Base64在输出钱包地址的时候会出现的问题
地址中的大小写字母等无法识别,所以引用Base58.
Base58编码方式(将冲突项都去掉)
- 在Base64的基础上去掉了比较容易混淆的字符
- Base58中不含Base64中的数字 0 ,大写字母 O ,小写字母 l ,大写字母 I ,以及 “+” 和 “/” 两个字符。
- 无法用整字节来转换表示Base58,所以开销会比64和16大得多,但是利于展示地址。
辗转相除法解决上述字节编码问题
1、字符1代表0、字符2代表1,字符3代表2…字符z代表57.
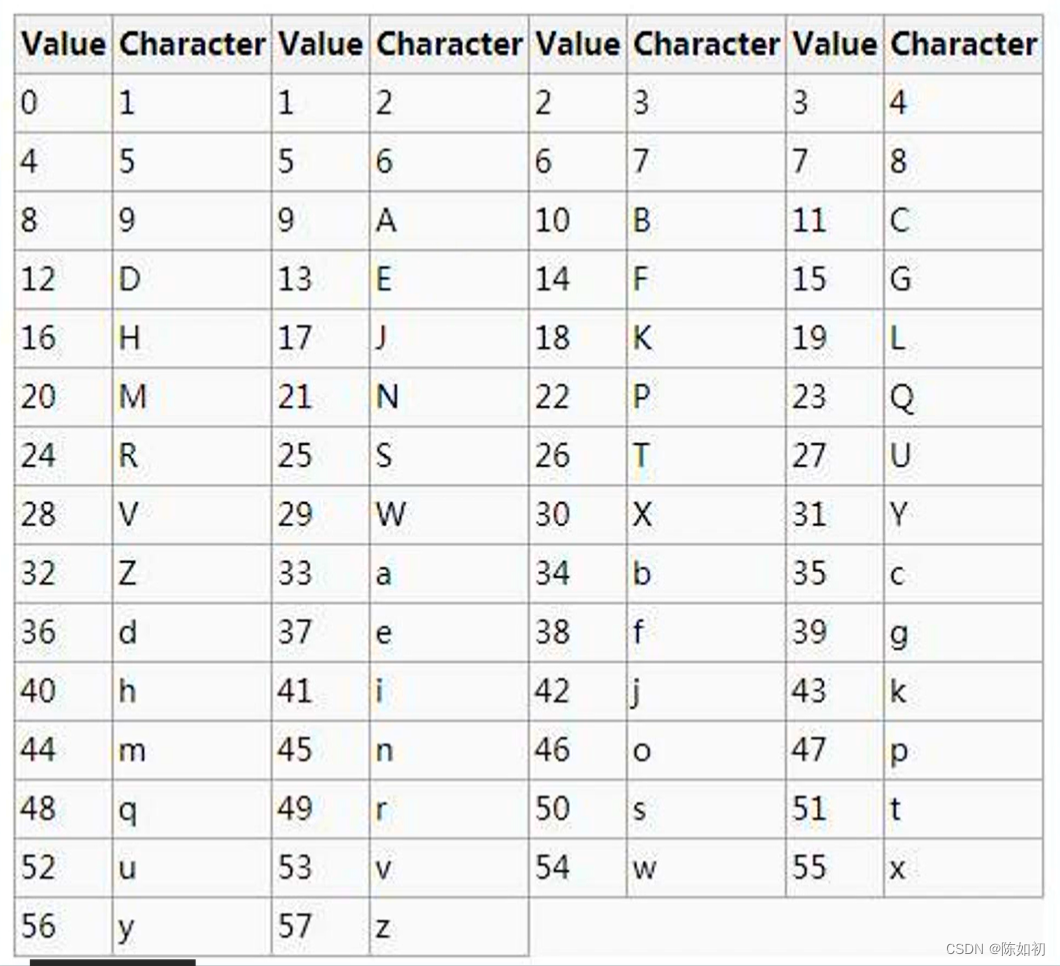
2、如果将1234转换为58进制:
(1)、1234除以58,商为21,余数为16,查上表得H
(2)、21除以58,商为0,余数为21,查表得N
(3)、得到base58编码为:NH
(4)、每个字符串转换之前先把转换数前面的0,转成对应的编码1
3、base58输出字节数:
(1)、位数:log2(58)(每一个字母代表的信息量是log2(58))
(2)、输出的字节:(length8)bit
(3)、预留的字符数量:(length8)/log2(58)=length*1.38
Base58 编解码
(1)编码部分
//编码表
static const char* pszBase58 = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz";
//编码函数:
std::string EncodeBase58(const unsigned char* pbegin, const unsigned char* pend)
{
// Skip & count leading zeroes.
