
淘宝App搜索业务侧采用的是局部动态化的跨端技术架构,客户端提供丰富的基础能力与视图组件的API,前端负责业务视图搭建与业务逻辑实现。

背景
目前客户端侧对于基础能力与组件的API信息内容是通过人工使用语雀文档来进行维护,然而端侧的API是在不断地迭代的,人工维护的方式存在以下的问题:
填写内容无统一规范,导致能力/组件介绍和调用规范不准确。
无卡口管控,文档内容同步非强制操作,导致有时候会忘记同步。(很多历史能力/组件的描述内容就是这样被遗漏的)。
而当调用规范文档有缺失后,对于跨端架构下的协同开发会带来下面的问题:
能力/组件介绍缺失:前端同学开发时无法获取到准确的端侧业务能力/组件的提供范围,导致出现二次开发的情况。
调用规范缺失:因缺少能力调用规范说明,增加了跨端协同之间的答疑和联调成本,降低了开发效率。
因此如何将端侧的API信息低成本的、规范化的维护,同时能够将这块信息高效的利用起来,降低跨端协同的成本是本篇文章的主题。

思路分析
▐ 现状
客户端侧的跨端API代码在编写时是有模板规范的(方便代码编译时检索与提取),且为了方便后续的维护,端侧同学在编写相关代码的时候,或多或少都会写一些注释对相关方法进行说明。eg:
基础能力模块相关:模块定义、模块方法
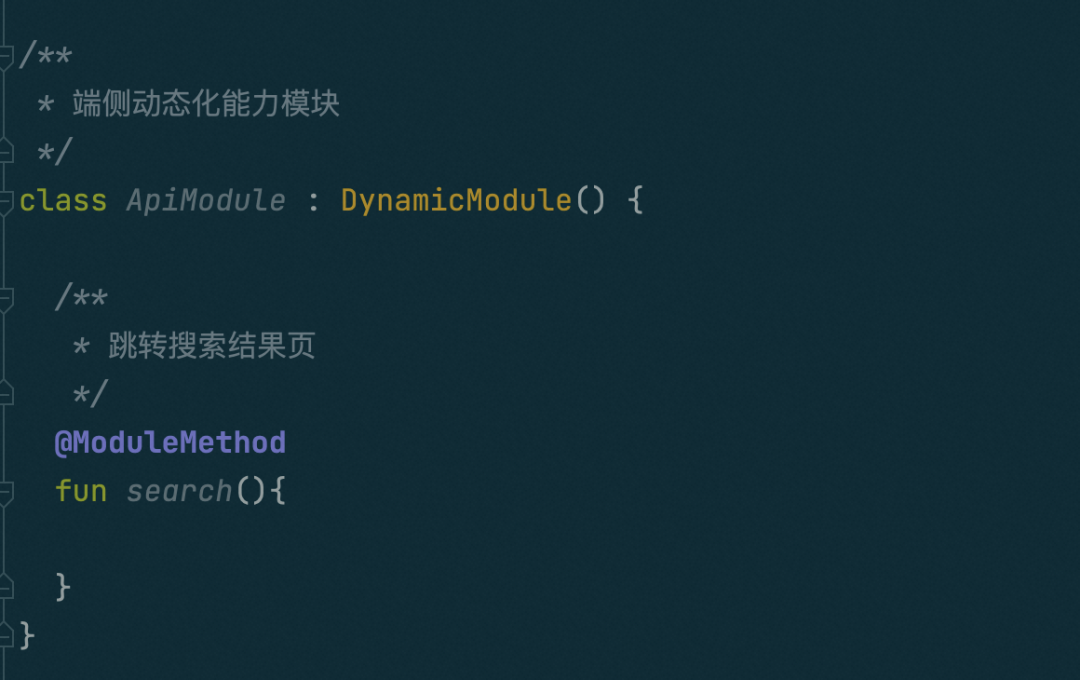
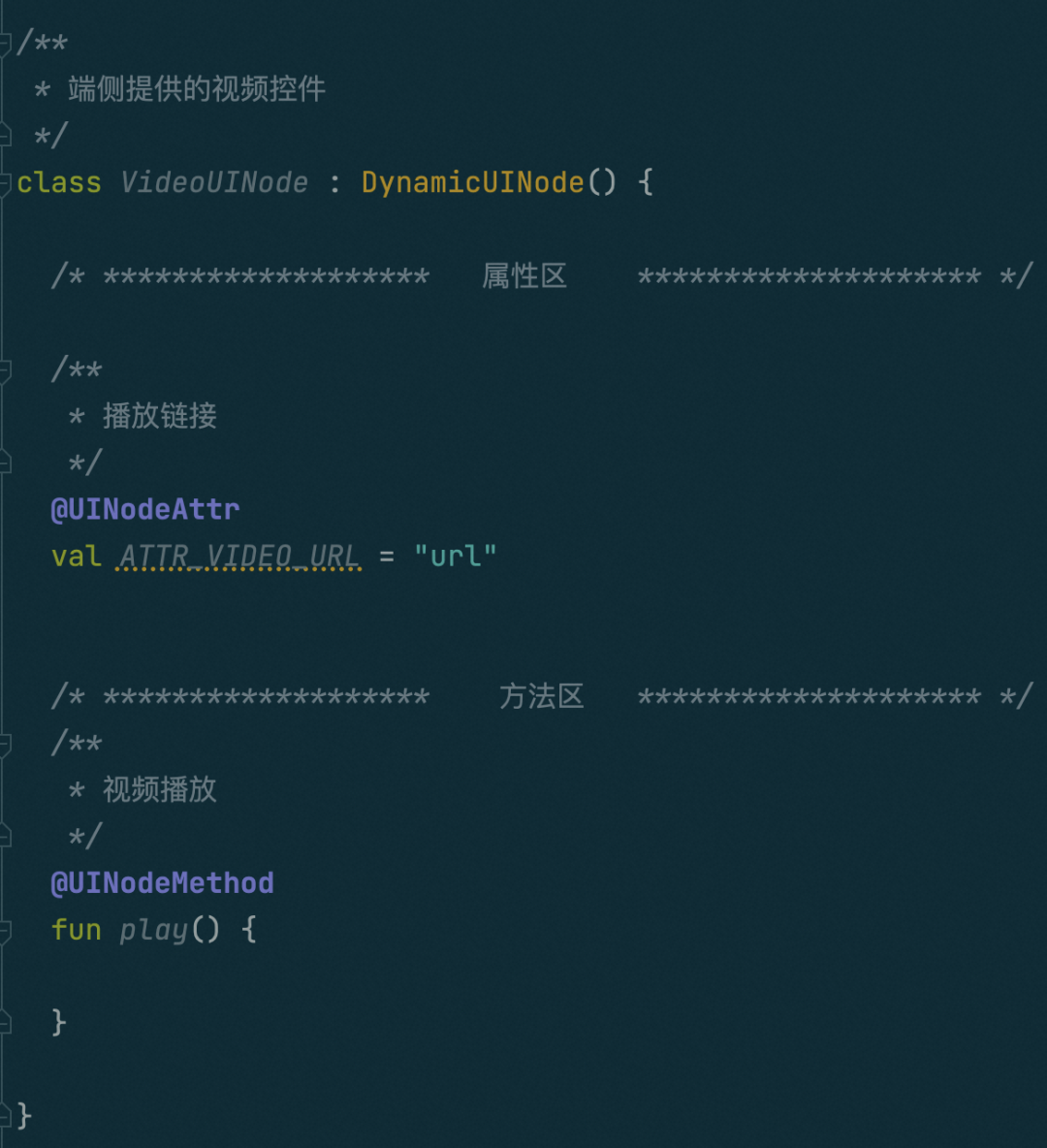
视图组件相关:组件定义、组件属性、组件方法
文档维护
