NER标注----BILSTM模型训练招投标实体标注模型
)
NER标注----BILSTM模型训练招投标实体标注模型
前言
上文中讲到如何使用spaCy来做词性标注,这个功能非常强大。现在来介绍另一个有 趣的组件:NER标注。并使用BILSTM模型来训练一个招投标实体标注模型。
`提示:以下是本篇文章正文内容
一、NER标注简介
NER标注的中文名为命名实体识别,与词性标注一样是自然语言处理的技术基础之一。
NER标注的作用:
1)显而易见最主要的是通过模型可以识别出文本中需要的实体。
2)可以推导出实体之间的关系;例如,Rome is the capital of Italy,可以根据实体识别可以判断出Rome是意大利的城市而不是R&B艺术家,这项工作叫实体消岐(NED);
NED的使用场景可以在医学研究中消除词语歧义鉴定基因和基因产物,写作风格分析等。
尽管spaCy预训练好的模型进行实体标注较容易,但基于应用场景的不同可以训练一个更符合应用的
NER标注器。
二、从头开始训练一个NER标注器
在数据准备阶段需要采用合适的方法对数据进行标注,标注的方法为IBO表示法和扩展BILOU系统。

在本次的项目中,我们采用的是和词性标注相同的模型
采用bilstm+CRF;
二、使用步骤
1.引入库
代码如下(示例):
import pandas as pd
import numpy as np
import keras
import re
import warnings
from keras.utils import to_categorical #转换为one_hot编码
from sklearn.model_selection import train_test_split
from keras.layers import Dense, Embedding, LSTM, TimeDistributed, Input, Bidirectional, Dropout
from keras.models import Model
warnings.filterwarnings('ignore')
2.数据处理
要将数据变成这种形式

代码如下:
doc = [] #单个汉字
f = open ('home_work.txt','r',encoding='utf8')
for line in f.readlines():
doc.append([text for text in line])
pos = [] #标签
for i in range(len(doc)):
pos.append(['O']*len(doc[i]))
train_label = pd.read_csv('label.txt',error_bad_lines=True, sep=' ',names=["中标", "招标"])
train_label.head(10)
train_data = pd.read_csv('home_work.txt',error_bad_lines=True,names=["文本"])
train_data.head()
train_data = np.array(train_data).tolist() #pd转list
TRAIN_DATA = []
test = []
test1 = []
for i in range(len(train_label)):
for j in range(len(train_data)):
if i==j:
out = re.finditer(str(train_label.iloc[j][0]),str(train_data[i])) #中标
for k in out:
shuzi = list(k.span())
pos[i][shuzi[0]-2] = 'B_bidder'
pos [i][shuzi[0]-1:shuzi[1]-2] = (shuzi[1]- 1 - (shuzi[0]+1))*['I_bidder']
pos[i][shuzi[1]-3] = 'L_bidder'
out1 = re.finditer(str(train_label.iloc[j][1]),str(train_data[i])) #招标
for k1 in out1:
shuzi = list(k1.span())
# print(data_2[i][shuzi[0]+1:shuzi[1]-1])
pos[i][shuzi[0]-2] = 'B_buyyer'
pos[i][shuzi[0]-1:shuzi[1]-2] = (shuzi[1]- 1 - (shuzi[0]+1))*['I_buyyer']
pos[i][shuzi[1]-3] = 'L_buyyer


将数据先处理成这种形式。
data_clean = []
df = []
for z in range(len(doc)):
for i in range(len(doc[z])):
for j in range(len(pos[z])):
if i==j:
df.append(dict.fromkeys(doc[z][i],pos[z][j]))
data_clean.append(df)
df = []

