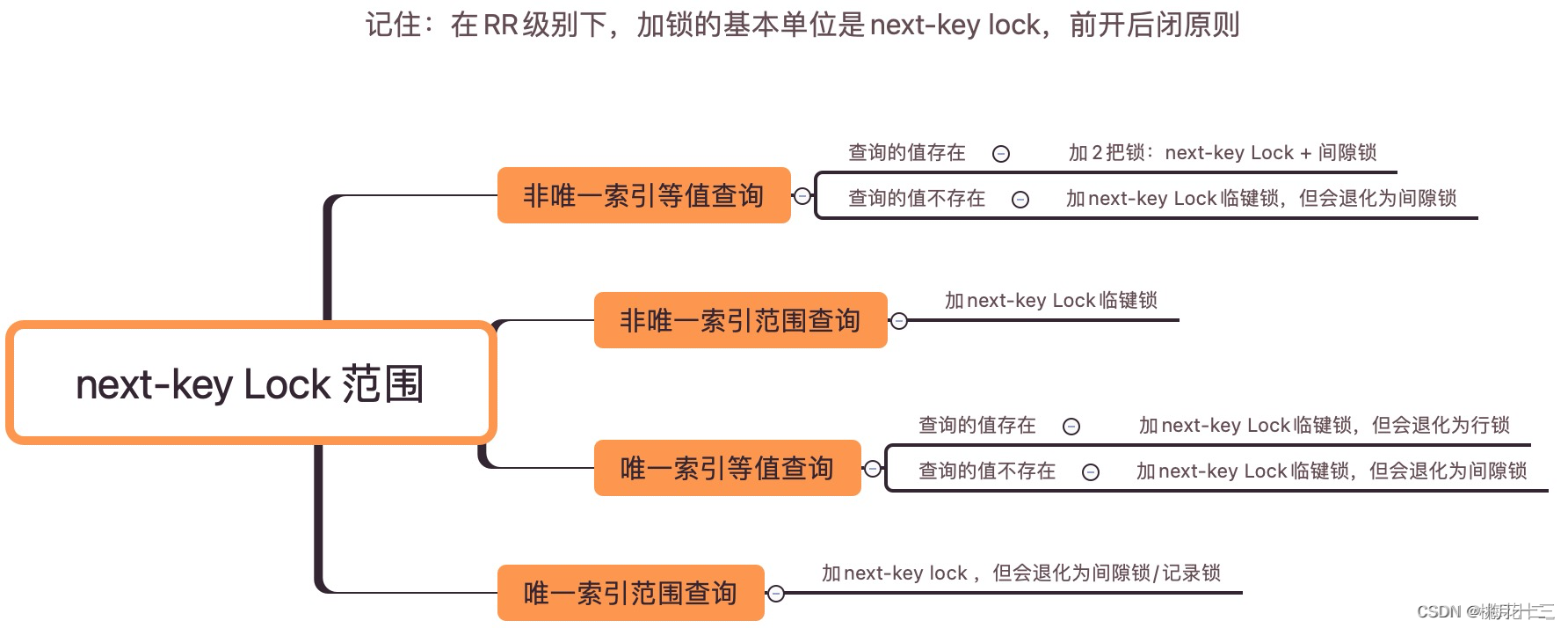
目录标题
前言
数据准备
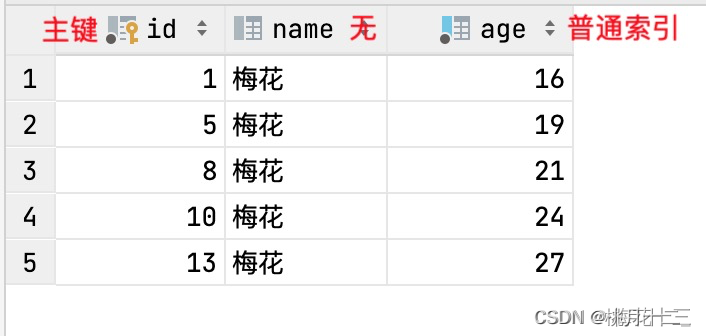
测试
1. 唯一索引的等值查询
查询的记录存在:在用「唯一索引进行等值查询」时,next-key lock 会退化成「记录锁」
查询的记录不存在:在用「唯一索引进行等值查询」时,next-key lock 会退化成「间隙锁」
唯一索引等值查询:记录存在,临键锁退为行锁

事务A加锁变化过程:
1.查询 id=8的数据,加锁的基本单位是 next-key lock,因此事务A的加锁范围是 id (5, 8];
2.唯一索引(包括主键索引) 进行等值查询,且查询的记录存在,所以next-key lock 退化成记录锁,最终加锁的范围就是 id = 8 这一行。
结论:
由于id=8退化为行锁,因此事务B修改 id=8的这条记录失败,而事务C插入id=6能够成功
唯一索引等值查询:记录不存在,临键锁退为间隙锁
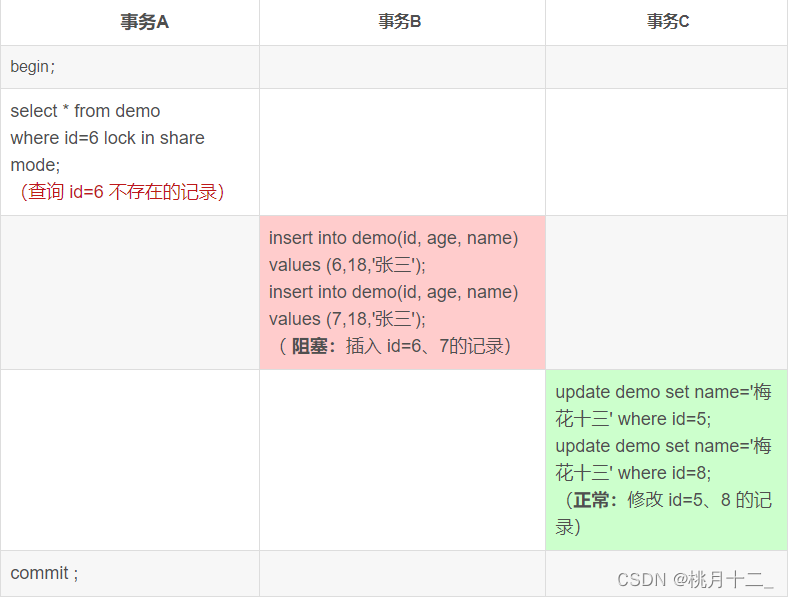
事务A加锁变化过程:
1.查询 id=6不存在的数据,加锁基本单位next-key lock,因此事务A的加锁范围是 id (5, 8];
2.唯一索引进行等值查询,由于查询的记录不存在,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,8)。
结论:
由于退化为间隙锁,因此事务B插入该间隙锁(5,8) 范围区间,id=6、7的数据都会失败,而事务C修改上下区间边界值id = 5、8的是能够成功的,因为是前开后开原则。
2. 唯一索引的范围查询
在满足一些条件的时候,临键锁退化为间隙锁和记录锁
select * from demo where id>=5 and id<7 lock in share mode;
事务A加锁变化过程:
1.首先最开始要找的记录是 id>=5,因此产生的临键锁 next-key lock 范围为:(1,5],但是由于 id 是唯一索引,且该记录是存在的,因此会退成记录锁,也就是只会对 id = 5 这一行加锁;
2.由于是范围查找,就会继续往后找存在的记录,也就是会找到 id = 8 这一行停下来,然后加 next-key lock (5, 8],但由于 id = 8 不满足 id < 7,所以会退化成间隙锁,加锁范围变为 (5, 8)。
根据事务A加锁变化得出,目前有2把锁,行锁:id=5 , 间隙锁:(5,8)。
假设事务B的操作,测试行锁
