一、基本的SELECT语句
SQL的分类:
DDL:(数据定义语言)(删结构)
CREATE DATABASE(创建数据库)
ALTER DATABASE(修改数据库)
CREATE TABLE(创建新表)
ALTER TABLE(变更(改变)数据库表)
DROP TABLE(删除表)
CREATE INDEX(创建索引(搜索键))
DROP INDEX(删除索引)
RENAME(重命名)
TRUNCATE(清空)
DML:(数据操作语言)(删一条记录)
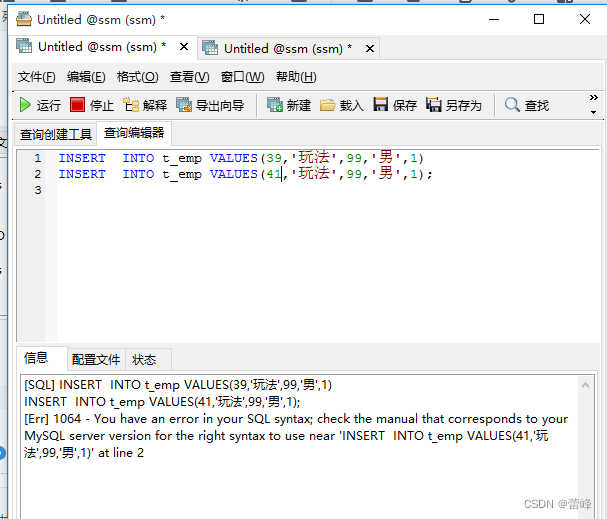
INSERT INTO(添加一条记录,向数据表中插入数据)
INSERT INTO t_emp values()
DELETE(删除,从数据库表中删除数据)
UPDATA(修改,更新数据库表中的数据)
SELECT(查询,从数据库表中获取数据)
DCL:(数据控制语言)
COMMIT(提交)\ROLLBACK(回滚,撤销)\SAVEPOINT(事务,回滚到具体的一个保存点上))|
GRANT(赋予相关的权限)、REVOKE(回收相关的权限)
SQL语言的规则与规范:
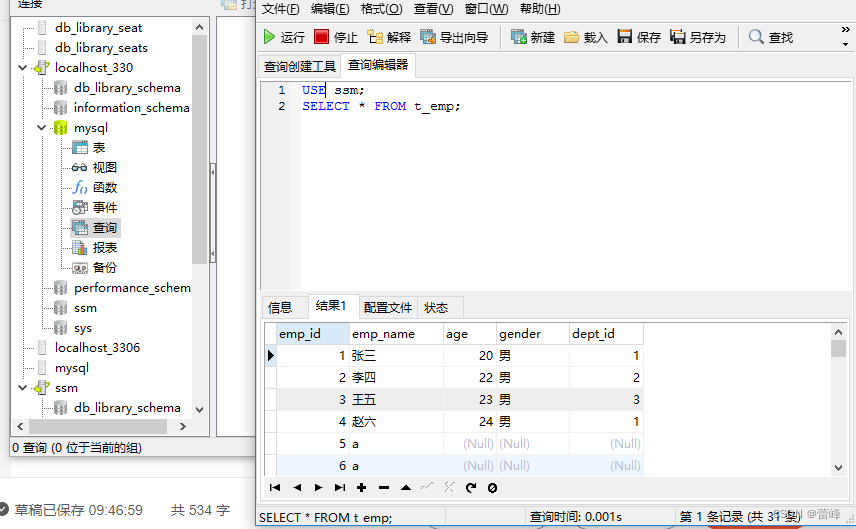
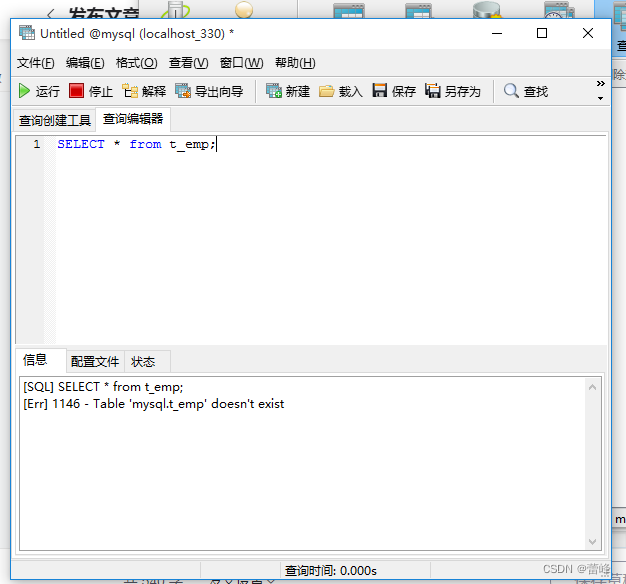
使用一个表之前先使用数据库:
USE ssm:
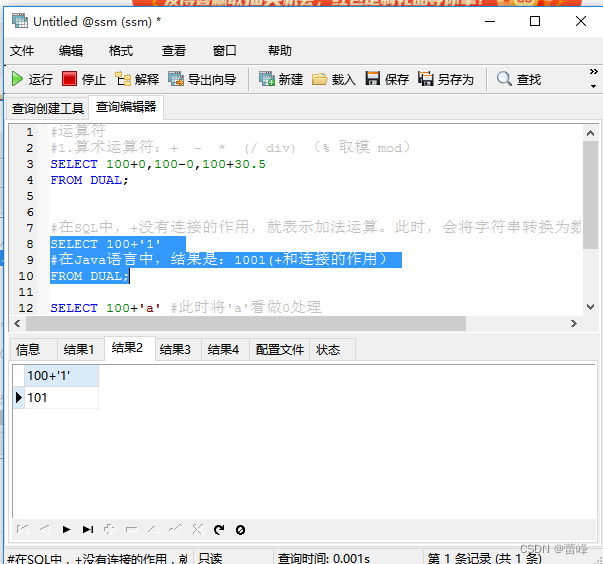
如果我们没有使用这句话,我们在查询过程中,换个数据库进行查询的时候会出现:
SELECT * FROM t_emp;
查询如下的时候,我们在原来的数据库进行查询,换个数据库继续查询,没有之前字段的话,就会出现错误。
我们换数据库之后如下所示:
我们发现出现了错误,所以当我们有多个数据库的时候,我们可以在前面加use语句,确保查询正确进行。
每条命令以;结束,单条命令执行的时候,;可写可不写。多条命令执行的时候,就必须要写。
我们出错如下所示:
我们也可以以\G和\g结束
我们在软件里面发现报错,我们可以利用命令提示符来进行演示。


