1 背景
常见的深度学习OCR过程中,会把文本检测与文本识别拆分成两个部分,通过先检测后识别的方法对图片中的文本进行OCR识别。
FOTS是一个快速的端到端的集成检测+识别的框架,和其他two-stage的方法相比,FOTS具有更快的速度。FOTS通过共享训练特征,互补监督,从而压缩了特征提取所占用的时间。
2 网络结构
 FOTS的整体结构由四部分组成。分别是:卷积共享特征(shared convolutions),文本检测分支(the text detection branch), RoIRotate操作(RoIRotate operation),文本识别分支(the text recognition branch)。
FOTS的整体结构由四部分组成。分别是:卷积共享特征(shared convolutions),文本检测分支(the text detection branch), RoIRotate操作(RoIRotate operation),文本识别分支(the text recognition branch)。
2.1 卷积共享
共享网络的主干是 ResNet-50。 受FPN的启发,我们连接了低级特征映射和高级语义特征映射。 共享卷积产生的特征图的分辨率是输入图像的1/4。
 FOTS的基础网络结构为ResNet-50,共享卷积层采用了类似U-net的卷积的共享方法,将底层和高层的特征进行了融合。这部分和EAST中的特征共享方式一样。最终输出的特征图大小为原图的1/4。
FOTS的基础网络结构为ResNet-50,共享卷积层采用了类似U-net的卷积的共享方法,将底层和高层的特征进行了融合。这部分和EAST中的特征共享方式一样。最终输出的特征图大小为原图的1/4。
2.2 文本检测分支
受EAST与DDRN的启发,我们采用完全卷积网络作为文本检测器。 由于自然场景图像中有许多小文本框,我们将共享卷积中原始输入图像的1/32到1/4大小的特征映射放大。 在提取共享特征之后,应用一个转换来输出密集的每像素的单词预测。 第一个通道计算每个像素为正样本的概率。 与EAST类似,原始文本区域的缩小版本中的像素被认为是正的。 对于每个正样本,以下4个通道预测其到包含此像素的边界框的顶部,底部,左侧,右侧的距离,最后一个通道预测相关边界框的方向。 通过对这些正样本应用阈值和NMS产生最终检测结果。
这一部分与EAST相同。损失函数包括了分类的loss(Cross Entropy Loss)和坐标的回归的loss(IOU Loss)。实验中的平衡因子,λreg =1。
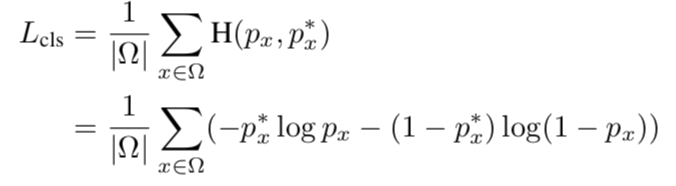
2.3 RoIRotate操作
这一部分的主要功能,将有角度的文本块,经过仿射变换,转化为正常的轴对齐的文本块。
在这项工作中,我们修正输出高度并保持纵横比不变以处理文本长度的变化。对比RRoI,其通过最大池化将旋转的区域转换为固定大小的区域,而本文使用双线性插值来计算输出的值。避免了RoI与提取特征不对准,使得输出特征的长度可变,更加适用于文本识别。
这个过程分为两个步骤:
①通过文本提议的预测或ground truth坐标计算仿射变换参数。
②将仿射变换分别应用于每个区域的共享特征映射,并获得文本区域的正常情况下水平的特征映射。
第①步中的计算:
 M:仿射变换矩阵,包含旋转,缩放,平移
M:仿射变换矩阵,包含旋转,缩放,平移
Ht:仿射变换后的特征图的高度,实验中为8
wt:仿射变换后的特征图的宽度
(x,y):特征图中的点的位置
(t; b; l; r) :特征图中的点距离旋转的框的上下左右的距离
θ:检测框的角度
第②步中的计算:
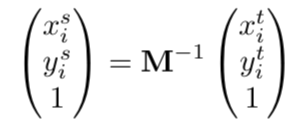
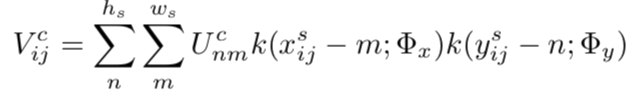 Vcij:在位置(i,j),通道c处的输出值。
Vcij:在位置(i,j),通道c处的输出值。
Ucnm:在位置(i,j),通道c处的输入值。
hs:输入的高度
ws:输入的宽度
Φx, Φy :双线性插值的核的参数
2.4 文本识别分支
文本识别分支旨在使用由共享卷积提取并由RoIRotate转换的区域特征来预测文本标签。 考虑到文本区域中标签序列的长度,LSTM的输入特征沿着宽度轴通过原始图像的共享卷积仅减少两次。 否则,将消除紧凑文本区域中的可辨别特征,尤其是窄形字符的特征。 我们的文本识别分支包括类似VGG的顺序卷积,仅沿高度轴减少的汇集,一个双向LSTM,一个完全连接和最终的CTC解码器。
这一部分主要是与CRNN类似,结构如下图所示。
 FOTS最终的损失函数是检测+识别的loss,λrecog=1。
FOTS最终的损失函数是检测+识别的loss,λrecog=1。
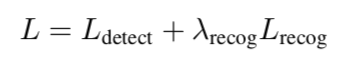
3 优点
FOTS一个检测+识别一体化的框架,具有模型小,速度快,精度高,支持多角度等特点。大大减少了这四种类型的错误(Miss:遗漏了一些文本区域;False:将一些非文本区域错误地视为文本区域;Split:错误地将整个文本区域拆分为多个单独的部分;Merge :错误地将几个独立的文本区域合并在一起)。