这种形式就可以了。
3.模型训练
#####建造词库和标签库相当于词列表和标签列表去重
def make_packages(ex_list , num):
result = []
for i in ex_list:
result += i
result = list(set(result))
result_dict = {
}
for i in range(len(result)):
result_dict[result[i]] = i + num
return result_dict
tag = make_packages(pos , 0) #词性标签
word_packages = make_packages(doc , 0) #词的标签
def write_dict(ex_dict,path):
vocab = open(path,"w",encoding="utf8")
for part_index in ex_dict.keys():
values = ex_dict[part_index]
vocab.write(part_index + " : " +str(values)+"\n")
vocab.close()
write_dict(tag,"./model/tag.txt") #标签库
write_dict(word_packages,"./model/word_packages.txt") #词库
def train_index(doc,word_packages): #数据转换,将文本数据转换成index
doc_index = []
for text in doc:
text_index = []
for word in text:
text_index.append(word_packages[word])
doc_index.append(text_index)
return doc_index
doc_index = train_index(doc,word_packages)
pos_index = train_index(pos,tag)
max_len = max([len(i) for i in doc_index])#计算最长的,方便变为矩阵
print(max_len)
import keras
import numpy as np
#使维度相等
input_array = np.array(doc_index) ####不同纬度但是会进行转换
# pad_sequence()函数将序列转化为经过填充以后得到的一个长度相同新的序列。
X = keras.preprocessing.sequence.pad_sequences(input_array,maxlen=max_len,padding='post') ###paddle
output_array = np.array(pos_index)
y = keras.preprocessing.sequence.pad_sequences(output_array,maxlen=max_len,padding='post')
#########y标签向量化
from keras.utils import to_categorical #转换为one_hot编码
y_onehot = to_categorical(y)
#划分训练集测试集
from sklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test = train_test_split(X,y_onehot,test_size=0.2, random_state=0)
之后就是模型训练与保存了:
from keras.layers import Dense, Embedding, LSTM, TimeDistributed, Input, Bidirectional, Dropout
from keras.models import Model
def create_model(maxlen, chars, word_size, output_dim ,infer=False):
sequence = Input(shape=(maxlen,), dtype='int32')
embedded = Embedding(len(chars) + 1, word_size, input_length=maxlen, mask_zero=True)(sequence)
"""
词嵌入层就是将文字转换为一串数字,可以理解为词在神经网络中的向量表示。
Embedding:词嵌入层通常放在模型的第一层,主要的作用是将one-hot向量纬度缩减,便于模型纬度变小
input_dim: 输入参数为词的索引
output_dim: 输出词向量的维度
input_length:序列长度
"""
blstm = Bidirectional(LSTM(64, return_sequences=True), merge_mode='concat')(embedded)
"""
merge_mode:向前向后的拼接方式,可选的参数有{‘sum’,‘mul’,‘concat’,‘ave’,None},默认concat
"""
output = TimeDistributed(Dense(output_dim , activation='softmax'))(blstm)
model = Model(inputs =sequence, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
def train_bilstm():
"""
train bilistm
:return:
"""
print("start train bilstm")
model = create_model(max_len, word_packages, 64, 7)
model.summary()
history = model.fit(X_train, y_train, batch_size=10,epochs=10, verbose=1)
model.save('model/model.h5')
train_bilstm()
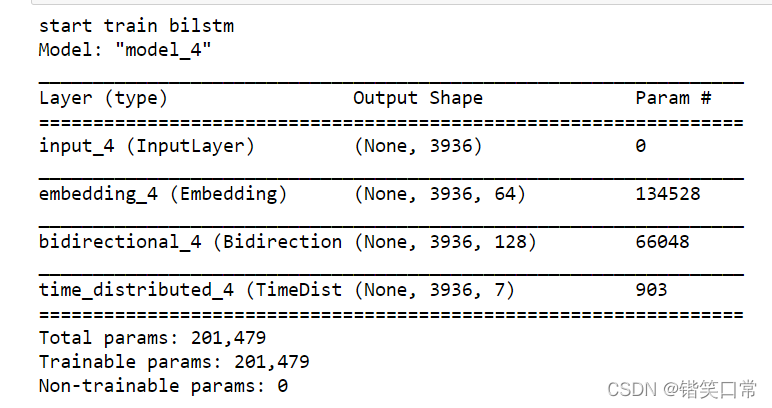

可见模型效果还是不错的。