int zeroes = 0;
int length = 0;
while (pbegin != pend && *pbegin == 0) {
pbegin++;
zeroes++;
}
// Allocate enough space in big-endian base58 representation.
int size = (pend - pbegin) * 138 / 100 + 1; // log(256) / log(58), rounded up.
std::vector<unsigned char> b58(size);
while (pbegin != pend) {
int carry = *pbegin;
int i = 0;
// Apply "b58 = b58 * 256 + ch".
for (auto it = b58.rbegin();
(carry != 0 || i < length) && (it != b58.rend());
it++, i++) {
carry += 256 * (*it);
*it = carry % 58;
carry /= 58;
}
assert(carry == 0);
length = i;
pbegin++;
}
// Skip leading zeroes in base58 result.
std::vector<unsigned char>::iterator it = b58.begin() + (size - length);
while (it != b58.end() && *it == 0)
it++;
// Translate the result into a string.
std::string str;
str.reserve(zeroes + (b58.end() - it));
str.assign(zeroes, '1');
while (it != b58.end())
str += pszBase58[*(it++)];
return str;
}
(2)解码部分
// 解码表需要自建,要满足处理时需要的 256位 和取出形近字符的要求
static const int8_t mapBase58[256] = {
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8,-1,-1,-1,-1,-1,-1,
-1, 9,10,11,12,13,14,15, 16,-1,17,18,19,20,21,-1,
22,23,24,25,26,27,28,29, 30,31,32,-1,-1,-1,-1,-1,
-1,33,34,35,36,37,38,39, 40,41,42,43,-1,44,45,46,
47,48,49,50,51,52,53,54, 55,56,57,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
};
//解码函数
bool DecodeBase58(const char* psz, std::vector<unsigned char>& vch, int max_ret_len)
{
// Skip leading spaces.
while (*psz && IsSpace(*psz))
psz++;
// Skip and count leading '1's.
int zeroes = 0;
int length = 0;
while (*psz == '1') {
zeroes++;
if (zeroes > max_ret_len) return false;
psz++;
}
// Allocate enough space in big-endian base256 representation.
int size = strlen(psz) * 733 / 1000 + 1; // log(58) / log(256), rounded up.
std::vector<unsigned char> b256(size);
// Process the characters.
static_assert(sizeof(mapBase58) / sizeof(mapBase58[0]) == 256, "mapBase58.size() should be 256"); // guarantee not out of range
while (*psz && !IsSpace(*psz)) {
// Decode base58 character
int carry = mapBase58[(uint8_t)*psz];
if (carry == -1) // Invalid b58 character
return false;
int i = 0;
for (std::vector<unsigned char>::reverse_iterator it = b256.rbegin(); (carry != 0 || i < length) && (it != b256.rend()); ++it, ++i) {
carry += 58 * (*it);
*it = carry % 256;
carry /= 256;
}
assert(carry == 0);
length = i;
if (length + zeroes > max_ret_len) return false;
psz++;
}
// Skip trailing spaces.
while (IsSpace(*psz))
psz++;
if (*psz != 0)
return false;
// Skip leading zeroes in b256.
std::vector<unsigned char>::iterator it = b256.begin() + (size - length);
// Copy result into output vector.
