书籍推荐:
Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems
一:名词认识
1 Segmentation (分割 )句号 逗号等标点符号 把句子分隔开
2 Tokenizing (标记化)
3 Stop words(停用词) 比如was are and in 等类型的词语
4 Stemming (提取词干)skipped skipping skips 都来自词语skip
5 Lemmatization (词型还原)are am is 都是be动词
6 speech tagging (词性)noum名词。vreb 动词。 preposition 介词

7 Named entity tagging(命名实体标记)
二:language modeling (n-gram RNN
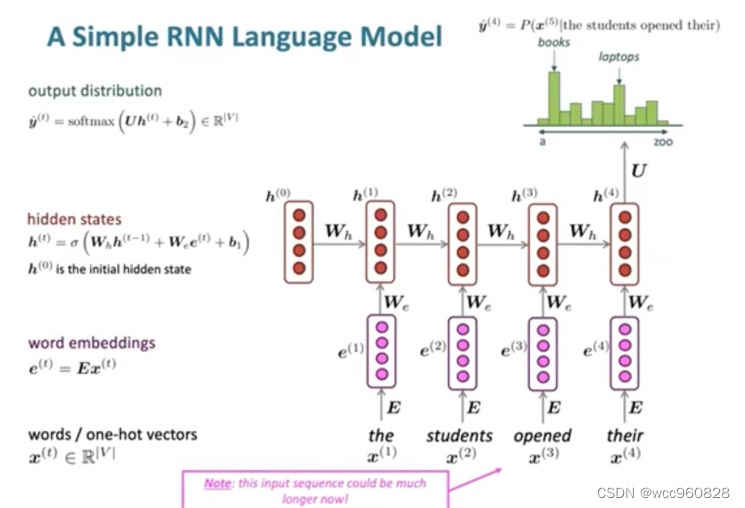
作用:预测下一个单词(比如谷歌搜索 输入一些单词以后 会根据下一个单词出现的可能性提示想查找的内容)
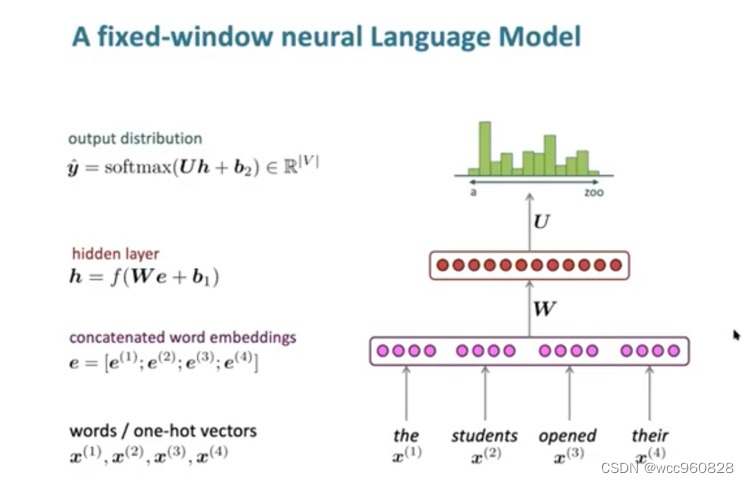
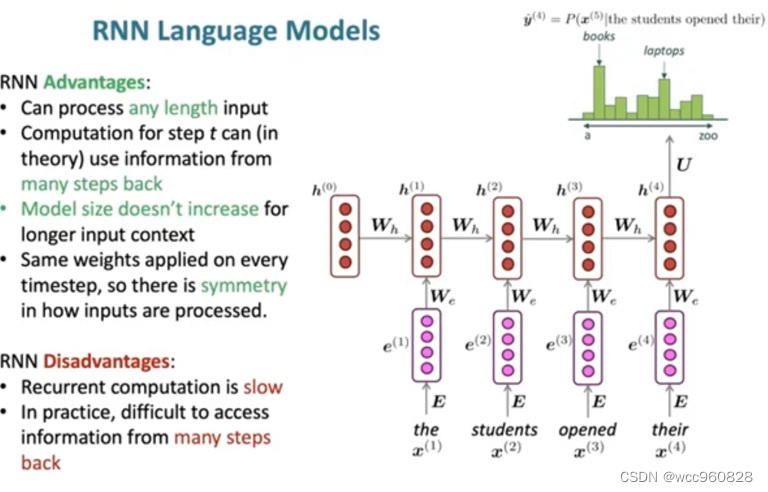
RNN 模型的优缺点:
原始文本(raw data) __
