我们一般说的分类任务,多指单标签多分类。
- 单标签分类: 每个样本一个label,这个label有多个目标选项。
- 多标签分类: 每个样本多个label,每个label有两个目标选项(0/1)。
接下来具体讲一下不同:
1. 训练阶段
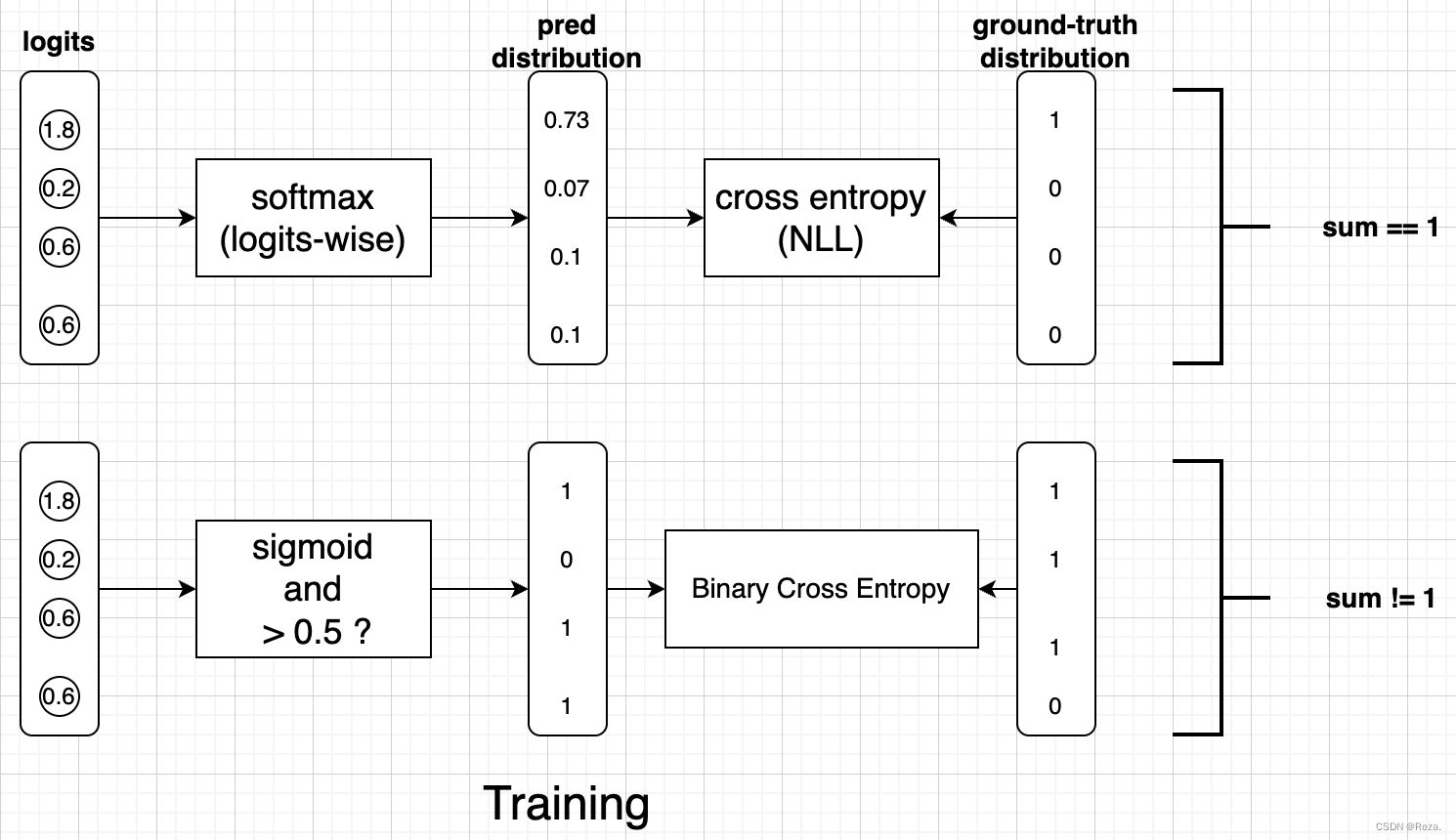
可以看到有一下不同:
- 激活函数:虽然模型输出logits均是4维(最左侧)。但是,单标签分类用的是softmax;多标签分类则用的sigmoid。
- 输出分布:单标签用softmax,将整个4维logits normalize成一个概率分布(求和为1);多标签用sigmoid,把4维logits中的每一个node进行normalize,每一个node都与其他nodes独立,最后输出是一个k-hot 向量。答案分布也是类似 (最右侧),单标签是求和为一,多标签则不一定。
