提示:所有代码均已开源,版权所有转载请标注来源,谢谢~
目录
背景
在写完上篇非2的幂,离散傅里叶变化DFT的快速实现后,家里的狗蛋问我,你写的这个是干啥的?
说者无意听者有心,在听到这个问题后大脑飞速旋转,一堆傅里叶变化将信号从时域观察改为频域观察的好处,但没有比举一个能让“dog”都能听懂的例子更切合实际(毕竟是狗蛋),然后就有了“识别男女声”的想法:
大脑在分别人的性别时,就是通过将人说话的声音(时域)转换到 从频域的角度去分析的,不同性别的人在发声时,声带的振荡频率不同,所以大脑能分别男女声音(完全是我脑补出来的答案,实际大脑怎么分辨或许是通过一大堆神经网络识别的吧,但也不能排除这个神经网络的输入是频域信号)。
一开始以为这个例子实现起来很简单,想着三下五除二录个我俩的声音,然后fft转换为频域,应该可以明显识别出两个声音在频域上峰值处于不同位置。But,当我一顿猛如虎的操作后,出来的结果也是傻了眼(下图),毛都分辨不出来。
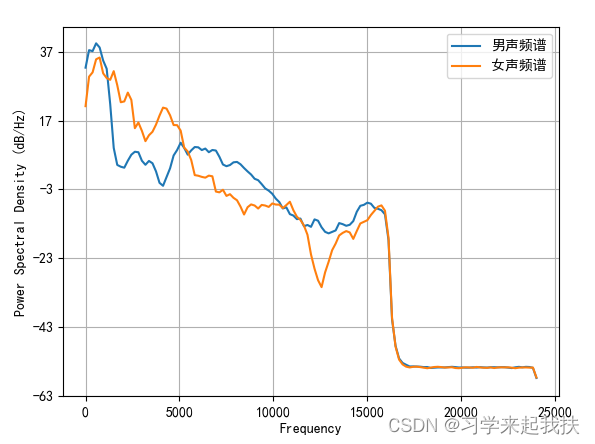
既然这样就只能老老实实查查文献,看看别人是怎么识别的,然后就有了下面罗里吧嗦的一堆东西~
提示:以下结论仅代表个人观点,没任何参考价值~ 完全是闹着玩~~
一、结果
老规矩直接先上结果:(检测样本较少,凑合看吧~)
女声的频率范围是261 ~ 333 Hz
在48000采样率下,周期为144 ~ 184样点
在44100采样率下,周期为132 ~ 168样点

方法1结果:

方法2结果:

结论:测试用例只有五个,方法1的准确率为40%,方法2的准确率为60%;
---------方法 1 是很多文献上的方法,理论上准确率应该高点;
---------方法 2 是直接观察时域信号规律,按照搜时延的方法找周期;
二、基础知识介绍
每个人声音的不同主要体现在声学特征上,比如经常听到的音色、音调,可能听过的基音周期、共振峰,其中基音周期就是所谓的声带的振动频率,也就是本文区分男女声的主要特征。在结论中的图1介绍过,男声的基音周期为136 ~ 185 Hz,女声的基音周期为261 ~ 333 Hz。本文的主要方法就是通过计算出每段数据的基音周期,按照男女声基音周期范围的不同进行区分。
1.数据读取:
音频数据处理直接拿手机录音,然后通过电脑软件“格式化工厂”直接转成wav格式,然后拿代码一解析。
需要注意的是:手机录取的声音一般是一个声道,但从网上下载下来的语音都有两个及以上声道,我们分析数据时只需要取出其中一个声带即可。
数据读取代码如下(示例)
# 导入数据
def fun_read_wav(data_path):
data_file = wave.open(data_path, 'rb')
data_paras = data_file.getparams()
nchannels, sampwidth, framerate, nframes = data_paras[:4]
data_str = data_file.readframes(nframes) # 读取音频,字符串格式
data = np.frombuffer(data_str, dtype=np.int16) # 将字符串转化为int, CHANGE
fs = data_paras[2]
data_file.close()
# return data, fs
return data[::nchannels], fs
2.分帧:
语音信号最基础的操作就是分帧。语音信号可以看做是一个非稳态+时变系统,但声带肌肉的振荡毕竟是缓慢的,所以在很短很短的时间内可以认为这段语音信号是稳态+时不变系统,而很短很短的数学描述就是分帧,把时域信号分成一截一截的。同时为了使每帧数据的特征可以平滑过渡,相邻两帧会有一段重叠的部分。
另外分帧的数据相当于对信号在时域上加了矩形窗,为了平滑过渡一般会对分帧后的数据进行加窗平滑。
分帧代码如下(示例):
import sys
import numpy as np
import scipy.signal as sig
import matplotlib.pyplot as plt
def fun_enfram(x, frame_len, shift_len, flt_flag=False):
"""
对数据进行分帧
@param x: 数据原始语音数据
@param frame_len: 每帧长度
@param shift_len: 每帧之间的偏移长度
@param flt_flag: 每帧数据是否滤波标志
@return: 分帧后数据,一行表示一帧
"""
data_len = x.shape[0]
overlap = frame_len - shift_len
frame_num = (data_len-overlap)//shift_len # 帧数 = 数据长度减去最后一个帧的剩余部分,再除以偏移长度
frame_start_index = np.arange(frame_num)*shift_len
data_enframe = np.zeros([frame_num,frame_len])
for i in range(frame_num):
frame_i_index = frame_start_index[i]
data_enframe[i,:] = x[frame_i_index:frame_i_index+frame_len]
if flt_flag:
wind = sig.hann(frame_len).reshape(1,-1)
wind_pad = np.tile(wind,[frame_num,1])
data_enframe = data_enframe * wind_pad
return data_enframe
# 做个台阶源就能看出是否进行滤波
if __name__ == '__main__':
data = np.ones(4096)
data[1024*0:1024*1] *= 100
data[1024*1:1024*2] *= 200
data[1024*2:1024*3] *= 300
data[1024*3:1024*4] *= 400
plt.subplot(121)
plt.plot(data,'*-')
plt.title('原始数据')
plt.grid(True)
data_enframe = fun_enfram(data, frame_len=512, shift_len=100)
plt.subplot(122)
plt.plot(data_enframe[8,:],'*-')
plt.plot(data_enframe[9,:],'*-')
plt.plot(data_enframe[10,:],'*-')
plt.title('8 9 10帧数据')
plt.grid(True)
结果:

3.平滑
顾名思义就是对数据进行平滑处理。平滑处理的原因是:由于每帧都会计算出一个基音周期,但不免部分帧本身不存在周期,这时该帧的基音周期其实就是一个异常值,通过用周围帧的基音周期对该帧进行平滑处理,可以增加整体基音周期的准确性。
本文平滑处理主要有两个手段:中值平滑 + 线性平滑。
中值平滑:用n个点的中值最为当前点的value;
线性平滑:用hanning窗对数据进行平滑滤波;
平滑代码如下(示例):
import sys
import numpy as np
import scipy.signal as sig
import matplotlib.pyplot as plt
def middle_smoth(x, deal_num, order):
"""
中值滤波:选取order范围内的中值,作为当前点的结果
@param x: 输入数据
@param deal_num:重复进行多次滤波
@param order:滤波范围
@return:滤波结果
"""
data_len = x.shape[0]
x_temp = np.zeros(data_len + order - 1)
for ni in range(deal_num):
x_temp[(order - 1) // 2:-(order - 1) // 2] = x
for xi in range(data_len):
x[xi] = np.median(x_temp[xi:xi+order])
return x
def line_smoth(x, win_len):
"""
