文章目录
1. ITK多线程简介
1.1~1.3部分主要是翻译自以下内容:
ITK的Guide book:https://itk.org/ItkSoftwareGuide.pdf,Part II Architecture->SYSTEM OVERVIEW->3.2.7 Multi-Threading
1.1 平台多线程
1.1.1 基本内容
- ITK的多线程是通过一个高层的抽象设计解决的,这个方法提供遍历的多线程,同时隐藏了ITK所支持的不同系统的线程实施的复杂性(比如:linux的多线程,windows的多线程,包括不同cpu的多线程等)
- 例如:
itk::PlatformMultiThreader这个类直接使用平台特定的语法来执行多线程,例如:Unix类系统的pthread_create方法(创建线程的函数) - 而
itk::TBBMultiThreader这个线程类则使用了Intel的TBB库来实现多线程,这个库进行了多线程间的动态负载均衡 - 所有的
multi-threader都继承自itk::MultiThreaderBase类
在ITK的itk::MultiThreaderBase 类页面中,可以看到有以下继承关系
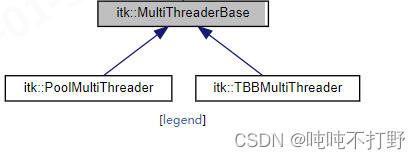
可以看到,这里另外有两个类是itk::PoolMultiThreader和itk::TBBMultiThreader 。
另外,在itk::MultiThreaderBase类中,
其实关于Threader的枚举值,有:Platform、First、Pool、TBB、Last和Unknown这6种。
namespace itk
{
class MultiThreaderBaseEnums
{
public:
enum class Threader : int8_t
{
Platform = 0,
First = Platform,
Pool,
TBB,
Last = TBB,
Unknown = -1
};
可以看到,
- First就是Platform,默认第一种就是调用每个系统特定的多线程
- TBB就是Last
- Pool
- 所以实际上就只有3种,Platform,Pool和TBB(后两个需要进行额外coding,所以继承了
MultiThreaderBase类)
using ThreaderEnum = MultiThreaderBaseEnums::Threader;
#if !defined(ITK_LEGACY_REMOVE)
using ThreaderType = ThreaderEnum;
static constexpr ThreaderEnum Platform = ThreaderEnum::Platform;
static constexpr ThreaderEnum First = ThreaderEnum::First;
static constexpr ThreaderEnum Pool = ThreaderEnum::Pool;
static constexpr ThreaderEnum TBB = ThreaderEnum::TBB;
static constexpr ThreaderEnum Last = ThreaderEnum::Last;
static constexpr ThreaderEnum Unknown = ThreaderEnum::Unknown;
1.1.2 Intel的TBB
ITK对TBB的支持,详见:itk::TBBMultiThreader Class Reference
关于TBB(线程构建模块(Thread Building Blocks,简称TBB)是Intel公司开发的并行编程开发的工具),可以参考:
OpenMP(就是omp)是和TBB同类型的工具,可以看看
1.2 典型例子(执行原理)
多线程通常是在算法执行阶段使用,
例如:对于类itk::ImageSource(大部分图像处理filter的父类),其中的GenerateData()方法如下:
this->GetMultiThreader()->template ParallelizeImageRegion<OutputImageDimension>(
this->GetOutput()->GetRequestedRegion(),
[this](const OutputImageRegionType & outputRegionForThread)
{
this->DynamicThreadedGenerateData(outputRegionForThread); }, this);
这个例子里,
- 每个线程都会触发衍生类(
itk::ImageSource的子类)的DynamicThreadedGenerateData方法
(例如:itk::ThresholdImageFilter中就有DynamicThreadedGenerateData方法,注意,不是所有的Filter都支持这个方法的) ParallelizeImageRegion方法用来将图像分成不重叠的不同区域,用于写操作。itk::ImageSource的GenerateData()方法将this指针传给ParallelizeImageRegion,这样ParallelizeImageRegion方法就可以更新region处理后的filter的进度了。
