文章目录
前言
虽然在大部分情况下我们不需要自己去写正则表达式,但是我们还是需要看懂别人写的正则表达式以及根据需求能够自己写出一写正则表达式,所以我觉得还是很有必要去整理一下这方面的内容。
一、概述
为什么要使用正则表达式?
典型的搜索和替换操作要求提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。在这种情况下,可以使用正则表达式来搜索和替换标记。
正则表达式:就是一个包含某些规则的字符串,用来对其他的字符串进行校验,校验其他的字符串是否满足正则表达式的规则需求。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
实用工具:
二、常用语法
1. 普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
| 字符 | 描述 | 实例 |
|---|---|---|
[ABC] |
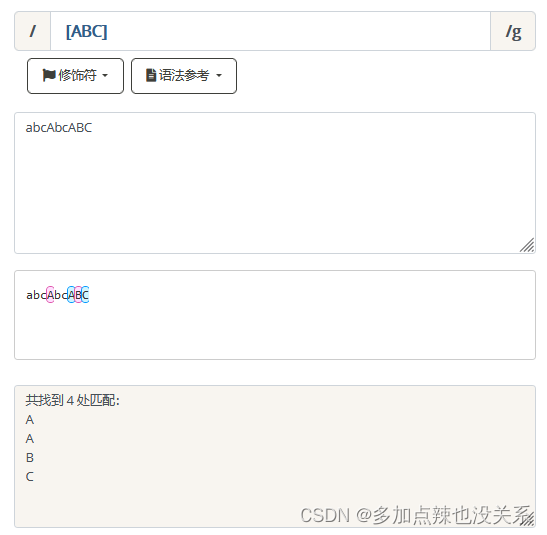
匹配 […] 中的所有字符,代表A或者B,或者C字符中的一个。 | 示例 |
[^ABC] |
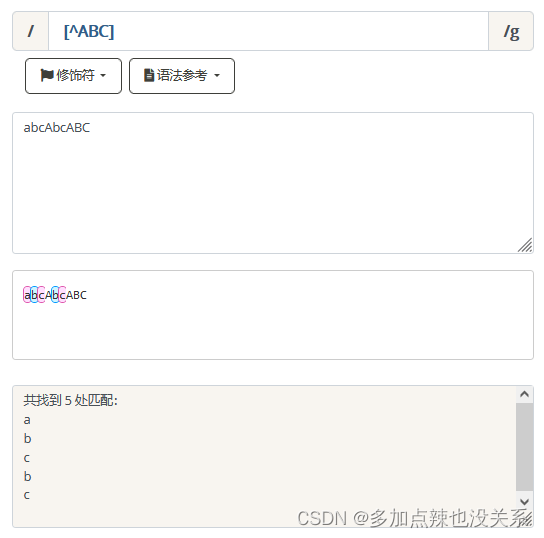
匹配除了 […] 中字符的所有字符,代表除 A,B,C 以外的任何字符。 | 示例 |
[A-Z] |
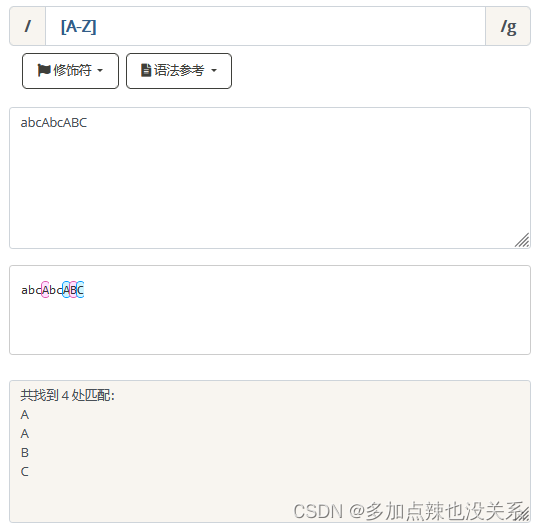
表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 |
示例 |
[0-9] |
表示一个区间,代表 0-9 之间的某一个数字字符。 | 示例 |
[a-zA-Z0-9] |
代表 a-z 或者A-Z 或者 0-9 之间的任意一个字符。 | 示例 |
[\s\S] |
匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 | 示例 |
2. 预定义字符
| 字符 | 描述 | 实例 |
|---|---|---|
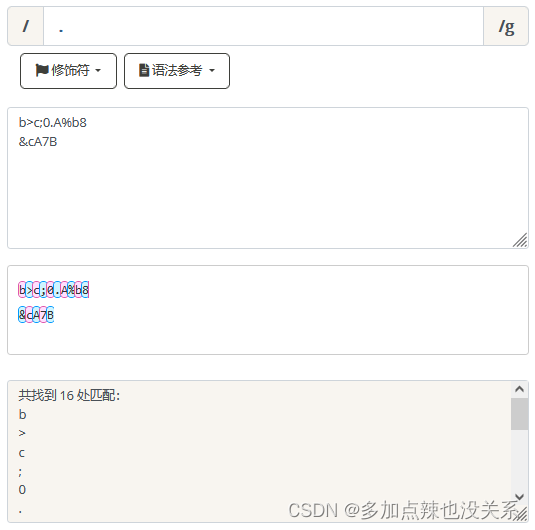
. |
匹配除换行符(\n、\r)之外的任何单个字符,等价于 [^\n\r]。 |
示例 |
\w |
匹配字母、数字、下划线。等价于 [A-Za-z0-9_]。 |
示例 |
\W |
匹配非字母、数字、下划线。等价于 [^A-Za-z0-9_]。 |
示例 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
示例 |
\S |
匹配所有非空白符。等价于 [^\s] 或者 [^ \f\n\r\t\v] |
示例 |
\d |
匹配任何数字,等价于 [0-9]。 |
示例 |
\D |
匹配任何非数字,等价于 [^0-9]。 |
示例 |
\cx |
匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
|
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
|
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
|
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
|
\t |
匹配一个制表符。等价于 \x09 和 \cI。 |