线性滤波器:通过生成win_len长度的hann滤波器,对x进行滤波
(hann滤波器系数就是对周围n个点分别赋予不同权重,求和作为当前点的结果)
@param x: 输入数据
@param win_len: 线性滤波器窗长
@return: 滤波结果
"""
win_temp = sig.hann(win_len)
win = win_temp/sum(win_temp)
res = sig.convolve(x, win, mode='same')
return res
def smooth(x, win_len):
"""
对数据用中值平滑 + 线性滤波平滑 处理
@param x: 对每行数据进行平滑处理
@param win_len: 线性滤波平滑滤波器窗长
@return: 平滑后数据
"""
seg_num = x.shape[0] # x是个矩阵,一行是一帧
x_smoth = np.zeros_like(x)
for i in range(seg_num):
# seg_i_start = seg_dict[i].begin
# seg_i_end = seg_dict[i].end
x_i = x[i,:].copy()
x_i_middle = middle_smoth(x_i, deal_num=1, order=5)
x_i_line = line_smoth(x_i_middle, win_len)
x_smoth[i] = x_i_line
# x_smoth[i] = x_i_middle
return x_smoth
if __name__ == '__main__':
x = np.linspace(0,100,1000)
data = np.sin(x)
noise_index = np.random.randint(0,1000,80)
noise_data = np.random.randint(-10,10,80)
data[noise_index] = noise_data
plt.plot(x,data,'*-')
data_smooth = smooth(data.reshape(10,-1),5).reshape(-1)
plt.plot(x,data_smooth,'*-')
plt.title('平滑处理')
plt.legend(['平滑前','平滑后'])
plt.grid(True)
对生成的三角函数加一些噪音点,可以查看平滑处理效果(效果还凑合,够用~):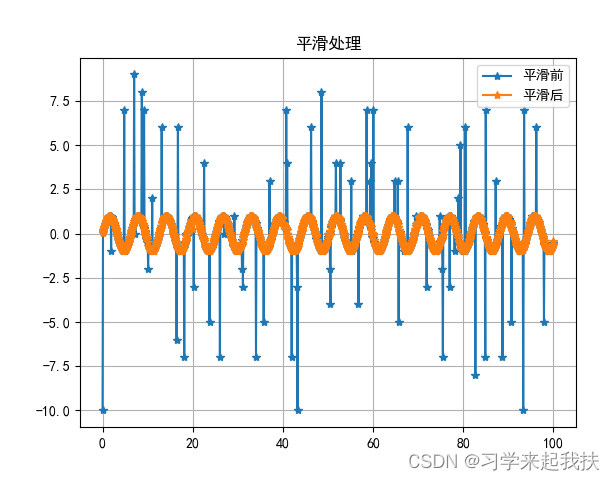
4.端点检测
端点检测的目的是为了在计算基音周期时,只用连续的有效帧来计算。何为有效帧:看时域的音频信号就能一眼出来(下图)。人的大脑基本上就是通过时域的振幅大小来区分,但为了更精准的区别有效帧,学术上一般通过每个帧的“能熵比”这个参数来区分。
【时域信号图】

能熵比:顾名思义就是每个帧的 能量 / 熵。
帧的能量 = 所有频点能量的和;
频点能量:每个频点能量的计算就是通过FFT计算出每个频点的幅值,进而得到能量;
帧的熵 = -sum(pi*log10pi),其中pi表示每个频点归一化谱概率密度
谱概率密度pi = Ei / E, 即每个频点的能量占整个帧的能量比
有效数据段:计算出每个帧的能熵比后,通过设置能熵比门限确定出有效帧,然后连续的有效帧就是有效的数据段。
另外:为了更精准的提高有效数据段的要求,可以给有效数据段设置一个帧数门限,即如果当前有效数据段包含的帧没有超过门限,则认为当前不是有效数据段。
平滑代码如下(示例):
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as sig
import wave
def cac_eef(voice_data):
"""
计算能熵比:计算每帧每个频点的能量,然后计算每个帧的能量,然后计算每个频点的能量谱,
然后计算每个帧的熵,最后能量/熵即为每个帧的能熵比
@param voice_data: 分帧后的语音信号,二维数组,每行表示一帧
@return: 每帧的能熵比
"""
frame_num, fram_len = voice_data.shape
# 计算每帧每个频点的能量
data_fft = np.fft.fft(voice_data, axis=1) # 每行是一帧,所以axis取1
data_fft = data_fft[:,:fram_len//2]
enery_frame_freq = data_fft * data_fft.conj() # 所以ij表示第i帧频点j的能量
enery_frame = np.sum(enery_frame_freq.real, axis=1) # 每帧的能量
p_frame_freq = enery_frame_freq.real / enery_frame.reshape(-1,1) # 每个频点在对应帧中的能量占比,叫做归一化谱概率密度
# 计算每帧的谱熵
H_frame = -np.sum(p_frame_freq * np.log2(p_frame_freq+np.spacing(1)),axis=1)
# 计算每帧的能熵比
low_h_index = np.where(H_frame<0.1)
H_frame[low_h_index] = np.max(H_frame) # 对谱熵小于0.1的帧用最大谱熵替换
EEF_frame = np.sqrt(1+abs(enery_frame/H_frame))
return EEF_frame
def find_actice_segment(EEF_frame, thr):
"""
找话语段:连续1的帧表示是一段话语
@param EEF_frame: 每帧的能熵比
@param thr: 每帧的能熵比门型
@return: 每段话语的起始和结束位置
"""
effect_frame_index = np.where(EEF_frame > thr)[0]
segment = {
}
segment_num = 0
segment_i_begin = effect_frame_index[0]
segment_i_end = effect_frame_index[0]
for i in range(effect_frame_index.shape[0]-1): # 给最后留一帧,这样最后一段不管走到哪个分支都能写入
if effect_frame_index[i+1] - effect_frame_index[i] > 1: # 表明两帧不是连着的
segment[segment_num] = [segment_i_begin, segment_i_end+1]
segment_i_begin = effect_frame_index[i + 1] # 确定下一段的起始索引
segment_i_end = effect_frame_index[i + 1] # 确定下一段初始的结束索引
segment_num += 1
else:
segment_i_end = effect_frame_index[i + 1] # 更新本段的结束索引
segment[segment_num] = [segment_i_begin, segment_i_end + 1] # 写入最后一段的索引
segment_num += 1
return segment, segment_num
def vad(voice_data, thr, mini_len=20):
"""
检测原始语音信号的有效数据段
@param voice_data: 分帧数据
@param thr: 每帧的能熵比门型
@param mini_len: 每段数据最少帧数门限
@return: 有效数据段帧的起始结束索引,每帧是否有效标志
"""
EEF_data = cac_eef(voice_data) # 计算每帧的能熵比
segment, segment_num = find_actice_segment(EEF_frame=EEF_data, thr=thr) # 查找每个话语的起始结束帧
# 按照最小话语长度更新话语并对每帧进行标注
new_seg_num = 0
new_seg = {
}
effect_frame_flag = np.zeros_like(voice_data)
for i in range(segment_num):
