A Contextual-Bandit Approach to Personalized News Article Recommendation-论文学习
github地址:bandit-learning
摘要
该算法根据用户和文章的上下文信息依次选择文章为用户服务,同时根据用户点击反馈调整其文章选择策略,以最大化用户总点击量。
问题定义
个性化新闻文章推荐问题可以建模为一个具有上下文信息的多臂老虎机问题。我们称其为上下文老虎机(contextual bandit)。使用算法 A A A 进行离散化实验 t = 1 , 2 , 3 , ⋯ t=1,2,3,\cdots t=1,2,3,⋯。在试验 t t t 中:
- 该算法观察当前用户 u t u_t ut 和臂或动作的集合 A t \mathcal{A}_t At,以及它们的特征向量 $x_{t,a} ,其中 ,其中 ,其中a\in \mathcal{A}_t$。特征向量 x t , a x_t,a xt,a概括了用户 u t u_t ut 和 臂 a a a 两者的信息,称之为上下文(
context)。 - 基于先前试验中观察到的奖励,算法 A A A 选择一个臂 a t ∈ A t a_t\in\mathcal{A}_t at∈At,并收到奖励 r t , a t r_{t,a_t} rt,at,其期望取决于用户 u t u_t ut 和 臂 a a a 。
- 然后,该算法使用新的观测值 x t , a , a t , r t , a t x_{t,a} ,a_t,r_{t,a_t} xt,a,at,rt,at 来改进臂选择策略。这里需要强调的是,对于未选择的臂 a ≠ a t a \ne a_t a=at,观察其 n o − f e e d b a c k no-feedback no−feedback(即收益 r t , a r_{t,a} rt,a)是很重要的。
在上面的过程中,算法 A A A 的总 T 轮奖励被定义为 ∑ t = 1 T r t , a t \sum_{t=1}^T r_{t,a_t} ∑t=1Trt,at,同样的,我们可以定义最优期望 T 轮奖励 E [ ∑ t = 1 T r t , a t ∗ ] \text{E}\left[\sum_{t=1}^Tr_{t,a_t^*}\right] E[∑t=1Trt,at∗],其中其中 a t ∗ a_t^* at∗ 是在试验 t t t 时具有最大预期收益的臂。我们的目标是设计算法 A A A ,使上面的预期总收益最大化。等价来说,就是找到一个算法使其关于最优臂选择策略的悔值(regret)最小化。这里,算法 A A A 的 T 轮悔值 R A ( T ) R_A(T) RA(T) 被形式化地定义为:
R A ( T ) = def E [ ∑ t = 1 T r t , a t ∗ ] − E [ ∑ t = 1 T r t , a t ] (1) R_A(T)\ \overset{\text{def}}{=} \ \text{E}\left[\sum_{t=1}^Tr_{t,a_t^*}\right] - \text{E}\left[\sum_{t=1}^Tr_{t,a_t}\right] \tag{1} RA(T) =def E[t=1∑Trt,at∗]−E[t=1∑Trt,at](1)
一般上下文强盗问题的一个重要特殊情况是著名的K臂老虎机问题(K-armed bandit),其中
- 臂集 A t \mathcal{A}_t At 保持不变,每轮 t t t 都有不变的 K K K 个臂
- 用户 u t u_t ut (即上下文 ( x t , 1 , ⋯ , x t , K ) ({x}_{t,1},\cdots,{x}_{t,K}) (xt,1,⋯,xt,K))对于所有 t t t是相同的。由于臂集和上下文在每次试验中都是恒定的,,因此我们也将这种类型的bandit称为上下文无关老虎机模型(
context-free bandit)。
在文章推荐的上下文中,我们可以将池中的文章视为臂。当点击所呈现的文章时,会产生 1 1 1 的奖励;否则奖励为 0 0 0。根据这种收益定义,一篇文章的预期收益就是它的点击率(clickthrough rate CTR),选择一篇具有最大点击率的文章相当于最大化用户的预期点击次数,这反过来又与我们bandit公式中的最大化总预期收益相同。
此外,在web服务中,我们经常可以访问用户信息,这些信息可以用来推断用户的兴趣,并选择她可能最感兴趣的新闻文章。
算法
鉴于UCB方法在无上下文bandit算法中的渐近最优性和强悔值界,设计类似的算法来解决上下文bandit问题是很有诱惑力的。给定奖励函数的某种参数形式,存在许多方法从数据估计参数的置信区间,我们可以用这些置信区间来计算估计臂奖励的UCB(置信上限)。然而,这些方法一般来说是代价较高的。
当奖励模型是线性时,可以有效地以封闭形式计算置信区间,并将此算法称为 L i n U C B LinUCB LinUCB。为了便于阐述,我们首先描述不相交线性模型的简单形式,然后考虑混合模型的一般情况。
不相交线性模型的LinUCB
我们假设臂 a a a 的期望收益在其 d d d 维特征 x t , a {x}_{t,a} xt,a 中是线性的, x t , a {x}_{t,a} xt,a 具有某个未知系数向量 θ a ∗ \pmb{\theta}_a^* θa∗ ;也就是说,对于所有 t t t,