1.命名规则:
列的别名可以用双引号表示,字符串型和日期时间类型用单引号 ' ' 。
MySQL在Windows环境下是大小写不敏感的,MySQL在Linux环境下是大小写敏感的。
数据库名、表名、表的别名、变量名是严格区分大小写的
关键字、函数名、列名(或字段名)、列的别名(字段的别名)是忽略大小写的
数据库名、表名、表的别名、字段名、字段别名等都小写
SQL关键字、函数名、绑定变量等都大写。
注释:#当行注释
-- 注释文字(--后面有一个空格)
/* */多行注释
命名规则:
1.数据库、表名不得超过30个字符,变量名限制为29个
2必须只能包含A-Z、a-z、0-9,_共63个字符
3.数据库名、表名、字段名等对象名中间不要包含空格
4.同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名。
5.必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,在SQL语句中使用'(着重号)引起来
6.保证字段名和类型的一致性,在命名字段并为其之指定数据类型的时候一定要保证一致性,假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了。
可以在Mysql>source 地址。
也可以通过软件创建新的数据库进行运行导入。(新建数据库,然后运行sql文件,进行刷新即可)
2.基本的SELECT语句:SELECT ......FROM ...
SELECT 1+1,3*2;
SELECT 1+1,3*2 FROM DUAL; #DUAL:伪表
# *:表中的所有的字段(或列)
SELECT * FROM t_user;
SELECT id,username FROM t_use;
列的别名:
#列的别名
#可以通过空格来进行别名的创建
#AS:全称:alias(别名),可以省略
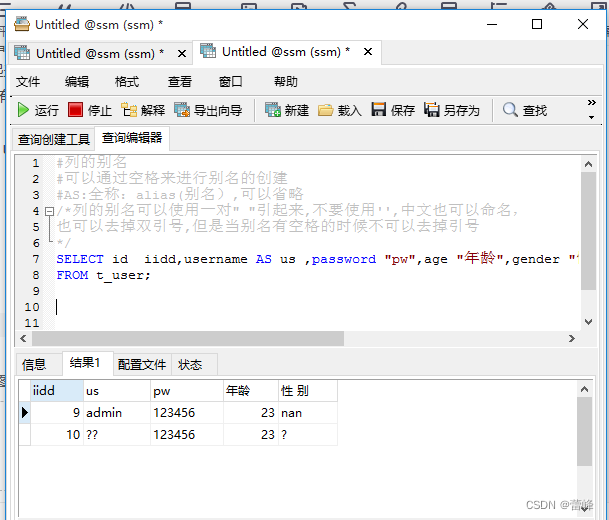
/*列的别名可以使用一对" "引起来,不要使用'',中文也可以命名,
也可以去掉双引号,但是当别名有空格的时候不可以去掉引号
*/
SELECT id iidd,username AS us ,password "pw",age "年龄",gender "性 别"
FROM t_user;我们如下所示:
3.去除重复行 DISTINCT
#去除重复行:
#关键词 DISTINCT 用于返回唯一不同的值。
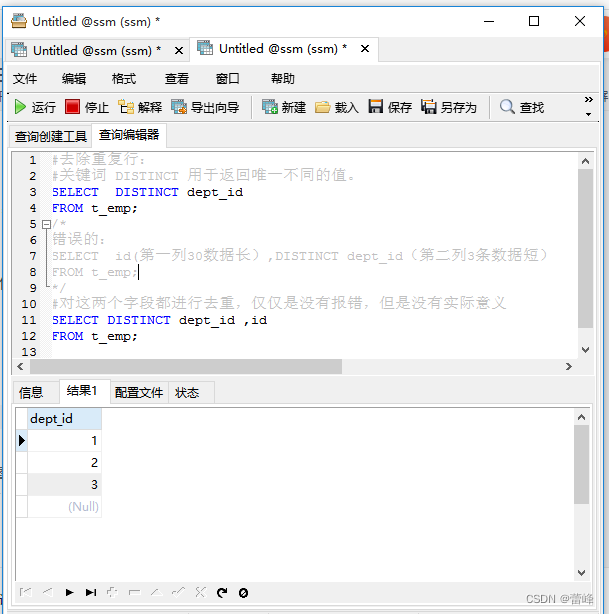
SELECT DISTINCT dept_id
FROM t_emp;
/*
错误的:
SELECT id(第一列30数据长),DISTINCT dept_id(第二列3条数据短)
FROM t_emp;
*/
#对这两个字段都进行去重,仅仅是没有报错,但是没有实际意义
SELECT DISTINCT dept_id ,id
FROM t_emp;
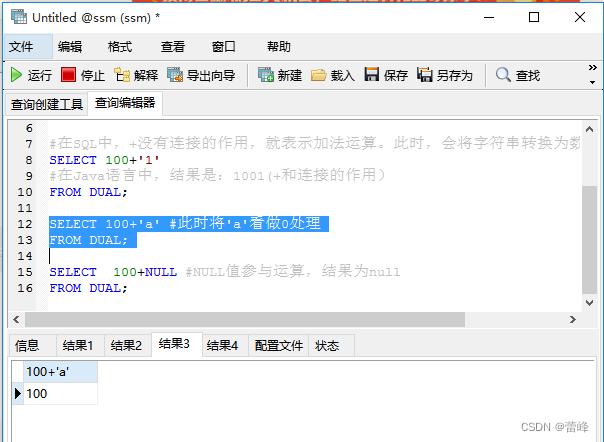
4.空值参与运算:
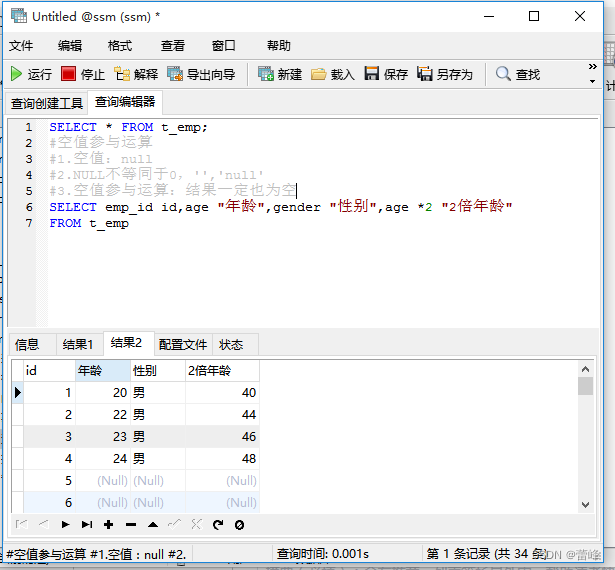
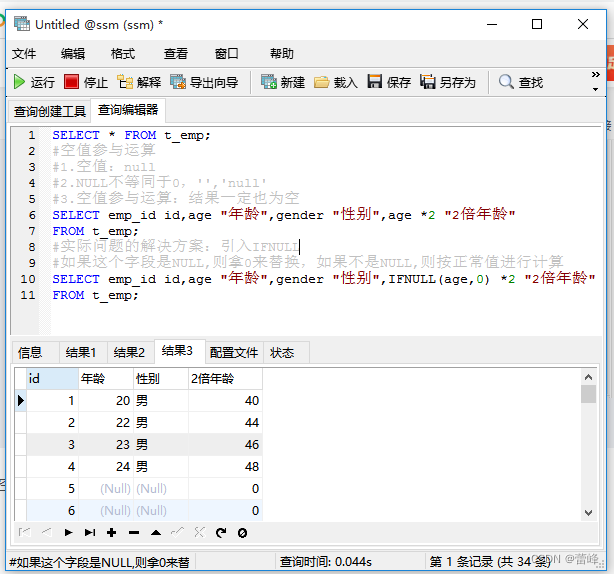
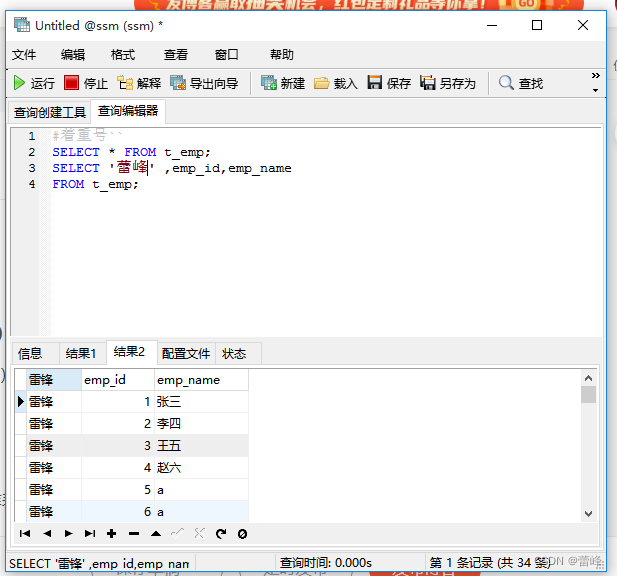
5.着重号:
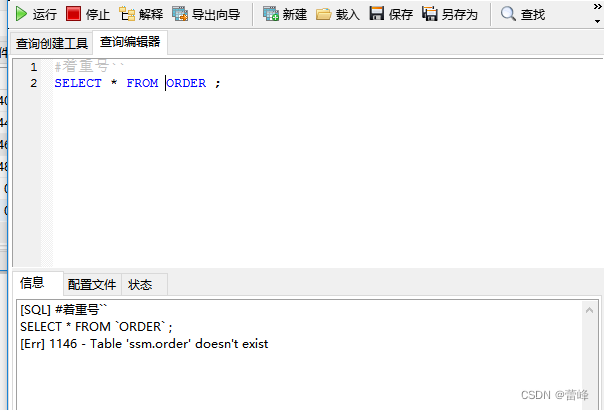
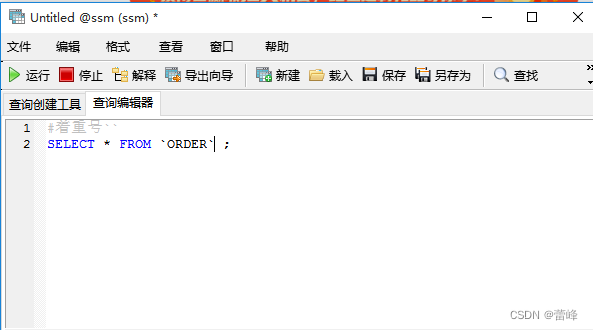
6.查询常数
当我们要用一个字段,而这个字段又不出现在这个表里,我们可以通过常量的形式进行添加。
7.显示表结构
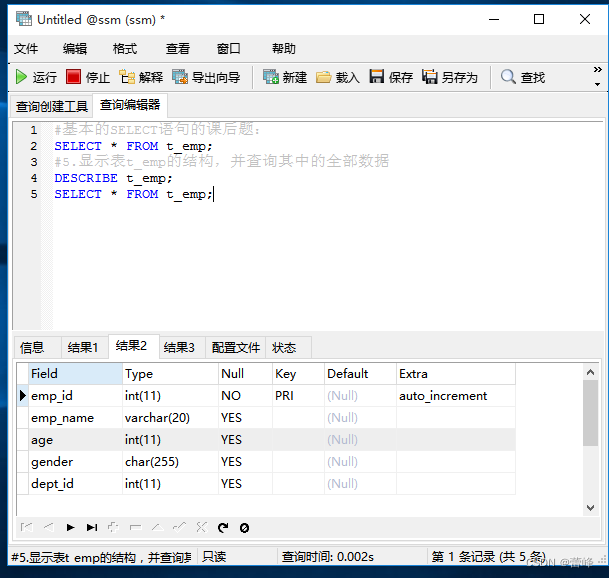
使用DESCRIBE或DESC命令,表示表结构