if segment[i][1] - segment[i][0] >= mini_len: # 大于最小长度说明是有效话语段
new_seg[new_seg_num] = segment[i].copy()
new_seg_num += 1
effect_frame_flag[segment[i][0]:segment[i][1]] = 1
else: # 小于最小有效长度说明该段不是有效话语段
pass
return new_seg, effect_frame_flag
if __name__ == "__main__":
# 读取音频数据
data_path = r'qn3.wav'
data_file = wave.open(data_path, 'rb')
paras = data_file.getparams()
nchannels, sampwidth, framerate, nframes = paras[:4]
data_str = data_file.readframes(nframes) # 读取音频,字符串格式
data = np.frombuffer(data_str, dtype=np.int16) # 将字符串转化为int, CHANGE
data_file.close()
fs = paras[2]
# 分帧
import enframe
frame_len = 320*8
shift_len = 80*6
data_enframe = enframe.fun_enfram(data, frame_len, shift_len)
# 检测
thr = 40000
voice_seg, frame_flag = vad(data_enframe, thr)
# 结果展示
plt.plot(np.arange(data.shape[0])/fs,data,'b*-')
plt.grid(True)
for i in voice_seg.keys():
frame_loc = np.array(voice_seg[i]) * shift_len + frame_len//2
plt.plot(np.arange(frame_loc[0],frame_loc[1])/fs, data[frame_loc[0]:frame_loc[1]],'r*-')
plt.legend(['原始数据','检测结果'])
plt.title('端点检测')
实验的音频数据专门说了一些词语“冰箱、空调、被子、桌子、凳子”,类似这样的词,为了说明结果也能把两个词之间的无效段抛弃掉。实验效果如下,调整门限其实可以得到更加精准的数据段。
![[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblog.csdmg.c3/Qnnr678bf5c0676243a4be4286156dc20749.png)https://img-j3xQncr-1/c67654369035)]]](https://img-blog.csdnimg.cn/8b1a1e503ed644c2b3b569e3923164f2.png)
三、基音计算
最后来到本文最后一部分,就是对每个音频数据的基音周期计算。
1.预处理:
预处理主要包括:去直流、幅值归一、分帧、帧数据映射到时间轴、查找有效数据段;
去直流:数据的均值在频域上体现在0频点,为了避免对查找有效数据产生因影响,直接对音频数据减去均值即可;
幅值归一:幅值归一化为了减少数据的波动,在第二节有效帧检测时,设置的能熵比门限达到4000,归一化后可以直接设置成4即可;
分帧:见第二节;
帧数据映射:这是一个维测手段,为了在数据分析方便把帧数据和原始数据对比,其实在第二节有效数据检查的代码中,为了展示数据检查的结果,就有这个操作;映射时是把每帧中间数据点所在的时间看成是该帧所在的时间;
查找有效数据段:见第二节;
预处理代码如下(示例):
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as sig
import wave
# 导入自写函数
import enframe
import voice_activity_detection as vad
def frame2time(frame_num, frame_len, shift_len, fs):
"""
求每个帧所在的时间点,用每帧中间样本点的时间代替该帧所在的时间
@param frame_num: 帧数
@param frame_len: 帧长
@param shift_len: 偏移长度
@param fs: 采样率
@return: 每帧的时间
"""
delt_time = 1/fs # 两个采样点之间的时间间隔
frame_loc = np.arange(frame_num)*shift_len + frame_len/2 # 每帧最中间样本点的索引
fram_time = frame_loc * delt_time
return fram_time
# 预处理
def data_pre_process(org_data, fs, frame_len, shift_len, T1):
"""
对数进行预处理:去直流、幅值归一化、分帧、查找话语段
@param org_data: 输入声音数据
@param fs: 数据采样率
@param frame_len: 帧长
@param shift_len: 每帧直接的步进
@param T1:有效帧门限
@return:有效话语段、每帧是否有效、原始数据时间坐标、分帧后数据的时间坐标
"""
# 去直流
data_mean = org_data - np.mean(org_data)
# 幅值归一
data_one = data_mean / np.max(data_mean)
# 分帧
data_enframe = enframe.fun_enfram(data_one,frame_len,shift_len)
frame_num = data_enframe.shape[0]
# 帧映射到时间上
data_len = org_data.shape[0]
org_data_time = np.arange(data_len) / fs # 计算原始数据的时间坐标(画图使用)
frame_time = frame2time(frame_num,frame_len,shift_len,fs) # 计算数据分帧后的时间坐标(画图使用)
# 查找有效话语段
voice_seg, frame_flag = vad.vad(data_enframe, T1)
return data_one, frame_flag, frame_time, voice_seg, org_data_time
if __name__ == '__main__':
# 参数初始化
frame_len = 320 # 帧长
shift_len = 80 # 帧移
T1 = 0.05 # 端点检测门型
# 导入数据
data_path_list = [r'qn3.wav', r'fei3.wav']
data = []
paras = []
for data_path_i in data_path_list:
data_file = wave.open(data_path_i, 'rb')
data_paras = data_file.getparams()
nchannels, sampwidth, framerate, nframes = data_paras[:4]
data_str = data_file.readframes(nframes) # 读取音频,字符串格式
data_i = np.frombuffer(data_str, dtype=np.int16) # 将字符串转化为int, CHANGE
data_file.close()
data.append(data_i)
paras.append(data_paras)
man_data = data[0]
man_fs = paras[0][2]
weman_data = data[1]
data = man_data
fs = man_fs
data_pro = data_pre_process(data,fs,frame_len,shift_len,T1)
2.对分帧数据进行滤波:
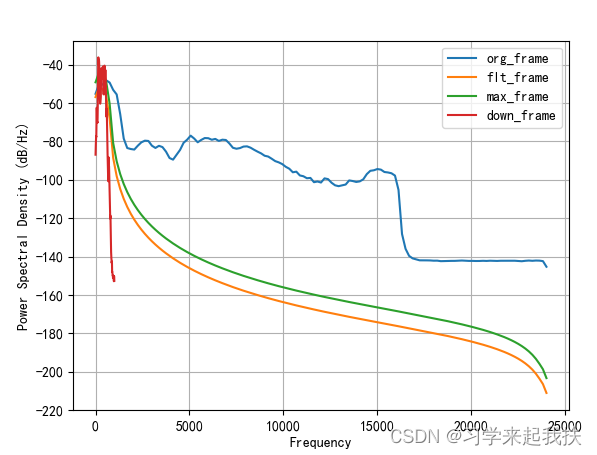