分词(segmentation)____
清洗(cleaning)无用的标点符号 特殊符号 停用词
标准化(nomalization) stemming词干提取 lemmation 词型还原
特征提取(feature extraction) tf-idf word2vec
建模(modeling) 相似度算法 分类算法
文本预处理:
1:去除数据中的非文本部分
正则表达式删除不需要的符号标点:clearn = re.compile(‘<.*!@>’)
- 分词
英文:split()
中文:pip install jieba
2.去掉停用词
英文:安装nltk
中文:自己构造中文停用词表 1208个
3.英文单词
stemming词干提取 lemmation 词型还原
使用nltk的wordnet
4.英文单词转换为小写
word=word.lower()
5.特征处理
bag of words词袋模型(bow ,, tf-idf)
n-gram语言模型(bigram, trigram)
word2vec分布式模型
二:RNN在NLP中的使用(Recurrent Neural Network)
原文参考:https://zhuanlan.zhihu.com/p/40797277
区别与N-gram RNN可以看到整个句子的前后,而2-gram。3-gram 等等只能看到一个句子的局部,所以误差比较大。
基本循环神经网络:
输入层—隐藏层—输出层 可以往前看任意个输出值
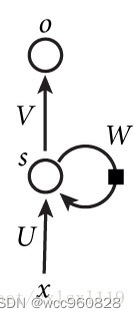
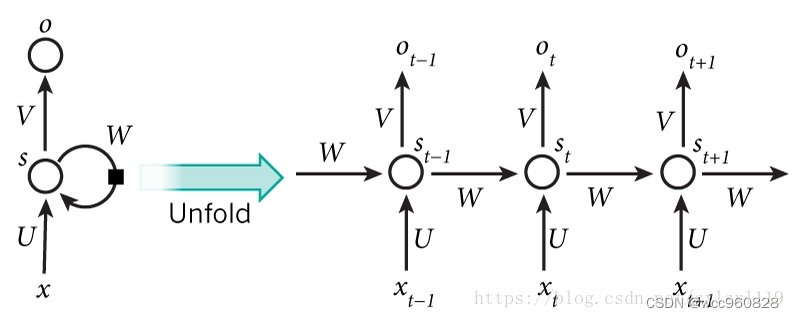
传统的神经网络(包括CNN),输入和输出都是相互独立的,例如一张图片的猫和狗是分隔开的,但是有些任务后续输出和之前的内容是相关的,局部的信息不足以使得后续的任务能够进行下去。RNN是需要之前或则之前序列的信息才能够使得任务进行下去的神经网络。RNN引入‘记忆’的概念,循环2字来源于其每个元素都执行相同的任务,但是输出依赖于输入和‘记忆’。其结构如下图所示:

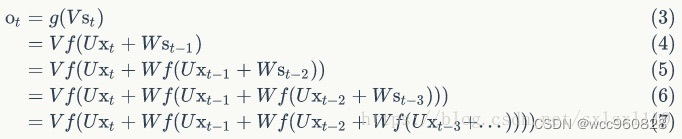
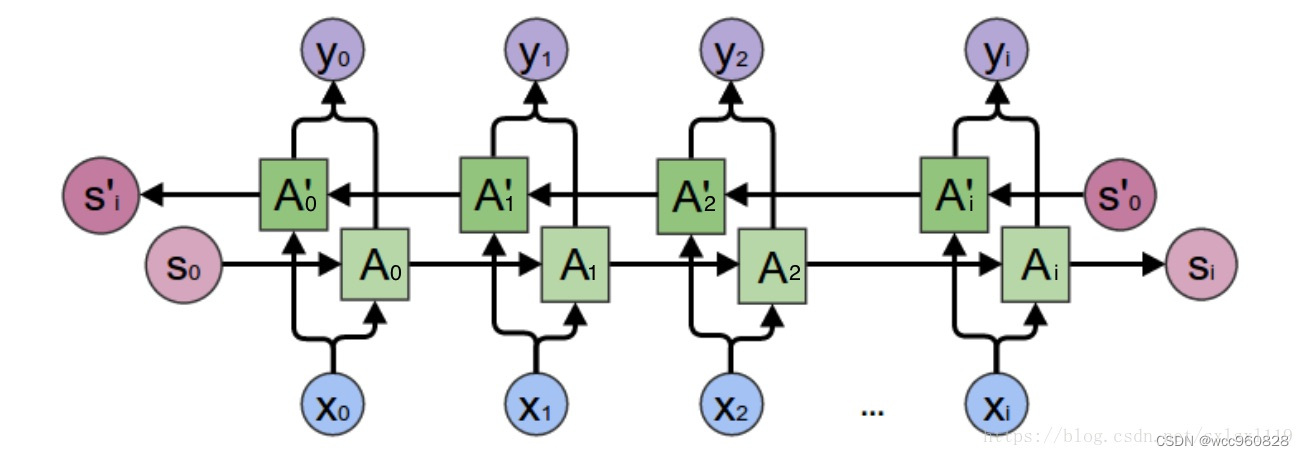
双向循环神经网络(英语完形填空不仅取决于前面的单词也取决于后面的单词)

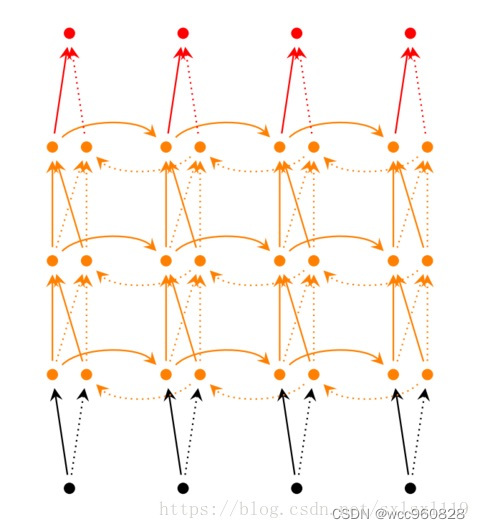
深度循环神经网络(隐藏层堆叠两个以上的隐藏层)

三:递归神经网络(Recursive Neural Network)
RNN实际效果与CNN差别不大,但训练速度比CNN慢太多