8.过滤数据:

课后题目:
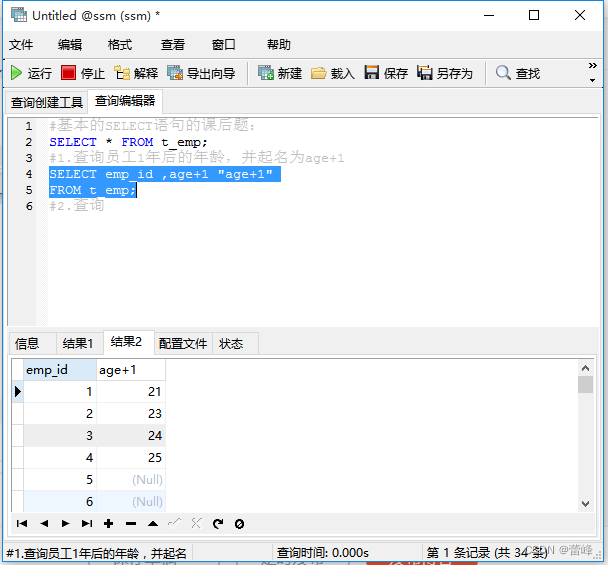
1.查询员工1年后的年龄,并起名为age+12.
2.查询表中去除重复部门以后的数据
3. 查询员工id小于5的员工姓名和年龄
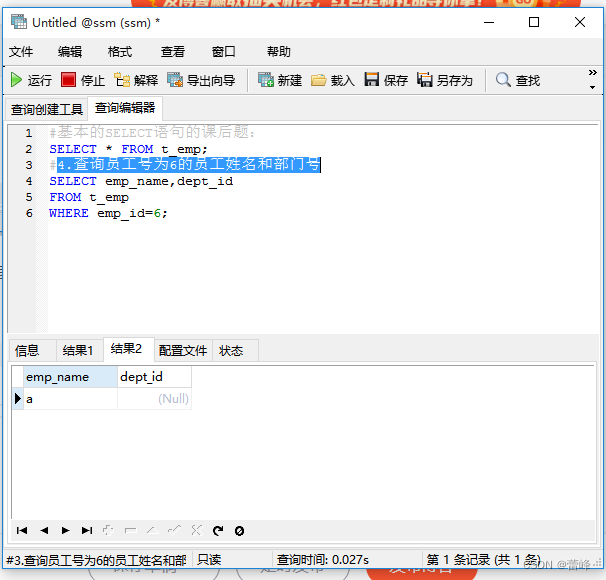
4.查询员工号为6的员工姓名和部门号:
5.显示表t_emp的结构,并查询其中的全部数据


二、运算符
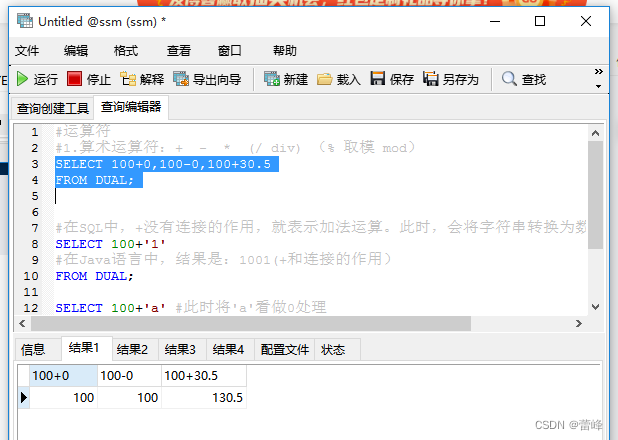
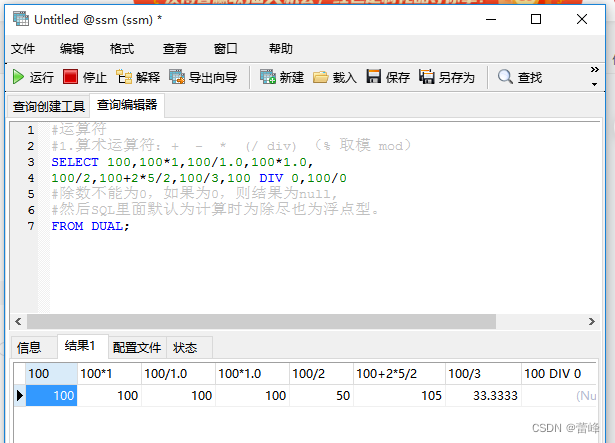
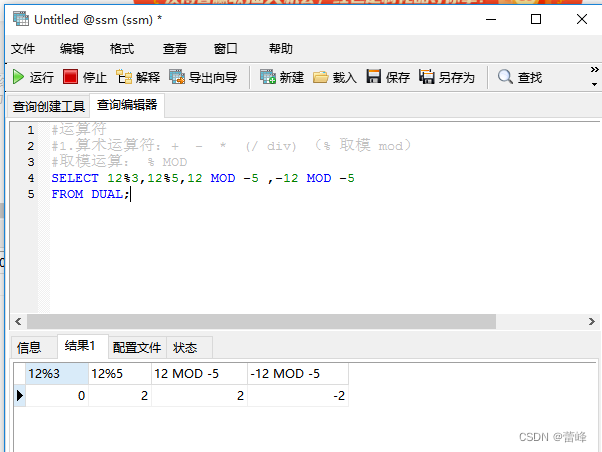
1.算术运算符:
取模运算:
与被模数的正负有关。