预处理操作时的分帧函数其实就自带滤波功能,滤波的目的在之前也提到了。在预处理中之所以没有对分帧数据进行滤波是为了维持每帧数据最原始的能量,增加有效帧识别准确率,所以把对每帧数据的滤波挪到此处。另外此处还对数据进行降采样率操作,因为手机录制的声音采样率太高,数据处理过慢。
分帧滤波代码如下(示例):
# 对分帧后的数据进行滤波(分帧是直接截断,需要加个窗平滑过渡)
fs2 = fs/2
Rp = 1
Rs = 50
Wp = np.array([60, 500])/fs2
Ws = np.array([20, 1000])/fs2
N, Wn = sig.ellipord(Wp, Ws, Rp, Rs)
coef_b, coef_a = sig.ellip(N, Rp, Rs, Wn,'bandpass')
# H,W = sig.freqz(coef_b,coef_a) # 画滤波器的频响
# plt.plot(20*np.log2(W+limit_min))
data_filt = sig.filtfilt(coef_b,coef_a,data_one)
data_max = data_filt/np.max(abs(data_filt))
data_down = sig.resample_poly(data_max,1,24) # 为了减少计算量,所以进行24倍下采样
# 查看预处理结果
# plt.figure()
# plt.psd(data_one,Fs=fs)
# plt.psd(data_filt,Fs=fs)
# plt.psd(data_max,Fs=fs)
# plt.psd(data_down,Fs=fs/24)
# plt.legend(['org_frame','flt_frame','max_frame','down_frame'])
# plt.grid(True)
# 对下采样后的数据再进行分帧分帧数据进行滤波,之前的分帧是为了端点检测
data_enframe = enframe.fun_enfram(data_down, int(frame_len/24), int(shift_len/24), flt_flag=True)
预处理+滤波后结果如下:
3.计算每帧数据相关性:
基础每帧数据的相关系数有两种方法,两种方法的根本区别是计算相关系数所用的数据不同。计算相关系数的方法都是调用自相关系数:通过计算数据每移动一个点后与原始数据的相关系数。自写代码只计算了正时延的结果,负时延结果是对称的。
自相关系数计算代码如下(示例):
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
def fun_xcorr_coeff(data, axis=0):
"""
计算相关性:按照皮尔逊相关系数,直接用数据计算,没有对数据本身进行归一化,
只对最终相关结果进行归一化表示,对标matlab函数xcorr(data,'coeff)
@param data:输入数据,支持一维和二维
@param axis:计算相关系数的维度
@return:对应维度,在不同偏移量下的相关值
"""
corr_coef = np.zeros_like(data)
m,n = data.shape
if axis == 0:
one_coef = np.sum(data ** 2, axis=axis).reshape(1, -1)
data_extend = np.zeros([m*2-1, n])
data_extend[:m,:] = data.copy()
for i in range(m):
corr_coef[i, :] = np.sum(data * data_extend[i:i+m, :], axis=axis)
else:
one_coef = np.sum(data ** 2, axis=axis).reshape(-1, 1)
data_extend = np.zeros([m, n*2-1])
data_extend[:,:n] = data.copy()
for i in range(n):
corr_coef[:, i] = np.sum(data * data_extend[:, i:i+n], axis=axis)
corr_coef = corr_coef/one_coef
return corr_coef
def show_corr_coef(data, axis=0):
# plt.figure()
legend_list = []
if axis == 0:
for i in range(data.shape[1]):
plt.plot(range(data.shape[0]), data[:, i], '*')
plt.vlines(range(data.shape[0]), ymin=0, ymax=data[:, i])
legend_list.append('fram_num=' + str(i))
else:
for i in range(data.shape[0]):
plt.plot(range(data.shape[1]), data[i, :], '*')
plt.vlines(range(data.shape[1]), ymin=0, ymax=data[i, :])
legend_list.append('fram_num=' + str(i))
plt.grid(True)
plt.xlabel("偏移量")
plt.ylabel("相关系数")
plt.title("不同偏移量下的相关系数")
plt.legend(legend_list)
if __name__ == "__main__":
data_test = np.array([[2,3,4,3,7],[1,2,1,2,1]])
axis = 1
corr_coef = fun_xcorr_coeff(data_test, axis)
show_corr_coef(corr_coef, axis)
(1)方法1
方法1是通过对语音信号进行LPC分析和内滤波,获得语音信号的预测误差,然后计算误差的相关系数
LPC方法计算代码如下(示例):
def cac_lpc_coef(s, p):
"""
:param s: 一帧数据
:param p: 线性预测的阶数
:return:
"""
n = len(s)
# 计算自相关函数
Rp = np.zeros(p)
for i in range(p):
Rp[i] = np.sum(np.multiply(s[i + 1:n], s[:n - i - 1]))
Rp0 = np.matmul(s, s.T)
Ep = np.zeros((p, 1))
k = np.zeros((p, 1))
a = np.zeros((p, p))
# 处理i=0的情况
Ep0 = Rp0
k[0] = Rp[0] / Rp0
a[0, 0] = k[0]
Ep[0] = (1 - k[0] * k[0]) * Ep0
# i=1开始,递归计算
if p > 1:
for i in range(1, p):
k[i] = (Rp[i] - np.sum(np.multiply(a[:i, i - 1], Rp[i - 1::-1]))) / Ep[i - 1]
a[i, i] = k[i]
Ep[i] = (1 - k[i] * k[i]) * Ep[i - 1]
for j in range(i - 1, -1, -1):
a[j, i] = a[j, i - 1] - k[i] * a[i - j - 1, i - 1]
ar = np.zeros(p + 1)
ar[0] = 1
ar[1:] = -a[:, p - 1]
G = np.sqrt(Ep[p - 1])
return ar, G
def lpcff(ar, npp=None):
"""
:param ar: 线性预测系数
:param npp: FFT阶数
:return:
"""
p1 = ar.shape[0]
if npp is None:
npp = p1 - 1
ff = 1 / np.fft.fft(ar, 2 * npp + 2)
return ff[:len(ff) // 2]
def lpc_lpccm(ar, n_lpc, n_lpcc):
lpcc = np.zeros(n_lpcc)