四:为什么在RNN中加入LSTM http:// https://zhuanlan.zhihu.com/p/40797277
随着时间间隔变大,RNN会丧失学习连接到很远的信息,也就是记忆容量有限,LSTM的记忆细胞被改造,应该记住的东西(如新输入的东西)会一直被传递下去,不该被记住的东西会被截断。
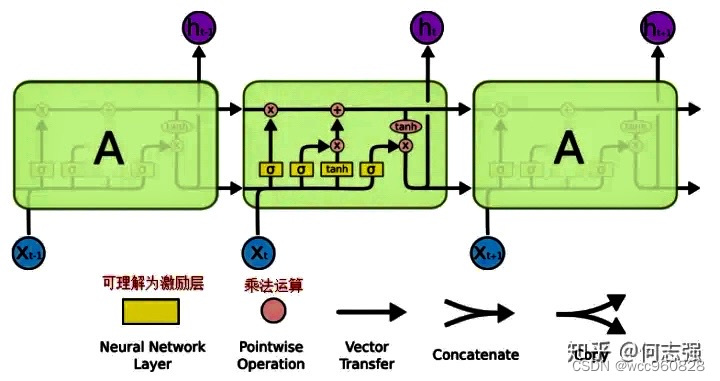
RNN细胞结构:
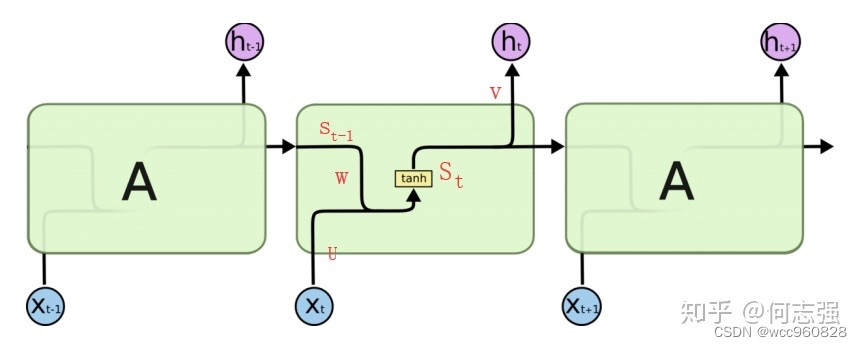
LSTM细胞结构:在RNN基础上加以改造
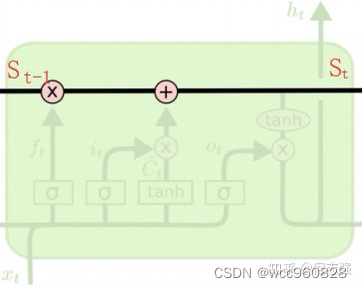
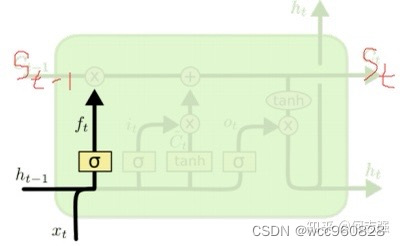
第一步:forget
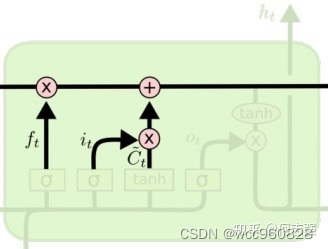
第二步:update
第三步:output
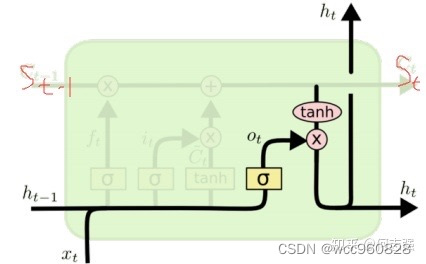
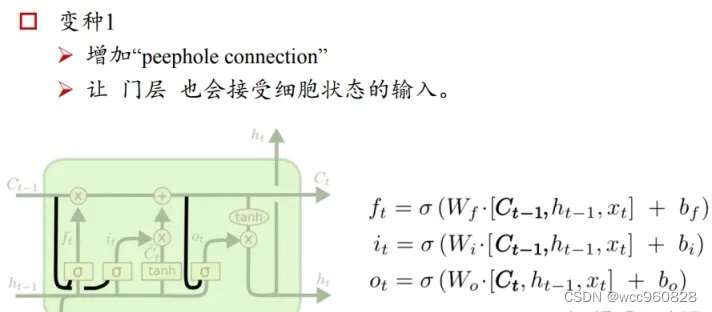
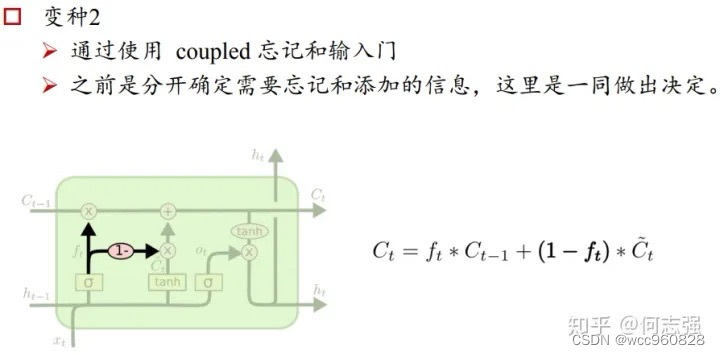
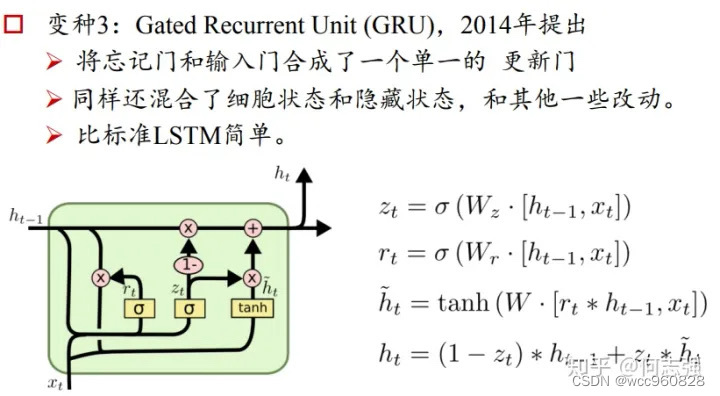
LSTM的几个变体