对于某个filter,如果其可以线程化,
- 则它的父类会有1个
GenerateData()方法,这个方法里会分配输出数据缓冲,生成多个线程,同时为每个线程调用DynamicThreadedGenerateData()方法,- 每个filter自己要实现
DynamicThreadedGenerateData()方法,父类实现GenerateData()方法
如果一个filter执行过程中会涉及一些串行操作,那么除了在BeforeThreadedGenerateData()方法中完成初始化,在AfterThreadedGenerateData()完成析构操作之外,可以在自己的GenerateData()方法中并行多个方法
- 例如:在
itk::CannyEdgeDetectionImageFilter的GenerateData()方法中
::GenerateData()
{
this->UpdateProgress(0.0f);
Superclass::AllocateOutputs();
// 简单的串行计算
this->UpdateProgress(0.01f);
ProgressTransformer progress1( 0.01f, 0.45f, this );
// 计算2阶方向导数
this->GetMultiThreader()->template ParallelizeImageRegion<TOutputImage::ImageDimension>(
this->GetOutput()->GetRequestedRegion(),
[this](const OutputImageRegionType & outputRegionForThread)
{
this->ThreadedCompute2ndDerivative(outputRegionForThread); }
progress1.GetProcessObject());
ProgressTransformer progress2( 0.45f, 0.9f, this );
// 计算第二个导数的梯度
this->GetMultiThreader()->template ParallelizeImageRegion<TOutputImage::ImageDimension>(
this->GetOutput()->GetRequestedRegion(),
[this](const OutputImageRegionType & outputRegionForThread)
{
this->ThreadedCompute2ndDerivativePos(outputRegionForThread); },
progress2.GetProcessObject());
// 更新进度100%
this->UpdateProgress(1.0f);
}
- 当从
GenerateData()中多次触发ParallelizeImageRegion时,this要么是空指针nullptr,要么是itk::ProgressTransformer对象,否则UpdateProgress会从0%更新到100%多次。 - 虽然程序不至于崩溃,但是这样的代码没有明确的意义,执行很confused。
- 因此,如果要自定义
filter,那么可以自己评估一下GenerateData()中每个部分的执行,构建传递合适的itk::ProgressTransformer对象进度。
1.3 5.X版本之后的变动
ITK 5.0对多线程机制进行了重构,以前是itk::MultiThreader,现在添加成为了类的层次结构
itk::PlatformMultiThreader这个类是对之前的旧类MultipleMethodExecute的一个轻量化洁净版本。SpawnThread方法被丢弃了(deprecated),不过其中很多东西都移到了itk::MultiThreaderBase中- 需要使用多线程的类应该通过
MultiThreader接口,来让调用库的用户可以在运行时灵活选择,同时为适应不同系统的multi-threader提供了良好的可扩展性 - 保留了向后兼容的
ThreadedGenerateData(Region, ThreadId)方法签名(这个函数的接口和名称没改过),以便已知线程数的filters进行调用。方法签名(method signature),方法名和形参列表共同组成方法签名(就是函数头)。- 要使用这个签名,则
filter需要在进行Update()之前,需要触发this->DynamicMultiThreadingOff(),由调用者或者是pieline的下游filter调用。最好的触发this->DynamicMultiThreadingOff()的位置,是filter的构造器里(初始化的时候触发)
- 在
image filters和其他ProcessObject的子类中,SetNumberOfWorkUnits方法用来控制并行的程度,当NumberOfWorkUnits数量大于线程数时,可以进行负载均衡。在开发者想要限制线程(threads)数量的大部分地方,应该使用更改work units的方法来进行itk::MultiThreaderBase的MaximumNumberOfThreads不应该改变,除非时测试性能、可伸缩性以及分析,或者是调试代码的时候。