在代码编写完后,端侧同学会按照自己的话术将注释内容进行丰富后(让前端同学能够理解的内容)维护到语雀文档中。
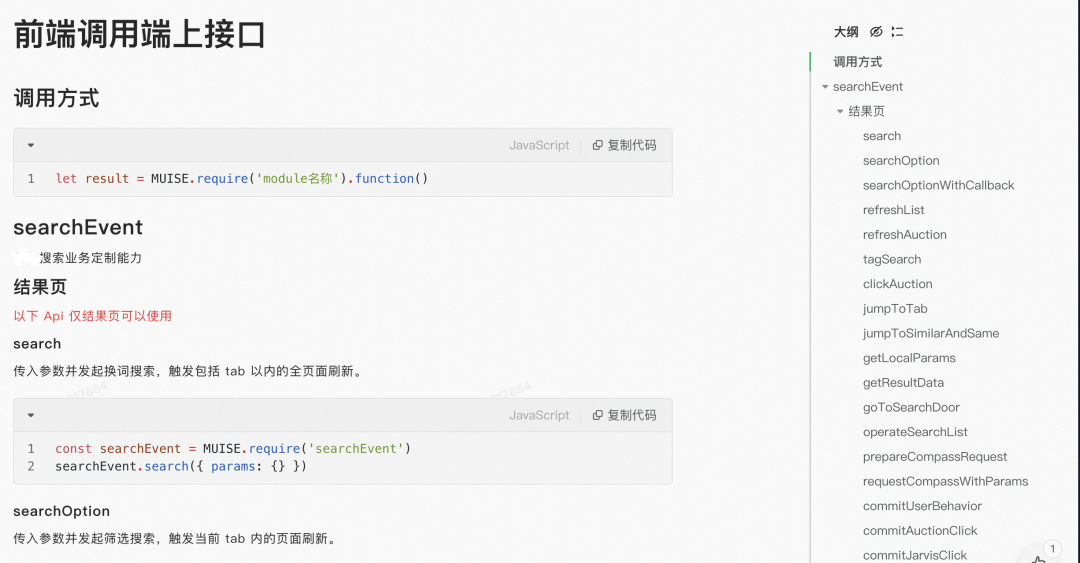
由于上面这种方式,无论是代码侧还是文档侧基本全靠开发同学的主观能动性来确保信息的完整和有效,那么久而久之就会出现背景中所述的问题。
▐ 优化思路
信息编写规范化
既然跨端能力代码可以有模板规范,那么也可以约定注释信息的填写模板,将注释内容信息规范化。
信息收集自动化
基于规范化的注释内容,可以通过脚本工具或者编译插件工具,在代码编译时按照既定的规则将这些信息进行采集。采集到信息之后,通过服务上报的方式将数据持久化在远端数据库,方便后续的二次加工和使用。
信息使用多样化
基于采集到的API信息,可以生成API介绍的网页来替代语雀文档展示的方式。
