PINN解偏微分方程实例2之一维非线性薛定谔方程
1. 一维非线性薛定谔方程
考虑偏微分方程如下:
i h t + 0.5 h x x + ∣ h ∣ 2 h = 0 h ( 0 , x ) = 2 s e c h ( x ) h ( t , − 5 ) = h ( t , 5 ) h x ( t , − 5 ) = h x ( t , 5 ) \begin{align} \begin{aligned} & ih_t + 0.5h_{xx} + |h|^2h = 0 \\ & h(0,x) = 2 sech(x) \\ & h(t,-5) = h(t,5) \\ & h_x(t,-5) = h_x(t,5) \end{aligned} \end{align} iht+0.5hxx+∣h∣2h=0h(0,x)=2sech(x)h(t,−5)=h(t,5)hx(t,−5)=hx(t,5)
其中 x ∈ [ − 5 , 5 ] , t ∈ [ 0 , π / 2 ] . x\in[-5,5],t\in[0,\pi/2]. x∈[−5,5],t∈[0,π/2].这是一个带有周期性边界条件,初始条件和复数解的偏微分方程。
2. 损失函数如下定义
M S E = M S E 0 + M S E b + M S E f \begin{align} \begin{aligned} MSE = MSE_0 + MSE_b + MSE_f \\ \end{aligned} \end{align} MSE=MSE0+MSEb+MSEf
其中
M S E 0 = 1 N 0 ∑ i = 1 N 0 ∣ h ( 0 , x 0 i ) − h 0 i ∣ 2 M S E b = 1 N b ∑ i = 1 N b ( ∣ h i ( t b i , − 5 ) − h i ( t b i , 5 ) ∣ 2 + ∣ h x i ( t b i , − 5 ) − h x i ( t b i , 5 ) ∣ 2 ) M S E f = 1 N f ∑ i = 1 N f ∣ f ( t f i , x f i ) ∣ 2 \begin{align} \begin{aligned} MSE_0 &= \frac{1}{N_0}\sum_{i=1}^{N_0}|h(0,x_0^i)-h_0^i|^2 \\ MSE_b &= \frac{1}{N_b}\sum_{i=1}^{N_b}(|h^i(t_b^i,-5)-h^i(t_b^i,5)|^2+|h^i_x(t_b^i,-5)-h^i_x(t_b^i,5)|^2) \\ MSE_f &= \frac{1}{N_f}\sum_{i=1}^{N_f}|f(t_f^i,x_f^i)|^2 \\ \end{aligned} \end{align} MSE0MSEbMSEf=N01i=1∑N0∣h(0,x0i)−h0i∣2=Nb1i=1∑Nb(∣hi(tbi,−5)−hi(tbi,5)∣2+∣hxi(tbi,−5)−hxi(tbi,5)∣2)=Nf1i=1∑Nf∣f(tfi,xfi)∣2
这里 M S E 0 MSE_0 MSE0是初始条件损失函数, M S E b MSE_b MSEb是周期条件损失函数, M S E f MSE_f MSEf是偏微分方程构造的损失函数。
由于 h ( t , x ) = u ( t , x ) + i v ( t , x ) h(t,x)=u(t,x)+iv(t,x) h(t,x)=u(t,x)+iv(t,x),在代码实现过程中,损失函数具体形式如下:
l = l 1 + l 2 + l 3 + l 4 + l 5 + l 6 + l 7 + l 8 \begin{align} \begin{aligned} l = l_1 + l_2 + l_3 + l_4 + l_5 + l_6 + l_7 + l_8 \end{aligned} \end{align} l=l1+l2+l3+l4+l5+l6+l7+l8
其中
l 1 = 1 N 0 ∑ i = 1 N 0 ∣ u ( 0 , x 0 i ) − u 0 i ∣ 2 l 2 = 1 N 0 ∑ i = 1 N 0 ∣ v ( 0 , x 0 i ) − v 0 i ∣ 2 l 3 = 1 N b ∑ i = 1 N b ∣ u i ( t b i , − 5 ) − u i ( t b i , 5 ) ∣ 2 l 4 = 1 N b ∑ i = 1 N b ∣ v i ( t b i , − 5 ) − v i ( t b i , 5 ) ∣ 2 l 5 = 1 N b ∑ i = 1 N b ∣ u x i ( t b i , − 5 ) − u x i ( t b i , 5 ) ∣ 2 l 6 = 1 N b ∑ i = 1 N b ∣ v x i ( t b i , − 5 ) − v x i ( t b i , 5 ) ∣ 2 l 7 = 1 N f ∑ i = 1 N f ∣ u t + 0.5 ∗ v x x + ( u 2 + v 2 ) ∗ v ∣ 2 l 8 = 1 N f ∑ i = 1 N f ∣ v t + 0.5 ∗ u x x + ( u 2 + v 2 ) ∗ u ∣ 2 \begin{align} \begin{aligned} l_1 &= \frac{1}{N_0}\sum_{i=1}^{N_0}|u(0,x_0^i)-u_0^i|^2 \\ l_2 &= \frac{1}{N_0}\sum_{i=1}^{N_0}|v(0,x_0^i)-v_0^i|^2 \\ l_3 &= \frac{1}{N_b}\sum_{i=1}^{N_b}|u^i(t_b^i,-5)-u^i(t_b^i,5)|^2 \\ l_4 &= \frac{1}{N_b}\sum_{i=1}^{N_b}|v^i(t_b^i,-5)-v^i(t_b^i,5)|^2 \\ l_5 &= \frac{1}{N_b}\sum_{i=1}^{N_b}|u^i_x(t_b^i,-5)-u^i_x(t_b^i,5)|^2 \\ l_6 &= \frac{1}{N_b}\sum_{i=1}^{N_b}|v^i_x(t_b^i,-5)-v^i_x(t_b^i,5)|^2 \\ l_7 &= \frac{1}{N_f}\sum_{i=1}^{N_f}|u_t + 0.5 *v _{xx} + (u^2+v^2)*v|^2 \\ l_8 &= \frac{1}{N_f}\sum_{i=1}^{N_f}|v_t + 0.5 *u _{xx} + (u^2+v^2)*u|^2 \\ \end{aligned} \end{align} l1l2l3l4l5l6l7l8=N01i=1∑N0∣u(0,x0i)−u0i∣2=N01i=1∑N0∣v(0,x0i)−v0i∣2=Nb1i=1∑Nb∣ui(tbi,−5)−ui(tbi,5)∣2=Nb1i=1∑Nb∣vi(tbi,−5)−vi(tbi,5)∣2=Nb1i=1∑Nb∣uxi(tbi,−5)−uxi(tbi,5)∣2=Nb1i=1∑Nb∣vxi(tbi,−5)−vxi(tbi,5)∣2=Nf1i=1∑Nf∣ut+0.5∗vxx+(u2+v2)∗v∣2=Nf1i=1∑Nf∣vt+0.5∗uxx+(u2+v2)∗u∣2
这里 N 0 = N b = 50 , N f = 20000. N_0=N_b=50,N_f=20000. N0=Nb=50,Nf=20000. 其中 u 0 i , v 0 i u_0^i,v_0^i u0i,v0i为谱方法计算出来的真解,其它均为神经网络输出值。
3. 代码
代码参考下图进行理解。

代码参考https://github.com/maziarraissi/PINNs,原代码运行框架tensorflow1,这里将其改为tensorflow2上运行,代码如下:
"""
@author: Maziar Raissi
@Annotator:ST
利用谱方法计算了t*x为[0,pi/2]*[-5,5]区域上的真解,真解个数t*x为201*256
"""
import sys
sys.path.insert(0, '../../Utilities/')
import tensorflow.compat.v1 as tf # tensorflow1.0代码迁移到2.0上运行,加上这两行
tf.disable_v2_behavior()
import tensorflow as tf2
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
from scipy.interpolate import griddata
from pyDOE import lhs # 拉丁超立方采样
from plotting import newfig, savefig
from mpl_toolkits.mplot3d import Axes3D
import time
import matplotlib.gridspec as gridspec
from mpl_toolkits.axes_grid1 import make_axes_locatable
np.random.seed(1234)
tf.random.set_random_seed(1234) # tf.random.set_seed
class PhysicsInformedNN:
# Initialize the class
def __init__(self, x0, u0, v0, tb, X_f, layers, lb, ub):
"""
由损失函数可以看出,周期性边界不需要真解,仅初始条件需要真解,就可以求解
:param x0: 左边界N0个点x值
:param u0: 左边界N0个点对应解的实部
:param v0: 左边界N0个点对应解的虚部
:param tb: 周期边界Nb个点t值
:param X_f: 在区域[0,pi/2]*[-5,5]内采用拉丁超立方采样得到的Nf个点的坐标值
:param layers: 神经网络各层神经元列表
:param lb: np.array([-5.0, 0.0])
:param ub: np.array([5.0, np.pi/2])
"""
X0 = np.concatenate((x0, 0*x0), 1) # 左边界坐标点(x,0)
X_lb = np.concatenate((0*tb + lb[0], tb), 1) # 下边界坐标点(-5,t)
X_ub = np.concatenate((0*tb + ub[0], tb), 1) # 上边界坐标点(5,t)
self.lb = lb
self.ub = ub
self.x0 = X0[:,0:1]
self.t0 = X0[:,1:2]
self.x_lb = X_lb[:,0:1]
self.t_lb = X_lb[:,1:2]
self.x_ub = X_ub[:,0:1]
self.t_ub = X_ub[:,1:2]
self.x_f = X_f[:,0:1]
self.t_f = X_f[:,1:2]
self.u0 = u0
self.v0 = v0
# Initialize NNs
self.layers = layers
self.weights, self.biases = self.initialize_NN(layers)
# tf Placeholders
self.x0_tf = tf.placeholder(tf.float32, shape=[None, self.x0.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.t0_tf = tf.placeholder(tf.float32, shape=[None, self.t0.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.u0_tf = tf.placeholder(tf.float32, shape=[None, self.u0.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.v0_tf = tf.placeholder(tf.float32, shape=[None, self.v0.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.x_lb_tf = tf.placeholder(tf.float32, shape=[None, self.x_lb.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.t_lb_tf = tf.placeholder(tf.float32, shape=[None, self.t_lb.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.x_ub_tf = tf.placeholder(tf.float32, shape=[None, self.x_ub.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.t_ub_tf = tf.placeholder(tf.float32, shape=[None, self.t_ub.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.x_f_tf = tf.placeholder(tf.float32, shape=[None, self.x_f.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
self.t_f_tf = tf.placeholder(tf.float32, shape=[None, self.t_f.shape[1]]) # tf.placeholder改为tf.compat.v1.placeholder
# tf Graphs
self.u0_pred, self.v0_pred, _ , _ = self.net_uv(self.x0_tf, self.t0_tf) # 左边界
