1、Paddle模型字典形式存储
paddle保存模型参数是parambase格式,paddle.save对要保存的字典对象的值会进行解码,对于parambase格式会进行转换。如果我们保存的格式是{‘model’: model.state_dict()},字典的值是字典(相当于2级字典),该2级字典的值是模型参数(parambase格式),但是paddle.save只对字典的值进行解码,对于该2级字典的值不会进行解译,因此需要手动修改。
def model_rebuild(model_state_dict):
new_dict = {
}
for k, v in model_state_dict.items():
new_dict[k] = v.numpy()
return new_dict
ckpt = {
'acc': val_dict['acc_now'],
'loss': val_dict['loss_now'],
'epoch': val_dict['epoch_now'],
'model_state_dict': model_rebuild(model.state_dict()),
'optimizer_state_dict': optimizer.state_dict(),
}
paddle.save(ckpt, save_path)
2、动态图存储载入体系
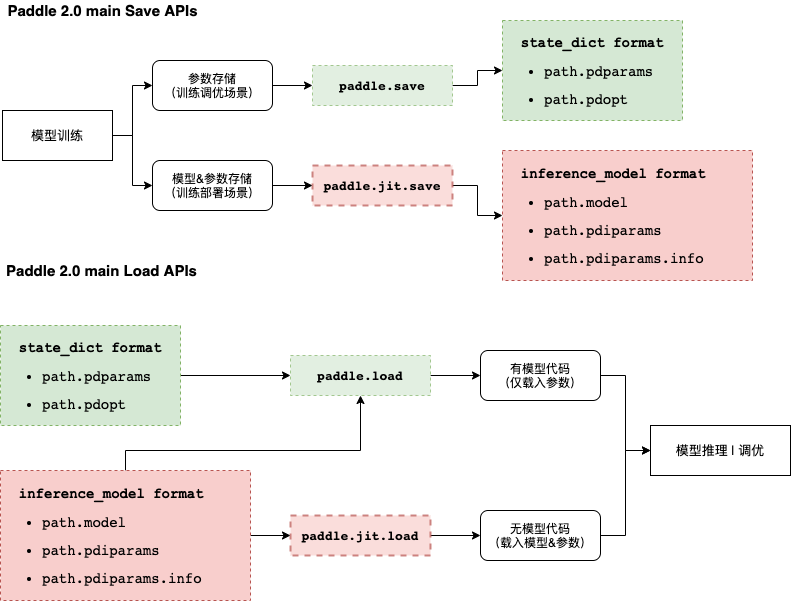
为提升框架使用体验,飞桨框架2.0将主推动态图模式,动态图模式下的存储载入接口包括:
paddle.save
paddle.load
paddle.jit.save
paddle.jit.load
save
参数存储时,先获取目标对象(Layer或者Optimzier)的state_dict,然后将state_dict存储至磁盘,示例如下(接前述示例):
paddle.save(layer.state_dict(), "linear_net.pdparams")
paddle.save(adam.state_dict(), "adam.pdopt")
load
参数载入时,先从磁盘载入保存的state_dict,然后通过set_state_dict方法配置到目标对象中,示例如下(接前述示例):
layer_state_dict = paddle.load("linear_net.pdparams")
opt_state_dict = paddle.load("adam.pdopt")
layer.set_state_dict(layer_state_dict)
adam.set_state_dict(opt_state_dict)
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
# save
paddle.save(layer.state_dict(), "linear_net.pdparams")
paddle.save(adam.state_dict(), "adam.pdopt")
# load
layer_state_dict = paddle.load("linear_net.pdparams")
opt_state_dict = paddle.load("adam.pdopt")
layer.set_state_dict(layer_state_dict)
adam.set_state_dict(opt_state_dict)
动态图训练 + 模型&参数存储
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
def forward(self, x):
return self._linear(x)
layer = LinearNet()
# save
path = "example.dy_model/linear"
paddle.jit.save(
layer=layer,
path=path,
input_spec=[InputSpec(shape=[None, 784], dtype='float32')])
动转静训练 + 模型&参数存储
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
@paddle.jit.to_static
def forward(self, x):
return self._linear(x)
layer = LinearNet()
# save
path = "example.model/linear"
paddle.jit.save(layer, path)
3、模型的载入
import paddle
import paddle.nn as nn
IMAGE_SIZE = 784
CLASS_NUM = 10
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
@paddle.jit.to_static
def forward(self, x):
return self._linear(x)
# create network
layer = LinearNet()
# load
path = "example.model/linear"
state_dict = paddle.load(path)
# inference
layer.set_state_dict(state_dict, use_structured_name=False)
layer.eval()
x = paddle.randn([1, IMAGE_SIZE], 'float32')
pred = layer(x)
4、ONNX的转化
动态图导出ONNX协议
安装pip install paddle2onnx onnx onnxruntime
import paddle
from paddle import nn
from paddle.static import InputSpec
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(784, 10)
def forward(self, x):
return self._linear(x)
# export to ONNX
layer = LinearNet()
save_path = 'onnx.save/linear_net'
x_spec = InputSpec([None, 784], 'float32', 'x')
paddle.onnx.export(layer, save_path, input_spec=[x_spec])
ONNX模型的验证
# check by ONNX
import onnx
onnx_file = save_path + '.onnx'
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)
print('The model is checked!')
ONNXRuntime推理
import numpy as np
import onnxruntime
x = np.random.random((2, 784)).astype('float32')
# predict by ONNX Runtime
ort_sess = onnxruntime.InferenceSession(onnx_file)
ort_inputs = {
ort_sess.get_inputs()[0].name: x}
ort_outs = ort_sess.run(None, ort_inputs)
print("Exported model has been predicted by ONNXRuntime!")
# predict by Paddle
layer.eval()
paddle_outs = layer(x)
# compare ONNX Runtime and Paddle results
np.testing.assert_allclose(ort_outs[0], paddle_outs.numpy(), rtol=1.0, atol=1e-05)
print("The difference of results between ONNXRuntime and Paddle looks good!")
6、动态图与静态图
动态图有诸多优点,包括易用的接口,Python风格的编程体验,友好的debug交互机制等。 在动态图模式下,代码是按照我们编写的顺序依次执行。这种机制更符合Python程序员的习 惯,可以很方便地将大脑中的想法快速地转化为实际代码,也更容易调试。但在性能方面, Python执行开销较大,与C++有一定差距。因此在工业界的许多部署场景中(如大型推荐系统、移动端)都倾向于直接使用C++来提速。
相比动态图,静态图在部署方面更具有性能的优势。静态图程序在编译执行时,先搭建模型 的神经网络结构,然后再对神经网络执行计算操作。预先搭建好的神经网络可以脱离Python依赖,在C++端被重新解析执行,而且拥有整体网络结构也能进行一些网络结构的优化。
动态图代码更易编写和debug,但在部署性能上,静态图更具优势。