首先我们先来看下网上最经典的解释
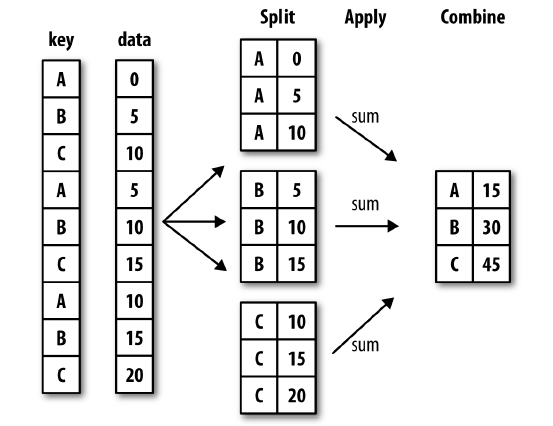
即对不同列进行在分类,标准是 先拆分 在组合(如果有操作比如sum则可以进行操作)
什么意思呢 。就是我们读取文件不是有很多列吗,如果我按列就行分类,那么先把选取列一样的挑出来
然后在进行操作。具体的看下下面一个例子
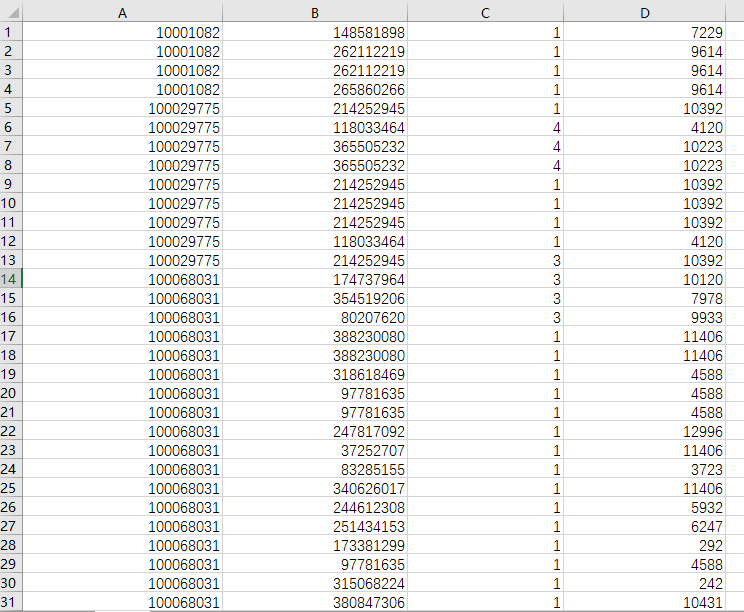
这里我们的列名省略了 其实是df_part_1.columns = ['user_id','item_id','behavior_type','item_category']
import pandas as pd
import numpy as np
path_df_part_1 = r'C:\Users\yang\Desktop\ceshi.csv' #时间11.22-11.27的数据
path_df = open(path_df_part_1, 'r')
try:
df_part_1 = pd.read_csv(path_df, index_col = False, parse_dates = [0])
df_part_1.columns = ['user_id','item_id','behavior_type','item_category']
finally:
path_df.close()
df_part_1['cumcount'] = df_part_1.groupby(['user_id', 'behavior_type']).cumcount()#
print(df_part_1)
这里我们选取了groupby(['user_id', 'behavior_type']
可能刚开始不懂啥意思 基本意思就是 我用这两列进行分类 树结构看过吗 这两个列就相当于树的节点 其他的列
通过这个节点再进行分支。还是不懂?没关系 来个最直白的意思 就是所有数据 只要['user_id', 'behavior_type']
这两个取值一样 就是一个小类 。如果这两个取值不一样则就不是一类 。可能单纯的说搞不懂,我们加了一个cumcount辅助理解
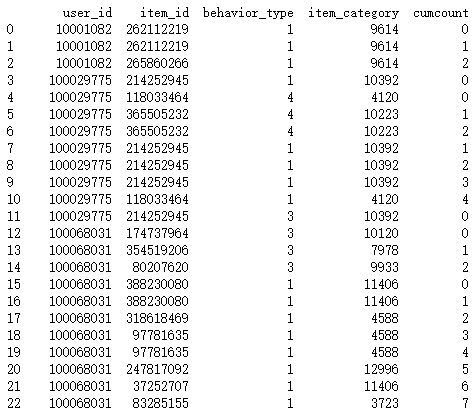
上述程序运行结果为上面所示 ,那么我们解释下 什么叫
只要['user_id', 'behavior_type'] 这两个取值一样 就是一个小类
我们看上图0-3行 选取的groupby没有变 即['user_id', 'behavior_type'] 没变 则一直计数
而3和4(横行标签)相比'behavior_type' 由1变成4了 则我们刚开始说的 只要有一个变就不是一类了 所以重新计数
现在懂了吧 最基本的就是可以选取我们需要的列进行分类 比如我们统计所有用户不同操作类型进行了多少次
首先我们必须先把同样的用户分在一起 然后再把相同操作分在一起 所以我们选取groupby(['user_id', 'behavior_type']
进行分类 ,而不是在很大的数据中茫茫没有思路