E [ r t , a ∣ x t , a ] = x t , a T θ a ∗ (2) \text{E}[r_{t,a}|{x}_{t,a}]\ =\ \bold{x}_{t,a}^T\ \pmb{\theta}_a^*\tag{2} E[rt,a∣xt,a] = xt,aT θa∗(2)
这个模型是不相交的(disjoint),因为参数在不同的臂间不共享。
设 D a \bold{D}_a Da 维数为 m × d m\times d m×d 的矩阵,它的行对应 m m m 个训练输入(例如,先前文章 a a a 中观察到的 m m m 个上下文), c a ∈ R m \bold{c}_a\in\mathbb{R}^m ca∈Rm 为对应的响应向量(如对应的 m m m 个点击/不点击反馈)。将岭回归(ridge regression)应用于训练数据 ( D a , c a ) (\bold{D}_a, \bold{c}_a) (Da,ca),给出系数的估计:
问题为 D a ⋅ θ a = c \bold{D}_{a}\cdot \theta_a = \bold{c} Da⋅θa=c
加上一个L2正则化项的损失函数如下
L o s s a ( θ a ) = ∣ ∣ D a ⋅ θ a − c a ∣ ∣ 2 + ∣ ∣ I a θ a ∣ ∣ 2 Loss_a(\bold{\theta}_a)=|| \bold{D}_{a}\cdot \theta_a-\bold{c}_a||^2+||\bold{I}_a\theta_a||^2 Lossa(θa)=∣∣Da⋅θa−ca∣∣2+∣∣Iaθa∣∣2
解得:
θ ^ a = ( D a T D a + I d ) − 1 D a T c a (3) \hat{\bold{\theta}}_a=(\bold{D}_a^T\bold{D}_a+\bold{I}_d)^{-1}\bold{D}_a^T\bold{c}_a \tag{3} θ^a=(DaTDa+Id)−1DaTca(3)
其中 I d \bold{I}_d Id 是 d × d d\times d d×d 的单位矩阵,当 c a \bold{c}_a ca 中的分量独立于 D a \bold{D}_a Da 中的相应行时,可以证明至少有 1 − δ 1−δ 1−δ 的概率,
∣ x t , a T θ ^ a − E [ r t , a ∣ x t , a ] ∣ ≤ α x t , a T ( D a T D a + I d ) − 1 x t , a (4) \left|\bold{x}_{t,a}^T\hat{\pmb{\theta}}_a-\text{E}[r_{t,a}|\bold{x}_{t,a}]\right| \le \alpha \sqrt{\bold{x}_{t,a}^T(\bold{D}_a^T\bold{D}_a+\bold{I}_d)^{-1}\bold{x}_{t,a}} \tag{4}
xt,aTθ^a−E[rt,a∣xt,a]
≤αxt,aT(DaTDa+Id)−1xt,a(4)
其中 δ > 0 δ>0 δ>0 为超参 , x t , a ∈ R d x_{t,a} \in \mathbb{R}^d xt,a∈Rd, α = 1 + ln ( 2 / δ ) 2 \alpha=1+\sqrt{\frac{\ln(2/δ)}{2}} α=1+2ln(2/δ)为一个常数。 x t , a T θ ^ a \bold{x}_{t,a}^T\hat{\pmb{\theta}}_a xt,aTθ^a 是观测到的臂 a a a 被选上的概率, E [ r t , a ∣ x t , a ] \text{E}[r_{t,a}|\bold{x}_{t,a}] E[rt,a∣xt,a]则是真实概率。上述不等式为臂 a a a 的预期收益提供了一个合理严格的UCB,从中可以得出一个UCB型的选择策略:在第 t t t 轮中,选择
a t = def arg max a ∈ A t ( x t , a T θ ^ a + α x t , a T A a − 1 x t , a ) (5) a_t \ \overset{\text{def}}{=} \ \arg\max_{a\in\mathcal{A}_t} \left(\bold{x}_{t,a}^T\hat{\pmb{\theta}}_a+\alpha \sqrt{\bold{x}_{t,a}^T \bold{A}_a^{-1}\bold{x}_{t,a}}\right)\tag{5} at =def arga∈Atmax(xt,aTθ^a+αxt,aTAa−1xt,a)(5)
其中 A = def D a T D a + I d \bold{A}\overset{\text{def}}{=}\bold{D}_a^T\bold{D}_a+\bold{I}_d A=defDaTDa+Id
