自然语言处理spaCy--训练一个词性标注模型
一、什么是词性标注?
词性标注的全称为Part-Of-Speech tagging。顾名思
义,词性标注是为输入文本中的单词 标注对应词性的
过程。
**
词性标注的作用:
**
(1)预测接下来一个词的词性,为翻译提供帮助;
(2)为句法分析、信息抽取等工作打下基础。
(3)为特殊的场景提供数据处理的能力。
在spaCy中,词性标注模型可以根据自己的数
据自定义一个词性标注的模型,采用的方法是神经
网络的模型,模型大致架构是:
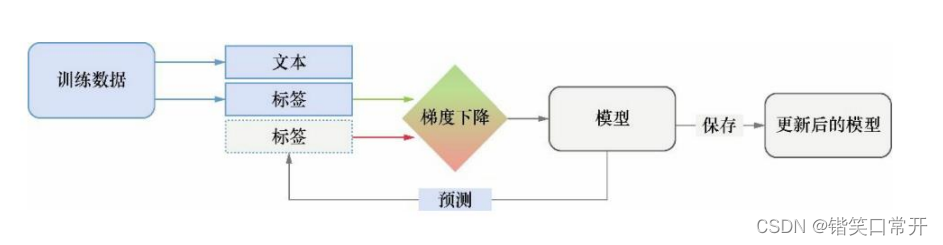
二、从头开始训练一个词性标注模型.
1.引入库
代码如下(示例):
from __future__ import unicode_literals, print_function
import plac
import random
from pathlib import Path
import spacy
from spacy.training import Example
from spacy.tokens import Doc
2.使用百度LAC模块进行词性标注
代码如下(示例):
from LAC import LAC
text = []
with open('train_text.txt',encoding='utf8') as f:
for i in f.readlines():
text.append(i.strip('\u200b\u200b\u200b\n'))
random.seed(123)
lac = LAC(mode='lac')
train = random.sample(text, 20)#随机取20条新闻
data = lac.run(train)
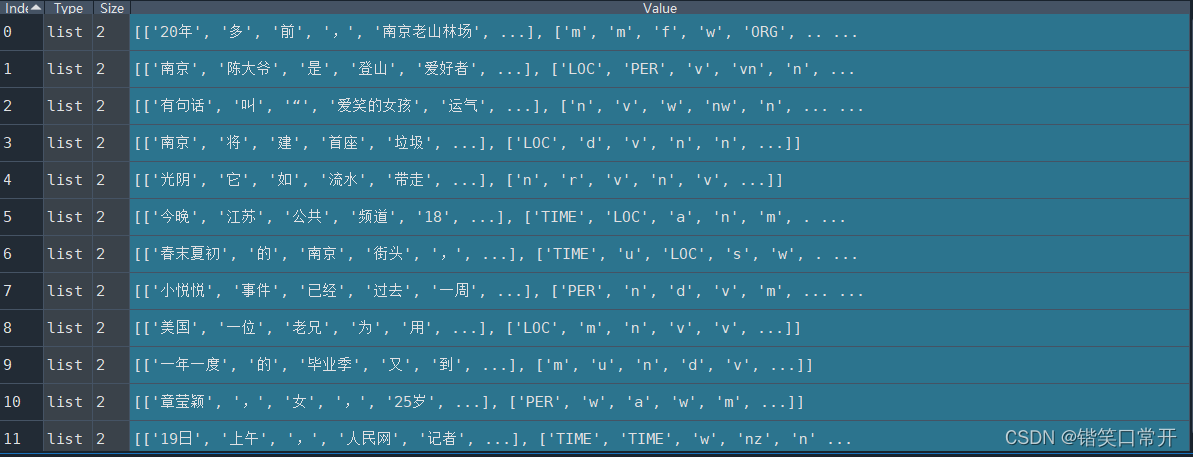

此处通过LAC已经进行了词性标注,方便后面把词性名称映射到通用词性标注集上。
3.模型训练
设置语种、输出目录以及训练迭代次数
@plac.annotations(
lang=("ISO Code of language to use", "option", "l", str),
output_dir=("Optional output directory", "option", "o", Path),
n_iter=("Number of training iterations", "option", "n", int))
模型训练:
def main(lang='zh', output_dir="C:/model/", n_iter=500):
nlp = spacy.blank(lang) # 创建中文模型
tagger = nlp.add_pipe('tagger')
print("names2:",nlp.pipe_names)
# 添加标注器
for tag, values in TAG_MAP.items():
print("tag:",tag)
tagger.add_label(tag)
optimizer = nlp.begin_training() # 模型初始化
for i in range(n_iter):
random.shuffle(TRAIN_DATA)
losses = {
}
for text, annotations in TRAIN_DATA:
example = Example.from_dict(Doc(nlp.vocab, words=text, spaces=[""] * len(text)), annotations)
nlp.update([example], sgd=optimizer, losses=losses)
print("i:",str(i) + str(losses))
放入测试集:本文测试集直接从训练集中抽取5条新闻聚合。
test_text = random.sample(train, 5)#随机取20条新闻
test_text = u','.join(test_text)
doc = nlp(test_text)
print("doc:",[t.text for t in doc])
print('Test_Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
保存模型:
# 将模型保存到输出目录
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
# 保存模型
print("Loading from", output_dir)
nlp2 = spacy.load(output_dir)
doc = nlp2(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
结果:
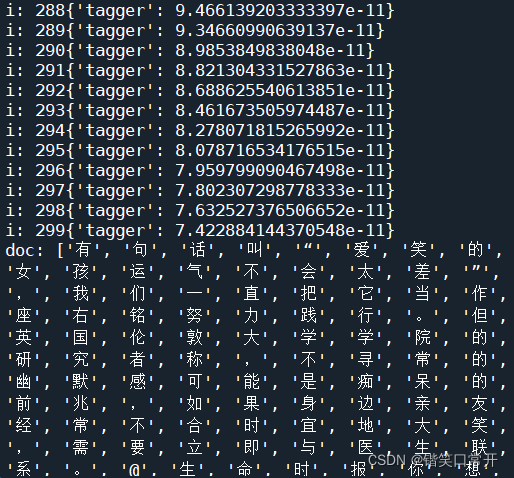
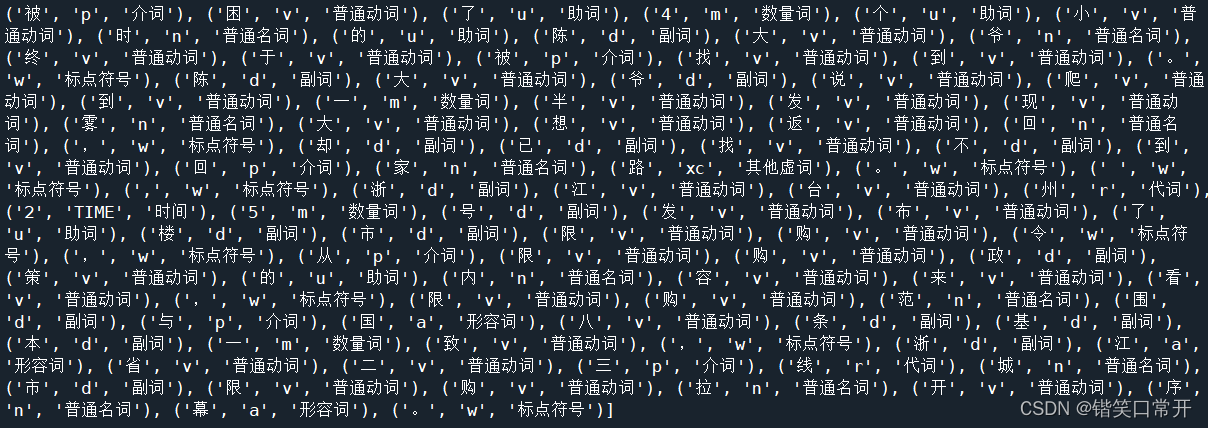
完整代码
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 1 18:10:18 2022
@author: He Zekai
"""
from __future__ import unicode_literals, print_function
import plac
