
背景: 企业业务运营的平稳,常常要依靠智能运维在后方保驾护航。熟悉运维的肯定都知道,在智能运维中有一环是通过监控指标来判断系统、云、业务应用、网络设备等运行的是否健康,以便及时排障维稳后台。在指标异常检测中,其阈值设定的合理性决定了故障发现的效率。当下,传统的维护模式过分依赖规则,而纯算法的模式又有门槛高、场景受限等问题。
一、算法与传统规则的融合
在擎创看来,指标监控要想实现实时适应动态业务的变化,且能精准发现并解决故障的效果,则需要在指标监测体系中将算法和传统规则相结合,动静并举才能轻松解决运维过程中的顽疾。擎创夏洛克指标解析中心独创以算法调节算法的能力,实现自动调参、自动匹配模型、自动优化阈值、智能告警等功能,助力客户高效完成智能运维工作,赋予业务运营更好的支撑。
在指标异常检测方面深入探索,我们通过总结落地案例总结出了以下六个实践要素。
1.选对算法
2.确定异常方向
3.考虑不同时段的检测差异
4.优化模型参数
5.优化告警阈值
6.长期关注数据质量
这期我们将通过几个故事场景对前面3点进行分享
使用人员:张三( 某企业应用运维人员 / 平台(云)运维人员 / 基础设施运维人员 )
实践重点:选对算法、确定异常方向、考虑不同时段的检测差异
使用产品:擎创夏洛克指标解析中心