self.u_lb_pred, self.v_lb_pred, self.u_x_lb_pred, self.v_x_lb_pred = self.net_uv(self.x_lb_tf, self.t_lb_tf) # 下边界
self.u_ub_pred, self.v_ub_pred, self.u_x_ub_pred, self.v_x_ub_pred = self.net_uv(self.x_ub_tf, self.t_ub_tf) # 上边界
self.f_u_pred, self.f_v_pred = self.net_f_uv(self.x_f_tf, self.t_f_tf)
# Loss
self.loss = tf.reduce_mean(tf.square(self.u0_tf - self.u0_pred)) + \
tf.reduce_mean(tf.square(self.v0_tf - self.v0_pred)) + \
tf.reduce_mean(tf.square(self.u_lb_pred - self.u_ub_pred)) + \
tf.reduce_mean(tf.square(self.v_lb_pred - self.v_ub_pred)) + \
tf.reduce_mean(tf.square(self.u_x_lb_pred - self.u_x_ub_pred)) + \
tf.reduce_mean(tf.square(self.v_x_lb_pred - self.v_x_ub_pred)) + \
tf.reduce_mean(tf.square(self.f_u_pred)) + \
tf.reduce_mean(tf.square(self.f_v_pred))
# MSE0|u|^2 + MSE0|v|^2 +
# MSEb|u(-5)-u(5)|^2 + MSEb|v(-5)-v(5)|^2 +
# MSEb|u_x(-5)-u_x(5)|^2 + MSEb|v_x(-5)-v_x(5)|^2
# MSEf|u|^2 + MSEf|v|^2
# 获取损失函数历史记录
# self.optimizer = tf.contrib.opt.ScipyOptimizerInterface(self.loss, # 将tf.contrib.opt改为tf.compat.v1.estimator.opt
# method = 'L-BFGS-B',
# options = {'maxiter': 50000,
# 'maxfun': 50000,
# 'maxcor': 50,
# 'maxls': 50,
# 'ftol' : 1.0 * np.finfo(float).eps})
self.optimizer_Adam = tf.train.AdamOptimizer()
self.train_op_Adam = self.optimizer_Adam.minimize(self.loss) # 反向传播算法更新权重和偏置
# tf session
self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=True))
init = tf.global_variables_initializer()
self.sess.run(init)
def initialize_NN(self, layers):
"""
初始化网络权重和偏置参数
:param layers: eg.[2, 100, 100, 100, 100, 2]
:return:
"""
weights = []
biases = []
num_layers = len(layers)
for l in range(0,num_layers-1):
W = self.xavier_init(size=[layers[l], layers[l+1]])
b = tf.Variable(tf.zeros([1,layers[l+1]], dtype=tf.float32), dtype=tf.float32)
weights.append(W)
biases.append(b)
return weights, biases
def xavier_init(self, size):
"""
正态分布初始化权重
tf.compat.v1.random.truncated_normal(维度,正态分布均值,正态分布标准差):截断的产生正态分布的随机数,即随机数与均值的差值若大于两倍的标准差,则重新生成。
:param size:
:return:
"""
in_dim = size[0]