当前模型中,预期收益 x t , a T θ a ∗ \bold{x}_{t,a}^T\pmb{\theta}_a^* xt,aTθa∗ 的预测方差(variance)被估计为 x t , a T A a − 1 x t , a \bold{x}_{t,a}^T \bold{A}_a^{-1}\bold{x}_{t,a} xt,aTAa−1xt,a,然后 x t , a T A a − 1 x t , a \sqrt{\bold{x}_{t,a}^T \bold{A}_a^{-1}\bold{x}_{t,a}} xt,aTAa−1xt,a 成为标准差(standard deviation)
算法1给出了整个 L i n U C B LinUCB LinUCB 算法的详细描述,其唯一的输入参数是 α α α 。注意,式(4)中给出的 α α α 值在某些应用中可能过于保守,因此优化该参数在实际中可能会导致更高的总收益。像所有的UCB方法一样, L i n U C B LinUCB LinUCB 总是选择具有最高UCB的臂(如公式(5))。

- 输入参数 α α α
- 对于 t = 1 , 2 , 3 , … , T t=1,2,3,\ldots,T t=1,2,3,…,T
- 观察所有臂 a ∈ A t a\in \mathcal{A}_t a∈At 的特征值 x t , a ∈ R d x_{t,a} \in \mathbb{R}^d xt,a∈Rd。
- 对于所有的臂 a ∈ A t a\in \mathcal{A}_t a∈At :
- 如果 a a a 是新的臂
- A a ← I d \bold{A}_a \leftarrow \bold{I}_d Aa←Id(d维单位矩阵)
- b a ← 0 d × 1 \bold{b}_a\leftarrow \bold{0}_{d\times 1} ba←0d×1(d维零向量)
- θ ^ a ← A a − 1 b a \hat{\bold{\theta}}_a\leftarrow \bold{A}_a^{-1}\bold{b}_a θ^a←Aa−1ba
- p t , a ← θ ^ a T x t , a + α x t , a T A a − 1 x t , a p_{t,a} \leftarrow \hat{\pmb{\theta}}_a^T \bold{x}_{t,a} +\alpha\sqrt{\bold{x}_{t,a}^T\bold{A}_a^{-1}\bold{x}_{t,a}} pt,a←θ^aTxt,a+αxt,aTAa−1xt,a
- 如果 a a a 是新的臂
- 选择使得 p t , a p_{t,a} pt,a 最大的臂,观察真实的奖励 r t r_t rt。
- A a t ← A a t + x t , a t x t , a t T \bold{A}_{a_t}\leftarrow \bold{A}_{a_t}+\bold{x}_{t,a_t}\bold{x}_{t,a_t}^T Aat←Aat+xt,atxt,atT
- b a t ← b a t + r t x t , a t \bold{b}_{a_t} \leftarrow\bold{b}_{a_t}+r_t\bold{x}_{t,a_t} bat←bat+rtxt,at
其中 A a = def D a T D a + I d \bold{A}_a\overset{\text{def}}{=}\bold{D}_a^T\bold{D}_a+\bold{I}_d Aa=defDaTDa+Id, b a = def D a T ⋅ c a \bold{b}_a\overset{\text{def}}{=}\bold{D}_a^T\cdot \bold{c}_a ba=defDaT⋅ca
混合线性模型的LinUCB
不相交线性模型由于参数是不相交的,因此 D a T D a + I d \bold{D}_a^T\bold{D}_a+\bold{I}_d DaTDa+Id 的逆可以很容易地计算出来,线性参数解 θ a \theta_a θa 不受其他手臂训练数据的影响,因此也可以单独计算。接下来考虑一种更复杂的情况,臂的参数既有独立部分,也有和其他臂共享的部分。
臂之间共享信息是很有帮助的。形式上,我们采用以下混合模型,在公式(2)的右侧增加另一个线性项
E [ r t , a ∣ x t , a ] = z t , a T β ∗ + x t , a T θ a ∗ (6) \text{E}[r_{t,a}|{x}_{t,a}]\ =\ \bold{z}_{t,a}^T\ \pmb{\beta}^*+ \bold{x}_{t,a}^T\ \pmb{\theta}_a^*\tag{6} E[rt,a∣xt,a] = zt,aT β∗+xt,aT θa∗(6)
其中 z t , a ∈ R k \bold{z}_{t,a}∈\mathbb{R}^k zt,a∈Rk 是当前用户/文章组合的特征, β ∗ \pmb{\beta}^* β∗ 是所有臂共有的未知系数向量。这个模型是混合的,因为有些系数 β ∗ \pmb{\beta}^* β∗ 为所有臂所共有,而另一些系数 θ a ∗ \pmb{\theta}_a^* θa∗ 则不是。
对于混合模型,我们不能再使用算法1,因为各臂的置信区间由于共享特征不是独立的。幸运的是,有一种计算UCB的有效方法,其推理思路与前一节相同。推导主要依赖于分块矩阵反演技术。
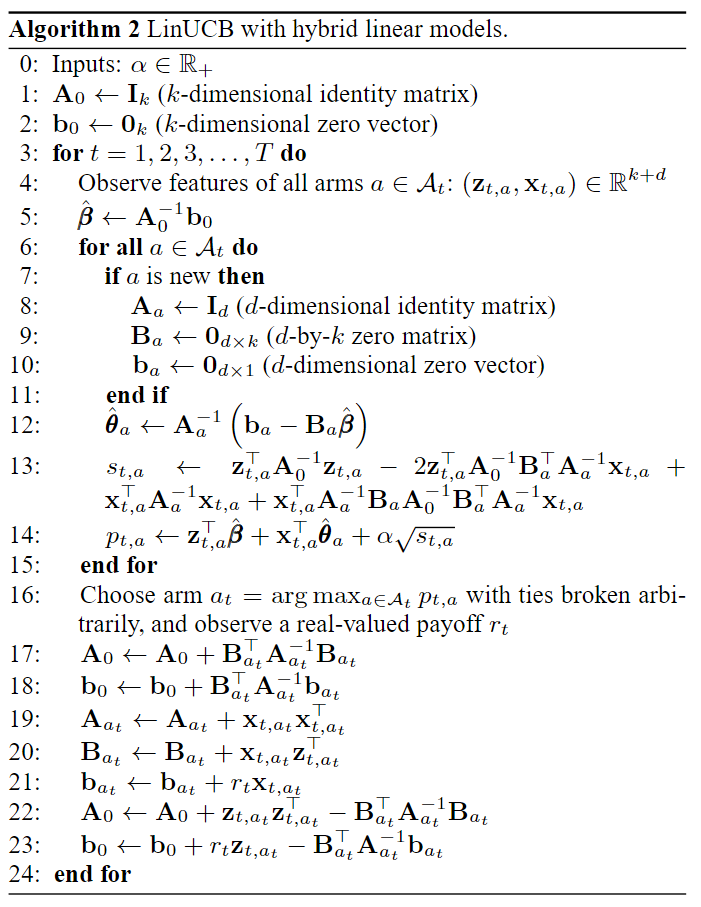