update demo set name='梅花十三' where id=5; -- 由于是行锁,锁定了该行,因此是无法修改的
假设事务B的操作,测试(5,8) 间隙锁区间范围
insert into demo(id, age, name) VALUES (6,18,'张三'); -- 失败
insert into demo(id, age, name) VALUES (7,18,'张三'); -- 失败
假设事务B的操作,测试下区间边界值
update demo set name='梅花十三' where id=8; -- id=8是间隙锁(5,8)范围内的下区间边界值,由于是后开原则,因此是可以修改的
3. 非唯一索引的等值查询【针对插入的数据在区间的边界值,则根据主键来判断锁定范围。】
查询的记录存在:除了会加 next-key lock 外,还额外加间隙锁,即加两把锁。
记录不存在时:只会加 next-key lock,然后会退化为间隙锁,即只会加一把锁。
非唯一索引,记录存在,除了加临键锁,还会额外增加间隙锁,两把锁
select * from demo where age=21 lock in share mode; -- 查询age=21的记录,并加读锁(共享锁)
事务A加锁变化过程:
1.对普通索引 age 加上 next-key lock,临键锁本身是左开右闭的区间,即范围是(19,21],也就是说,除了锁定age=21 这条记录本身,还锁定了索引节点上 age=21 前面的那个间隙。
因为是非唯一索引,且查询的记录是存在的(加锁规则1),所以还会加上Gap Lock间隙锁,规则是向下遍历到第一个不符合条件的值才能停止,因此间隙锁的范围是(21,24)
结论:
事务A的普通索引 age上共有两个锁,分别是 next-key lock(19,21] 和 间隙锁(21,24) 。
假设事务B的数据操作如下,测试第一把锁范围:age临键锁(19-21]
update demo set name='梅花十三' where age=19; -- 成功
insert into demo(id, age, name) VALUES (4,19,'张三'); -- 成功
insert into demo(id, age, name) VALUES (7,19,'张三'); -- 失败
insert into demo(id, age, name) VALUES (20,19,'张三'); -- 失败
思考:为什么age相同的情况都是19,其id=4的记录能够插入成功,而id=7或20的插入失败!