out_dim = size[1]
xavier_stddev = np.sqrt(2/(in_dim + out_dim))
# return tf.Variable(tf.truncated_normal([in_dim, out_dim], stddev=xavier_stddev), dtype=tf.float32)
return tf.Variable(tf.compat.v1.random.truncated_normal([in_dim, out_dim], stddev=xavier_stddev), dtype=tf.float32)
def neural_net(self, X, weights, biases):
"""
:param X: 输入(x,t)
:param weights: 模型权重
:param biases: 模型偏置
:return: 返回(u,v),其中u为真解实部,v为真解虚部
"""
num_layers = len(weights) + 1
H = 2.0*(X - self.lb)/(self.ub - self.lb) - 1.0
for l in range(0,num_layers-2):
W = weights[l]
b = biases[l]
H = tf.tanh(tf.add(tf.matmul(H, W), b))
W = weights[-1]
b = biases[-1]
Y = tf.add(tf.matmul(H, W), b)
return Y
def net_uv(self, x, t):
X = tf.concat([x,t],1)
uv = self.neural_net(X, self.weights, self.biases)
u = uv[:,0:1]
v = uv[:,1:2]
u_x = tf.gradients(u, x)[0]
v_x = tf.gradients(v, x)[0]
return u, v, u_x, v_x
def net_f_uv(self, x, t):
u, v, u_x, v_x = self.net_uv(x,t)
u_t = tf.gradients(u, t)[0]
u_xx = tf.gradients(u_x, x)[0]
v_t = tf.gradients(v, t)[0]
v_xx = tf.gradients(v_x, x)[0]
f_u = u_t + 0.5*v_xx + (u**2 + v**2)*v
f_v = v_t - 0.5*u_xx - (u**2 + v**2)*u
return f_u, f_v
def callback(self, loss):
print('Loss:', loss)
def train(self, nIter):
tf_dict = {
self.x0_tf: self.x0, self.t0_tf: self.t0,
self.u0_tf: self.u0, self.v0_tf: self.v0,
self.x_lb_tf: self.x_lb, self.t_lb_tf: self.t_lb,
self.x_ub_tf: self.x_ub, self.t_ub_tf: self.t_ub,
self.x_f_tf: self.x_f, self.t_f_tf: self.t_f}
start_time = time.time()
for it in range(nIter):
self.sess.run(self.train_op_Adam, tf_dict)
# Print
if it % 10 == 0:
elapsed = time.time() - start_time
loss_value = self.sess.run(self.loss, tf_dict)
print('It: %d, Loss: %.3e, Time: %.2f' %
(it, loss_value, elapsed))
start_time = time.time()
# self.optimizer.minimize(self.sess,
# feed_dict = tf_dict,
# fetches = [self.loss],
# loss_callback = self.callback)
#
def predict(self, X_star):
"""
:param X_star: 真解坐标值(x,y)
:return:
"""
tf_dict = {
self.x0_tf: X_star[:,0:1], self.t0_tf: X_star[:,1:2]}