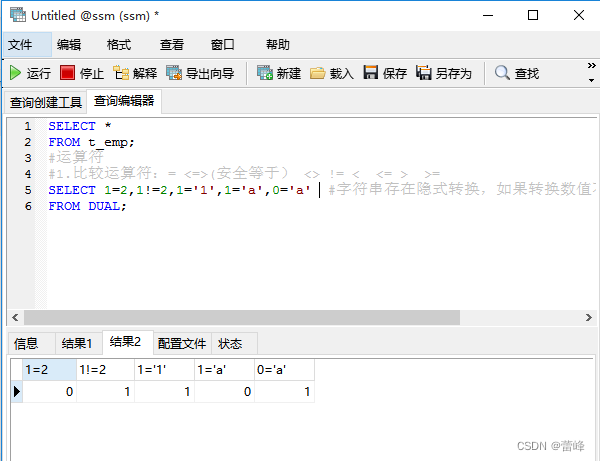
2.比较运算符
比较的结果为真,则返回1。
比较的结果为假,则返回0.
其他情况则返回NULL
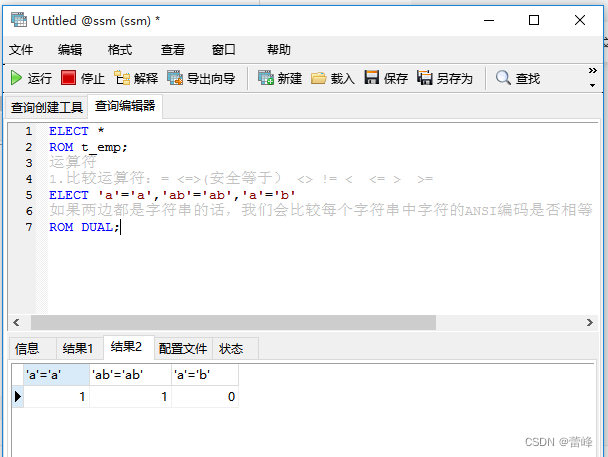
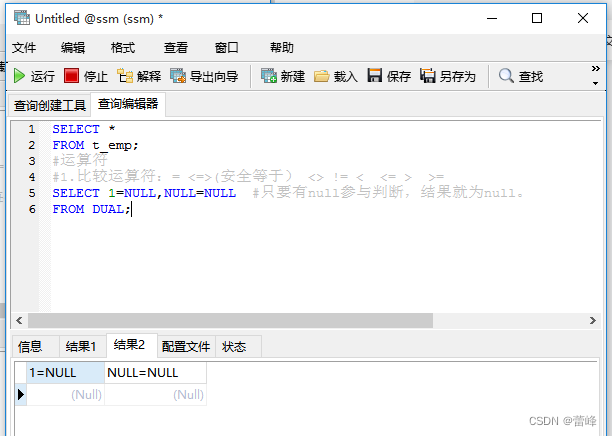
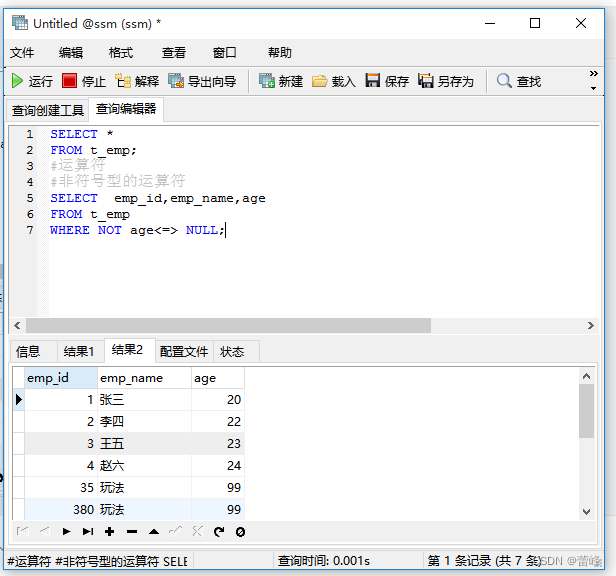
只要NULL参与运算,就不会有任何的结果: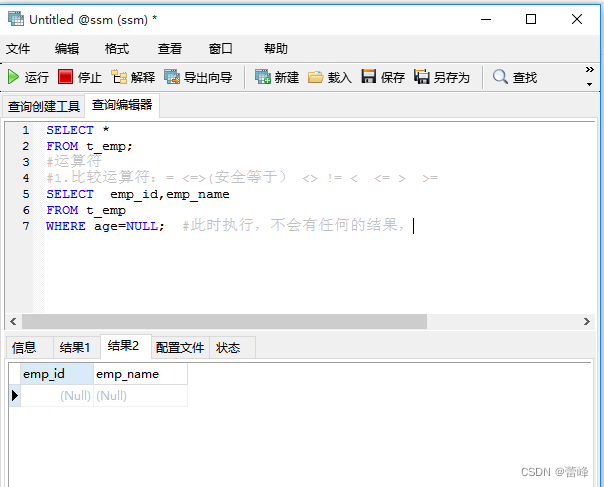
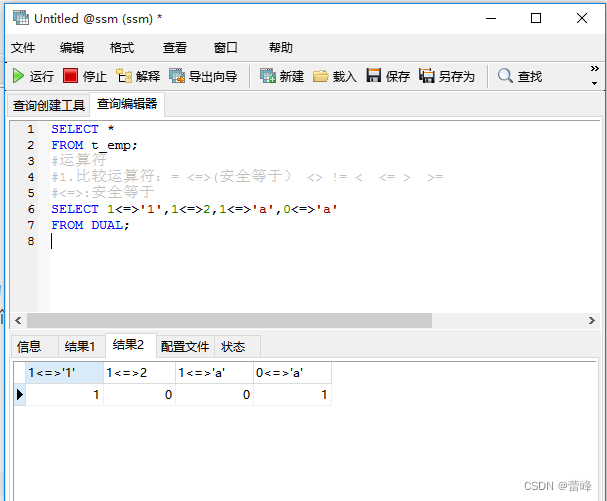
<=>安全等于运算符:
与等于运算符(=)的作用是相似的,唯一的区别是<=>可以用来对NULL进行判断,在两个操作数均为NULL时,其返回值为1,当一个操作数为NULL时,其返回值为0.而不是NULL。
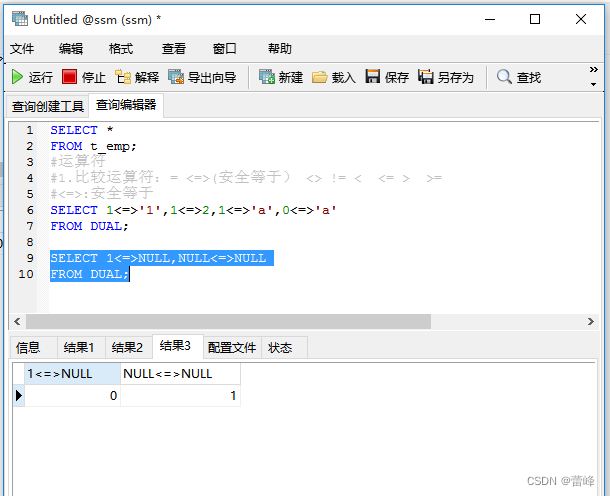
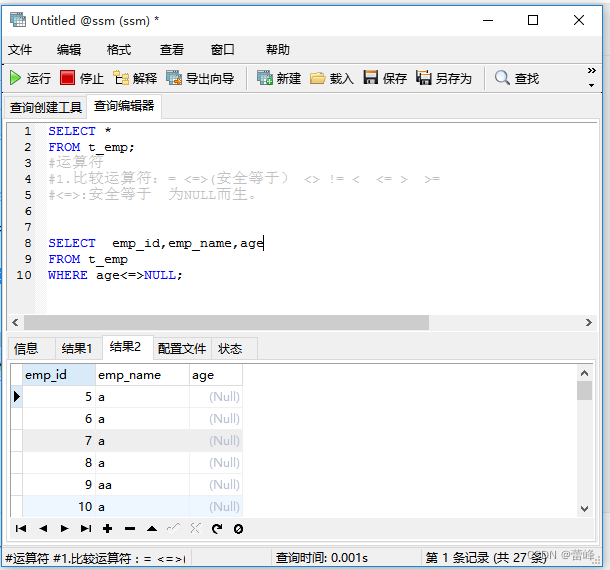
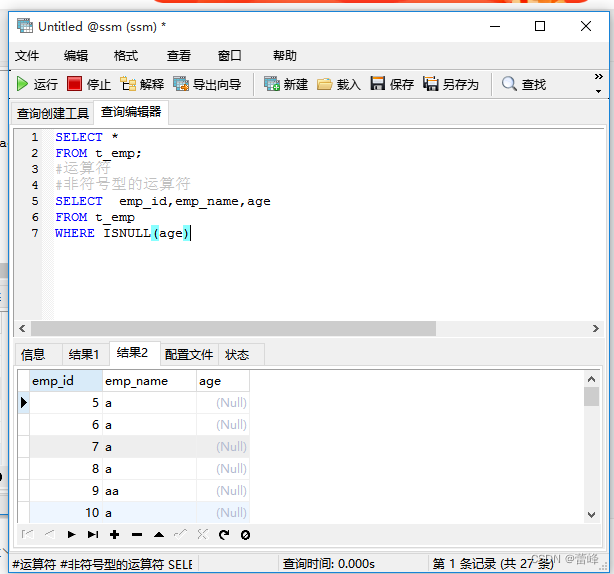
3. 非符号型的运算符:
ISNULL 、IS NULL 、 IS NOT NULL:判断空还是不空
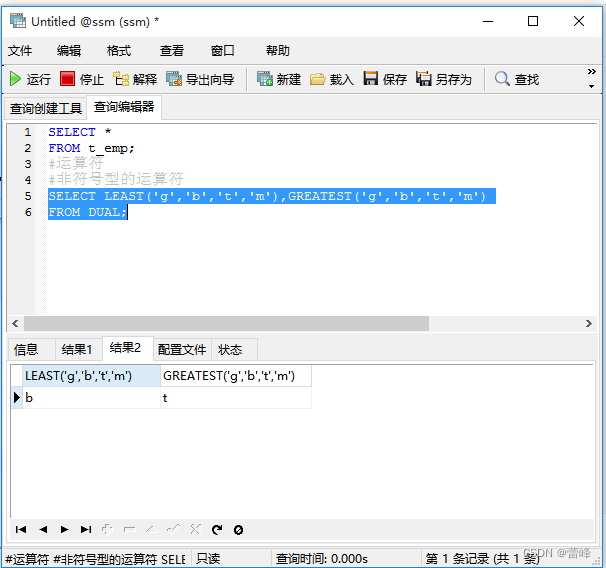
LEAST:最小值运算符
GREATEST:最大值运算符
BETWEEN AND:两者之间运算符
IN:是否在列表里面
NOT IN:不属于运算符
LIKE:是否符合模糊匹配规则
(1)ISNULL 、IS NULL 、 IS NOT NULL:判断空还是不空
我们表中的字段用IS NULL ,IS NOT NULL,而比如数字比较的时候我们用<=>。