同时还可以更进一步,按照前端语言规范,将这些信息生成前端代码库的JS描述文件,实现了在前端IDE中编写代码时的端侧 Api 提示和代码补全能力,同时描述文件也可以使用npm进行版本管理。
基于以上思路分析,整体的方案链路大致如下:
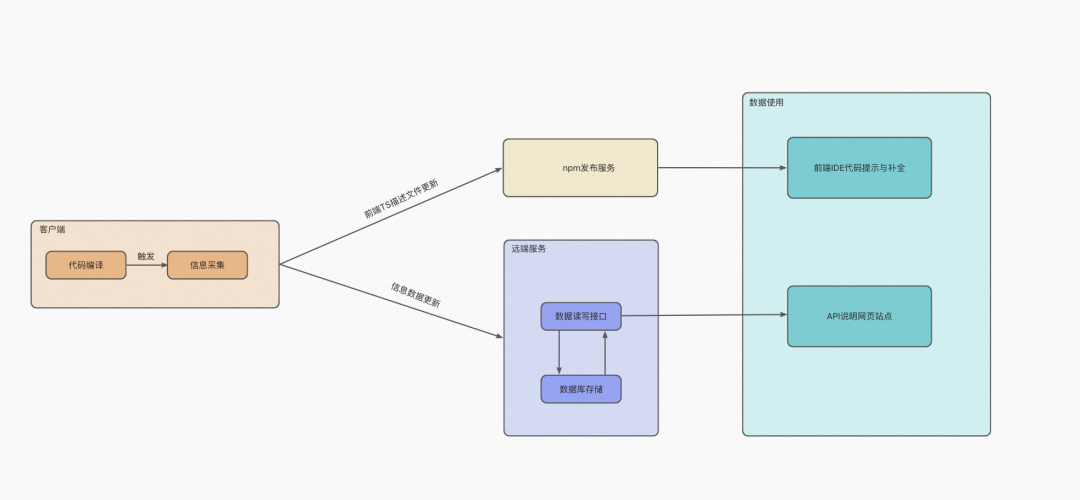

模块拆解
综合考虑开发成本并结合Android端侧的编译环境,选择自定义Java注解和注解处理器的方式来作为信息生成的方案。
▐ 基于注解的API信息生成
API注解与注解内容规范定义
既然是基于注解的自动化采集方式,我们除了需要将端侧复杂的API按照作用进行分类外,还需要对不同类目的API设计适配性的内容填写规范,使API信息尽可能的有效且丰富。