该算法在计算上是有效的,因为该算法中的构件块 ( A 0 、 b 0 、 A a 、 B a 和 b a ) (A_0、b_0、A_a、B_a和b_a) (A0、b0、Aa、Ba和ba) 都有固定的尺寸,可以递增更新。此外,与 A \mathcal{A} A 中不存在的臂相关的量不再参与计算。最后,我们还可以周期性地计算和缓存逆( A 0 − 1 A_0^{-1} A0−1和 A 1 − 1 A_1^{-1} A1−1),而不是在每次试验结束时计算和缓存,从而将每次试验的计算复杂度降低到 O ( d 2 + k 2 ) O(d^2+k^2) O(d2+k2)。
评估方法
不同于其他监督学习,在线学习算法的评估方法不那么容易。由于是探测问题,如果不上线,就没办法探到算法希望的内容一个方式是根据离线数据构造一个模拟器,但是这种模拟器会引入bias。我们提出了一个没有bias的简单实现。
- 我们假设有若干未知的分布 D D D 服从独立同分布, ( x 1 , . . . , x K , r 1 , … , r K ) (\bold{x}_{1}, ..., \bold{x}_{K}, r_{1}, \ldots, r_{K}) (x1,...,xK,r1,…,rK)。
- 每个分布包含了所有臂的可观测特征向量与隐含的奖励。我们还假设可以访问由日志政策与现实世界的交互所产生的大量记录事件序列。
- 每个这样的事件都由上下文向量 ( x 1 , . . . , x K ) (\bold{x}_{1}, ..., \bold{x}_{K}) (x1,...,xK),一个选定的臂 a a a 和由此观察到的奖励 r a r_a ra组成。简单起见,我们把实
- 实验的事件流看作是无限的,但是实验所需的事件是有上限的。
我们的目标是利用这些数据来评估一个bandit算法 π π π 。形式上, π π π 是一个(可能是随机的)映射,从历史 t − 1 t-1 t−1 个事件 h t − 1 h_{t-1} ht−1,以及当前的上下文特征向量 ( x t 1 , . . . , x t K ) (\bold{x}_{t1}, ..., \bold{x}_{tK}) (xt1,...,xtK)映射到在 t t t 时刻选择臂 a a a。算法如下所示

- 该方法将策略 π π π 和设定数量的“good”事件 T T T 作为输入,以此作为评估的基础。然后,我们逐一查看记录的事件流。
- 如果给定当前历史 t − 1 t−1 t−1 ,碰巧策略 π π π 选择了与日志策略选择的臂 a a a 相同,那么该事件被保留,也就是说,被添加到历史中,总收益 R t R_t Rt 被更新。否则事件被忽略,算法继续处理下一个事件,而不改变其状态。
- 值得注意的是,日志策略选择臂的策略是均匀随机选择,所以每个事件被算法保留的概率 1 K \frac{1}{K} K1,并且各自是独立的。
根据真实世界事件评估策略和使用策略评估器对日志事件流评估策略是等效的。
实验
雅虎的Today模块
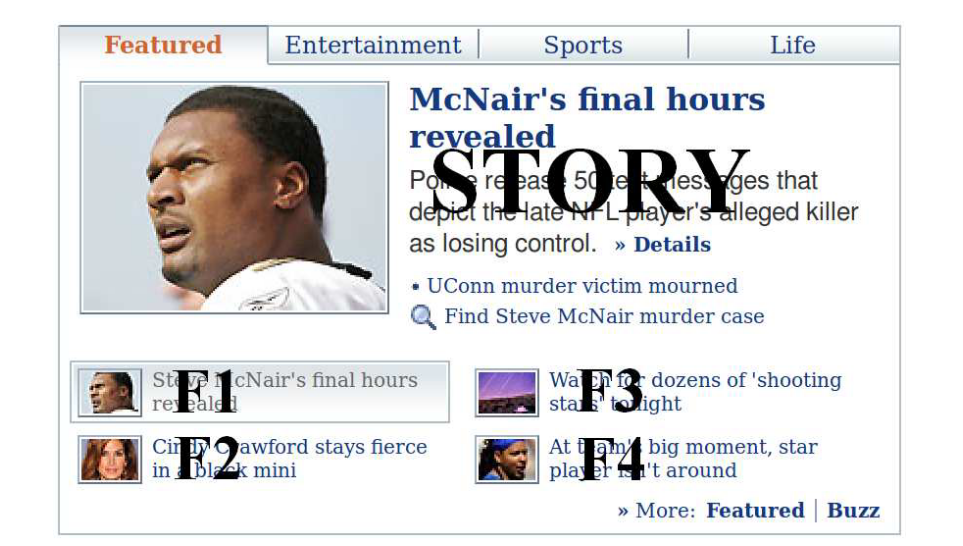
Today模块是雅虎首页,如下图所示。Today模块中的默认“Featured”选项卡突出显示了四篇高质量文章中的一篇,,而这四篇文章是从人工编辑每小时更新一次的文章池中选择的。如图所示,页脚位置有四篇文章,索引为F1-F4。每篇文章都由一张小图片和一个标题表示。四篇文章中的一篇被突出显示在Story位置,配有一张大图、一个标题和一个简短的摘要以及相关链接。默认情况下,位于F1的文章在Story位置突出显示。如果用户对文章感兴趣,可以点击Story位置的高亮文章阅读更多细节。事件被记录为故事点击。为了吸引访问者的注意力,我们会根据个人兴趣对可用文章进行排名,并在Story位置突出最吸引每位访问者的文章。
数据收集
我们在2009年5月从一个随机的bucket中收集事件。用户按一定的访问概率随机选择bucket。在这个bucket中,从文章池中随机选择文章为用户服务。为了避免页脚位置的曝光偏差,我们只关注用户在Story位置与F1文章的互动。每个用户交互事件由三个部分组成:**(i)选择为用户服务的随机文章,(ii)用户/文章信息,以及(iii)**用户是否在Story位置点击文章。5月1日,随机bucket中大约有470万个事件。我们使用当天的事件进行模型验证,以确定每个算法的最佳参数。然后,我们在5月03日至09日的随机bucket中运行这些算法,在一周的事件集上运行这些算法,其中包含大约3600万个事件。
特征构造
某一特性的支持度是指拥有该特性的用户比例。为了减少数据中的噪声,我们只选择支持度高的特征。具体来说,我们使用支持度至少为0.1的特性。然后,每个用户最初由超过1000个分类分量的原始特征向量表示,其中包括:
- 个人统计信息:性别(男和女)和年龄(离散为10个分段)。
- 地理特征:全球约200个大都市和美国各州。
- 行为类别:大约 1000 个二项类别,总结了用户在雅虎内的历史。
除了这些特征之外,没有其他信息用于识别用户。
同样,每篇文章都由大约 100 个分类特征的原始特征向量表示,这些特征向量的构建方式相同。这些特征包括:
- URL 类别:从文章资源的 URL 推断出的数十个类。
- 编辑类别:由人工编辑标记的数十个主题来总结文章内容。