lpcc[0] = ar[0] # 计算n=1的lpcc
for n in range(1, n_lpc): # 计算n=2,,p的lpcc
lpcc[n] = ar[n]
for l in range(n - 1):
lpcc[n] += ar[l] * lpcc[n - 1] * (n - l) / n
for n in range(n_lpc, n_lpcc): # 计算n>p的lpcc
lpcc[n] = 0
for l in range(n_lpc):
lpcc[n] += ar[l] * lpcc[n - 1] * (n - l) / n
return -lpcc
# 提取基音周期
erro_correlation = np.zeros([frame_num,frame_len])
for segi in voice_seg.keys(): # 对每段数据分别进行检测
segi_frame_begin, segi_frame_end = voice_seg[segi]
frame_num_seg = segi_frame_end - segi_frame_begin
erro_frame_seg = np.zeros([frame_num_seg,frame_len])
for i in range(segi_frame_begin, segi_frame_end): # 对每帧数据进行处理
frame_i_data = data_enframe[i,:]
lpc_coef, gain = cac_lpc_coef(frame_i_data, lpc_order) # 用lpc计算每帧数据的自相关器系数
lpc_coef[0] = 0
est_frma_i = sig.filtfilt(-lpc_coef, 1, frame_i_data) # lpc逆滤波法求出每帧的预测数据
erro_i = frame_i_data - est_frma_i # 计算预测结果与真实结果的误差
erro_frame_seg[i-segi_frame_begin,:] = sig.resample_poly(erro_i, 24, 1) # 对误差进行24倍上采样恢复原始速率
erro_correlation[segi_frame_begin:segi_frame_end] = corr.fun_xcorr_coeff(erro_frame_seg, axis=1) # 用自相关系数法求出每帧数据每个偏移量的相关系数
# 查看相关系数
# plt.figure()
# corr.show_corr_coef(erro_correlation[segi_frame_begin:segi_frame_end], axis=1)
# corr.show_corr_coef(erro_correlation[220:230], axis=1)
(2)方法2
方案2是通过直接计算每帧数据在时域上的相关性,通过计算每帧数据的相关系数。
直接时域计算代码如下(示例):
# 提取基音周期
correlation = np.zeros([frame_num,frame_len])
for segi in voice_seg.keys(): # 对每段数据分别进行检测
segi_frame_begin, segi_frame_end = voice_seg[segi]
frame_segi = data_enframe[segi_frame_begin:segi_frame_end]
frame_segi_up = sig.resample_poly(frame_segi, 24, 1,axis=1)
# 直接在时域上搜索周期
correlation[segi_frame_begin:segi_frame_end] = corr.fun_xcorr_coeff(frame_segi_up, axis=1)
# 查看相关系数
# plt.figure()
# corr.show_corr_coef(erro_correlation[segi_frame_begin:segi_frame_end], axis=1)
# corr.show_corr_coef(erro_correlation[220:230], axis=1)
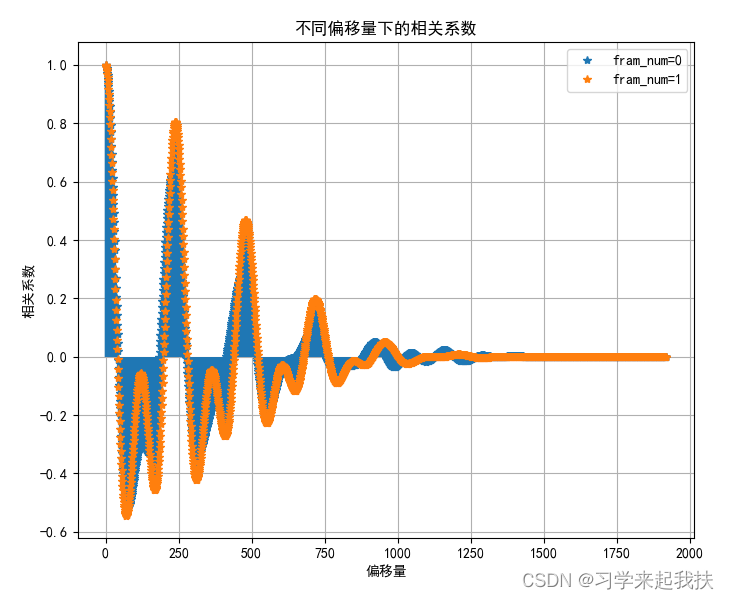
某两帧相关系数结果如下:
4.查找每帧数据最大基音周期:
通过求出每帧数据最大相关系数所在的索引即为该帧数据的基音周期。由于人的听力是60 ~ 500 Hz,所以基音周期的搜索在这个范围搜索即可;
查找每帧数据基音周期代码如下(示例):
# 取出在[60-500]hz范围内的最大值即为该帧的基音频率(人耳范围)
freq_min = int(fs/500) # 人耳最大基频500hz,则周期为1/500s,在fs采样率下,一个周期内就有fs*1/500个点
freq_max = int(fs/60)
frame_period = np.zeros(frame_num,'int')
# max_corr_frame = np.max(erro_correlation[:,freq_min:freq_max], axis=1) # 通过看每帧最大相关系数的分布,可以给相关系数做个门限
# plt.figure()
# plt.hist(max_corr_frame,bins=10,color='pink',edgecolor='b')
print(voice_seg)
for segi in voice_seg.keys():
segi_frame_begin, segi_frame_end = voice_seg[segi]
# 在人耳范围内求出相关系数最大的位置
# peroid_index_frame = np.argmax(abs(correlation[segi_frame_begin:segi_frame_end,freq_min:freq_max]), axis=1)
peroid_index_frame = np.argmax(correlation[segi_frame_begin:segi_frame_end,freq_min:freq_max], axis=1)
frame_period[segi_frame_begin:segi_frame_end] = freq_min + peroid_index_frame
# plt.figure()
# data_num, data_freq, _ = plt.hist(frame_period[segi_frame_begin:segi_frame_end], bins=max(frame_period))
# data_base_period_index = np.argmax(data_num)
# data_base_period = data_freq[data_base_period_index]
# print('当前该段数据用众数计算的基音频率为:{:}'.format(data_base_period))
5.对每段数据的基音数据进行平滑处理:
因为分帧的缘故会导致部分帧的基音周期很大,所以需要对每段数据的基音周期进行平滑处理。
基音周期平滑代码如下(示例):
# 对所有帧周期做平滑处理
period_smooth = smooth_line.smooth(frame_period.reshape(1,-1),5)[0,:]
plt.figure()
plt.plot(frame_time, period_smooth, '*-')
plt.grid(True)
plt.title('平滑处理后的帧周期')
平滑处理后帧周期结果: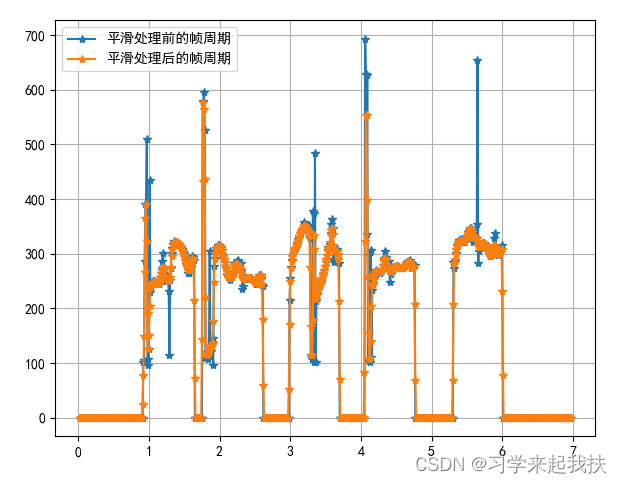
6.计算音频数据的基音周期:
本文通过用平均值和众数两种方法来确定音频数据的最终基音周期,两种数据按照测试效果来看,平均数计算的准确性更高。分析原因可能是由于每帧数据的样本点较离散,所以众数所在的样本点其实不太多,没有说服力。(也有可能是由于众数计算时分段数设置不合理导致)
最终基音周期计算代码如下(示例):
# 计算平滑后所有帧周期计算的平均值和众数
plt.figure()
data_num, data_freq, _ = plt.hist(period_smooth, bins=max(period_smooth), color='pink', edgecolor='b')