import random
from pathlib import Path
import spacy
from spacy.training import Example
from spacy.tokens import Doc
TAG_MAP = {
'n':{
'pos':'普通名词'},
'f':{
'pos':'方位名词'},
's':{
'pos':'处所名词'},
'nw':{
'pos':'作品名'},
'nz':{
'pos':'其他专名'},
'v':{
'pos':'普通动词'},
'vd':{
'pos':'动副词'},
'vn':{
'pos':'名动词'},
'a':{
'pos':'形容词'},
'ad':{
'pos':'副形词'},
'an':{
'pos':'名形词'},
'd':{
'pos':'副词'},
'm':{
'pos':'数量词'},
'q':{
'pos':'量词'},
'r':{
'pos':'代词'},
'p':{
'pos':'介词'},
'c':{
'pos':'连词'},
'u':{
'pos':'助词'},
'xc':{
'pos':'其他虚词'},
'w':{
'pos':'标点符号'},
'PER':{
'pos':'人名'},
'LOC':{
'pos':'地名'},
'ORG':{
'pos':'机构名'},
'TIME':{
'pos':'时间'}
}
import random
from LAC import LAC
import pandas as pd
text = []
with open('train_text.txt',encoding='utf8') as f:
for i in f.readlines():
text.append(i.strip('\u200b\u200b\u200b\n'))
random.seed(123)
lac = LAC(mode='lac')
train = random.sample(text, 20)#随机取20条新闻
data = lac.run(train)
TRAIN_DATA = []
for i in range(len(data)):
txt = (data[i][0],{
'tags':data[i][1]})
TRAIN_DATA.append(txt)
TRAIN_DATA
@plac.annotations(
lang=("ISO Code of language to use", "option", "l", str),
output_dir=("Optional output directory", "option", "o", Path),
n_iter=("Number of training iterations", "option", "n", int))
def main(lang='zh', output_dir="C:/Users/11752/Desktop/大三下/自然语言处理/作业5--自然语言处理作业zip/model/", n_iter=300):
nlp = spacy.blank(lang)
tagger = nlp.add_pipe('tagger')
print("names2:",nlp.pipe_names)
#添加标注器
for tag, values in TAG_MAP.items():
print("tag:",tag)
tagger.add_label(tag)
optimizer = nlp.begin_training() #模型初始化
for i in range(n_iter):
random.shuffle(TRAIN_DATA)
losses = {
}
for text, annotations in TRAIN_DATA:
example = Example.from_dict(Doc(nlp.vocab, words=text, spaces=[""] * len(text)), annotations)
nlp.update([example], sgd=optimizer, losses=losses)
print("i:",str(i) + str(losses))
test_text = random.sample(train, 5)#随机取20条新闻
test_text = u','.join(test_text)
doc = nlp(test_text)
print("doc:",[t.text for t in doc])
print('Test_Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
# 将模型保存到输出目录
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
# 保存模型
print("Loading from", output_dir)
nlp2 = spacy.load(output_dir)
doc = nlp2(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
if __name__ == '__main__':
plac.call(main)
总结
以上就是基于spacy从头训练中文模型的内容,本文仅仅简单介绍使用,根据结果可看出并没有基于中文词语进行切分,这个不足之处,需要改进。