对特征进行降维:
- 我们首先使用逻辑回归(LR)拟合一个给定原始用户/文章特征的点击概率双线性模型,使 ϕ u T W ϕ a \pmb{\phi}_u^T \bold{W} \pmb{\phi}_a ϕuTWϕa 近似于用户 u u u 点击文章 a a a 的概率,其中 ϕ u \pmb{\phi}_u ϕu 和 ϕ a \pmb{\phi}_a ϕa 是对应的特征向量, W \bold{W} W 为LR优化的权重矩阵。
- 然后通过计算 ψ u = def ϕ u T W \pmb{\psi}_u \overset{\text{def}}{=} \pmb{\phi}_u^T \bold{W} ψu=defϕuTW 将原始用户特征投影到诱导空间上。这里,用户 u u u 的 ψ u \pmb{\psi}_u ψu 中的第 i 个分量可解释为用户喜欢第 i 个类别的文章的程度。应用K-means,将用户分组为 5 5 5 个聚类。
- 最后得到的用户特征是一个6-向量:其中5个条目对应于该用户在这5个聚类中的membership(用高斯核计算,然后归一化,以便它们加起来为1),第六个是恒定特征1。
于每个文章 a a a,我们执行相同的降维操作以获得一个六维的文章特征(包括一个常数 1 1 1特征)。它与用户的外积 z t , a ∈ R 36 \bold{z}_{t,a}\in \mathbb{R}^{36} zt,a∈R36,对应公式6中的共享特征,因此 ( z t , a , x t , a ) (\bold{z}_{t,a},\bold{x}_{t,a}) (zt,a,xt,a)可用于混合线性模型。注意, z t , a \bold{z}_{t,a} zt,a包含用户-文章交互信息,而 x t , a \bold{x}_{t,a} xt,a仅包含用户信息。
使用五个特征是较为合适的。用相对较小的特征空间的另一个原因是,在在线服务中,存储和检索大量用户/文章信息的成本太高,不太实际。
代码
数据集说明
数据集说明如下:
-
共10,000行,对应于用户访问不同站点的事件;
-
每一行包含102个空格分隔的整数列:
-
第1列:10篇文章中的一篇(1-10),即臂的编号;
-
第2列:如果用户点击该文章,则从臂中获得的奖励为1,否则为0;
-
第3-102列:100个模糊的上下文信息:每个臂有10个特征(包括文章的内容及其与访问用户的匹配),首先是臂1的特征,然后是臂2的特征,直到臂10。
引入相应的库
import numpy as np
from numpy.linalg import inv
import matplotlib.pyplot as plt
应用简单的ε-Greedy算法、UCB算法和Thompson Sampling算法
class BasicMAB():
def __init__(self, narms):
"""初始化
Args:
narms (int): 臂的数量
"""
pass
def select_arm(self, context = None):
"""选择一个臂
Args:
tround (int): 当前的轮次数
context (1D float array): 给定arm的上下文信息
"""
pass
def update(self, arm, reward, context = None):
"""更新算法
Args:
arm (int): 当前选择的臂,1,...,self.narms
reward (float): 从一个臂中获得的奖励
context (1D float array): 给定arm的上下文信息
"""
pass
class EpsilonGreedy(BasicMAB):
def __init__(self, narms, epsilon=0):
self.narms = narms
self.epsilon = epsilon
# 总的执行次数
self.step = 0
# 每只臂被选择过的次数
self.step_arm = np.zeros(self.narms)
# 每只臂的平均奖励
self.mean_reward = np.zeros(self.narms)
return
def select_arm(self, context=None):
# 每个臂至少选择一次
if len(np.where(self.step_arm==0)[0]) > 0:
action = np.random.choice(np.where(self.step_arm==0)[0])
return action + 1
if np.random.rand() < self.epsilon:
action = np.random.choice(self.narms)
else:
# 选择平均奖励最大的臂
action = np.random.choice(np.where(self.mean_reward==np.max(self.mean_reward))[0])
# 由于臂的下标为1-10,所以要+1
return action + 1
def update(self, arm, reward, context=None):
self.arm = arm
self.step += 1
self.step_arm[self.arm] += 1