vch.reserve(zeroes + (b256.end() - it));
vch.assign(zeroes, 0x00);
while (it != b256.end())
vch.push_back(*(it++));
return true;
}
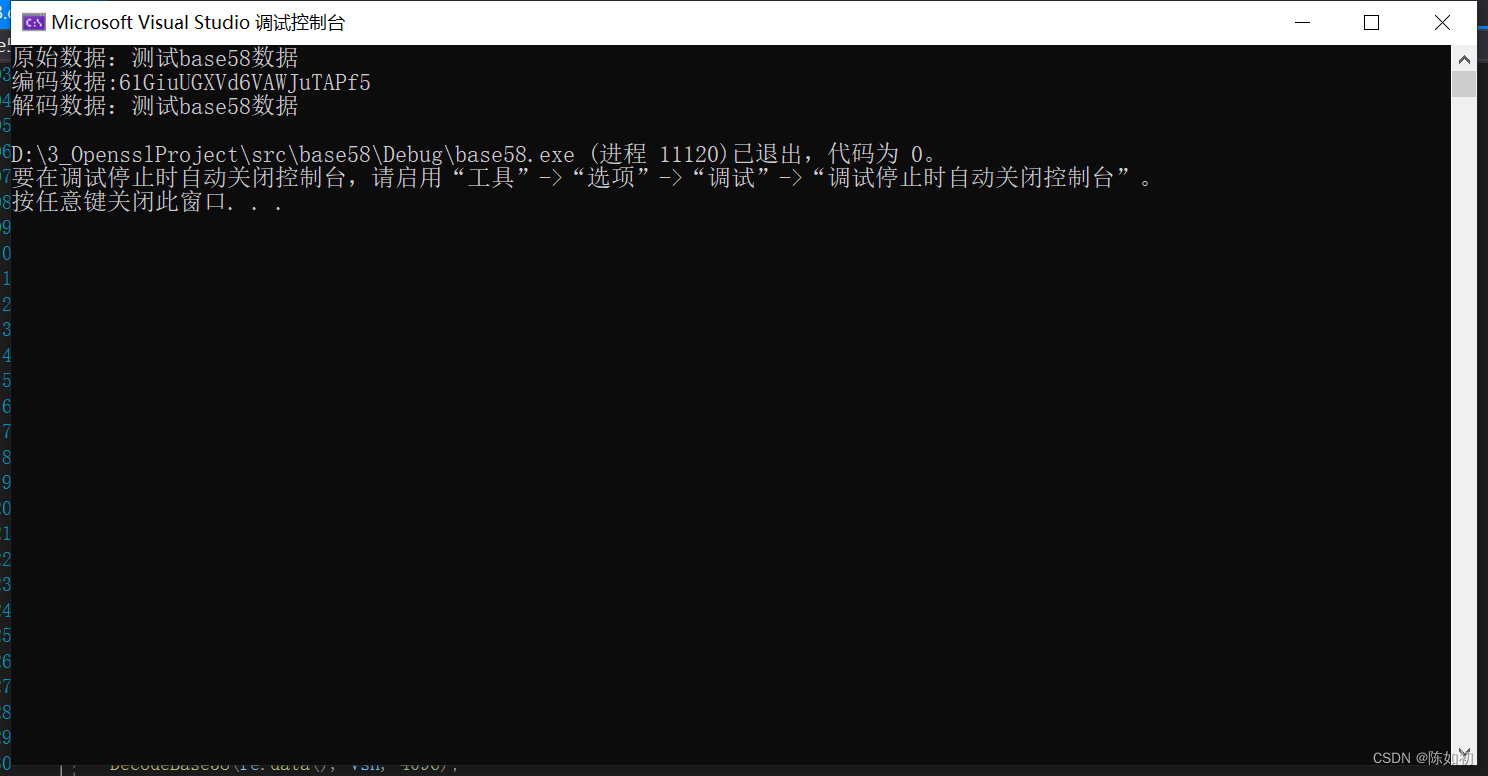
测试结果