引言
- 背景
信息时代的来临使得企业营销焦点从产品转向了客户,客户的管理关系成为企业的核心问题。客户的关系管理问题是客户分群。通过客户分群,进而区分无价值客户和高价值客户。高价值客户代表他们的消费会给企业带来利益最大。企业需要针对不同类别的客户进行定制个性化服务方案,采取不同的营销策略,实现企业利润最大化。准确的客户分群结果是企业优化营销资源分配的重要依据,客户分群是重要的解决问题之一。
一、RFM模型介绍
R(Recency):指的是最近一次消费时间与截止时间的间隔。通常情况下,最近一次消费时间与截 止时间的间隔越短,客户对即时提供的商品或是服务也最有可能感兴趣。这也是为什么消费时间间隔为0-6个月的顾客收到的沟通信息多于一年以上的顾客。
F(Frequency):指顾客在某段时间内所消费的次数。消费频率越高的顾客,也是满意度越高的顾客,其忠诚度越高,顾客价值也就越大。增加顾客购买的次数意味着从竞争对手处抢得市场占有率,赚取营业额。商家需要做的,是通过各种营销方式去不断地刺激顾客消费,提高他们的消费频率,提升店铺的复购率。
M(Monetary):指顾客在某段时间内所消费的金额。消费金额越大的顾客,他们的消费能力自然也就越大,这就是所谓"20%的顾客贡献了80%的销售额"的二八法则。而这批顾客也必然是商家在进行营销活动时需要特别照顾的群体,尤其是在商家前期资源不足的时候。
在RFM模型理论中,最近一次消费时间与截止时间的间隔、消费频率、消费金额是测算客户价值最重要的特征。这3个特征对营销活动具有十分重要的意义。其中,最近一次消费时间与截止时间的间隔是最有力的特征。
RFM模型包括3个特征,R值越大,说明该类客户最近都没有来店消费,。R特征数值变大需要企业管理人员引起重视,说明该类客户可能流失,对企业造成损失。消费频率F很高,说明客户很活跃,经常到商家店里消费。消费金额M值很高,说明该类客户具备一定的消费能力,为店里贡献了很多的营业额。
二、航空公司客户分析实例
在RFM模型中,消费金额表示在一段时间内客户购买该企业产品金额总的和。由于航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的,比如一位购买长航线、低等级舱位票的旅客与一位购买短航线、高等级舱位票的旅客相比,后者对于航空公司而言价值可能更高。因此这个特征并不适合用于航空公司的客户价值分析,取消这个特征。
所以我们这一选取以下作为特征之后进行聚类分析:


(一)python代码实现:
data_select=new_data[["FFP_DATE","LOAD_TIME","FLIGHT_COUNT","LAST_TO_END","avg_discount","SEG_KM_SUM"]]
L=pd.to_datetime(data_select["LOAD_TIME"])-pd.to_datetime(data_select["FFP_DATE"])
L=L.astype('str').str.split().str[0]
L=L.astype('int')/30日期进行相减,然后进行分割取第一个元素,结果如图:


data_features=pd.concat([L,data_select.iloc[:,2:]],axis=1)
data_features.columns=["L","FLIGHT_COUNT","LAST_TO_END","avg_discount","SEG_KM_SUM"]
这样我们就可以得到重要的特征值啦!!为啥选取这个作为特征值了呢?这是根据社会背景分析达!
我们在通过聚类分析,根据这些重要特征进行聚类分析,代码如下(KMEANS聚类)
from sklearn.preprocessing import StandardScaler
data1=StandardScaler().fit_transform(data_features)#标准化
print('标准化后LRFMC五个特征为:\n',data1[:5,:])
from sklearn.cluster import KMeans
from sklearn import metrics
group_number=5
kmeans_model=KMeans(n_clusters = group_number,random_state=123)
kmeans_model.fit(data1)
kmeans_model.cluster_centers_ 查看聚类中心,结果如图:

kmeans_model.labels_查看标签,结果如图:
![]()
pgjg=metrics.silhouette_score(data1, kmeans_model.labels_, metric='euclidean')
print('聚类结果的轮廓系数=',pgjg)查看轮廓系数,结果如图:
![]()
得到如下客户群:
#直方图形式显示聚类后各组聚类中心的值
%matplotlib inline
import matplotlib.pyplot as plt
cluster_center.drop(['客户数'],axis=1,inplace=True)
my_sort=cluster_center.rank(ascending=True)
airline_features.drop(['cluster'],axis=1,inplace=True)
my_sort.columns=list(airline_features.columns)
my_sort["cluster"]=np.array(range(group_number))+1
data_group=my_sort.groupby("cluster").mean()
data_group.plot(kind="bar",figsize=(13,6),ylim=(0,7.5))
plt.show()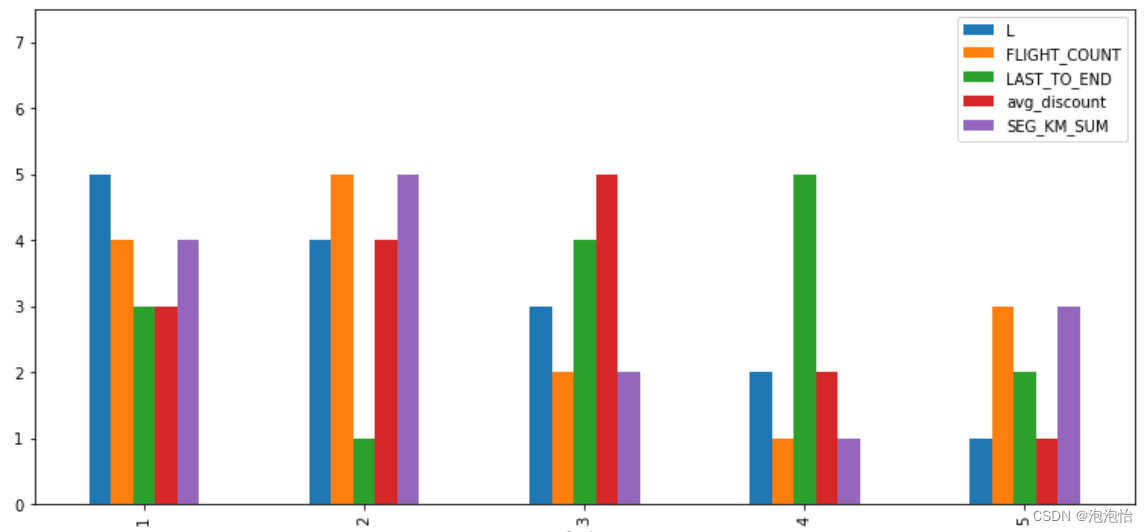
客户群1:飞行次数第4,飞行公里数第4,飞行时间间隔第2,平均折扣系数第1,会员时长第3。-----一般客户
客户群2:飞行次数第5,飞行公里数第5,飞行时间间隔第1,平均折扣系数第4,会员时长第4。-----低价值客户
客户群3:飞行次数第1,飞行公里数第1,飞行时间间隔第5,平均折扣系数第2,会员时长第2。-----重要保持客户
客户群4:飞行次数第3,飞行公里数第3,飞行时间间隔第4,平均折扣系数第5,会员时长第5。-----重要发展客户
客户群5:飞行次数第2,飞行公里数第2,飞行时间间隔第3,平均折扣系数第3,会员时长第1。-----重要挽留客户