继续看pytorch_quantiation.calib 中Calibrator类,代码位于:tools\pytorch-quantization\pytorch_quantization\calib
其作用:收集校准数据的统计信息:将校准数据馈送到模型,并以直方图的形式收集每个层的激活分布统计信息以进行量化。收集直方图数据后,使用一个或多个校准算法( compute_amax)校准刻度( calibrate_model )。
在标定过程中,尽量确定每一层的量化尺度,以达到优化模型精度等目标。目前有两种校准器等级:
- pytorch_quantization.calib.histogram – 使用熵最小化(KLD)、均方误差最小化(MSE)或百分位度量方法(选择动态范围,以表示指定的分布百分比)。
- pytorch_quantization.calib.max – 使用最大激活值进行校准(表示浮点数据的整个动态范围)。
抽象基类:
代码位于:tools\pytorch-quantization\pytorch_quantization\calib\calibrator.py
class _Calibrator():
"""Abstract base class of calibrators
Args:
num_bits: An integer. Number of bits of quantization.
axis: A tuple. see QuantDescriptor.
unsigned: A boolean. using unsigned quantization.
Readonly Properties:
axis:
"""
def __init__(self, num_bits, axis, unsigned):
self._num_bits = num_bits
self._axis = axis
self._unsigned = unsigned
def collect(self, x):
"""Abstract method: collect tensor statistics used to compute amax
Args:
x: A tensor
"""
raise NotImplementedError
def reset(self):
"""Abstract method: reset calibrator to initial state"""
raise NotImplementedError
def compute_amax(self, *args, **kwargs):
"""Abstract method: compute the amax from the collected data
Returns:
amax: a tensor
"""
raise NotImplementedError
def __repr__(self):
s = "num_bits={_num_bits}"
s += " axis={_axis}"
s += " unsigned={_unsigned}"
return s.format(**self.__dict__)
HistogramCalibrator
直方图只收集一次。compute_amax()基于参数执行entropy、percentile或mse校准
class HistogramCalibrator(_Calibrator):
"""Unified histogram calibrator
Args:
num_bits:整数。量化位数。
axis:元组,参见QuantDescriptor
unsigned:布尔值,使用无符号量化
num_bins:整数,直方图bin数。默认为2048
grow_method:字符串,已弃用。默认为None
skip_zeros:布尔值。如果为True,则在收集直方图数据时跳过零。默认为False
torch_hist:布尔值。如果为True,则通过torch.histc而不是np.histogram收集直方图。如果输入张量在GPU上,histc也将在GPU上运行。默认为False
"""
def __init__(self, num_bits, axis, unsigned, num_bins=2048, grow_method=None, skip_zeros=False, torch_hist=False):
super(HistogramCalibrator, self).__init__(num_bits, axis, unsigned)
self._num_bins = num_bins
self._skip_zeros = skip_zeros
# 直方图bin的边缘(数组:长度为length(hist)+1)
self._calib_bin_edges = None
# 直方图值
self._calib_hist = None
# True:收集torch.histc生成直方图信息,否则使用np.histogram
self._torch_hist = torch_hist
if axis is not None:
raise NotImplementedError("Calibrator histogram collection only supports per tensor scaling")
if grow_method is not None:
logging.warning("grow_method is deprecated. Got %s, ingored!", grow_method)
收集直方图信息
# torch.histc生成直方图信息
def collect(self, x):
"""Collect histogram"""
if torch.min(x) < 0.:
logging.log_first_n(
logging.INFO,
("Calibrator encountered negative values. It shouldn't happen after ReLU. "
"Make sure this is the right tensor to calibrate."),
1)
x = x.abs()
x = x.float()
if not self._torch_hist:
x_np = x.cpu().detach().numpy()
if self._skip_zeros:
x_np = x_np[np.where(x_np != 0)]
# 直方图值和bin边缘都为空,调用np.histogram生成直方图信息
if self._calib_bin_edges is None and self._calib_hist is None:
# first time it uses num_bins to compute histogram.
# 返回值:hist:直方图值,bin_edges:bin的边缘(数组:长度为length(hist)+1)
self._calib_hist, self._calib_bin_edges = np.histogram(x_np, bins=self._num_bins) # _num_bins:直方图个数
else:
temp_amax = np.max(x_np)
# 最大值大于直方图边缘的最大值,即最大值超出直方图范围,这是需要增加bin
if temp_amax > self._calib_bin_edges[-1]:
# increase the number of bins
# bin的宽度
width = self._calib_bin_edges[1] - self._calib_bin_edges[0]
# NOTE:np.arange可以在包含temp_amax的bin后创建额外bin
# NOTE: np.arange may create an extra bin after the one containing temp_amax
new_bin_edges = np.arange(self._calib_bin_edges[-1] + width, temp_amax + width, width)
# np.hstack:将参数元组的元素数组按水平方向进行叠加
self._calib_bin_edges = np.hstack((self._calib_bin_edges, new_bin_edges))
# 重新划分直方图信息
hist, self._calib_bin_edges = np.histogram(x_np, bins=self._calib_bin_edges)
hist[:len(self._calib_hist)] += self._calib_hist
self._calib_hist = hist
else:
# This branch of code is designed to match numpy version as close as possible
with torch.no_grad():
if self._skip_zeros:
x = x[torch.where(x != 0)]
# Because we collect histogram on absolute value, setting min=0 simplifying the rare case where
# minimum value is not exactly 0 and first batch collected has larger min value than later batches
x_max = x.max()
if self._calib_bin_edges is None and self._calib_hist is None:
self._calib_hist = torch.histc(x, bins=self._num_bins, min=0, max=x_max)
self._calib_bin_edges = torch.linspace(0, x_max, self._num_bins + 1)
else:
if x_max > self._calib_bin_edges[-1]:
width = self._calib_bin_edges[1] - self._calib_bin_edges[0]
self._num_bins = int((x_max / width).ceil().item())
self._calib_bin_edges = torch.arange(0, x_max + width, width, device=x.device)
hist = torch.histc(x, bins=self._num_bins, min=0, max=self._calib_bin_edges[-1])
hist[:self._calib_hist.numel()] += self._calib_hist
self._calib_hist = hist
校准方法
直方图校准
直方图校准调用compute_amax, 提供3中校准方式:
- entropy:利用KL散度,和TensorRT中PTQ int8采用采用一样
- percentile
- 均方误差最小化(MSE)
def compute_amax(
self, method: str, *, stride: int = 1, start_bin: int = 128, percentile: float = 99.99):
"""Compute the amax from the collected histogram
Args:
method: A string. One of ['entropy', 'mse', 'percentile']
Keyword Arguments:
stride: An integer. Default 1
start_bin: An integer. Default 128
percentils: A float number between [0, 100]. Default 99.99.
Returns:
amax: a tensor
"""
if isinstance(self._calib_hist, torch.Tensor):
calib_hist = self._calib_hist.int().cpu().numpy()
calib_bin_edges = self._calib_bin_edges.cpu().numpy()
else:
calib_hist = self._calib_hist
calib_bin_edges = self._calib_bin_edges
if method == 'entropy':
