https://antkillerfarm.github.io/
折扣未来奖励(Discounted Future Reward)
为了获得更多的奖励,我们往往不能只看当前奖励,更要看将来的奖励。
给定一个MDP周期,总的奖励显然为:
那么,从当前时间t开始,总的将来的奖励为:
但是Environment往往是随机的,执行特定的动作不一定得到特定的状态,因此将来的奖励所占的权重要依次递减,因此使用discounted future reward代替:
这里 是0和1之间的折扣因子——越是未来的奖励,折扣越多,权重越小。而明显上式是个迭代过程,因此可以写作:
即当前时刻的奖励等于当前时刻的即时奖励加上下一时刻的奖励乘上折扣因子 。
如果 等于0,意味着只看当前奖励;
如果 等于1,意味着环境是确定的,相同的动作总会获得相同的奖励(也就是cyclic Markov processes)。
因此实际中 往往取类似0.9这样的值。因此我们的任务变成了找到一个策略,最大化将来的奖励R。
Policy, Value, Transition Model
增强学习中,比较重要的几个概念:
Policy就是我们的算法追求的目标,可以看做一个函数,在输入state的时候,能够返回此时应该执行的action或者action的概率分布。
Value,价值函数,表示在输入state,action的时候,能够返回在state下,执行这个action能得到的Discounted future reward的(期望)值。
Value function一般有两种。
state-value function:
action-value function:
后者由于和state、action都有关系,也被称作state-action pair value function。
Transition model是说环境本身的结构与特性:当在state执行action的时候,系统会进入的下一个state,也包括可能收到的reward。
很显然,以上三者互相关联:
如果能得到一个好的Policy function的话,那算法的目的已经达到了。
如果能得到一个好的Value function的话,那么就可以在这个state下,选取value值高的那个action,自然也是一个较好的策略。
如果能得到一个好的transition model的话,一方面,有可能可以通过这个transition model直接推演出最佳的策略;另一方面,也可以用来指导policy function或者value function 的学习过程。
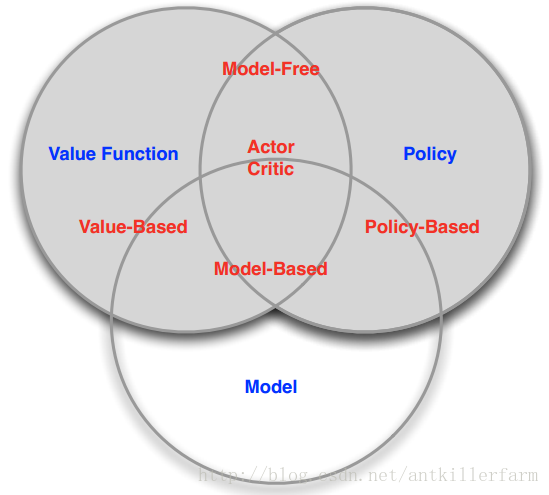
因此,增强学习的方法,大体可以分为三类:
Value-based RL,值方法。显式地构造一个model来表示值函数Q,找到最优策略对应的Q函数,自然就找到了最优策略。
Policy-based RL,策略方法。显式地构造一个model来表示策略函数,然后去寻找能最大化discounted future reward。
Model-based RL,基于环境模型的方法。先得到关于environment transition的model,然后再根据这个model去寻求最佳的策略。
以上三种方法并不是一个严格的划分,很多RL算法同时具有一种以上的特性。
参考
https://mp.weixin.qq.com/s/f6sq8cSaU1cuzt7jhsK8Ig
强化学习(Reinforcement Learning)基础介绍
https://mp.weixin.qq.com/s/TGN6Zhrea2LPxdkspVTlAw
穆黎森:算法工程师入门——增强学习
https://mp.weixin.qq.com/s/laKJ_jfNR5L1uMML9wkS1A
强化学习(Reinforcement Learning)算法基础及分类
https://mp.weixin.qq.com/s/Cvk_cePK9iQd8JIKKDDrmQ
强化学习的核心基础概念及实现
http://mp.weixin.qq.com/s/gHM7qh7UTKzatdg34cgfDQ
强化学习全解
https://mp.weixin.qq.com/s/B6ZpJ0Yw9GBZ9_MyNwjlXQ
构建强化学习系统,你需要先了解这些背景知识
https://mp.weixin.qq.com/s/AKuuIJnESMmck8k210CnWg
易忽略的强化学习知识之基础知识及MDP(上)
https://mp.weixin.qq.com/s/phuCKNj_a4CPq6w51Md-9A
易忽略的强化学习知识之基础知识及MDP(下)
https://mp.weixin.qq.com/s/QHAnpGsr1sSaUgOXTJjVjQ
李飞飞高徒带你一文读懂RL来龙去脉
https://mp.weixin.qq.com/s/iN8q24ka762LqY74zoVFsg
3万字剖析强化学习在电商环境下应用