Java注解定义
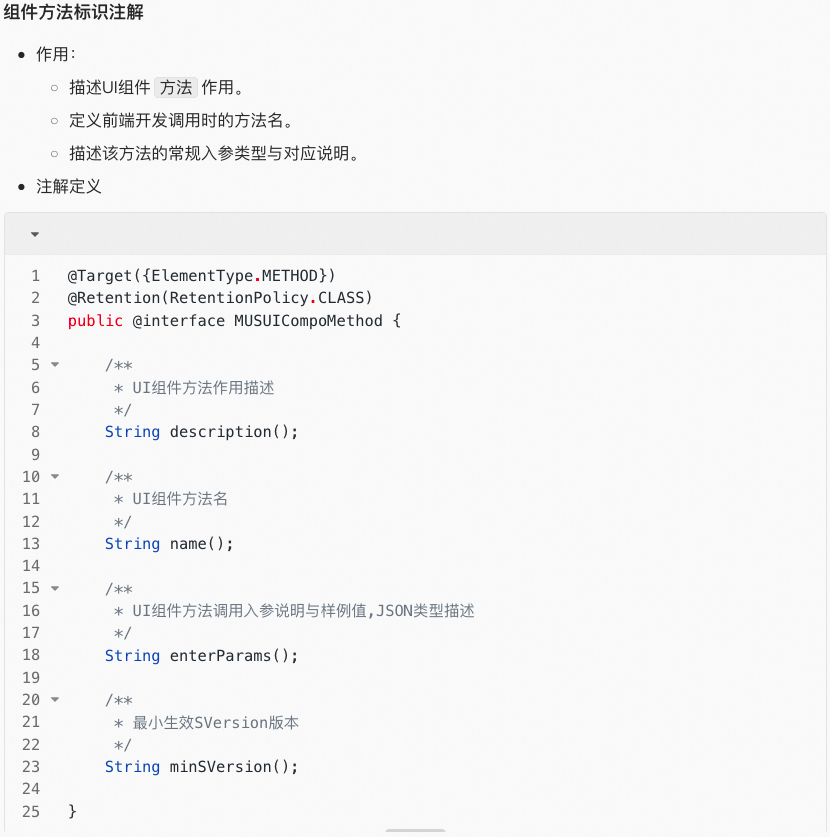
注解内容规范定义


API注解内容生成与维护工具
在实际操作过程中我们发现,为了尽可能完整的描述方法或者组件的能力和调用方式,有些比较复杂的方法需要填写的信息内容比较多,例:

如果纯手工完成信息生成和后续的维护,难免会出现内容填写格式错误的情况,一旦内容填充错误,就会导致后续的信息采集失败。
既然注解内容的生成是有模板规范的,那么我们完全可以通过工具将一些关键字段补充之后,按照规范生成对应内容,于是就有了下面的注解内容自动化生成工具。
根据关键字段生成注解内容:

相应的,也能通过注解内容反序列化成关键字段。
▐ 基于自定义注解处理器的API信息采集