data_base_period_index = np.argmax(data_num[freq_min + 1:freq_max])
data_base_period = freq_min + data_freq[data_base_period_index]
print('当前数据用众数计算的基音频率为:{:}'.format(data_base_period))
print('当前数据用平均计算的基音频率为:{:}'.format(np.mean(period_smooth[period_smooth != 0])))
print('=====================================')
7.音频数据处理代码整理:
方法1:
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as sig
import wave
# 导入自写函数
import voice_preprocess as vpro
import enframe
import lpc
import cac_corr_coef as corr
import smooth_line
limit_min = np.spacing(1)
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def main(data,fs,frame_len,shift_len,T1,lpc_order):
# 数据预处理
data_one, frame_flag, frame_time, voice_seg, org_data_time \
= vpro.data_pre_process(data, fs, frame_len, shift_len, T1)
frame_num = frame_flag.shape[0]
# 对分帧后的数据进行滤波(分帧是直接截断,需要加个窗平滑过渡)
fs2 = fs/2
Rp = 1
Rs = 50
Wp = np.array([60, 500])/fs2
Ws = np.array([20, 1000])/fs2
N, Wn = sig.ellipord(Wp, Ws, Rp, Rs)
coef_b, coef_a = sig.ellip(N, Rp, Rs, Wn,'bandpass')
# H,W = sig.freqz(coef_b,coef_a) # 画滤波器的频响
# plt.plot(20*np.log2(W+limit_min))
data_filt = sig.filtfilt(coef_b,coef_a,data_one)
data_max = data_filt/np.max(abs(data_filt))
data_down = sig.resample_poly(data_max,1,24) # 为了减少计算量,所以进行24倍下采样
# 查看预处理结果
# plt.figure()
# plt.psd(data_one,Fs=fs)
# plt.psd(data_filt,Fs=fs)
# plt.psd(data_max,Fs=fs)
# plt.psd(data_down,Fs=fs/24)
# plt.legend(['org_frame','flt_frame','max_frame','down_frame'])
# plt.grid(True)
# 对下采样后的数据再进行分帧分帧数据进行滤波,之前的分帧是为了端点检测
data_enframe = enframe.fun_enfram(data_down, int(frame_len/24), int(shift_len/24), flt_flag=True)
# 提取基音周期
erro_correlation = np.zeros([frame_num,frame_len])
for segi in voice_seg.keys(): # 对每段数据分别进行检测
segi_frame_begin, segi_frame_end = voice_seg[segi]
frame_num_seg = segi_frame_end - segi_frame_begin
erro_frame_seg = np.zeros([frame_num_seg,frame_len])
for i in range(segi_frame_begin, segi_frame_end): # 对每帧数据进行处理
frame_i_data = data_enframe[i,:]
lpc_coef, gain = lpc.cac_lpc_coef(frame_i_data, lpc_order) # 用lpc计算每帧数据的自相关器系数
lpc_coef[0] = 0
est_frma_i = sig.filtfilt(-lpc_coef, 1, frame_i_data) # lpc逆滤波法求出每帧的预测数据
erro_i = frame_i_data - est_frma_i # 计算预测结果与真实结果的误差
erro_frame_seg[i-segi_frame_begin,:] = sig.resample_poly(erro_i, 24, 1) # 对误差进行24倍上采样恢复原始速率
erro_correlation[segi_frame_begin:segi_frame_end] = corr.fun_xcorr_coeff(erro_frame_seg, axis=1) # 用自相关系数法求出每帧数据每个偏移量的相关系数
# 查看相关系数
# plt.figure()
# corr.show_corr_coef(erro_correlation[segi_frame_begin:segi_frame_end], axis=1)
# corr.show_corr_coef(erro_correlation[220:230], axis=1)
# 取出在[60-500]hz范围内的最大值即为该帧的基音频率(人耳范围)
freq_min = int(fs/500) # 人耳最大基频500hz,则周期为1/500s,在fs采样率下,一个周期内就有fs*1/500个点
freq_max = int(fs/60)
frame_period = np.zeros(frame_num,'int')
# max_corr_frame = np.max(erro_correlation[:,freq_min:freq_max], axis=1) # 通过看每帧最大相关系数的分布,可以给相关系数做个门限
# plt.figure()
# plt.hist(max_corr_frame,bins=10,color='pink',edgecolor='b')
for segi in voice_seg.keys():
segi_frame_begin, segi_frame_end = voice_seg[segi]
# 在人耳范围内求出相关系数最大的位置
# peroid_index_frame = np.argmax(abs(erro_correlation[segi_frame_begin:segi_frame_end,freq_min:freq_max]), axis=1)
peroid_index_frame = np.argmax(erro_correlation[segi_frame_begin:segi_frame_end,freq_min:freq_max], axis=1)
frame_period[segi_frame_begin:segi_frame_end] = freq_min + peroid_index_frame
# plt.figure()
# data_num, data_freq, _ = plt.hist(frame_period[segi_frame_begin:segi_frame_end], bins=max(frame_period))
# 未平滑处理的帧周期
plt.figure()
plt.plot(frame_time, frame_period, '*-')
plt.grid(True)
plt.title('平滑处理前的帧周期')
