数据处理用numpy,画图matplotlib.pyplot
import numpy as np
import matplotlib.pyplot as plt1.引入数据
points = np.genfromtxt('data.csv', delimiter=',')
print(points[0,0])
# 提取points中的两列数据,分别作为x,y
x = points[:, 0]
y = points[:, 1]
# 用plt画出散点图
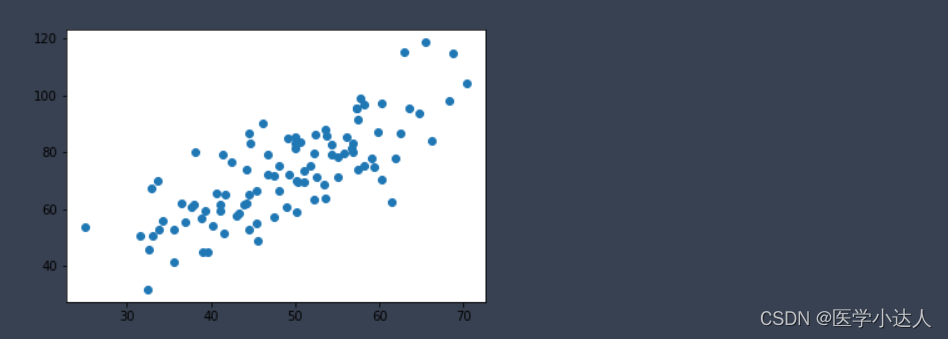
plt.scatter(x, y)
plt.show()data.csv的连接
链接:https://pan.baidu.com/s/1LildPm1cFCW2XGBgSNDy3A
提取码:star
结果如下:
2.定义损失函数:
# 损失函数是系数的函数,另外还要传入数据的x,y
def compute_cost(w, b, points):
total_cost = 0
M = len(points)
# 逐点计算平方损失误差,然后求平均数
for i in range(M):
x = points[i, 0]
y = points[i, 1]
total_cost += ( y - w * x - b ) ** 2
return total_cost/M损失函数公式:
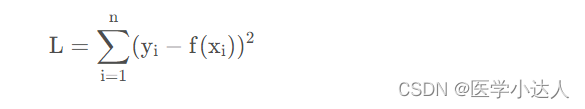
2.定义算法拟合函数:
# 先定义一个求均值的函数
def average(data):
sum = 0
num = len(data)
for i in range(num):
sum += data[i]
return sum/num
# 定义核心拟合函数
def fit(points):
M = len(points)
x_bar = average(points[:, 0])
sum_yx = 0
sum_x2 = 0
sum_delta = 0
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_yx += y * ( x - x_bar )
sum_x2 += x ** 2
# 根据公式计算w
w = sum_yx / ( sum_x2 - M * (x_bar**2) )
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_delta += ( y - w * x )
b = sum_delta / M
return w, b3.通过拟合函数可以得到函数的w和b:
w, b = fit(points)
print("w is: ", w)
print("b is: ", b)
cost = compute_cost(w, b, points)
print("cost is: ", cost)结果如下:

4.画出拟合曲线
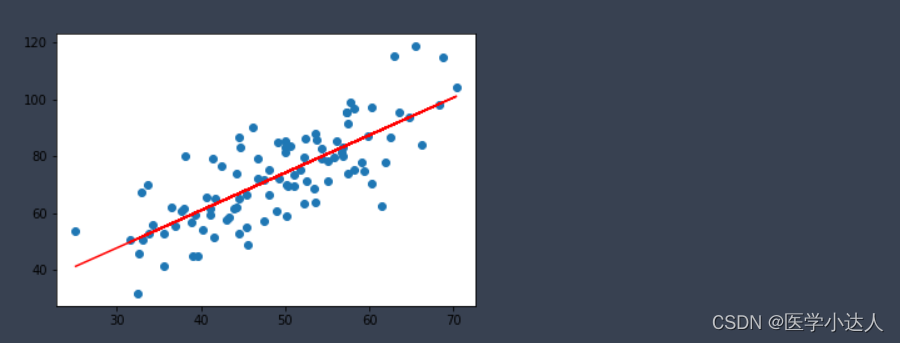
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()结果如下:
6.线性回归调sklearn库实现
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
x_new = x.reshape(-1, 1)
y_new = y.reshape(-1, 1)
lr.fit(x_new, y_new)
# 从训练好的模型中提取系数和截距
w = lr.coef_[0][0]
b = lr.intercept_[0]
print("w is: ", w)
print("b is: ", b)
cost = compute_cost(w, b, points)
print("cost is: ", cost)结果如下,和上面自己算的几乎一样,说明调库还是很简单又高效的,

画图:
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()结果如下:

总结:这两种方法都可以使用哦
声明: 代码参考b站up主尚硅谷的代码。