|
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
3. 特殊字符
所谓特殊字符,就是一些有特殊含义的字符。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符 \ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 字符 | 描述 | 实例 |
|---|---|---|
$ |
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 \$。 |
|
\ |
转义字符,将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。‘\n’ 匹配换行符。序列 ‘\’ 匹配 “”,而 ‘(’ 则匹配 “(”。 | |
( ) |
分组括号,标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
|
^ |
匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
|
{
|
标记限定符表达式的开始。要匹配 {,请使用 \{
。 |
|
[ |
标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
|
| |
替换,"或"操作,指明两项之间的一个选择。使得 “m |food” 匹配 “m” 或 “food” 。若要匹配 “mood” 或 “food”,请使用括号创建子表达式,从而产生(m|f)ood。 要匹配 |,请使用 \|。 |
|
*、+、? |
限定符中介绍… |
4. 限定符
| 字符 | 描述 | 实例 |
|---|---|---|
* |
匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,} |
|
+ |
匹配前面的子表达式一次或多次。例如,zo+ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
|
? |
匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 “do” 、 “does”、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
|
{n} |
n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 “Bob” 中的 o,但是能匹配 “food” 中的两个 o。 | |
{n,} |
n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 “Bob” 中的 o,但能匹配 “foooood” 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 | |
{n,m} |
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 “fooooood” 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
三、常用正则表达式
1. 校验数字的表达式
- 数字:
^[0-9]*$ - n位的数字:
^\d{n}$ - 至少n位的数字:
^\d{n,}$ - m-n位的数字:
^\d{m,n}$ - 零和非零开头的数字:
^(0|[1-9][0-9]*)$ - 非零开头的最多带两位小数的数字:
^([1-9][0-9]*)+(\.[0-9]{1,2})?$ - 带1-2位小数的正数或负数:
^(\-)?\d+(\.\d{1,2})$ - 正数、负数、和小数:
^(\-|\+)?\d+(\.\d+)?$ - 有两位小数的正实数:
^[0-9]+(\.[0-9]{2})?$ - 有1~3位小数的正实数:
^[0-9]+(\.[0-9]{1,3})?$ - 非零的正整数:
^[1-9]\d*$或^([1-9][0-9]*){1,3}$或^\+?[1-9][0-9]*$ - 非零的负整数:
^\-[1-9][]0-9"*$或^-[1-9]\d*$ - 非负整数:
^\d+$或^[1-9]\d*|0$ - 非正整数:
^-[1-9]\d*|0$或^((-\d+)|(0+))$ - 非负浮点数:
^\d+(\.\d+)?$或^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ - 非正浮点数:
^((-\d+(\.\d+)?)|(0+(\.0+)?))$或^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ - 正浮点数:
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$或^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ - 负浮点数:
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ - 浮点数:
^(-?\d+)(\.\d+)?$或^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
2. 校验字符的表达式
- 汉字:
^[\u4e00-\u9fa5]{0,}$ - 英文和数字:
^[A-Za-z0-9]+$或^[A-Za-z0-9]{4,40}$ - 长度为3-20的所有字符:
^.{3,20}$ - 由26个英文字母组成的字符串:
^[A-Za-z]+$ - 由26个大写英文字母组成的字符串:
^[A-Z]+$ - 由26个小写英文字母组成的字符串:
^[a-z]+$ - 由数字和26个英文字母组成的字符串:
^[A-Za-z0-9]+$ - 由数字、26个英文字母或者下划线组成的字符串:
^\w+$或^\w{3,20}$ - 中文、英文、数字包括下划线:
^[\u4E00-\u9FA5A-Za-z0-9_]+$ - 中文、英文、数字但不包括下划线等符号:
^[\u4E00-\u9FA5A-Za-z0-9]+$或^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$ - 可以输入含有
^%&',;=?$\"等字符:[^%&',;=?$\x22]+ - 禁止输入含有
~的字符:[^~]+
3. 特殊需求的表达式
- Email地址:
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ - 域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? - InternetURL:
[a-zA-z]+://[^\s]*或^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ - 手机号码:
^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$ - 电话号码(“XXX-XXXXXXX”、“XXXX-XXXXXXXX”、“XXX-XXXXXXX”、“XXX-XXXXXXXX”、"XXXXXXX"和"XXXXXXXX):
^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$ - 国内电话号码(0511-4405222、021-87888822):
\d{3}-\d{8}|\d{4}-\d{7} - 电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号):
((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$) - 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:
(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$) - 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ - 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):
^[a-zA-Z]\w{5,17}$ - 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$ - 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ - 日期格式:
^\d{4}-\d{1,2}-\d{1,2} - 一年的12个月(01~09和1~12):
^(0?[1-9]|1[0-2])$ - 一个月的31天(01~09和1~31):
^((0?[1-9])|((1|2)[0-9])|30|31)$ - xml文件:
^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$ - 中文字符的正则表达式:
[\u4e00-\u9fa5] - 双字节字符 (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)):
[^\x00-\xff] - 空白行的正则表达式 (可以用来删除空白行):
\n\s*\r - HTML标记的正则表达式:
<(\S*?)[^>]*>.*?|<.*? /> - 首尾空白字符的正则表达式 (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等):
^\s*|\s*$或(^\s*)|(\s*$) - 腾讯QQ号 (腾讯QQ号从10000开始):
[1-9][0-9]{4,} - 中国邮政编码 (中国邮政编码为6位数字):
[1-9]\d{5}(?!\d) - IPv4地址:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3} - 子网掩码:
((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)) - 校验日期 (“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年):