(2) LEAST:最小值运算符
GREATEST:最大值运算符

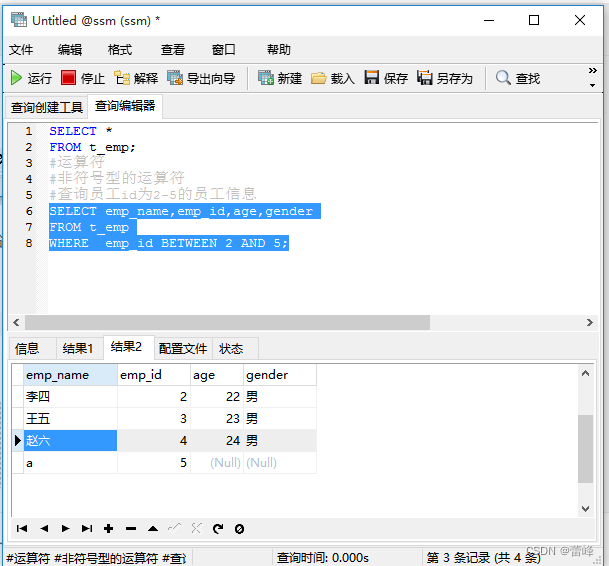
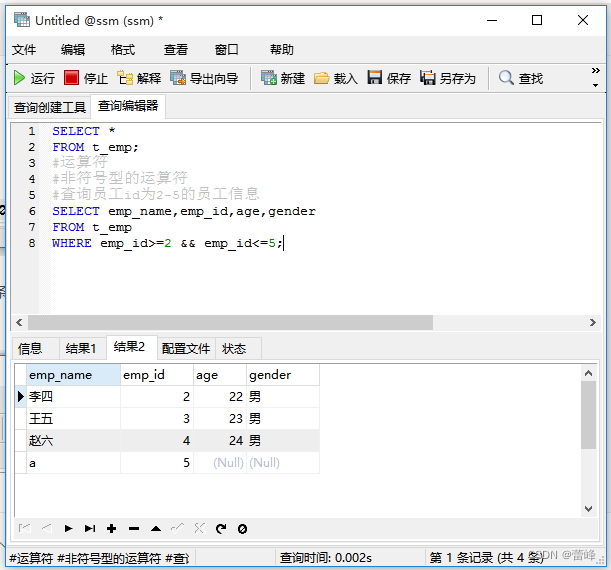
(3) BETWEEN 条件下界1 AND 条件上界2 (查询条件1和条件2范围内的数据,包含边界):两者之间运算符
交换2和5之后,查询不到数据
查询员工id不在2到5的员工信息:


(4)IN(set集合):是否在列表里面
NOT IN)(set集合):不属于运算符
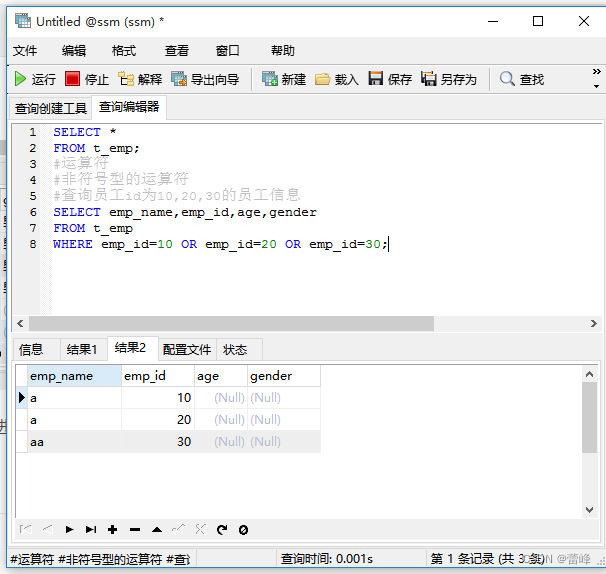
查询员工为10,20,30id的员工信息
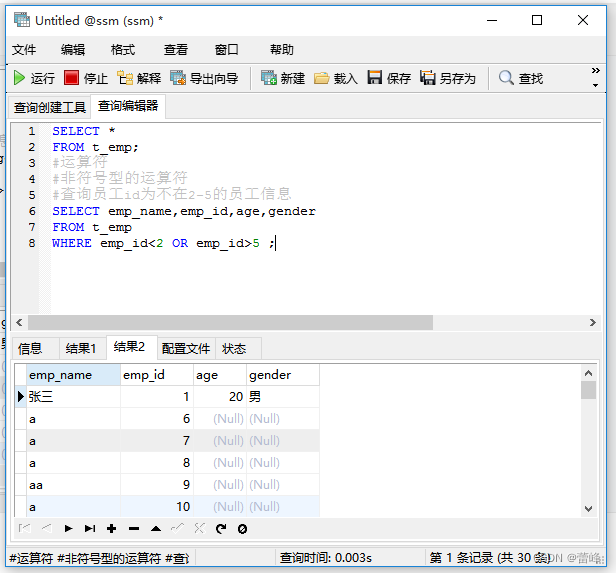
我们也可以使用OR来进行查看:
我们发现这样子查询不对,我们来进行补充条件:
我们下来通过IN来进行判断:
查询员工id不是10,20,30的员工信息:


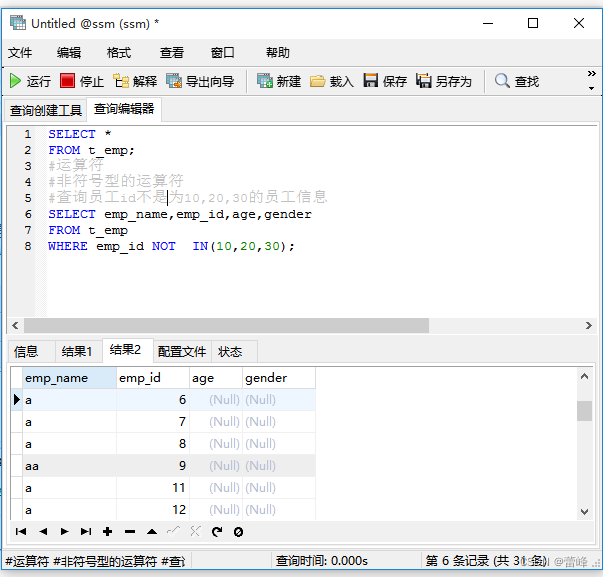
(5) LIKE:是否符合模糊匹配规则(模糊查询)
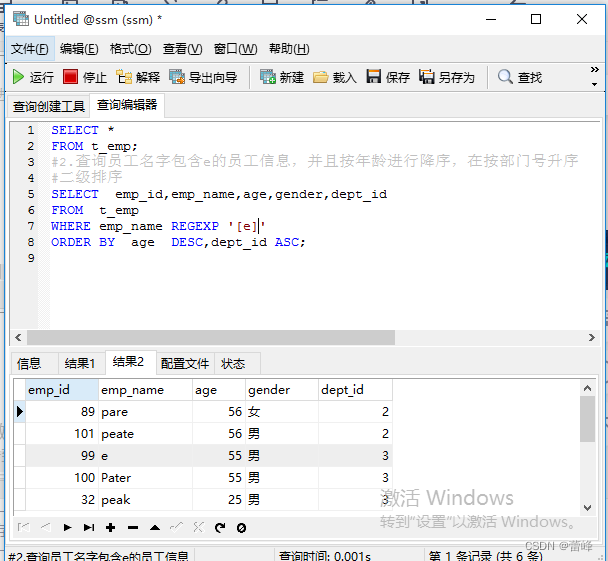
查询员工名字里面包含字符'a'且包含字符'e'的员工信息:
方法一:
方法二:
我们不确定是否是a在前面还是是b在前面,我们可以把两种情况全部加载进去:
查询第二个字符是'a'的员工信息:
查询第二个字符是_且第三个字符是'a'的员工信息:




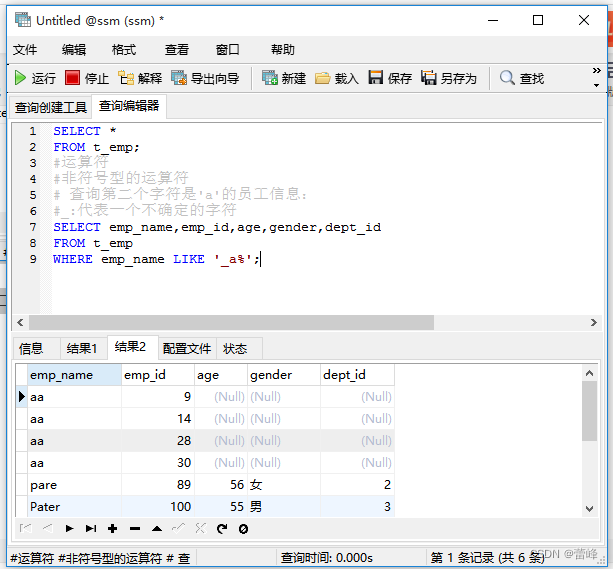

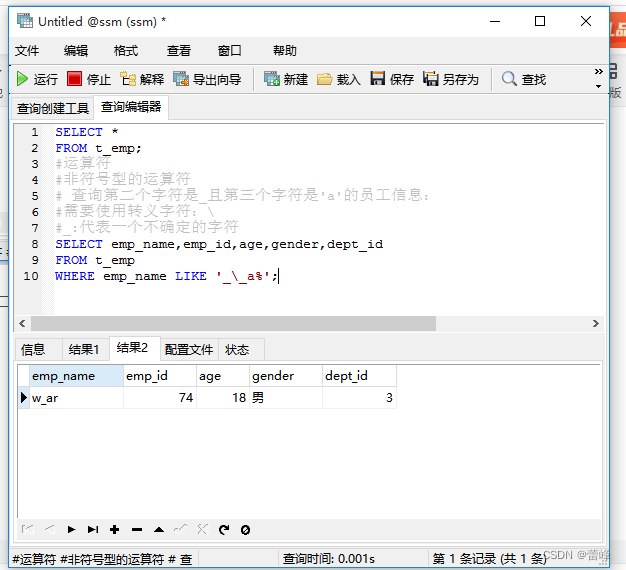
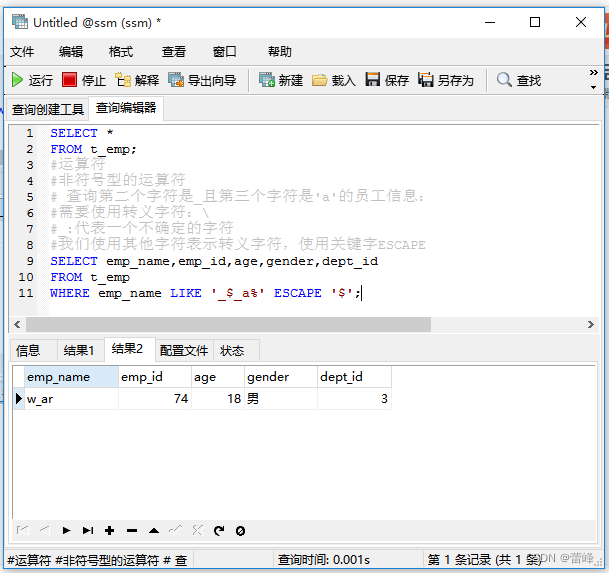
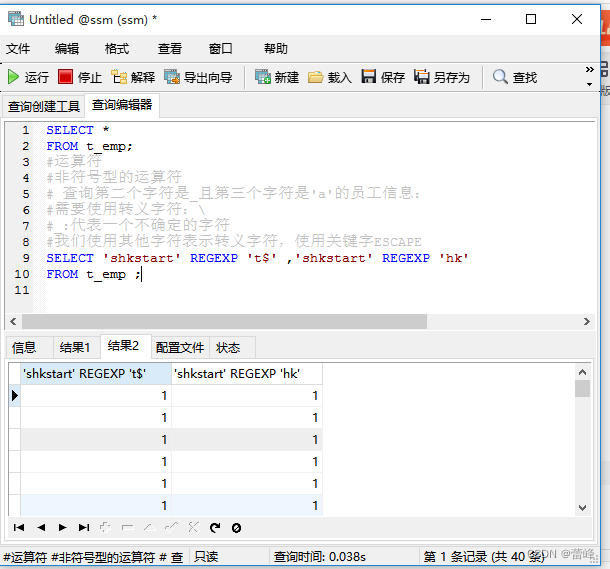
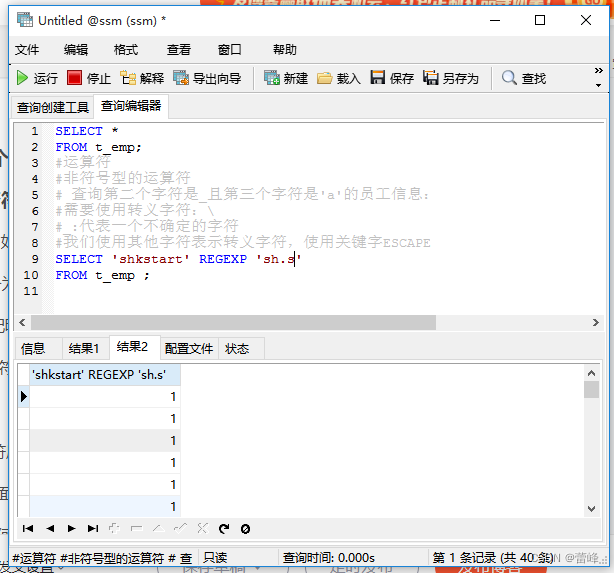
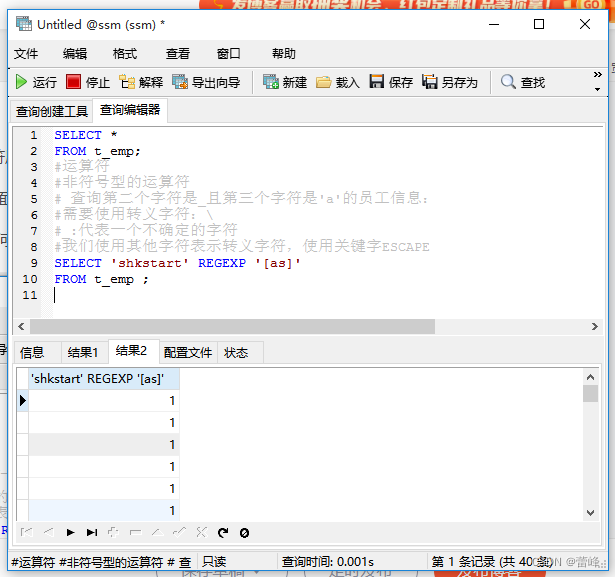
(6)REGEXP:判断一个值是否符合正则表达式的规则
RLIKE: 判断一个值是否符合正则表达式的规则
expr REGEXP 匹配条件:如果expr满足匹配条件,返回1;如果不满足,则返回0.
若expr或匹配条件任意一个为NULL,则结果为NULL.
REGEXP运算符在进行匹配时,常用的有下面几种通配符:
1.'$'匹配以该字符前面的字符结尾的字符串
2.'.'匹配任何一个单字符
3.‘向下的箭头'匹配以该字符后面的字符开头的字符串
4.'*'匹配零个或多个在它前面的字符
5.“[ ]"匹配在方括号内的任何字符
3.逻辑运算符
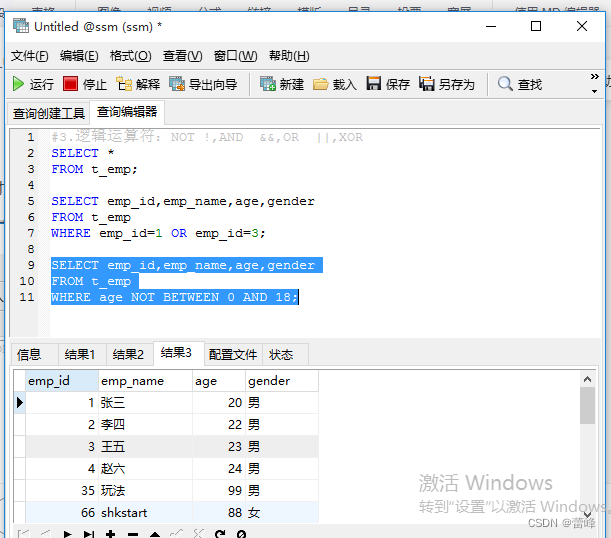
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1,0或者NULL。
(1)NOT或 !(逻辑非)(非假得真,非真得假)
(2)AND 或 &&(逻辑与)(有假则假,全为真才为真)
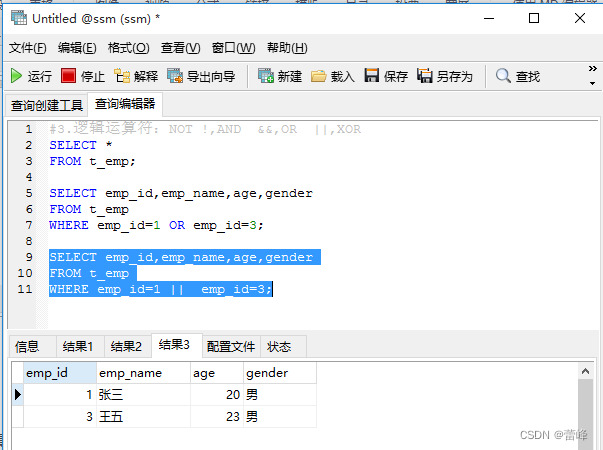
(3)OR 或 ||(逻辑或)(有真则真)
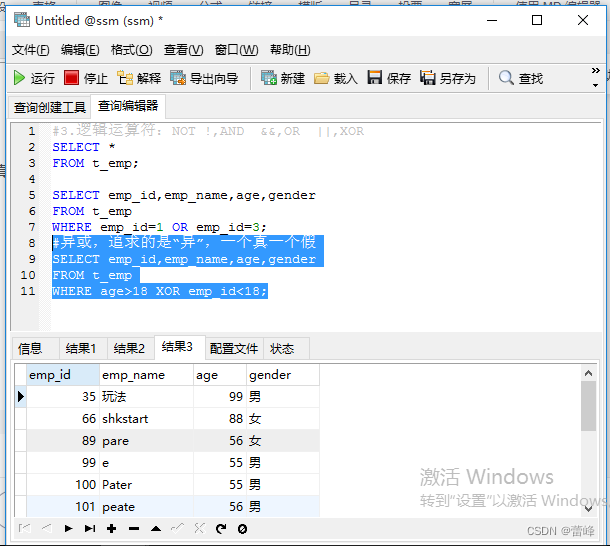
(4)XOR(逻辑异或,一个为真则全为真,全为真或全为假则为假)满足其中一个条件但是不满足另一个条件
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,在与OR中的操作数进行结合。