self.mean_reward[self.arm] = (
self.mean_reward[self.arm] * (self.step_arm[self.arm]-1) + reward)/ float(self.step_arm[self.arm])
class UCB(BasicMAB):
def __init__(self, narms, alpha=1):
self.narms = narms
# 超参,>0
self.alpha = alpha
# 总的执行次数
self.step = 0
# 每只臂被选择过的次数
self.step_arm = np.zeros(self.narms)
# 每只臂的平均奖励
self.mean_reward = np.zeros(self.narms)
return
def select_arm(self, context=None):
# 每个臂至少选择一次
if len(np.where(self.step_arm==0)[0]) > 0:
action = np.random.choice(np.where(self.step_arm==0)[0])
return action + 1
# 计算ucb
ucb_values = np.zeros(self.narms)
for arm in range(self.narms):
# 置信区间
ucb_values[arm] =np.sqrt(self.alpha *(np.log(self.step)) / self.step_arm[arm])
temp = self.mean_reward + ucb_values
action = np.random.choice(np.where(temp == np.max(temp))[0])
return action + 1
def update(self, arm, reward, context=None):
self.arm = arm
self.step += 1
self.step_arm[self.arm] += 1
self.mean_reward[self.arm] = (
self.mean_reward[self.arm] * (self.step_arm[self.arm]-1) + reward)/ float(self.step_arm[self.arm])
class BetaThompsonSampling(BasicMAB):
def __init__(self, narms, alpha0=1.0, beta0=1.0):
self.narms = narms
# 总的执行次数
self.step = 0
# 每只臂被选择过的次数
self.step_arm = np.zeros(self.narms)
self.alpha0 = np.ones(narms) * alpha0
self.beta0 = np.ones(narms) * beta0
def select_arm(self, context=None):
# 每个臂至少选择一次
if len(np.where(self.step_arm==0)[0]) > 0:
action = np.random.choice(np.where(self.step_arm==0)[0])
return action + 1
means = np.random.beta(self.alpha0, self.beta0)
action = np.random.choice(np.where(means==np.max(means))[0])
return action + 1
def update(self, arm, reward, context=None):
self.arm = arm
self.step += 1
self.step_arm[self.arm] += 1
if reward == 1:
self.alpha0[arm] += 1
else:
self.beta0[arm] += 1
LinUCB
class LinUCB(BasicMAB):
def __init__(self, narms, ndims, alpha):
self.narms = narms
# 上下文特征的数量
self.ndims = ndims
# 超参,>0
self.alpha = alpha
# 每个臂的A矩阵为(ndims,ndims)的单位矩阵
self.A = np.array([np.identity(self.ndims)] * self.narms)
# 每个臂的b矩阵为(ndims,1)的矩阵
self.b = np.zeros((self.narms, self.ndims, 1))
return
def select_arm(self, context=None):
p_t = np.zeros((self.ndims,1))
for i in range(self.narms):
self.theta = inv(self.A[i]).dot(self.b[i])
# 获得每个臂的特征
x = np.array(context[i*10:(i+1)*10]).reshape(self.ndims, 1)
