本篇继续来介绍SQLite中的一些常用语句,这次介绍这5个:
- limit:用于限制由select语句返回的数据数量
- order by:用来基于一个或多个列按升序或降序顺序排列数据
- group by:与select语句以及order by语句一起使用,来对相同的数据进行分组
- having:可以指定条件来过滤group by分组的结果
- distinct:与select语句一起使用,用来消除重复的记录,并只获取唯一一次的记录
下面通过实例来演示这4个的用法,通过命令行的方式进行快速测试。
1 限制-limit
limit语句用于限制由select语句返回的数据数量。使用select语句,会把符合调节的所有数据都筛选出来,如果只是想要一条数据,或是数据太多的情况下,只想要指定数据的数据,这时就可以再配合limit语句进行数量上的限制了。
其基本语法如下:
select column1, column2, columnN
from table_name
limit [no of rows]
其中,no of rows即为要限制输出的行数。
还可以与offset子句一起使用,用于指定偏移量,及从指定的行数(row num)开始,输出需要数量(no of rows)的数据
select column1, column2, columnN
from table_name
limit [no of rows] offset [row num]
以之前的测试的数据库为例,有如下数据:
sqlite> select * from SCORE;
id chinese math english
-- ------- ---- -------
1 90 95 88
2 80 90 92
3 85 89 82
4 80 81 82
5 90 91 92
6 90 88 89
若想要从表中提取前3行数据,sql语句为:
select * from SCORE limit 3;
结果如下图所示,可以看出该指令筛选出了前3条数据,即id 1~3:

若想要从表中的第2行之后,提取3行数据,sql语句为:
select * from SCORE limit 3 offset 2;
结果如下图所示,可以看出该指令筛选出了从第2条数据之后的3条数据,即id 3~5:

2 排序-order by
order语句用来基于一个或多个列按升序或降序顺序排列数据。使用select语句,会把符合调节的所有数据都筛选出来,如果想让数据按照某种顺序输出出来,这时就可以再配合order by语句进行排序了。
其基本语法为:
select column-list
from table_name
[where condition]
[order by column1, column2, .. columnN] [asc | desc];
其中,condition是可选的调节。asc是升序排序,desc是降序排序。
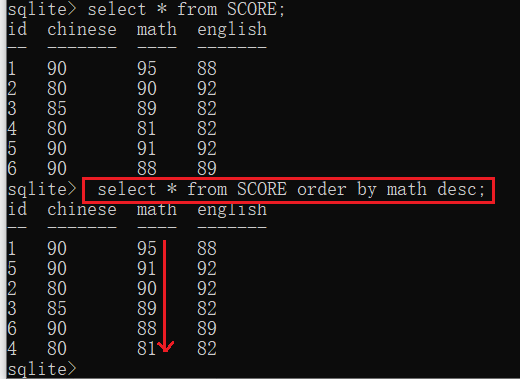
比如将数据按照math成绩降序排序:
select * from SCORE order by math desc;
结果如下图所示,可以看出该指令使得所有数据按照math降序输出:
再比如将id前3的数据按照chinese成绩升序排序,就可以把condition条件加上,sql语句为:
select * from SCORE where id <= 3 order by chinese asc;
结果如下图所示,可以看出该指令使得前3条数据按照math升序输出:

排序后,如果再结合limit语句,就可以选出最高分或最低分的数据了。
3 分组-group by
group by子句用于与select语句以及order by语句一起使用,来对相同的数据进行分组。
其基本语法为:
select column-list
from table_name
where [ conditions ]
group by column1, column2....columnN
order by column1, column2....columnN;
测试group by的使用时,需要创建一个稍微复杂一点的数据库。
先创建一个表:

然后写入下面这些数据:
命令行打开查看:
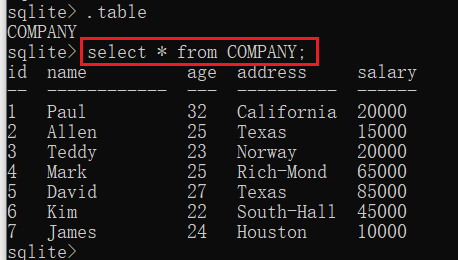
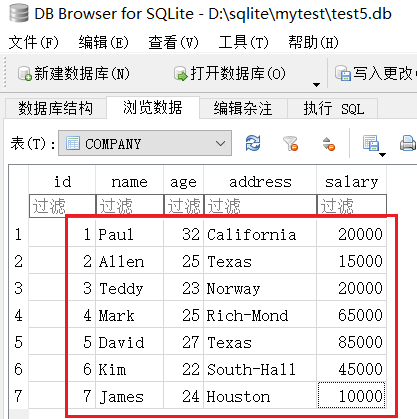
目前数据库中有如下数据:
id name age address salary
-- ------------ --- ---------- ------
1 Paul 32 California 20000
2 Allen 25 Texas 15000
3 Teddy 23 Norway 20000
4 Mark 25 Rich-Mond 65000
5 David 27 Texas 85000
6 Kim 22 South-Hall 45000
7 James 24 Houston 10000
注意,这里的7条数据,从name、age、address列可以看出,这是7个不同的员工。
假如这张表中有同一个人的多条记录(发了多次工资)或有同名的人,我们可以使用inset语句插入几条数据来创造这样的情况:
insert into COMPANY values (8, 'Paul', 32, 'California', 15000 );
insert into COMPANY values (9, 'James', 44, 'Houston', 30000 );
insert into COMPANY values (10, 'James', 24, 'Texas', 40000 );
插入后再来看一下:

如果想查看每个人的工资总额(以相同的name、age、address为同一员工),则可使用group by查询:
select id, name, age, address, sum(salary) from COMPANY group by name, age, address order by id asc;

可以看出,输出了9条数据,因为id1和id8被合并了,这两条是同一个人(group by name, age, address的作用),输出的结果也通过sum语句输出了该职工的总工资3500(sum(salary)的作用),输出是按照id升序排序的(order by id asc的作用)。
假如,换一个标准来判定是否是一个人,比如只要名字和年龄一样,可以使用如下指令再试一下:
select id, name, age, address, sum(salary) from COMPANY group by name, age order by id asc;

4 过滤-having
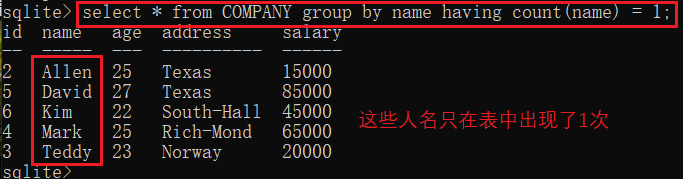
上面的group by子句可以对数据进行分组,那可不可以对分组的数据进一步筛选呢?比如,只想列出name计数为1的人名(没有重名的人)
having子句可以指定条件来过滤group by分组的结果
包含having的语法示例:
select column1, column2
from table1, table2
where [ conditions ]
group by column1, column2
having [ conditions ]
order by column1, column2
示例,以上次创建的数据为例,有如下数据:
id name age address salary
-- ----- --- ---------- ------
1 Paul 32 California 20000
2 Allen 25 Texas 15000
3 Teddy 23 Norway 20000
4 Mark 25 Rich-Mond 65000
5 David 27 Texas 85000
6 Kim 22 South-Hall 45000
7 James 24 Houston 10000
8 Paul 32 California 15000
9 James 44 Houston 30000
10 James 24 Texas 40000
显示name只出现2次以上的所有记录:
select * from COMPANY group by name having count(name) > 2;

显示name只出现1次的所有记录:
select * from COMPANY group by name having count(name) = 1;
5 去重-distinct
distinct与select语句一起使用,用来消除重复的记录,并只获取唯一一次的记录。
其基本语法为:
select distinct column1, column2,.....columnN
from table_name
where [condition]
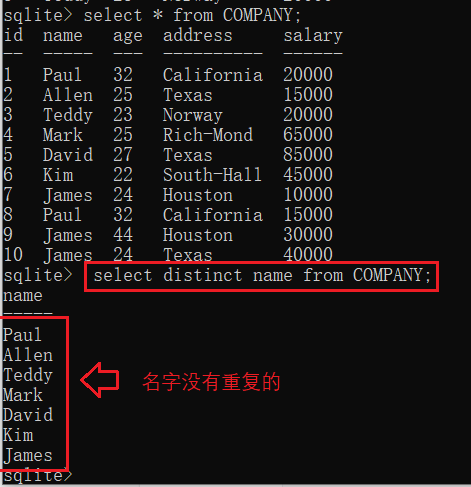
例如,可以使用distinct来查询没有重复的人名:
select distinct name from COMPANY;
本篇介绍了5种了SQLite常用语句:用于限制数量的limit、用于排序输出的order by、用于分组的group by、用于进一步过滤的having以及用于去除重复的distinct。