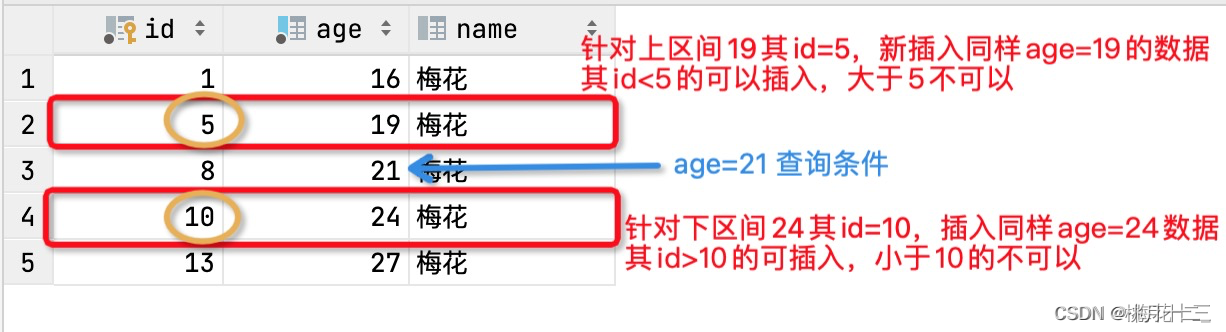
插入的数据在区间的边界值,则根据主键来判断锁定范围。针对锁范围 (19,21] ,其锁相对应的id范围是(5,8),如果新插入的数据,其age值是上区间边界值19,则其插入的主键必须是小于 age=19所对应的id值5。主键<5的可以插入,>5的不可以,否则插入失败。
insert into demo(id, age, name) VALUES (4,20,'张三'); -- 失败
insert into demo(id, age, name) VALUES (7,20,'张三'); -- 失败
update demo set name='梅花' where age=20; -- 成功(不存在的记录,修改无意义)
insert into demo(id, age, name) VALUES (7,21,'张三'); -- 失败
update demo set name='梅花update' where age=21; -- 失败
-- 21处于(19,21] 的后闭范围,因此age=21这条索引是被锁住的,无论修改还是新增都失败
假设事务B的数据操作如下,测试第一把锁范围: age间隙锁(21-24)
insert into demo(id, age, name) VALUES (9,22,'张三'); -- 失败
insert into demo(id, age, name) VALUES (9,23,'张三'); -- 失败
update demo set name='梅花update' where age=24; -- 成功
insert into demo(id, age, name) VALUES (9,24,'张三'); -- 失败
insert into demo(id, age, name) VALUES (11,24,'张三'); -- 成功
思考:为什么age相同的情况都是24,其id=9的记录失败了,而id=11的插入成功!
