参考的几篇完整的sqlalchemy文档:
https://www.osgeo.cn/sqlalchemy/core/internals.html?highlight=has_table#sqlalchemy.engine.Dialect.has_table
https://www.wenjiangs.com/doc/sqlalchemy-core-internals#sqlalchemy.engine.Dialect
mysqlalchemy 的核心内构件的方法:
1.4 新版功能.
method sqlalchemy.engine.Dialect.has_sequence(connection, sequence_name, schema=None, **kw)
检查数据库中是否存在特定序列。
给出了一个 Connection 对象和字符串 sequence_name ,如果给定序列存在于数据库中,则返回true,否则返回false。
method sqlalchemy.engine.Dialect.has_table(connection, table_name, schema=None, **kw)
检查数据库中是否存在特定表。
给出了一个 Connection 对象和字符串 table_name ,如果给定的表(可能在指定的 schema )存在于数据库中,否则为false。
另:
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
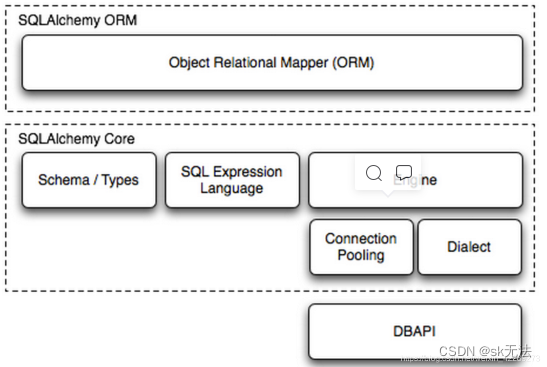
下面参考文章
http://t.zoukankan.com/yasmi-p-5587852.html
1.Dialect:英文含义为方言,这边指模块对不同的数据库的连接以及操作的实现。
其实可以理解成不同的数据库语言,如mysql,sqlserver,Oracle等,不同的数据库语言,彼此的语法规则都有一定区别。
2.engine:引擎,代表到数据库的一个连接,数据库自身有一个连接最大限制,不能超过这个限制。这里引擎可以连接多个数据。具体连接实现使用dialect方案
数据库链接:连接代表从用户进程到数据库实例进程之间的一个通信信道(进程间通信,网络间通信),因此建立连接需要占用资源内存,花销很大。
数据库连接池:另外建立数据库连接耗时,不能每次操作都建立连接。因此连接可以复用,通过使用数据库连接池;使用数据库时候,通过在连接池中获取一个空闲的连接对数据库进行操作。一般在一个进程中,系统初始化一个连接池,该进程内的对象都可以使用这个连接池。而只有进程销毁,连接池才销毁。
jdbc 连接池 :每申请一个连接(Connection)会在物理网络(如 TCP/IP网络)上建立一个用于通讯的连接,在此连接上还可以申请一定数量的Statement。同一连接可提供的活跃Statement数量可以达到 几百。在节约网络资源的同时,缩短了每次会话周期(物理连接的建立是个费时的操作)。但在一般的应用中,多数按照2.1范例操作,这样有10个程序调用, 则会产生10次物理连接,每个Statement单独占用一个物理连接,这是极大的资源浪费。 ConnectionPool可以解决这个问题,让几十、几百个Statement只占用同一个物理连接
数据库会话:或者叫session;与sqlalchemy的session,不同。sqlalchemy的session是在python应用端的,而数据库会话一般指在连接用户进程与数据库实例之间系列通信。一个连接可以一个多个会话。