落地场景一: · 选对算法 ·
(涵盖周期性算法 / 非周期性算法 / 综合特征算法)
近日,超级网银要上架一个全新的业务,张三在设定指标检测算法的时候,通过指标解析中心测算业务模型,依据结果得到业务波动呈现固定的规律性,系统自动选择周期性算法进行后续指标监测。在业务运行期间,如果出现了异常问题,在监测图表中很容易体现,运维人员能够快速找到故障根源并进行排障。
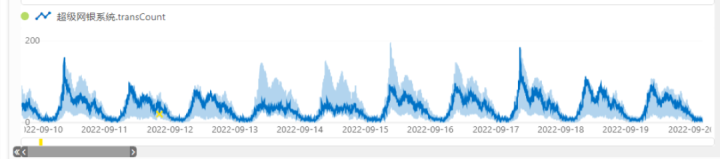
企业IT运维会随着业务变化而随时变动,每一项业务都有自己所属的模型,擎创指标解析中心产品能够根据传统规则、经验对业务进行模型测算,判断业务规律是周期性、非周期性还是二者兼具,并以此结果智能选择相应检测算法,使之高度契合,更易定障排障。
落地场景二: · 确定异常方向 ·
(上基带 / 下基带 / both)
业务运行平稳的状态下,指标检测到的业务指标往往也比较平稳,仍以超级网银为例,张三当值的这天,突然出现大量用户延迟高的反馈,指标解析中心在此之前就选用了符合上基带监测模型的算法,因此快速且精准发现了问题,张三迅速联系同事进行处理,将业务影响降到了最低。
所以说业务指标检测具有一定的方向性,比如延迟一类的异常,只需要上基带模型检测算法;业务成交量的异常,只需要下基带模型检测算法;而例如交易量指标则可能适合两者并用的方式。
落地场景三:
①· 考虑不同时段的检测差异 ·
(设定运维日历 )
张三在使用指标解析中心的时候,根据业务的某些特性从中挑选出两类特别事件:重复事件(比如双休日/下班时间)、单次事件(比如变更),将这两种事件设定在产品的运维日历中,只要在此时段内,系统会自动选择合适的算法进行监测或不监测,避免误告漏告。
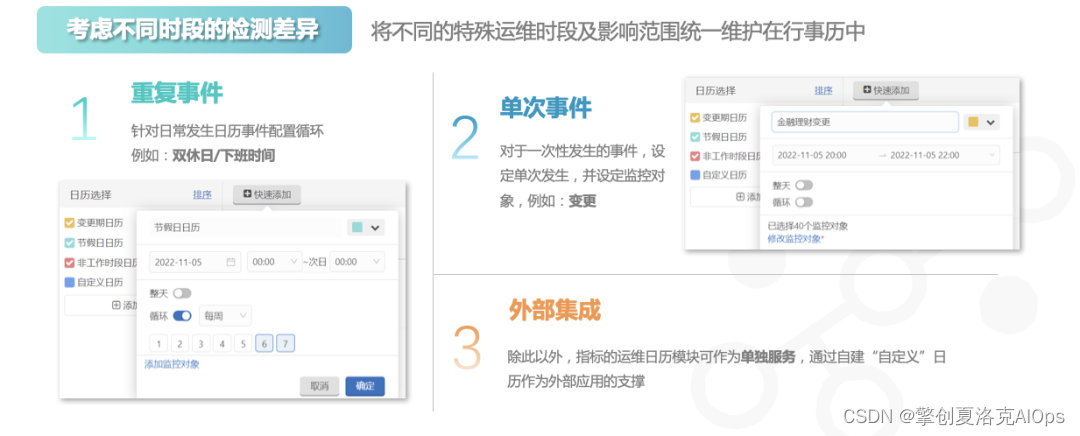
另外,指标解析中心的运维日历能够作为单独模块进行服务,通过自建的“自定义”日历作为外部应用的支撑。简而言之,就是可以帮助其他平台、工具的使用提供时间、事件规划,将格式形式统一。
②· 不同时段匹配不同的算法策略 ·
(匹配运维日历)
上面提到设定运维日历,将不同的特殊运维时段及影响范围,统一维护在行事历中,那么到了特殊时段又是如何运作呢?请看下图。
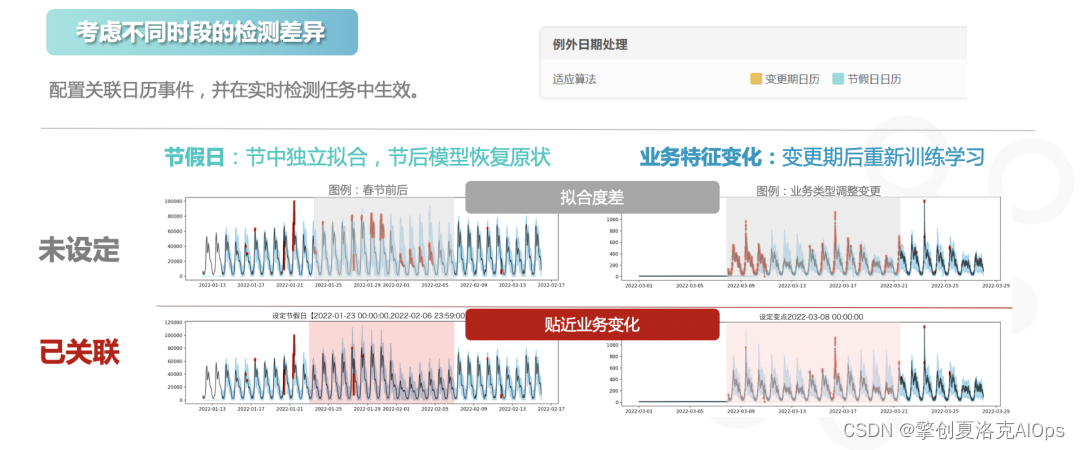
张三在节假日前后看到,指标解析中心通过对日历的匹配,为当前时段设定了独立的拟合算法,节后又恢复了往常的模型,这期间出现的告警数量明显减少,告警准确度提高20%。
同样,系统在面对某一次业务变更的时候进行了算法的调整,变更后重置历史并重新开始训练。这样既贴合了实际业务的变化,也能避免无效学习,使得变更后的检测工作能更精准地判断异常与否。
关于指标异常检测的分享本期就到这儿了,下期我们将接着分享余下的三点,感兴趣的可以先关注收藏,下期我们精彩继续~

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司致力于协助企业客户提升对运维数据的洞见能力,优化运维效率,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

更多运维思路与案例持续更新中,敬请期待
随手点关注,更新不迷路