- ITK中关于线程安全的共识是:访问一个类的不同实例(包括方法)都是线程安全的操作;在不同线程里调用同一个实例是不安全的(应该避免)
更多实现层面的了解,可以参考github上的文档:Multithreading refactored
可以在这个页面搜索”SetNumberOfWorkUnits“
1.4 ITK多线程整体认识
1.4部分主要来自ITK官方文档:Threading
1.4.1 基本内容
ITK在设计的时候,就考虑了在多处理器环境下运行。
- ITK的很多filters都是多线程的
- 当一个多线程的filter执行时,会自动在共享内存配置的多处理器中划分工作,称为
Filter Level Multithreading(过滤器级别的多线程)- 例如下面的动图:
- 多个CPU(处理器)在共享内存中,自动把输入划分到不同处理器中执行,然后再把不同处理器的结果合并,即:过滤器级别的多线程

- 使用ITK构建的应用,也可以管理自己执行的线程。例如:一个应用可以使用1个线程来处理数据,使用另一个线程处理用户界面,这称为
Application Level Multithreading(应用级别的多线程)
1.4.2 过滤器级别的多线程(Filter Level Multithreading)
- 如果希望一个filter支持多线程,那么与普通单线程需要实现GenerateData()方法不同,其需要提供ThreadedGenerateData()方法的实现
- filter的父类会产生多个线程(通常和系统中处理器的数量匹配),会调用每个线程中的
ThreadedGenerateData()方法,来指定输出中每个线程负责生成的部分。 - 例如:对于一个有两个处理器(可以开两个线程)的计算机来说,则一个图像处理filter可以产生两个线程,每个处理线程负责生成结果的一半,同时每个线程只能写输出图像中对应的那部分。
- 注意:
entire输入和entire输出图像(指的是GenerateData()方法可得的图像,可以查看Streaming部分的讨论)在每次ThreadedGenerateData()方法的调用中都是可得的。 - 每个线程都可以读取输入图像的所有部分,但是每个线程只能在自己被规定好的输出图像的部分进行写操作。
- 输出图像在内存中占用一个连续的块,所有的处理线程都可以使用这个内存。每个线程都被分配了自己要在输出中负责生成的那部分像素,所有的线程都可以向这个内存块进行写入,但是每个线程只能写设置好的那部分像素
1.4.3 内存管理(Memory Management)
GenerateData()方法用于输出块数据的分配,对于图像处理filter来说,相当于对输出图像对象上调用Allocate()。- 如果一个filter是多线程的,那么它不需要提供
GenerateData()方法,但是需要提供ThreadedGenerateData()方法。这个filter的父类的GenerateData()方法会对输出块数据进行分配,并为每个线程调用ThreadedGenerateData()方法 - 如果一个filter不是多线程的,那么它必须提供自己的
GenerateData()方法,自己分配输出块数据(比如:对一个输出图像对象调用Allocate()方法)
1.5 GenerateData()和ThreadedGenerateData()、DynamicThreadedGenerateData()
1.5.1 GenerateData()
GenerateData()函数的说明文档
- 每个图像处理
filter都有自己的GenerateData()函数。主要作用是:通过多线程来把图像处理分成多个部分 - 缓冲区在这个方法里进行分配。
- 接下来调用
ThreadedGenerateData()方法(如果提供了的话)。 - 然后会生成很多线程,每个线程都会调用
DynamicThreadedGenerateData()方法 - 当所有线程都完成处理后,调用
AfterThreadedGenerateData()方法(如果提供了的话) - 如果一个图像处理
filter不能被线程化,则这个filter需要提供GenerateData()实现,用于分配输出缓冲区, - 如果一个图像处理
filter可以被线程化,那么就不应该提供GenerateData,而是提供DynamicThreadedGenerateData()
1.5.2 ThreadedGenerateData()和DynamicThreadedGenerateData()
这两个函数其实作用是类似的,属于历史遗留问题。在1.3部分 5.X版本之后的变动中,提到了:
- 保留了向后兼容的
ThreadedGenerateData(Region, ThreadId)方法签名(这个函数的接口和名称没改过),以便已知线程数的filters进行调用。 - 即
ThreadedGenerateData和DynamicThreadedGenerateData的区别仅在于:前者已知线程数,后者需要动态确认线程数