# 获得每个臂的奖励
p_t[i] = self.theta.T.dot(x) + \
self.alpha * np.sqrt(x.T.dot(inv(self.A[i]).dot(x)))
action = np.random.choice(np.where(p_t == max(p_t))[0])
return action+1
def update(self, arm, reward, context=None):
self.arm = arm
x = np.array(context[arm*10:(arm+1)*10]).reshape(self.ndims, 1)
self.A[arm] = self.A[arm] + x.dot(x.T)
self.b[arm] = self.b[arm] + reward*x
return
评估框架
def offlineEvaluate(mab, data_num, arms, rewards, contexts, rounds=None):
"""模拟在线环境的离线测试
Args:
mab (BasicMAB): 多臂老虎机算法
data_num (int): 数据量
arms (1D int array): 数据集中选择的臂的数量
rewards (1D float array): 数据集中的奖励
contexts (2D float array): 数据集中的上下文信息
rounds (int, optional): 选择限制的轮次. Defaults to None.
Returns:
reward_arms (1D float array): 获得的奖励
chosen_arms (1D int array): 选择的臂
cumulative_reward (1D float array): 累积的奖励
"""
chosen_arms = np.zeros(rounds)
reward_arms = np.zeros(rounds)
cumulative_reward = np.zeros(rounds)
# 当前轮次
T = 0
# 当前累计奖励
G = 0
# 离线历史
history = []
# 最初选择一个动作
action = mab.select_arm(contexts[0, :])
for i in range(data_num):
action = mab.select_arm(contexts[i, :])
if T < rounds:
# 当算法选择的臂跟实际数据匹配时,更新参数
if action == arms[i]:
# 将选择的臂的上下文信息添加到历史信息中
history.append(contexts[i, :])
reward_arms[T] = rewards[i]
# action要-1,便于映射到下标
mab.update(action-1, rewards[i], contexts[i, :])
G += rewards[i]
cumulative_reward[T] = G
chosen_arms[T] = action
T += 1
else:
break
return reward_arms, chosen_arms, cumulative_reward
测试
JOBS = 1
test_rounds = 800
np.random.seed(1)
data = np.loadtxt('dataset.txt')
datalen = np.shape(data)[0]
arms = data[:, 0]
rewards = data[:, 1]
contexts = data[:, 2:102]
epsilon = 0.05
alpha = 0.1
alpha2 = 0.2
mab1 = EpsilonGreedy(10,epsilon)
mab2 = UCB(10, alpha)
mab3 = BetaThompsonSampling(10, 1.0, 1.0)
mab4 = LinUCB(10, 10 ,alpha2)
cul_TS = 0
cul_Eps = 0
cul_UCB = 0
cul_LinUCB = 0
cul2_TS = np.zeros(test_rounds)
cul2_Eps = np.zeros(test_rounds)
cul2_UCB = np.zeros(test_rounds)
cul2_LinUCB = np.zeros(test_rounds)
for j in range(JOBS):
results_Eps, _ , cumulative_reward_Eps = offlineEvaluate(
mab1, datalen, arms, rewards, contexts, test_rounds)
results_UCB, _ , cumulative_reward_UCB = offlineEvaluate(
mab2, datalen, arms, rewards, contexts, test_rounds)
results_TS, _ , cumulative_reward_TS = offlineEvaluate(
mab3, datalen, arms, rewards, contexts, test_rounds)