u_star = self.sess.run(self.u0_pred, tf_dict) # 执行sess.run()时,tensorflow并不是计算了整个图,只是计算了与想要fetch的值相关的部分。
u_star = self.sess.run(self.v0_pred, tf_dict) # 这里u_star、u_star是h(t,x)=u(t,x)+iv(t,x)
tf_dict = {
self.x_f_tf: X_star[:,0:1], self.t_f_tf: X_star[:,1:2]}
f_u_star = self.sess.run(self.f_u_pred, tf_dict) # 这里f_u_star是u_t + 0.5*v_xx + (u**2 + v**2)*v
f_v_star = self.sess.run(self.f_v_pred, tf_dict) # 这里f_v_star是v_t - 0.5*u_xx - (u**2 + v**2)*u
return u_star, v_star, f_u_star, f_v_star
if __name__ == "__main__":
noise = 0.0
# Doman bounds
lb = np.array([-5.0, 0.0])
ub = np.array([5.0, np.pi/2])
N0 = 50
N_b = 50
N_f = 20000
layers = [2, 100, 100, 100, 100, 2]
data = scipy.io.loadmat('../Data/NLS.mat')
t = data['tt'].flatten()[:,None] # (201,1)
x = data['x'].flatten()[:,None] # (256,1)
Exact = data['uu'] # (256,201)
Exact_u = np.real(Exact) # (256,201)
Exact_v = np.imag(Exact) # (256,201)
Exact_h = np.sqrt(Exact_u**2 + Exact_v**2)
X, T = np.meshgrid(x,t)
X_star = np.hstack((X.flatten()[:,None], T.flatten()[:,None]))
u_star = Exact_u.T.flatten()[:,None]
v_star = Exact_v.T.flatten()[:,None]
h_star = Exact_h.T.flatten()[:,None]
###########################
idx_x = np.random.choice(x.shape[0], N0, replace=False) # 从0-256中选取N0个整数
x0 = x[idx_x,:] # (50,1)
u0 = Exact_u[idx_x,0:1] # (50,1)
v0 = Exact_v[idx_x,0:1] # (50,1)
idx_t = np.random.choice(t.shape[0], N_b, replace=False)
tb = t[idx_t,:] # (50,1)
X_f = lb + (ub-lb)*lhs(2, N_f) # (20000,2) # lhs(因子数,采样数)
"""
lhs(因子数,采样数):拉丁超立方采样,若因子数为2,默认取样空间是[0,1]*[0,1]
这里通过(-5,0)+(10,pi/2)*lhs(2, N_f)可以改变取样空间
"""
model = PhysicsInformedNN(x0, u0, v0, tb, X_f, layers, lb, ub)
start_time = time.time()
model.train(50000)
elapsed = time.time() - start_time
print('Training time: %.4f' % (elapsed))
u_pred, v_pred, f_u_pred, f_v_pred = model.predict(X_star)
h_pred = np.sqrt(u_pred**2 + v_pred**2)
error_u = np.linalg.norm(u_star-u_pred,2)/np.linalg.norm(u_star,2) # np.linalg.norm求2范数
error_v = np.linalg.norm(v_star-v_pred,2)/np.linalg.norm(v_star,2)
error_h = np.linalg.norm(h_star-h_pred,2)/np.linalg.norm(h_star,2)