可以看到,这两个函数的函数头,前者需要传入线程id参数,后者不需要。ThreadedGenerateData() template<typename TOutputImage> virtual void itk::ImageSource< TOutputImage >::ThreadedGenerateData (const OutputImageRegionType & region, ThreadIdType threadId ) DynamicThreadedGenerateData() template<typename TOutputImage> virtual void itk::ImageSource< TOutputImage >::DynamicThreadedGenerateData(const OutputImageRegionType & outputRegionForThread )
ThreadedGenerateData()的说明文档 和DynamicThreadedGenerateData的说明文档 ,内容基本一样,看其中一个就行
- 如果一个图像处理
filter可以作为多线程实施,那么这个filter需要提供ThreadedGenerateData()或者DynamicThreadedGenerateData()的实现。- 由这个图像
filter的父类对输出图像进行划分,产生多个线程,在每个线程中调用(Dynamic)ThreadedGenerateData()。 - 生成线程之前,会调用
BeforeThreadedGenerateData() - 当所有线程处理完成后,会调用
AfterThreadedGenerateData()方法
- 由这个图像
- 如果一个图像处理
filter不支持线程化,则这个filter需要实现GenerateData()方法而不是(Dynamic)ThreadedGenerateData()。- 如果实现了
GenerateData(),那么这个filter就会对输出数据进行分配 - 如果一个
filter实现的是(Dynamic)ThreadedGenerateData(),则输出的内存分配是由其父类自动进行,每个线程的(Dynamic)ThreadedGenerateData()方法只会生成outputThreadRegion参数明确的那部分输出,是无法对输出的其他部分内容进行写操作的(其他部分是其他线程负责的)
- 如果实现了
DynamicThreadedGenerateData()是没有threadId参数的ThreadedGenerateData()方法的一个新的变体,推荐优先使用这个方法,同时这个方法也是默认调用的方法。
- 作用是:根据当前点多处理器负载,将请求的区域划分为多个部分,来获得更好的负载均衡。
- 过去的非动态版本,即
ThreadedGenerateData()函数头包含threadId参数,需要被划分的数量是提前知道的,- 如果想使用
ThreadedGenerateData方法,需要在派生类的构造函数中通过调用this->DynamicMultiThreadingOff()来激活。 - 适用于以下场景:当多线程算法需要预分配一些数据(数据的大小取决于分块的数量,这里的分块,英语上表述是:pieces /chunks/work units,或者不太正确的描述成threads),、
- 只有
PlatformMultiThreader可以保证每个块在自己专属的线程中进行处理。Pool and TBB multi-threaders这两种会自己维护一个线程池(通常等于处理器核的数量)来处理块,可能会造成单个线程被用来处理多个块。
- 如果想使用
2. 支持多线程加速的Filter(开发者须知)
MultiThreaded Filters页面,这里记录的就是ITK已经实现好的支持多线程的Filter
2.1 基础内容
首先要知道哪些Filter是支持多线程的,并不是所有的Filter都支持多线程,如果不支持,调用
someFilter->SetNumberOfWorkUnits()
someFilter->SetMaximumNumberOfThreads()
其实是没有意义的。
上面说过 itk::ThresholdImageFilter中就有DynamicThreadedGenerateData方法,即支持多线程

- 可以看到这样的分类,点击
MultiThreaded Filters,跳转到MultiThreaded Filters页面,这里记录的就是ITK已经实现好的支持多线程的Filter - 常用的
itk::MultiScaleHessianBasedMeasureImageFilter,这个类的页面搜索thread就什么都搜不到,所以filter能否多线程其实与其实现的原理有关,对于这个filter来说,可能大部分都是串行操作??? - 常用的
itk::OtsuMultipleThresholdsImageFilter,是支持多线程的,itk::OtsuMultipleThresholdsImageFilter的文档。这个页面可以搜到GenerateData()函数,所以这其实是个父类
2.2 父类和子类示例
在GenerateData()函数的说明文档、ThreadedGenerateData()的说明文档 和DynamicThreadedGenerateData的说明文档 中,都有类似下面的内容。
Reimplemented in itk::MRIBiasFieldCorrectionFilter< TInputImage, TOutputImage, TMaskImage >, ....