- 损失函数:单标签计算两个分布之间的交叉熵;多标签则是每个node,和对应那个答案(0/1)之间的二元熵,依旧是nodes之间互相独立。(交叉熵和二元熵,本质是一样的)
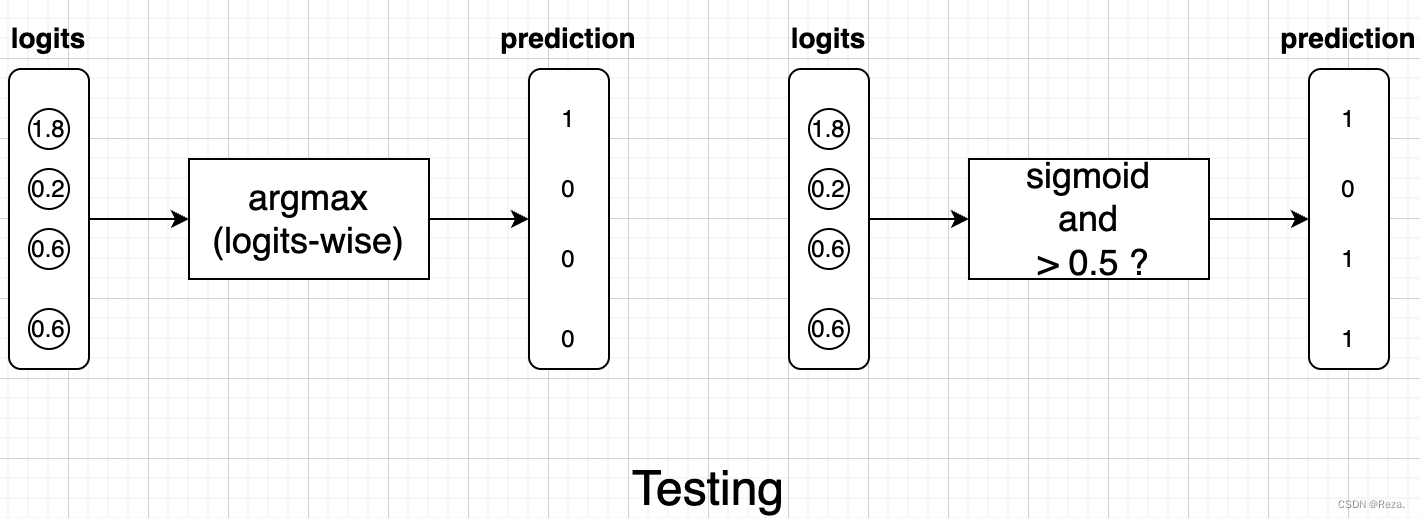
2. 测试阶段
测试阶段也是类似,只不过单标签用argmax选出最后的预测;多标签依旧是sigmoid,然后判断每个normalize之后的node是否大于一个threshold(比方说,0.5)。
3. 具体实现差异
如上述介绍的,其实单标签、多标签,在代码实现上差距也很小。
以huggingface transformer为例:
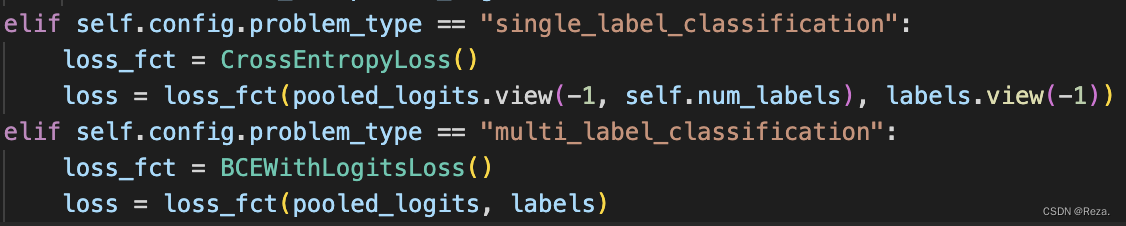
训练的时候,最大区别就是loss的计算不同(如上图);测试的时候,就和上一节总结的一样。