calib_amax = _compute_amax_entropy(
calib_hist, calib_bin_edges, self._num_bits, self._unsigned, stride, start_bin)
elif method == 'mse':
calib_amax = _compute_amax_mse(
calib_hist, calib_bin_edges, self._num_bits, self._unsigned, stride, start_bin)
elif method == 'percentile':
calib_amax = _compute_amax_percentile(calib_hist, calib_bin_edges, percentile)
else:
raise TypeError("Unknown calibration method {}".format(method))
return calib_amax
KL散度:
采用和TensorRT 一样的int8量化策略,选用对称量化,量化参数Z=0,只需要计算尺度S
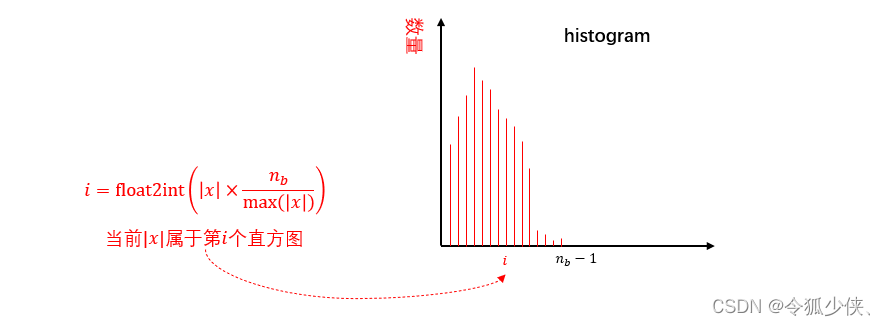
完成 n b n_b nb个bin的统计直方图histogram,再对histogram进行归一化,即可获得一个分布 P ( i ) P(i) P(i)
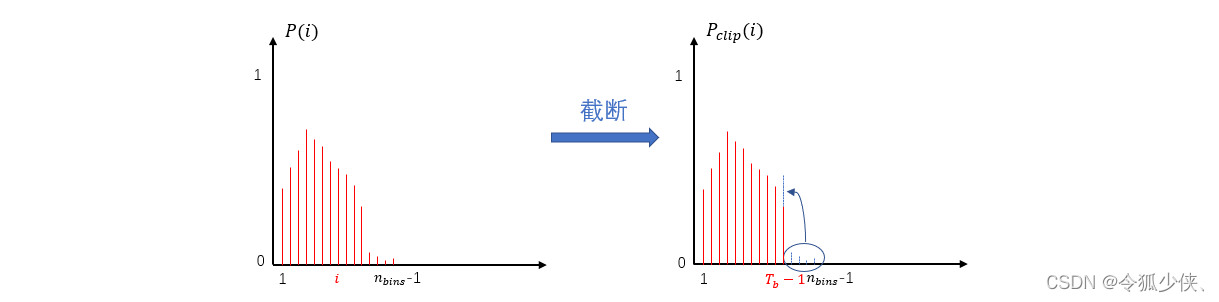
截断方案:直方图截断,选择从第 T b T_b Tb 个bin截断, T b T_b Tb后面的bin加到 T b − 1 T_{b-1} Tb−1 上,截断后的|x|分布变为 P c l i p ( i ) P_{clip}(i) Pclip(i)

_compute_amax_entropy:即通过计算KL散度(也称为相对熵,用以描述两个分布之间的差异)来评估量化前后的两个分布之间存在的差异,最小化量化后int8与原始float32数据之间的信息损失,遍历搜索并选择KL散度最小的calib_amax
TensorRT 采用基于实验的迭代搜索阈值。校准是其中的一个主要部分。校准过程如下所示,具体过程如下:
- 将数据划分为2047个bin
- 取前 128 个 bin 作为基准,逐次向后搜索,每次扩增一个 bin的长度。
- 将bin[0],…,bin[i-1]量化为128个bin,计算P的概率分布并归一化
- 选择从第i个bin截断,i后面的bin加到i-1 上,得到一个基本没有损失的直方图概率分布P_clip,并归一化
- 调用
scipy.stats的entropy方法计算KL散度
- 选取KL散度最小时对应的
calib_amax,calib_amax表示KL散度最小时,直方图对应的clip`边缘位置,该位置clip,效果最好

def _compute_amax_entropy(calib_hist, calib_bin_edges, num_bits, unsigned, stride=1, start_bin=128):
# 返回使收集的直方图的KL散度最小化的amax
"""Returns amax that minimizes KL-Divergence of the collected histogram"""
# If calibrator hasn't collected any data, return none
if calib_bin_edges is None and calib_hist is None:
return None
def _normalize_distr(distr):
summ = np.sum(distr)
if summ != 0:
distr = distr / summ
bins = calib_hist[:]
bins[0] = bins[1]
total_data = np.sum(bins)
divergences = []
arguments = []
# we are quantizing to 128 values + sign if num_bits=8
nbins = 1 << (num_bits - 1 + int(unsigned)) # 对称量化 nbins=128
starting = start_bin
stop = len(bins) # 4028
new_density_counts = np.zeros(nbins, dtype=np.float64)
#首次遍历 i=128
for i in range(starting, stop + 1, stride):
new_density_counts.fill(0)
# 这里是先进行量化,再计算数据分布Q,耗时比较大
# 把bin[0],...,bin[i-1]量化为128个bin
space = np.linspace(0, i, num=nbins + 1)
# numpy.digitize(array_x, bins, right=False):返回array中每一个值在bins中所属的位置
# 记录量化前的i在量化后的位置
digitized_space = np.digitize(range(i), space) - 1
digitized_space[bins[:i] == 0] = -1 # 直方图值为0 对应 digitized_space 值取-1
# 计算量化后的数据分布Q
for idx, digitized in enumerate(digitized_space):
if digitized != -1:
# 将直方图柱子不为0依次累加
new_density_counts[digitized] += bins[idx]
counter = Counter(digitized_space) # Counter:统计可迭代序列中每个元素出现次数
for key, val in counter.items():
if key != -1:
# 计算分布Q:new_density_counts
new_density_counts[key] = new_density_counts[key] / val
new_density = np.zeros(i, dtype=np.float64)
# 剔除直方图值为0的
for idx, digitized in enumerate(digitized_space):
if digitized != -1:
new_density[idx] = new_density_counts[digitized]
total_counts_new = np.sum(new_density) + np.sum(bins[i:])
# 归一化
_normalize_distr(new_density)
# 取前i个bin
reference_density = np.array(bins[:len(digitized_space)])
# 选择从第i个bin截断,i后面的bin加到i-1 上,得到一个基本没有损失的直方图P_clip
# reference_density 代表原始float数据截断后的分布情况
reference_density[-1] += np.sum(bins[i:])
total_counts_old = np.sum(reference_density)
if round(total_counts_new) != total_data or round(total_counts_old) != total_data:
raise RuntimeError("Count mismatch! total_counts_new={}, total_counts_old={}, total_data={}".format(
total_counts_new, total_counts_old, total_data))
_normalize_distr(reference_density)
# 计算KL散度,散度越小代表分布越相似
ent = entropy(reference_density, new_density)
divergences.append(ent)
arguments.append(i)
divergences = np.array(divergences)
logging.debug("divergences={}".format(divergences))
last_argmin = len(divergences) - 1 - np.argmin(divergences[::-1])
# calib_amax代表截断float的最大值,在此处截断,量化效果最好
calib_amax = calib_bin_edges[last_argmin * stride + starting]
calib_amax = torch.tensor(calib_amax.item())
return calib_amax
均方误差最小化(MSE)
_compute_amax_mse
通常会假设 权重和 激活的数值呈正态分布,根据正态分布的性质,可以取区间 ,可以覆盖99%以上的数据。但如果实际分布不是正态分布就可能带来巨大的误差
def _compute_amax_mse(calib_hist, calib_bin_edges, num_bits, unsigned, stride=1, start_bin=128):
"""Returns amax that minimizes MSE of the collected histogram"""
# If calibrator hasn't collected any data, return none
if calib_bin_edges is None and calib_hist is None:
return None
# 每个柱子的值,表示输入的在这个区间的个数
counts = torch.from_numpy(calib_hist[:]).float()
edges = torch.from_numpy(calib_bin_edges[:]).float()
# 取直方图每个柱子的中心
centers = (edges[1:] + edges[:-1]) / 2
mses = []
arguments = []
# 每次扩增一个 bin
for i in range(start_bin, len(centers), stride):
amax = centers[i]
# 伪量化后的中心
quant_centers = fake_tensor_quant(centers, amax, num_bits, unsigned)
# 计算均方根误差
mse = ((quant_centers - centers)**2 * counts).mean()
mses.append(mse)
arguments.append(i)
logging.debug("mses={}".format(mses))
# np.argmin()求最小值对应的索引
argmin = np.argmin(mses)
calib_amax = centers[arguments[argmin]]
return calib_amax
百分比:
_compute_amax_percentile
# 将范围设置为绝对值分布的百分位数。例如,选取tensor的99%或者其他百分比的数值,其余的截断
def _compute_amax_percentile(calib_hist, calib_bin_edges, percentile):
"""Returns amax that clips the percentile fraction of collected data"""
if percentile < 0 or percentile > 100:
raise ValueError("Invalid percentile. Must be in range 0 <= percentile <= 100.")