但是不难发现,DynamicThreadedGenerateData的说明文档 中的内容,和多线程的filter列表:MultiThreaded Filters中并不完全一致。
以MultiThreaded Filters中的itk::XorImageFilter为例,
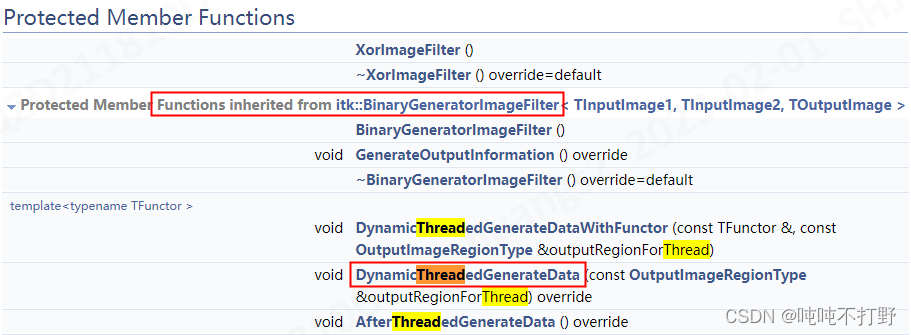
- itk::XorImageFilter的文档,文档中可以搜索到
DynamicThreadedGenerateData:
同时可以看到其类的层级结构
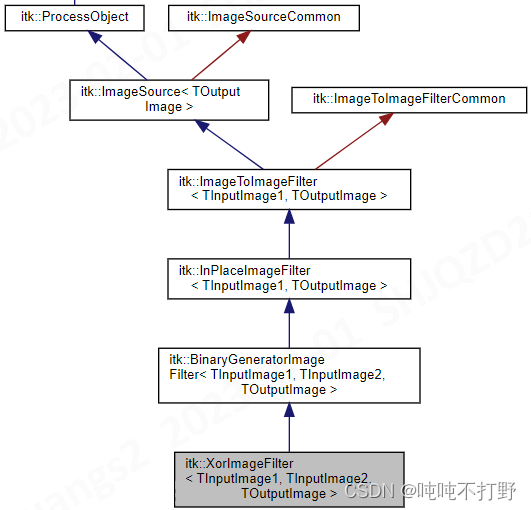
在itk::ProcessObject Class Reference中,可以搜到GenerateData (),也就是可以作为父类。
2.3 SetNumberOfWorkUnits和SetMaximumNumberOfThreads
参考github上的文档:Multithreading refactored可知:
-
Get/SetGlobalMaximumNumberOfThreads()和GlobalDefaultNumberOfThreads()现在位于itk::MultiThreaderBase中。
但是要注意,这几个函数仍然可以保留在itk::PlatformMultiThreader中itk::MultiThreaderBase的文档页面包含以下相关的函数:
# Public Member Functions virtual void SetMaximumNumberOfThreads (ThreadIdType numberOfThreads) virtual ThreadIdType GetMaximumNumberOfThreads () const virtual void SetNumberOfWorkUnits (ThreadIdType numberOfWorkUnits) virtual ThreadIdType GetNumberOfWorkUnits () const # Static Public Member Functions static void SetGlobalMaximumNumberOfThreads (ThreadIdType val) static ThreadIdType GetGlobalMaximumNumberOfThreads () static void SetGlobalDefaultNumberOfThreads (ThreadIdType val) static ThreadIdType GetGlobalDefaultNumberOfThreads () -
GetGlobalDefaultNumberOfThreadsByPlatform()方法已经从itk::ThreadPool移动到了itk::MultiThreaderBase中 -
对于图像filters和其他
itk::ProcessObject的派生类来说,SetNumberOfThreads已经改名为SetNumberOfWorkUnits.- 在itk::ProcessObject Class Reference,可以看到
SetNumberOfWorkUnits方法的说明:设置执行时的work units的数量(把输出分成几块,一般和处理器数量对应)
- 在itk::ProcessObject Class Reference,可以看到
-
对于
itk::MultiThreaderBase及其派生类,SetNumberOfThreads被分成了SetMaximumNumberOfThreads和SetNumberOfWorkUnits, 在itk::MultiThreaderBase,可以看到这两个方法的说明SetMaximumNumberOfThreads():设置要使用的线程数量,是个大于1的整数,调用的时候也要确认一下是不是可以接受这个设置。SetNumberOfWorkUnits():设置要创建的work units数量,是个大于1的整数,所以调用时要确认是否可以负荷这个数量
-
当
NumberOfWorkUnits大于线程数时,可以进行负载均衡。- 以前常见的
innerFilter->SetNumberOfThreads(1),现在可以改成innerFilter->SetNumberOfWorkUnits(1)。即:之前用线程(threads)操作的地方,现在都换成工作单元(work units)
- 以前常见的
-
如果要保证你的写的类(一般都是自己写
filter)和旧的代码兼容,即编译ITK的时候开启了ITKV4_COMPATIBILITY,则需要在filter的构造器里进行this->DynamicMultiThreadingOn() -
变量
ITK_MAX_THREADS和ITK_DEFAULT_THREAD_ID现在都位于itk:: namespace中,使用下面的方法可以向后兼容:using itk::ITK_MAX_THREADS; using itk::ITK_DEFAULT_THREAD_ID;
2.4 Demo
2.4.1 代码和实验
另外,比较关注和Hessian相关的内容
- 在
DynamicThreadedGenerateData的说明文档 中,搜到了itk::HessianToObjectnessMeasureImageFilter - 进一步,在