# 计算平滑前所有帧周期计算的平均值和众数
# plt.figure()
# data_num, data_freq, _ = plt.hist(frame_period,bins=max(frame_period),color='pink',edgecolor='b')
# data_base_period_index = np.argmax(data_num[freq_min+1:freq_max])
# data_base_period = freq_min + data_freq[data_base_period_index]
# print('当前数据用众数计算的基音频率为:{:}'.format(data_base_period))
#
# print('当前数据用平均计算的基音频率为:{:}'.format(np.mean(frame_period[frame_period != 0])))
# 对所有帧周期做平滑处理
period_smooth = smooth_line.smooth(frame_period.reshape(1,-1),5)[0,:]
plt.figure()
plt.plot(frame_time, period_smooth, '*-')
plt.grid(True)
plt.title('平滑处理后的帧周期')
# 计算平滑后所有帧周期计算的平均值和众数
plt.figure()
data_num, data_freq, _ = plt.hist(period_smooth, bins=max(period_smooth), color='pink', edgecolor='b')
data_base_period_index = np.argmax(data_num[freq_min + 1:freq_max])
data_base_period = freq_min + data_freq[data_base_period_index]
print('当前数据用众数计算的基音频率为:{:}'.format(data_base_period))
print('当前数据用平均计算的基音频率为:{:}'.format(np.mean(period_smooth[period_smooth != 0])))
print('=====================================')
方法2
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as sig
import wave
# 导入自写函数
import voice_preprocess as vpro
import enframe
import lpc
import cac_corr_coef as corr
import smooth_line
limit_min = np.spacing(1)
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def main(data,fs,frame_len,shift_len,T1,lpc_order):
# 数据预处理
data_one, frame_flag, frame_time, voice_seg, org_data_time \
= vpro.data_pre_process(data, fs, frame_len, shift_len, T1)
frame_num = frame_flag.shape[0]
# 对分帧后的数据进行滤波(分帧是直接截断,需要加个窗平滑过渡)
fs2 = fs/2
Rp = 1
Rs = 50
Wp = np.array([60, 500])/fs2
Ws = np.array([20, 1000])/fs2
N, Wn = sig.ellipord(Wp, Ws, Rp, Rs)
coef_b, coef_a = sig.ellip(N, Rp, Rs, Wn,'bandpass')
# H,W = sig.freqz(coef_b,coef_a) # 画滤波器的频响
# plt.plot(20*np.log2(W+limit_min))
data_filt = sig.filtfilt(coef_b,coef_a,data_one)
data_max = data_filt/np.max(abs(data_filt))
data_down = sig.resample_poly(data_max,1,24) # 为了减少计算量,所以进行24倍下采样
# 查看预处理结果
# plt.figure()
# plt.psd(data_one,Fs=fs)
# plt.psd(data_filt,Fs=fs)
# plt.psd(data_max,Fs=fs)
# plt.psd(data_down,Fs=fs/24)
# plt.legend(['org_frame','flt_frame','max_frame','down_frame'])
# plt.grid(True)
# 对下采样后的数据再进行分帧分帧数据进行滤波,之前的分帧是为了端点检测
data_enframe = enframe.fun_enfram(data_down, int(frame_len/24), int(shift_len/24), flt_flag=True)
# 提取基音周期
correlation = np.zeros([frame_num,frame_len])
for segi in voice_seg.keys(): # 对每段数据分别进行检测
segi_frame_begin, segi_frame_end = voice_seg[segi]
frame_segi = data_enframe[segi_frame_begin:segi_frame_end]
frame_segi_up = sig.resample_poly(frame_segi, 24, 1,axis=1)
# 直接在时域上搜索周期
correlation[segi_frame_begin:segi_frame_end] = corr.fun_xcorr_coeff(frame_segi_up, axis=1)
# 查看相关系数
# plt.figure()
# corr.show_corr_coef(erro_correlation[segi_frame_begin:segi_frame_end], axis=1)
# corr.show_corr_coef(erro_correlation[220:230], axis=1)
# 取出在[60-500]hz范围内的最大值即为该帧的基音频率(人耳范围)
freq_min = int(fs/500) # 人耳最大基频500hz,则周期为1/500s,在fs采样率下,一个周期内就有fs*1/500个点
freq_max = int(fs/60)
frame_period = np.zeros(frame_num,'int')
# max_corr_frame = np.max(erro_correlation[:,freq_min:freq_max], axis=1) # 通过看每帧最大相关系数的分布,可以给相关系数做个门限
# plt.figure()
# plt.hist(max_corr_frame,bins=10,color='pink',edgecolor='b')
print(voice_seg)
for segi in voice_seg.keys():
segi_frame_begin, segi_frame_end = voice_seg[segi]
# 在人耳范围内求出相关系数最大的位置
# peroid_index_frame = np.argmax(abs(correlation[segi_frame_begin:segi_frame_end,freq_min:freq_max]), axis=1)
peroid_index_frame = np.argmax(correlation[segi_frame_begin:segi_frame_end,freq_min:freq_max], axis=1)
frame_period[segi_frame_begin:segi_frame_end] = freq_min + peroid_index_frame