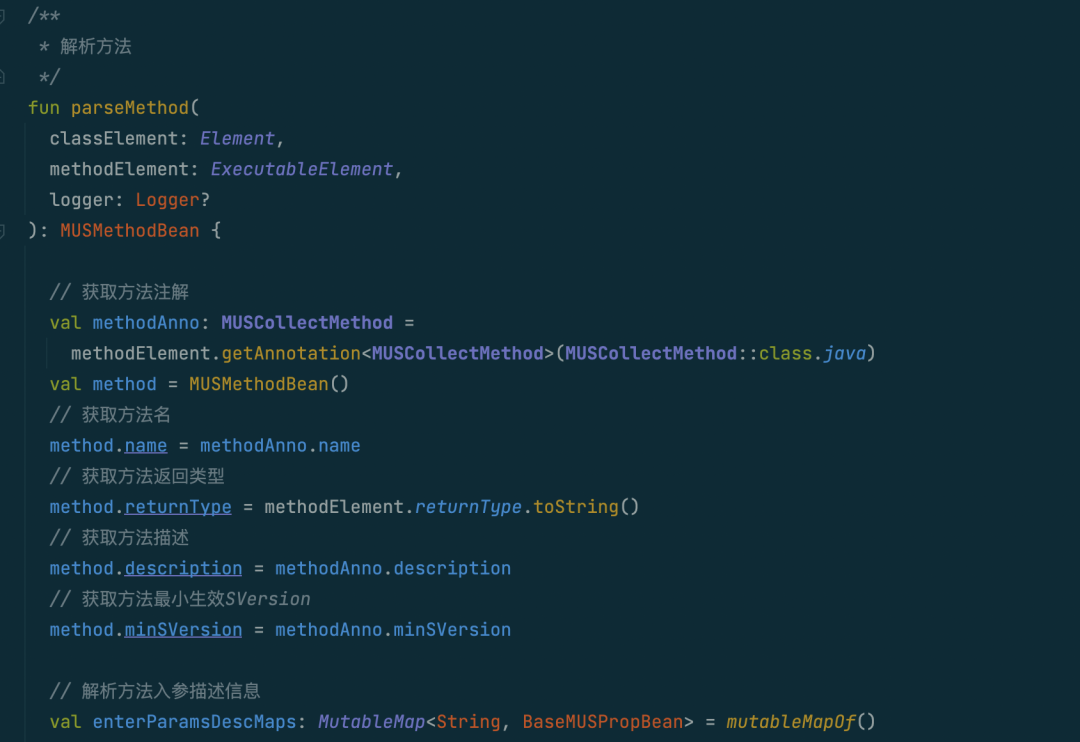
基于Java自定义注解的信息在填充完成后,我们需要自定义Java注解处理器,在代码编译时将相关信息采集并处理成我们需要的格式。
信息采集规则
采集规则不用特殊设计,代码编译时按照注解的定义规则,将对应注解里面的字段按照定义拆解出key-value即可。
生成目标文件
信息JSON文件
按照方案设计中的构想,我们需要将采集到的API信息进行上报,为了方便数据上报,我们将信息组装成json文件。
文件生成
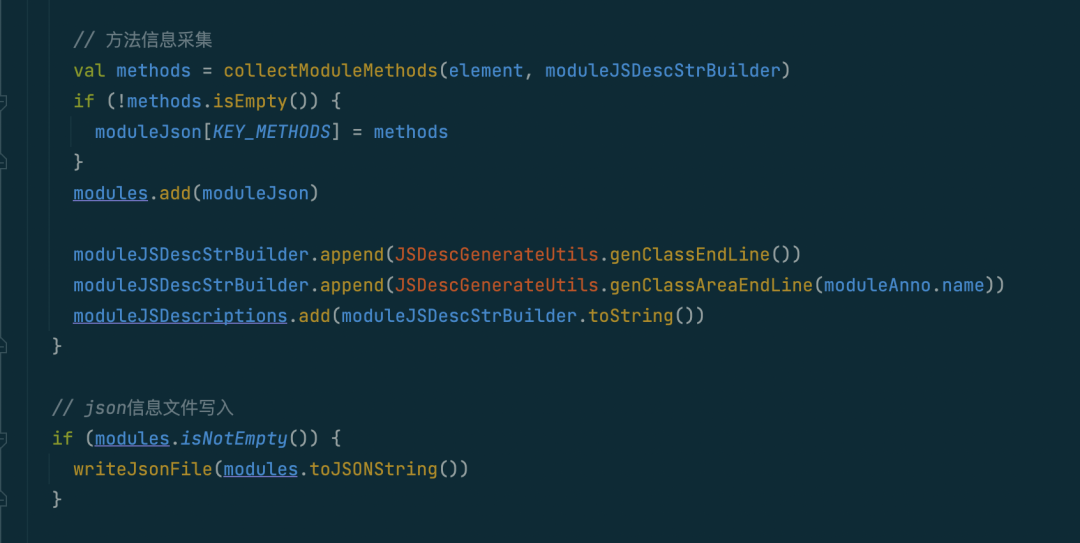
目标文件

前端描述文件
为了支持前端IDE的代码提示,还需要按照前端的API描述文件编写规范生成对应的描述文件。