HessianToObjectnessMeasureImageFilter的页面中,确实搜到了DynamicThreadedGenerateData,说明这个filter是可以进行多线程的。
做了个简单的实验,其中关于线程和数据分块用到的代码如下:
#include <itkMultiThreaderBase.h>
itk::MultiThreaderBase::SetGlobalDefaultUseThreadPool(true);
itk::MultiThreaderBase::SetGlobalDefaultNumberOfThreads(32);
// 本机(Windows 10)8核,逻辑CPU 16,最多可以支持16个线程,所以这里设置32其实没有意义
// 不设置的话,默认就是本机支持的全部线程数量
yourFilter->SetNumberOfWorkUnits(1);
// 设置输入的图像要分成的块数,一般要和线程数对应,不设置的话,默认是4倍的线程数
// 可以先去搜一下 这个filter是不是继承了itk::ProcessObject,可以在 Public Member Functions inherited from itk::ProcessObject这里面找找,是不是有`SetNumberOfWorkUnits`这个函数
std::cout<<"Default GlobalDefaultNumberOfThreads is :"<<itk::MultiThreaderBase::GetGlobalDefaultNumberOfThreads()<<std::endl;
std::cout<<"objectnessFilter Work Units num: "<< objectnessFilter->GetNumberOfWorkUnits()<<std::endl;
时间统计:
16.0792879
""" 默认程序里不加上面这些设置代码 """
[14.6647972, 14.2902138, 15.678211, 14.7281133, 14.1761234, 14.4348833, 14.2341834, 14.5651432, 15.0468122, 16.6349639, 13.5964487, 13.5063107, 14.4932562, 13.9727078, 14.1482695, 13.6999142, 14.4058869, 15.0797446]
""" SetGlobalDefaultNumberOfThreads保持在16以上,SetNumberOfWorkUnits保持在8以上,结果都差不多,和不加这些设置的时间差不多"""
[19.2044184, 18.9394968]
""" SetGlobalDefaultNumberOfThreads保持16,SetNumberOfWorkUnits减小为4,时间明显多了3s"""
[33.6664439, 35.5176676]
"""SetGlobalDefaultNumberOfThreads保持16,SetNumberOfWorkUnits减小为1,时间增加就相当明显了"""
为了帮助调试程序,想知道当前程序真正调用的线程数量,可以看看:
- linux下查看程序的线程数量:Solved: Check thread count per process in Linux [5 Methods]
- windows下查看程序的线程数量:How to get process threads in Windows 10 C/C++ Source Code Included.
参考:
-
discourse:Threading in ITK
-
discourse:Multi-threader refactoring
-
discourse:More Threading issue,这个讨论的意思好像是说:ITK默认创建线程池的时候会使用所有的线程数
-
SphinxExamples/src/Core/Common/SetDefaultNumberOfThreads/Code.cxx
2.4.2 结论
和discourse:More Threading issue这个讨论的结果差不多:
- ITK在创建线程池时,会使用系统的最大线程数
- 同时,默认数据分块(work units)的数量是线程数×4
所以即便代码里什么都不加,其实ITK已经调用了当前系统默认的多线程了。
- 如果希望进一步提速,可能要去看看TBB等专门的库吧
3. 自己写的filter支持多线程
TBD
可以看看 ITK的BarCamp (可以理解为一种技术分享会)的文档记录:Write Multi-Threaded Code
参考:
- ITK官方文档:Threading
- ITK的BarCamp (可以理解为一种技术分享会)的文档记录:Write Multi-Threaded Code
- MITK中使用多线程ITK的一个ppt(pdf格式)文件:Multithreading with ITK
- ITK的论坛(讨论的还是4.3版本):Threading in ITK
- ITK的Guide book:https://itk.org/ItkSoftwareGuide.pdf,
Part II Architecture->SYSTEM OVERVIEW->3.2.7 Multi-Threading