插入的数据在区间的边界值,则根据主键来判断锁定范围。针对锁范围 (21,24),下区间边界值是24,其对应的id为10,如果新插入的数据,其age值是下区间边界值24,则其插入的主键必须是大于 age=24所对应的id值10。即主键>10的可以插入,<10不可以,否则插入失败。
注意:针对插入的数据在区间的边界值,则根据主键来判断锁定范围。这里需要区分一个点,是上区间还是下区间,如下图,即便插入的是边界值,最终它封锁的还是 (19,24) 这个范围。
非唯一索引,记录不存在,临键锁退为间隙锁,一把锁
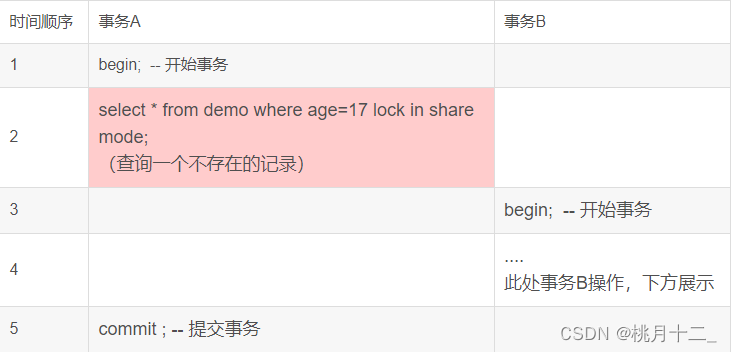
事务A加锁变化过程:
1.加锁查询age=17的记录,先会对普通索引 age 加上 next-key lock,范围是(16,19]。
2.由于查询的记录不存在(加锁规则2),所以不会再额外加个间隙锁,但next-key lock 会退化为间隙锁,最终加锁范围是 (16,19)。
假设事务B的操作如下
update demo set name='梅花十三' where age=16; -- 成功
insert into demo(id, age, name) VALUES (-1,16,'张三'); -- 成功
insert into demo(id, age, name) VALUES (2,16,'张三'); -- 失败
针对上区间边界值16,如果新插入的数据age值也是16,则其插入的主键id必须小于age=16所对应的id值 1,也就是说 主键<1 的可以插入, 否则插入失败。
-- (16,19)锁区间范围内的值,age=17、18都会被事务A锁住,不管主键是什么,事务B都无法插入
insert into demo(id, age, name) VALUES (-1,17,'张三'); -- 失败
insert into demo(id, age, name) VALUES (2,17,'张三'); -- 失败
insert into demo(id, age, name) VALUES (2,18,'张三'); -- 失败
insert into demo(id, age, name) VALUES (4,19,'张三'); -- 失败
insert into demo(id, age, name) VALUES (6,19,'张三'); -- 成功
针对下区间边界值19,如果新插入的数据age值也是19,则其插入的主键id必须大于age=19所对应的id值 5,也就是说 主键>5 的可以插入, 否则插入失败。
insert into demo(id, age, name) VALUES (2,15,'张三'); -- 成功
insert into demo(id, age, name) VALUES (6,20,'张三'); -- 成功
4. 非唯一索引的范围查询【针对插入的数据在区间的边界值,则根据主键来判断锁定范围。】
select * from demo where age>=19 and age<22 lock in share mode;
事务A加锁变化过程如下:
1.首先最开始要找的记录是 age>=19,因此产生的临键锁 next-key lock 范围为:(16,19]
2.由于是范围查找,则继续往后找存在的记录,查询条件age<22 最终产生2个next-key lock,分别是 (19,21]、(21, 24]
结论:
事务A产生的三把next-key lock,范围分别是:(16,19]、 (19,21]、(21, 24],总范围可以得出:(16,24]
假设事务B的操作如下
update demo set name='梅花十三' where age=16; -- 成功
insert into demo(id, age, name) VALUES (-1,16,'张三'); -- 成功
insert into demo(id, age, name) VALUES (2,16,'张三'); -- 失败
注意:插入的数据在区间的边界值,则根据主键来判断锁定范围
update demo set name='梅花十三' where age=24; -- 失败
insert into demo(id, age, name) VALUES (9,24,'张三'); --失败
insert into demo(id, age, name) VALUES (11,24,'张三'); -- 成功
注意:插入的数据在区间的边界值,则根据主键来判断锁定范围
结论
唯一索引等值查询
当查询的记录是存在的,next-key lock 会退化成「记录锁」。
当查询的记录是不存在的,next-key lock 会退化成「间隙锁」。
非唯一索引等值查询【针对插入的数据在区间的边界值,则根据主键来判断锁定范围。】
当查询的记录存在时,除了会加 next-key lock 外,还额外加间隙锁,也就是会加两把锁。
当查询的记录不存在时,只会加 next-key lock,然后会退化为间隙锁,也就是只会加一把锁。
非唯一索引和主键索引的范围查询的加锁规则不同之处在于
唯一索引在满足一些条件的时候,next-key lock 退化为间隙锁和记录锁。
非唯一索引范围查询,next-key lock 不会退化为间隙锁和记录锁。