不产出随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
d:数据, e:'010001', f:很长,是一个定值 g:0CoJUm6Qyw8W8jud
var h = {
} #空对象
, i = a(16); #i就是一个16为的随机值
return h.encText = b(d, g),# g是密钥
h.encText = b(h.encText, i), #返回的就是params i也是密钥
h.encSecKey = c(i, e, f), # 得到的就是encSecKey,e和f是固定的,如果此时我们把i固定,得到的key也是固定的
h
}
两次加密:
数据+g =>b => 第一次加密+i =>b =params
防盗链的处理
该项目中防盗链主要是referer,它的作用是要想请求该资源网站,必须是通过原来的某个网站访问才可以成功请求。
# 1.拿到contId
# 2.拿到videoStatus返回的json。->srcURl
# 3.把srcURL里面的内容进行整理
# 4.下载视频
import requests
import json
url = 'https://www.pearvideo.com/video_1765875'
contId = url.split('_')[1]
videoStatusUrl = f'https://www.pearvideo.com/videoStatus.jsp?contId={
contId}&mrd=0.6123042939703023'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 "
"Safari/537.36X-Requested-With: XMLHttpRequest ",
# 防盗链:表示上一次请求必须是Referer: https://www.pearvideo.com/video_1765875
# 要有上一次的溯源:当前本次请求的上一次是谁
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
# 处理过后的url
srcUrl = srcUrl.replace(systemTime, f'cont-{
contId}')
# print(srcUrl)
# 下载视频
with open('a.mp4', 'wb') as f:
f.write(requests.get(srcUrl).content)
print('succeed!!!')
# https://video.pearvideo.com/mp4/adshort/20220621/cont-1765875-15898547_adpkg-ad_hd.mp4
# https://video.pearvideo.com/mp4/adshort/20220621/1657171644874-15898547_adpkg-ad_hd.mp4
# print(srcUrl)
# print(systemTime)
如果需要参考完整的代码:gitee仓库