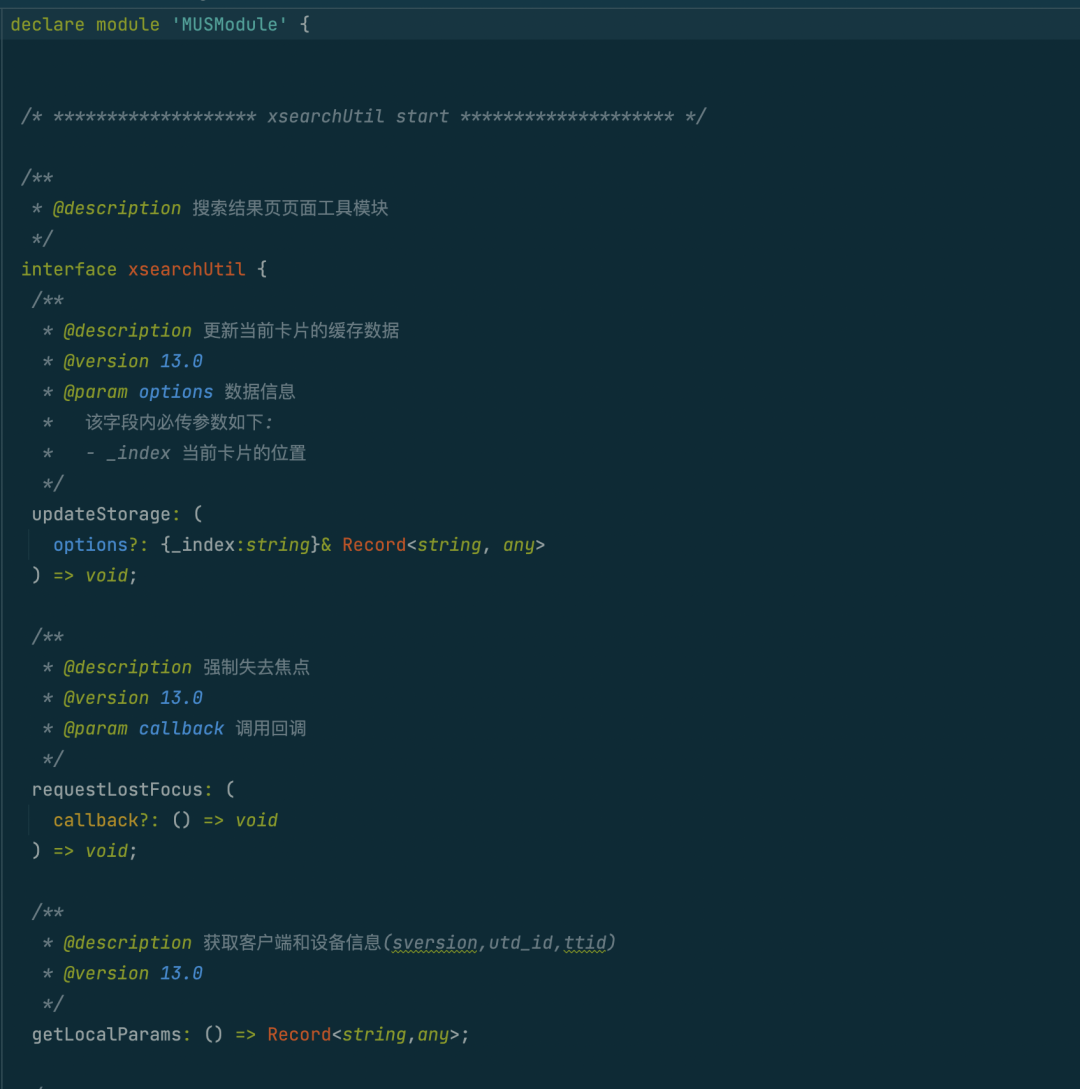
前端API描述文件规范
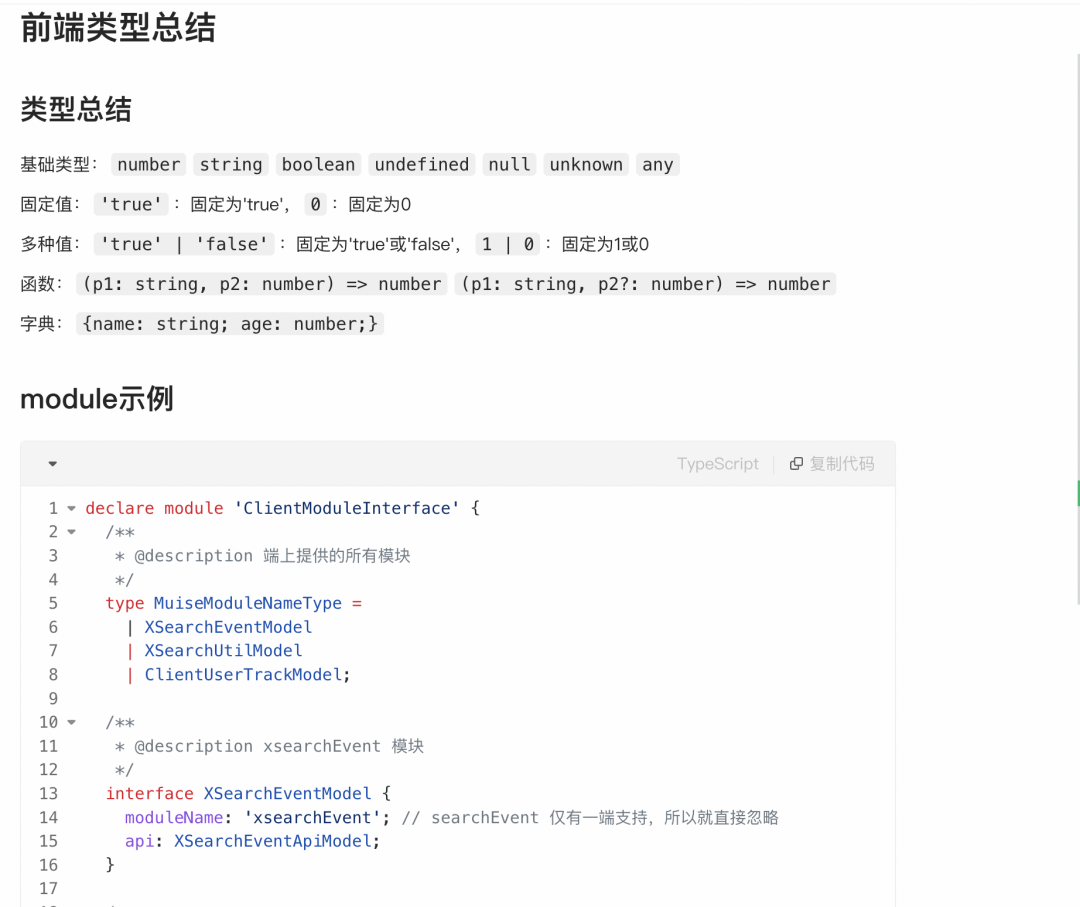
文件生成
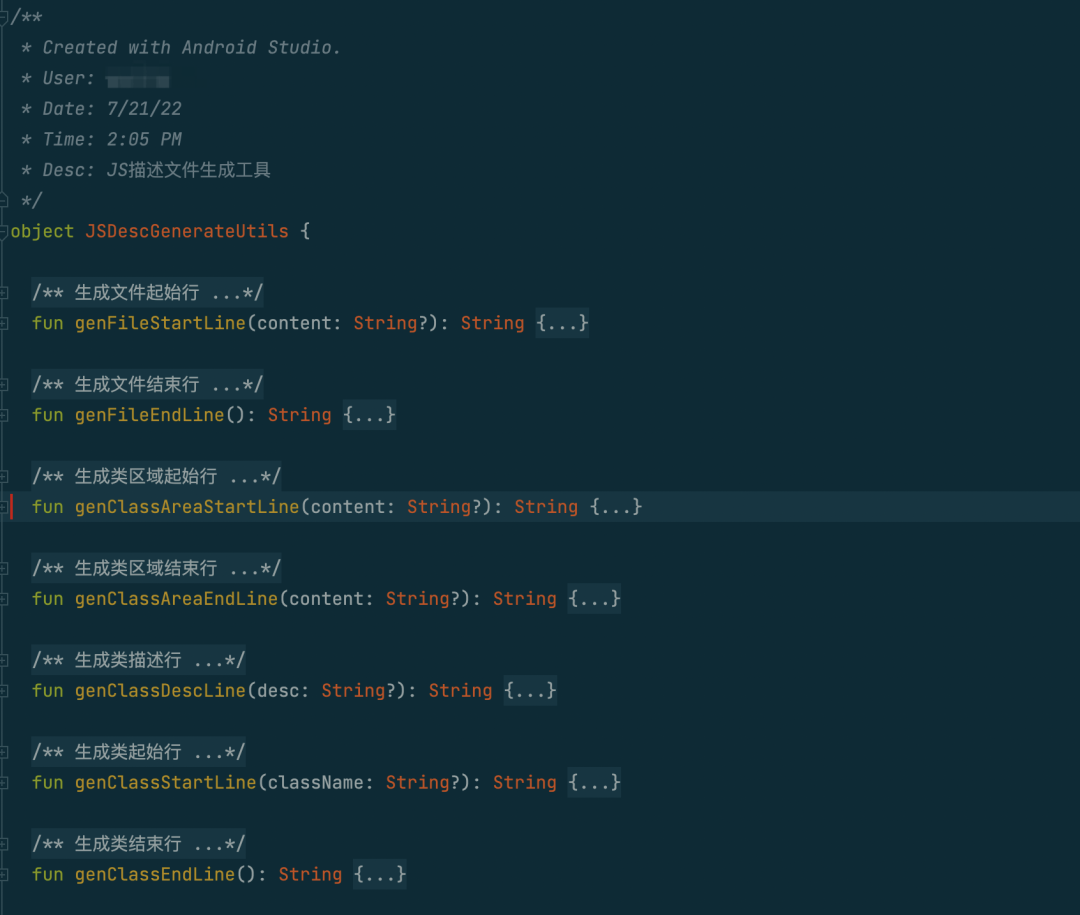
目标文件
▐ 基于脚本的API信息数据上报
目前端侧的打包发布平台支持丰富的自定义配置,在打包流水线中添加自定义脚本执行节点,在自定义脚本文件中完成API信息数据的上报和前端描述文件的发布。

进展
▐ 使用效果
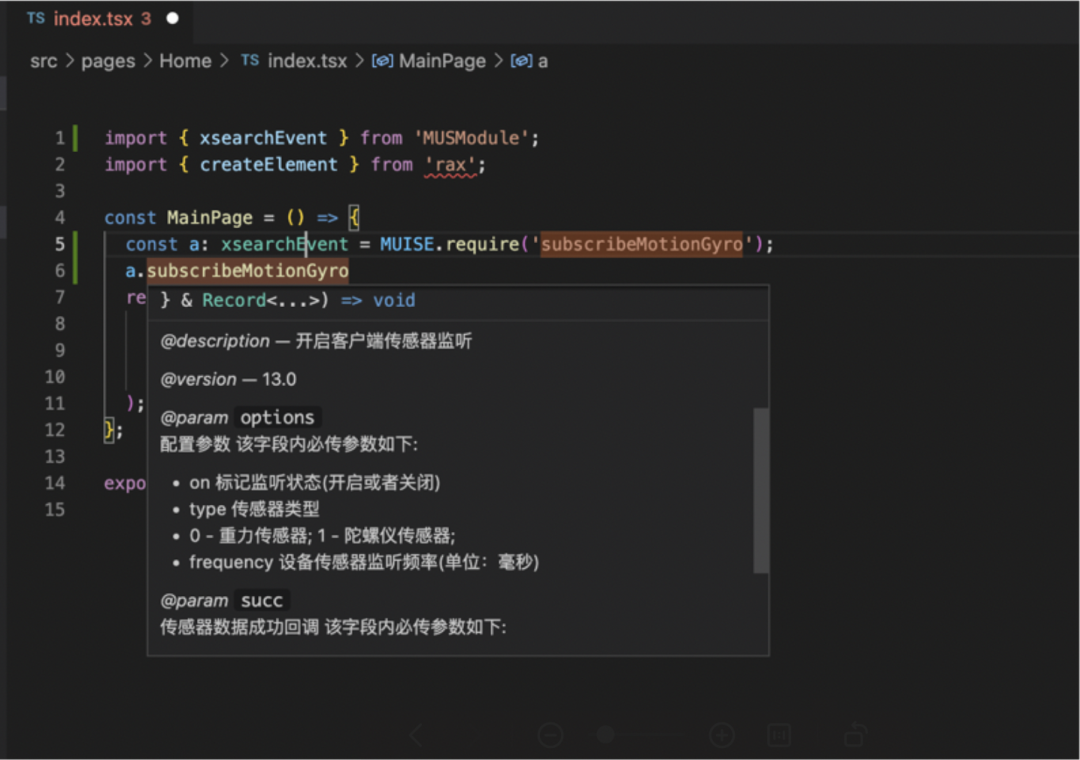
前端代码提示插件
目前前端代码提示插件已能正常使用,相比之前盲写代码还是舒服了不少。IDE中使用效果如下:
端侧API说明站点
通过持久化的API数据,自动生成相关API的说明站点,包含API的功能描述与调用方式。

▐ 持续优化
API注解信息编译卡口检测
目前注解信息填写依靠CR规范限制开发者填写,后续考虑通过使用编译插件进行检测,对没有填写相关信息的API进行编译中断,强制开发者进行填写。

总结
以上就是淘宝App搜索业务在跨端架构下客户端侧API维护的一种思路实现方式,整体方案比较常规,也是希望通过将一些常用的工具进行组合,尽可能的提高跨端协同的效率与开发幸福感。

团队介绍
我们是大淘宝技术营销与平台策略技术搜索终端团队,负责集团核心电商搜索推荐、图像视频搜索的业务研发,还致力于相关技术平台的建设、新业务和前沿技术探索等工作。
¤ 拓展阅读 ¤