# If calibrator hasn't collected any data, return none
if calib_bin_edges is None and calib_hist is None:
return None
total = calib_hist.sum()
cdf = np.cumsum(calib_hist / total) # 按行累加
# 在数组cdf中查找percentile / 100对应的区间,返回一个下标列表
idx = np.searchsorted(cdf, percentile / 100)
calib_amax = calib_bin_edges[idx]
# 返回这个张量的值,在浮点数结果上使用 .item() 函数可以提高显示精度
calib_amax = torch.tensor(calib_amax.item()) #pylint: disable=not-callable
return calib_amax
最大值校准
tools/pytorch-quantization/pytorch_quantization/calib/max.py
返回所有收集张量的绝对最大值
class MaxCalibrator(_Calibrator):
"""Max calibrator, tracks the maximum value globally
Args:
calib_desc: A MaxCalibDescriptor.
num_bits: An integer. Number of bits of quantization.
axis: A tuple. see QuantDescriptor.
unsigned: A boolean. using unsigned quantization.
Readonly Properties:
amaxs: A list of amax. Numpy array is saved as it is likely to be used for some plot.
"""
def __init__(self, num_bits, axis, unsigned, track_amax=False):
super(MaxCalibrator, self).__init__(num_bits, axis, unsigned)
self._track_amax = track_amax
if self._track_amax:
self._amaxs = [] # shall we have a better name?
self._calib_amax = None
# pylint:disable=missing-docstring
@property
def amaxs(self):
return self._amaxs
# pylint:enable=missing-docstring
def collect(self, x):
"""Tracks the absolute max of all tensors
Args:
x: A tensor
Raises:
RuntimeError: If amax shape changes
"""
# 校准器遇到负值,ReLU之后不应该发生这种情况
if torch.min(x) < 0.:
logging.log_first_n(
logging.INFO,
("Calibrator encountered negative values. It shouldn't happen after ReLU. "
"Make sure this is the right tensor to calibrate."), 1)
x = x.abs()
# Swap axis to reduce.
axis = self._axis if isinstance(self._axis, (list, tuple)) else [self._axis]
reduce_axis = []
for i in range(x.dim()):
if not i in axis:
reduce_axis.append(i)
# 用于将当前的tensor从计算图中取出,通俗点解释就是,经过detach返回的张量将不会进行反向传播计算梯度
local_amax = quant_utils.reduce_amax(x, axis=reduce_axis).detach()
if self._calib_amax is None:
self._calib_amax = local_amax
else:
if local_amax.shape != self._calib_amax.shape:
raise RuntimeError("amax shape changed!")
self._calib_amax.copy_(torch.max(self._calib_amax, local_amax).data)
if self._track_amax:
self._amaxs.append(local_amax.cpu().numpy())
def reset(self):
"""Reset the collected absolute max"""
self._calib_amax = None
def compute_amax(self):
"""Return the absolute max of all tensors collected"""
return self._calib_amax
看下quant_utils.reduce_amax,代码位于:tools/pytorch-quantization/pytorch_quantization/utils/reduce_amax.py
# 获取张量绝对最大值的函数
def reduce_amax(input, axis=None, keepdims=True):
"""Compute the absolute maximum value of a tensor.
除keepdims为真,沿轴中给定的尺寸减小input_tensor,每个条目的张量的秩将减少1。如果keepdims为真,则减小的尺寸保留为长度1。
.. note::
Gradient computeation is disabled as this function is never meant learning reduces amax
Args:
input: 输入张量
axis: 要减小的尺寸。None或int或int元组。如果无(默认),减小了所有尺寸。必须在范围[-rank(input_tensor),rank(input_tensor))内。
keepdims: 布尔值。如果为真,则保留长度为1的缩小尺寸。默认为True
granularity: 已弃用。指定是否必须以张量或通道粒度计算统计信息
Returns:
The reduced tensor.
Raises:
ValueError: Any axis which doesn't make sense or is not supported
ValueError: If unknown granularity is passed in.
"""
with torch.no_grad():
output = input.abs()
if axis is None:
output = torch.max(output)
else:
if isinstance(axis, int):
output, _ = torch.max(output, dim=axis, keepdim=keepdims)
else:
if isinstance(axis, tuple) and len(axis) > input.dim():
raise ValueError("Cannot reduce more axes than tensor's dim.")
for i in axis:
output, _ = torch.max(output, dim=i, keepdim=True)
# numel()函数:返回数组中元素的个数
if not keepdims or output.numel() == 1:
# 把shape为1的维度去掉
output.squeeze_()
return output