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ - 抽取 HTML 中的注释:
<!--(.*?)--> - 查找CSS属性:
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1} - 提取页面超链接:
(<a\\s*(?!.*\\brel=)[^>]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^" rel="external nofollow" ]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)> - 提取网页图片:
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*) - 提取网页颜色代码:
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$ - 文件 (.txt) 扩展名效验:
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"<>|]+\\.txt(l)?$ - 判断IE版本:
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
四、示例
匹配 […] 中的所有字符,代表A或者B,或者C字符中的一个。
匹配除了 […] 中字符的所有字符,代表除 A,B,C 以外的任何字符。
[A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。
[0-9] 表示一个区间,代表0-9之间的某一个数字字符。
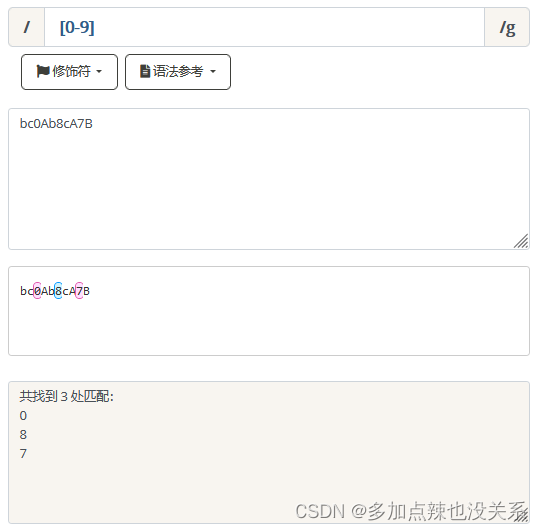
[0-9] 表示一个区间,代表0-9之间的某一个数字字符。
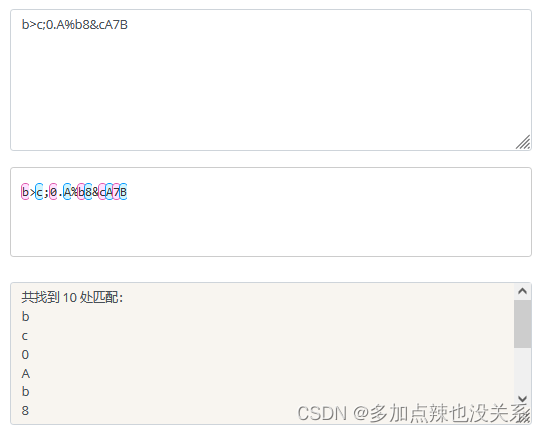
匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。
匹配字母、数字、下划线。等价于 [A-Za-z0-9_]。
匹配非字母、数字、下划线。等价于 [^A-Za-z0-9_]。
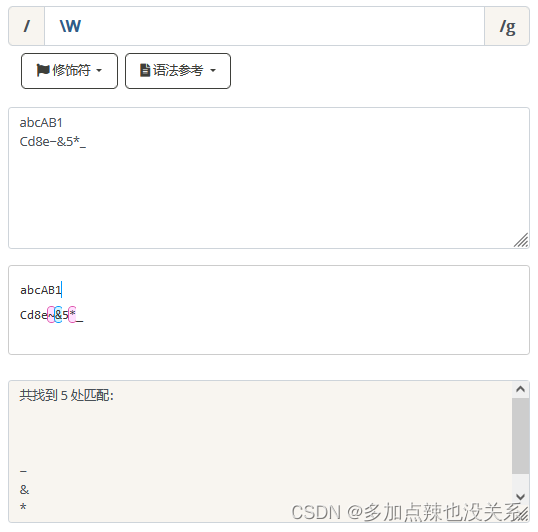
匹配所有空白符,包括换行。
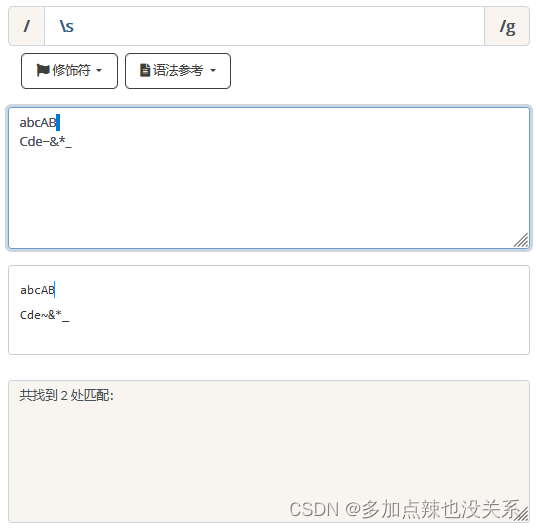
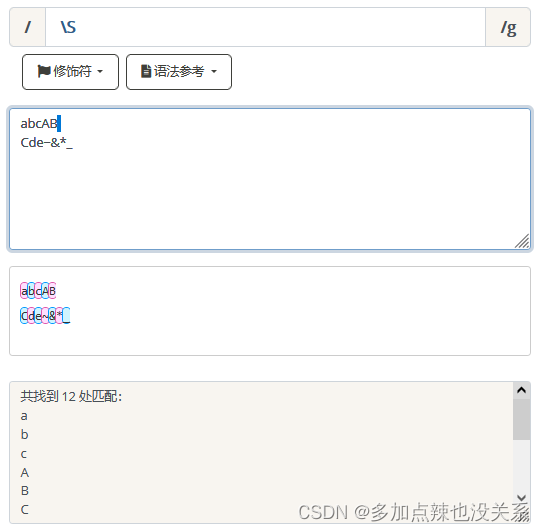
匹配所有非空白符,不包括换行。
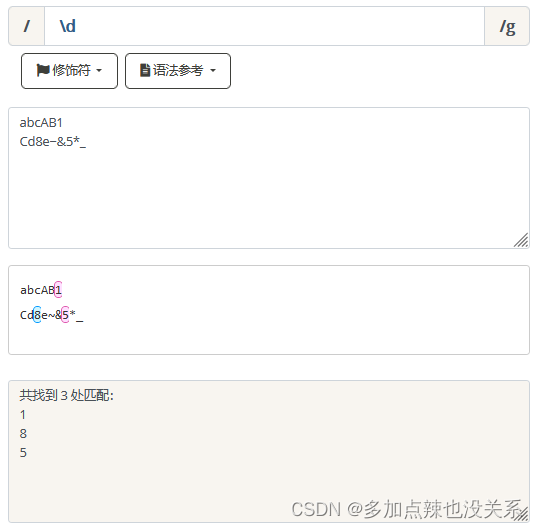
匹配任何数字,等价于 [0-9]。
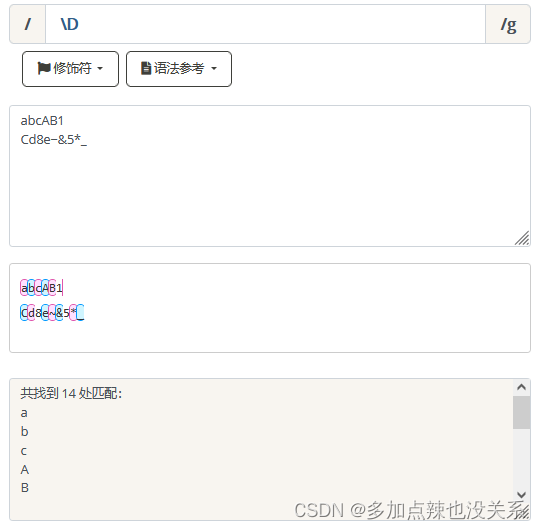
匹配任何非数字,等价于 [^0-9]。
参考博客:
菜鸟教程 - 正则表达式:https://www.runoob.com/regexp/regexp-tutorial.html
最全常用正则表达式大全:https://blog.csdn.net/ZYC88888/article/details/98479629
正则表达式 详解:https://blog.csdn.net/Yy_Rose/article/details/122139645