results_LinUCB, _ , cumulative_reward_LinUCB = offlineEvaluate(
mab4, datalen, arms, rewards, contexts, test_rounds)
cul_TS += np.mean(results_TS)
cul_Eps += np.mean(results_Eps)
cul_UCB += np.mean(results_UCB)
cul_LinUCB += np.mean(results_LinUCB)
cul2_TS += cumulative_reward_TS
cul2_Eps += cumulative_reward_Eps
cul2_UCB += cumulative_reward_UCB
cul2_LinUCB += cumulative_reward_LinUCB
print('Epsilon-greedy average reward', cul_Eps/JOBS)
print('UCB average reward', cul_UCB/JOBS)
print('Thompson Sampling average reward', cul_TS/JOBS)
print('LinUCB-greedy average reward', cul_LinUCB/JOBS)
plt.figure(figsize=(12, 8))
plt.plot((cul2_Eps/JOBS)/(np.linspace(1, test_rounds, test_rounds)),label=r"$\epsilon=$ {:.2f}(greedy)".format(epsilon))
plt.plot((cul2_UCB/JOBS)/(np.linspace(1, test_rounds, test_rounds)),label=r"$\alpha=$ {:.2f}(UCB)".format(alpha))
plt.plot((cul2_LinUCB/JOBS)/(np.linspace(1, test_rounds, test_rounds)),label=r"$\alpha=$ {:.2f}(LinUCB)".format(alpha2))
plt.plot((cul2_TS/JOBS)/(np.linspace(1, test_rounds, test_rounds)),label=r"Thompson Sampling")
plt.legend()
plt.xlabel("Rounds")
plt.ylabel("Average Reward")
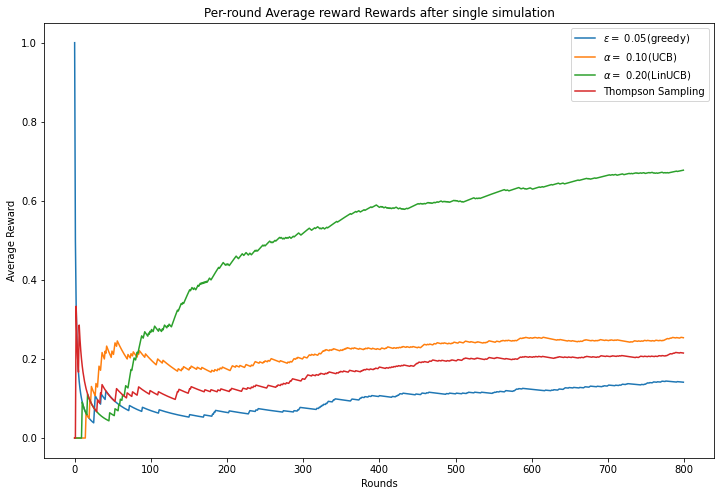
plt.title("Per-round Average reward Rewards after single simulation")
plt.show()
plt.figure(figsize=(12, 8))
plt.plot(cul2_Eps/JOBS,label=r"$\epsilon=$ {:.2f}(greedy)".format(epsilon))
plt.plot(cul2_UCB/JOBS,label=r"$\alpha=$ {:.2f}(UCB)".format(alpha))
plt.plot(cul2_LinUCB/JOBS,label=r"$\alpha=$ {:.2f}(LinUCB)".format(alpha2))
plt.plot(cul2_TS/JOBS,label=r"Thompson Sampling")
plt.legend()
plt.xlabel("Rounds")
plt.ylabel("Culmulative Reward")
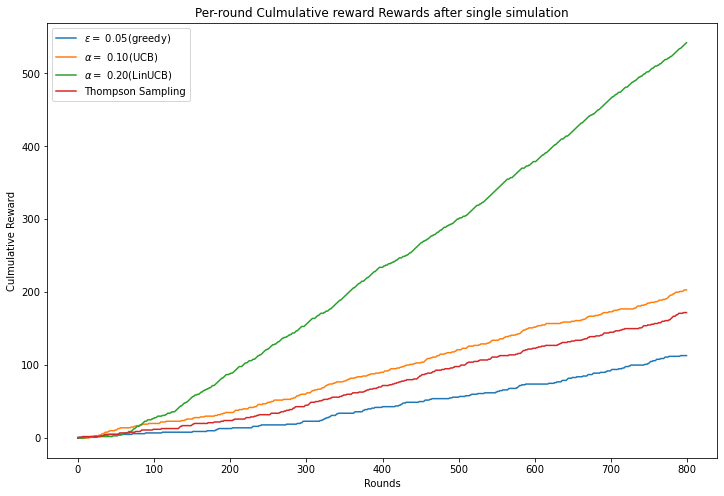
plt.title("Per-round Culmulative reward Rewards after single simulation")
plt.show()
Epsilon-greedy average reward 0.14125
UCB average reward 0.25375
Thompson Sampling average reward 0.215
LinUCB-greedy average reward 0.6775
参考资料
- Li, Lihong, et al. “A contextual-bandit approach to personalized news article recommendation.” Proceedings of the 19th international conference on World wide web. 2010.
- Multi-Armed Bandit: LinUCB 1 - 苍耳的文章 - 知乎 https://zhuanlan.zhihu.com/p/545790329
- A Contextual-Bandit Approach to Personalized News Article Recommendation:论文精读 - 北土城倒8号线的文章 - 知乎 https://zhuanlan.zhihu.com/p/34940176
- Multi-armed-Bandits