print('Error u: %e' % (error_u))
print('Error v: %e' % (error_v))
print('Error h: %e' % (error_h))
U_pred = griddata(X_star, u_pred.flatten(), (X, T), method='cubic') # (201,256)
V_pred = griddata(X_star, v_pred.flatten(), (X, T), method='cubic')
H_pred = griddata(X_star, h_pred.flatten(), (X, T), method='cubic')
FU_pred = griddata(X_star, f_u_pred.flatten(), (X, T), method='cubic')
FV_pred = griddata(X_star, f_v_pred.flatten(), (X, T), method='cubic')
######################################################################
############################# Plotting ###############################
######################################################################
X0 = np.concatenate((x0, 0*x0), 1)
X_lb = np.concatenate((0*tb + lb[0], tb), 1)
X_ub = np.concatenate((0*tb + ub[0], tb), 1)
X_u_train = np.vstack([X0, X_lb, X_ub])
fig, ax = newfig(1.0, 0.9)
ax.axis('off')
####### Row 0: h(t,x) ##################
gs0 = gridspec.GridSpec(1, 2)
gs0.update(top=1-0.06, bottom=1-1/3, left=0.15, right=0.85, wspace=0)
ax = plt.subplot(gs0[:, :])
h = ax.imshow(H_pred.T, interpolation='nearest', cmap='YlGnBu',
extent=[lb[1], ub[1], lb[0], ub[0]],
origin='lower', aspect='auto')
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.05)
fig.colorbar(h, cax=cax)
ax.plot(X_u_train[:,1], X_u_train[:,0], 'kx', label = 'Data (%d points)' % (X_u_train.shape[0]), markersize = 4, clip_on = False)
line = np.linspace(x.min(), x.max(), 2)[:,None]
ax.plot(t[75]*np.ones((2,1)), line, 'k--', linewidth = 1)
ax.plot(t[100]*np.ones((2,1)), line, 'k--', linewidth = 1)
ax.plot(t[125]*np.ones((2,1)), line, 'k--', linewidth = 1)
ax.set_xlabel('$t$')
ax.set_ylabel('$x$')
leg = ax.legend(frameon=False, loc = 'best')
# plt.setp(leg.get_texts(), color='w')
ax.set_title('$|h(t,x)|$', fontsize = 10)
####### Row 1: h(t,x) slices ##################
gs1 = gridspec.GridSpec(1, 3)
gs1.update(top=1-1/3, bottom=0, left=0.1, right=0.9, wspace=0.5)
ax = plt.subplot(gs1[0, 0])
ax.plot(x,Exact_h[:,75], 'b-', linewidth = 2, label = 'Exact')