# plt.figure()
# data_num, data_freq, _ = plt.hist(frame_period[segi_frame_begin:segi_frame_end], bins=max(frame_period))
# data_base_period_index = np.argmax(data_num)
# data_base_period = data_freq[data_base_period_index]
# print('当前该段数据用众数计算的基音频率为:{:}'.format(data_base_period))
# 未平滑处理的帧周期
plt.figure()
plt.plot(frame_time, frame_period, '*-')
plt.grid(True)
plt.title('平滑处理前的帧周期')
# 计算平滑前所有帧周期计算的平均值和众数
# plt.figure()
# data_num, data_freq, _ = plt.hist(frame_period,bins=max(frame_period),color='pink',edgecolor='b')
# data_base_period_index = np.argmax(data_num[freq_min+1:freq_max])
# data_base_period = freq_min + data_freq[data_base_period_index]
# print('当前数据用众数计算的基音频率为:{:}'.format(data_base_period))
#
# print('当前数据用平均计算的基音频率为:{:}'.format(np.mean(frame_period[frame_period != 0])))
# 对所有帧周期做平滑处理
period_smooth = smooth_line.smooth(frame_period.reshape(1,-1),5)[0,:]
plt.figure()
plt.plot(frame_time, period_smooth, '*-')
plt.grid(True)
plt.title('平滑处理后的帧周期')
# 计算平滑后所有帧周期计算的平均值和众数
plt.figure()
data_num, data_freq, _ = plt.hist(period_smooth, bins=max(period_smooth), color='pink', edgecolor='b')
data_base_period_index = np.argmax(data_num[freq_min + 1:freq_max])
data_base_period = freq_min + data_freq[data_base_period_index]
print('当前数据用众数计算的基音频率为:{:}'.format(data_base_period))
print('当前数据用平均计算的基音频率为:{:}'.format(np.mean(period_smooth[period_smooth != 0])))
print('=====================================')
四、实验结果汇总
1.主函数:
主函数代码如下,音频文件自己录制即可。
import numpy as np
import matplotlib.pyplot as plt
import scipy.signal as sig
import wave
import time
# 导入自写函数
import data_process
import data_process_plus
limit_min = np.spacing(1)
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 参数初始化
frame_len = 320*6 # 帧长
shift_len = 80*6 # 帧移
T1 = 4 # 端点检测门型
lpc_order = 4
if __name__ == "__main__":
data_start, data_end = 2, 7
for i in range(data_start, data_end+1):
# 计算男声
start_time = time.time()
print('===========计算第 {:} 组数的男声============='.format(i))
data_path = r'qn{:}.wav'.format(i)
data,fs = fun_read_wav(data_path)
# data_process.main(data,fs,frame_len,shift_len,T1,lpc_order)
data_process_plus.main(data,fs,frame_len,shift_len,T1,lpc_order)
print('第 {:} 组数男声用时:{:} s'.format(i,time.time()-start_time))
# 计算女声
# start_time = time.time()
# print('===========计算第 {:} 组数的女声============='.format(i))
# data_path = r'fei{:}.wav'.format(i)
# data, fs = fun_read_wav(data_path)
# # data_process.main(data, fs, frame_len, shift_len, T1, lpc_order)
# data_process_plus.main(data, fs, frame_len, shift_len, T1, lpc_order)
# print('第 {:} 组数女声用时:{:} s'.format(i,time.time()-start_time))
# # 计算test
# start_time = time.time()
# print('===========计算第 {:} 组数的test声============='.format(i))
# data_path = r'test{:}.wav'.format(i)
# data, fs = fun_read_wav(data_path)
# print('采样率:{:}'.format(fs))
# # data_process.main(data, fs, frame_len, shift_len, T1, lpc_order)
# data_process_plus.main(data, fs, frame_len, shift_len, T1, lpc_order)
# print('第 {:} 组数女声用时:{:} s'.format(i,time.time()-start_time))
# plt.plot(data[45000:75000],'*-')
# plt.plot(data[35000:65000],'*-')
# # plt.plot(data[:],'*-')
# # plt.plot(data1[0000:10000],'*-')
plt.plot(np.arange(data.shape[0])/fs,data,'*-')
# plt.plot(data,'*-')
plt.grid(True)
2.实验结果汇总:
方法1的检测结果:
方法2的检测结果:

方法2的结果对于本文的目的来说,可能更有用一些~
方法1与方法2计算结果的差异可能是由于方法1的目的并不仅仅是本文区分男女声这么简单的目的,方法1更根本的目的是“语音转换”,即把男声变成具有相同特征的女声,感兴趣的可以自己查查资料实践一下~~
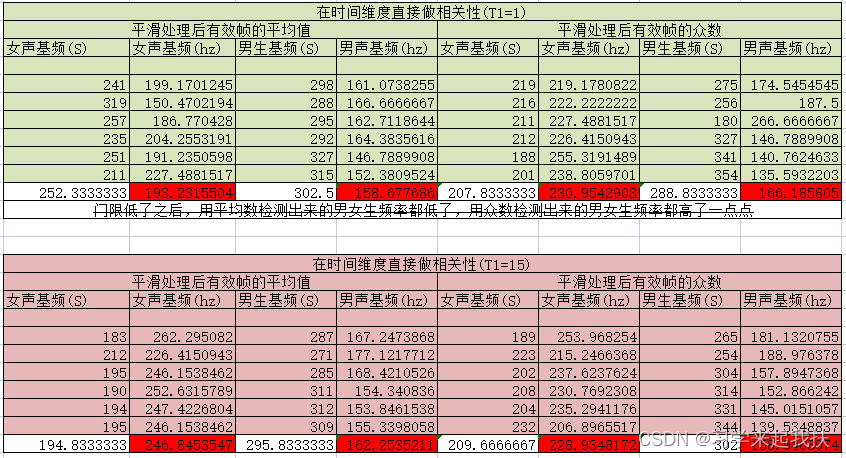
方法2在不同能熵比门限的实验结果如下:

五、总结
本文区分男女声的方法其实很简单:就是在时域上通过自相关方法求出音频数据的循环周期,以此作为所谓的基音周期。为了达到此目的,需要经过一系列的预处理操作以及最重要的有效段检测。为了让计算结果更精确在最后对基音周期进行平滑处理。
所以归纳起来就三个词:有效帧检测、自相关系数、平滑处理;
最后:
语音信号处理有专门的一套完整的理论,本文只对其中的九牛一毛拿来玩,感兴趣的可以自行搜索。
预告:
下期目前在“卡尔曼滤波”和“微信小程序”两个方向的抉择中,微信小程序是想换个口味玩一玩~
谢谢思密达~~~