ax.plot(x,H_pred[75,:], 'r--', linewidth = 2, label = 'Prediction')
ax.set_xlabel('$x$')
ax.set_ylabel('$|h(t,x)|$')
ax.set_title('$t = %.2f$' % (t[75]), fontsize = 10)
ax.axis('square')
ax.set_xlim([-5.1,5.1])
ax.set_ylim([-0.1,5.1])
ax = plt.subplot(gs1[0, 1])
ax.plot(x,Exact_h[:,100], 'b-', linewidth = 2, label = 'Exact')
ax.plot(x,H_pred[100,:], 'r--', linewidth = 2, label = 'Prediction')
ax.set_xlabel('$x$')
ax.set_ylabel('$|h(t,x)|$')
ax.axis('square')
ax.set_xlim([-5.1,5.1])
ax.set_ylim([-0.1,5.1])
ax.set_title('$t = %.2f$' % (t[100]), fontsize = 10)
ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.8), ncol=5, frameon=False)
ax = plt.subplot(gs1[0, 2])
ax.plot(x,Exact_h[:,125], 'b-', linewidth = 2, label = 'Exact')
ax.plot(x,H_pred[125,:], 'r--', linewidth = 2, label = 'Prediction')
ax.set_xlabel('$x$')
ax.set_ylabel('$|h(t,x)|$')
ax.axis('square')
ax.set_xlim([-5.1,5.1])
ax.set_ylim([-0.1,5.1])
ax.set_title('$t = %.2f$' % (t[125]), fontsize = 10)
# plt.show()
savefig('./figures/retest/reNLS')
4. 实验细节及复现结果
这里使用4层全连接神经网络,输入层和输出层各两个神经元,输入层两个神经元分别代表 x , t x,t x,t,输出层两个神经元分别代表 u ( x , t ) , v ( x , t ) u(x,t),v(x,t) u(x,t),v(x,t),隐藏层每层100个神经元。为了计算误差,作者提供了使用谱方法计算的 ( 256 ∗ 201 ) (256*201) (256∗201)个真解,其中第一维度代表空间 x x x,第二维度代表时间 t t t. 训练50000次之后输出结果如下:
It: 49990, Loss: 8.158e-05, Time: 0.38
Training time: 1970.0348
Error u: 1.154980e+00
Error v: 0.000000e+00
Error h: 4.879406e-01
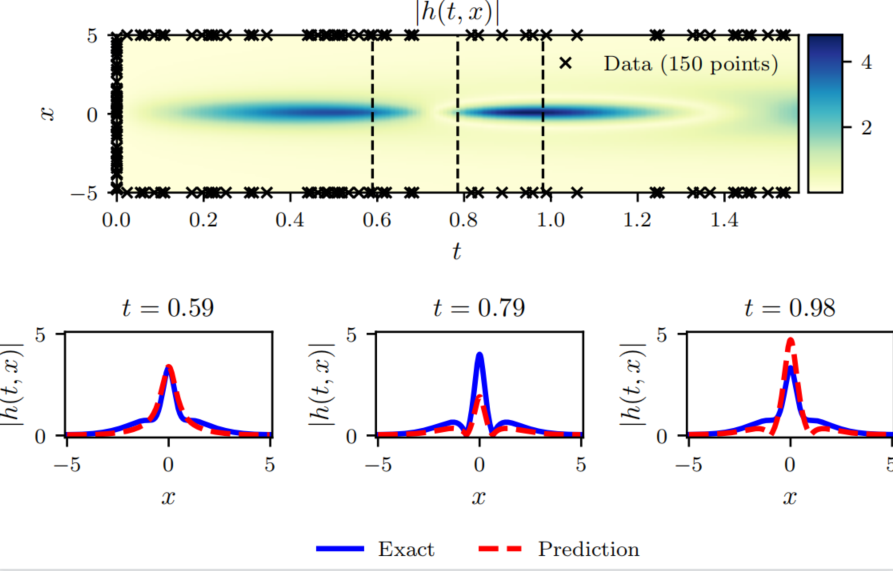
为了对比,下面是训练10000次的结果。
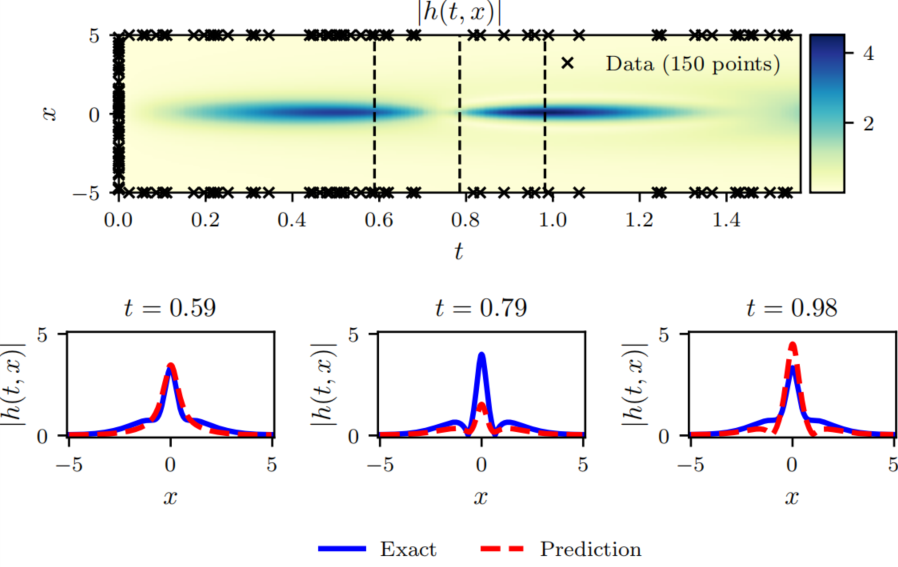
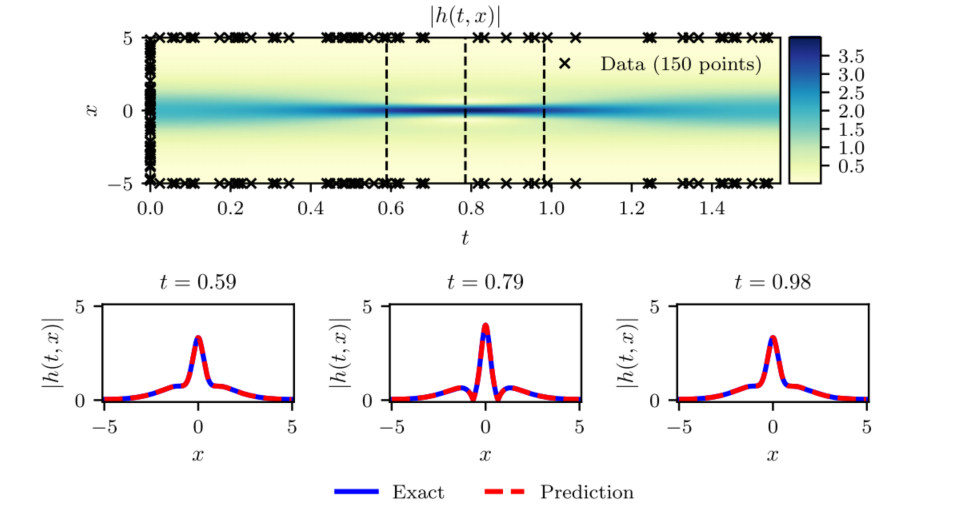
接下来是作者论文中的训练结果。
5. 可能遇到的问题
1. 若遇到以下问题,是由于matplotlib版本过高导致,具体解释见博客,我这里使用的matplotlib版本是3.4.3。
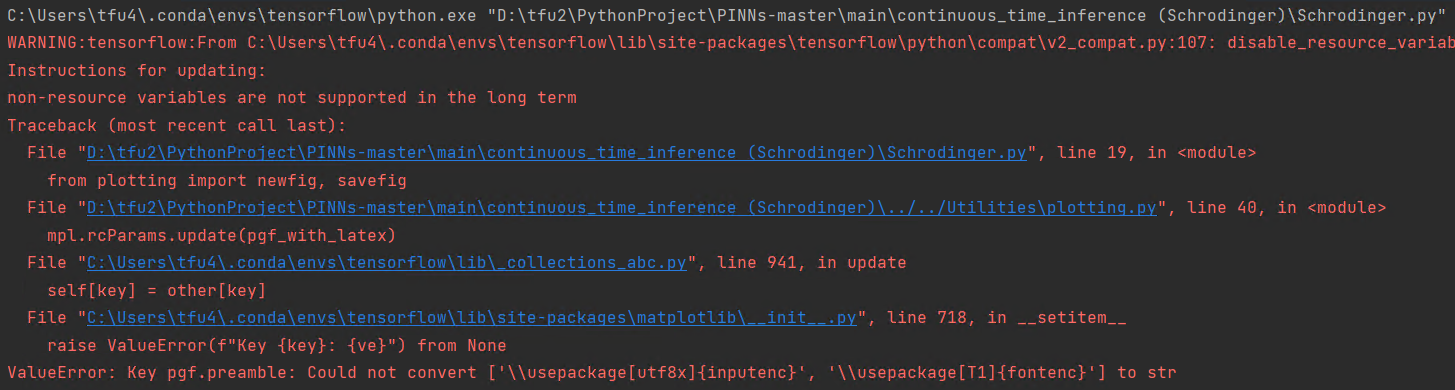
解决方法:
卸载使用虚拟环境中的matplotlib,安装matplotlib v3.4.3版本。
pip uninstall matplotlib
pip install matplotlib==3.4.3
2. 若出现cannot import name ‘newfig’ from 'plotting’错误。
解决方法:
见评论。
3. 若出现如下问题:
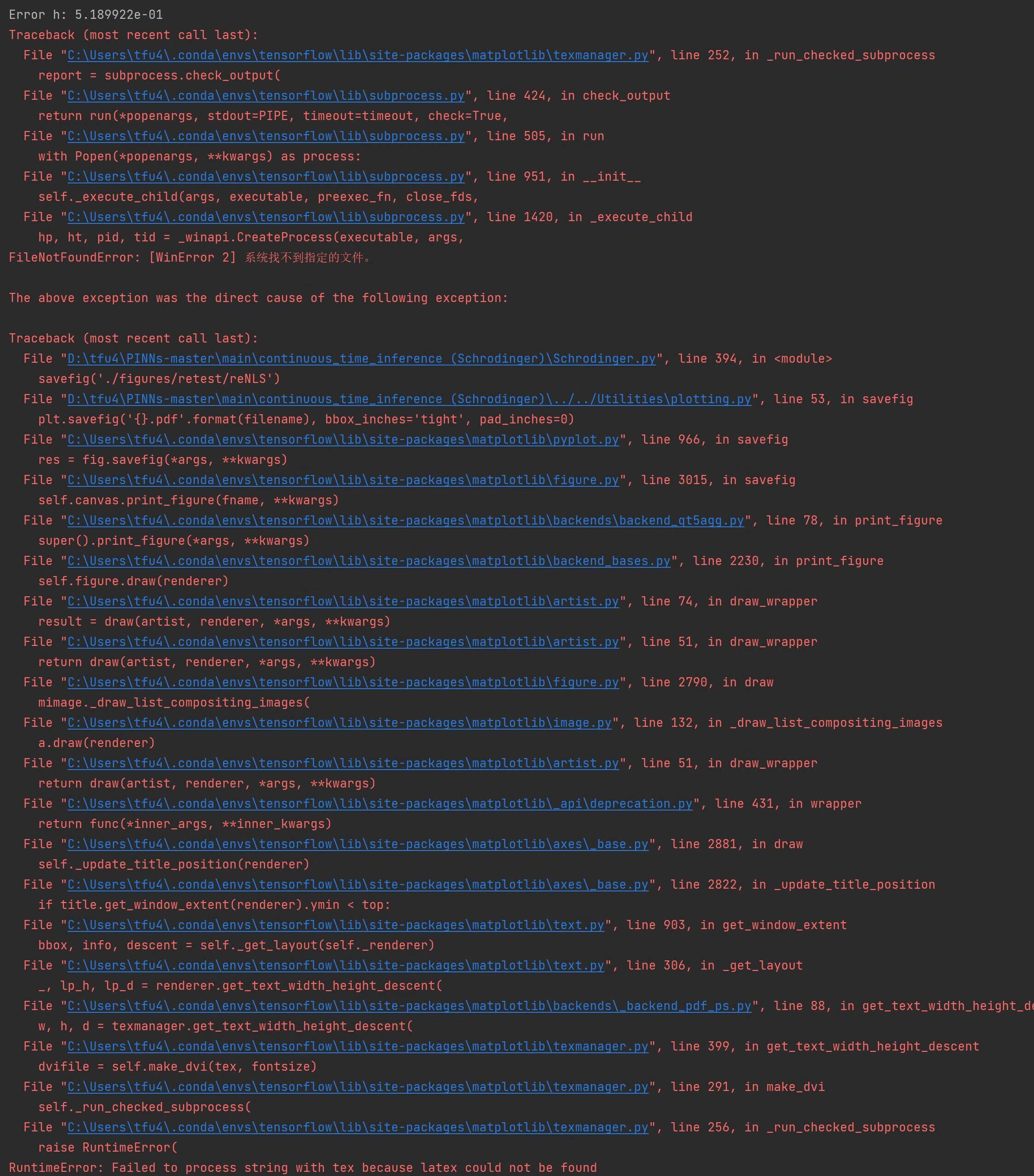
解决方法: 可以在代码导入包处加入以下两行代码。
import matplotlib as mpl
mpl.rcParams.update(mpl.rcParamsDefault)
参考资料
[1]. Physics-informed machine learning