4.位运算符
位运算符是在二进制数上进行计算的运算符,位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数。
>> 按位右移
<<按位左移
&按位与
| 按位或
~按位取反
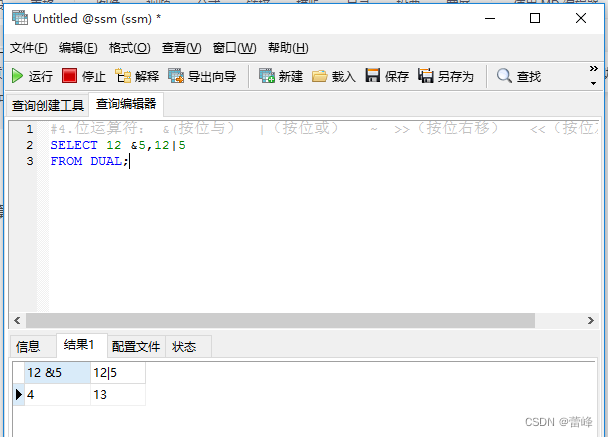
我们的底层都是二进制进行存储的,一位为8个字节,12为8+4,2的三次方加2的2次方,即为00001100,而5为2的2次方加1,为00000101,我们进行按位与操作,即为全为真则真,为00000100,即为4.
12=8+4,2的三次方加2的2次方,即为00001100,而5为2的2次方加1,为00000101,我们进行按位或操作,即为有真则真,为00001101,为2的2次方加2的3次方加1,等于13。
按位取反:
按位取反(~)运算符将给定的值的二进制数逐位进行取反操作,即将1变为0,将0变为1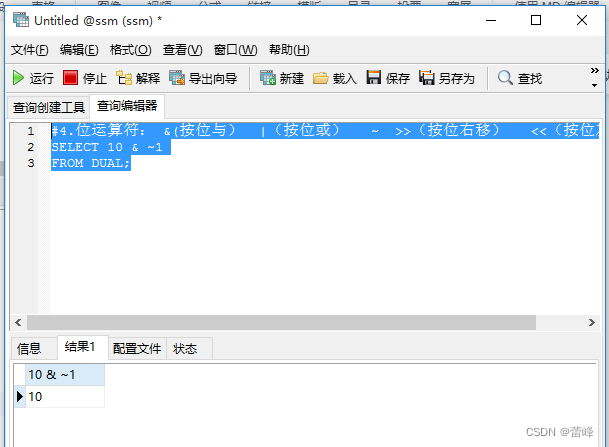
我们进行按位取反的底层操作:
我们的底层都是二进制进行存储的,一位为8个字节,
1的00000001,我们进行取反操作之后为11111110,
10为8+2,为2的3次方和2的一次方,为00001010
我们进行按位与操作,全为真才为真,00001010,为10.

我们进行二进制运算,4为00000100,我们向左移一位,为00001000,为2的三次方为8。
8为00001000,我们向右移一位,为00000100,为2的2次方,为4.
运算符课后练习:
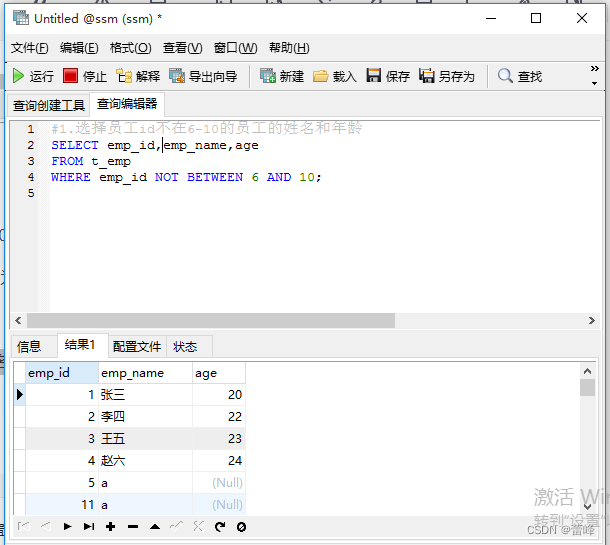
1.选择员工id不在6-10的员工的姓名和年龄:
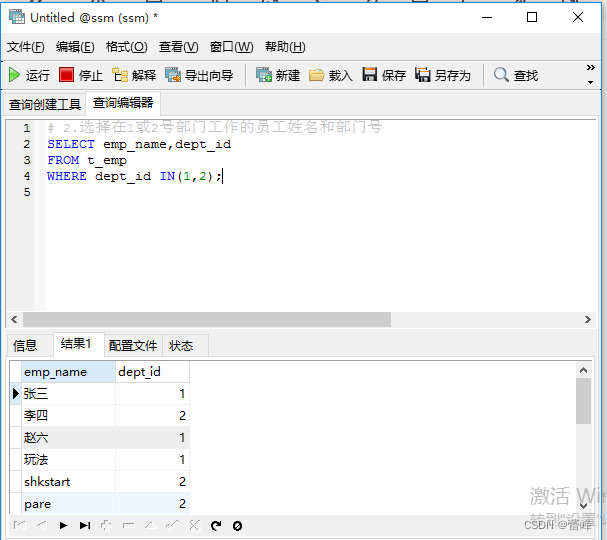
2.选择在20或50号部门工作的员工姓名和部门号

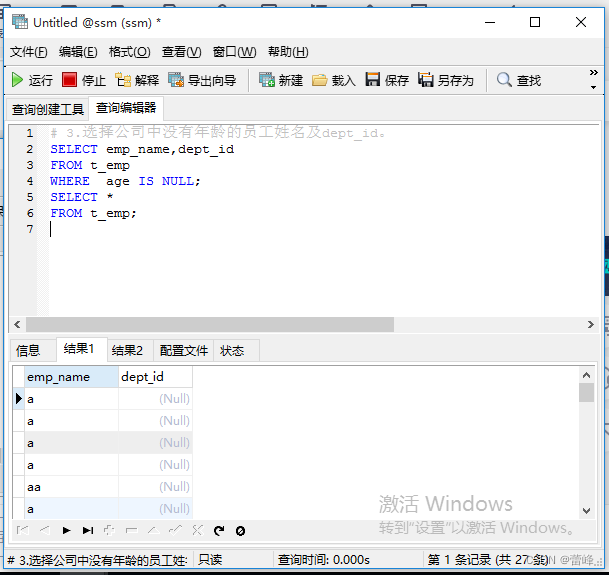
3.选择公司中没有年龄的员工姓名及dept_id。
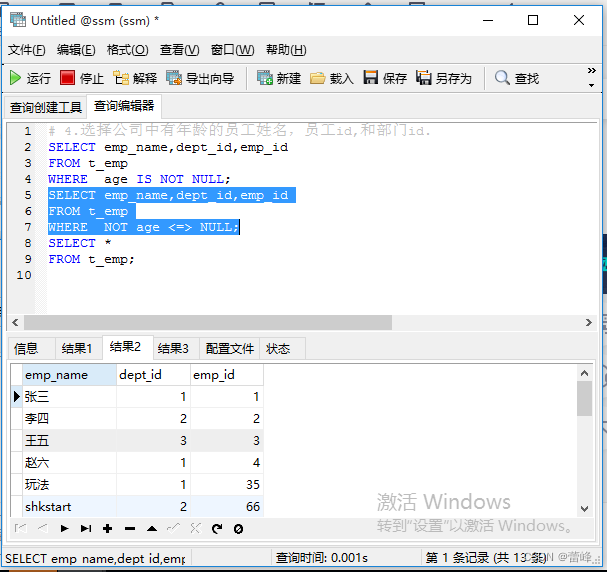
4.选择公司中有年龄的员工姓名,员工id,和部门id.

5.选择员工姓名的第三个字母是a的员工姓名:

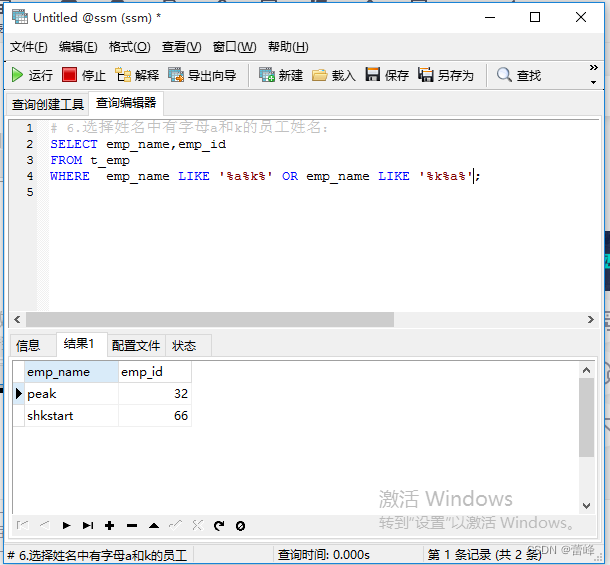
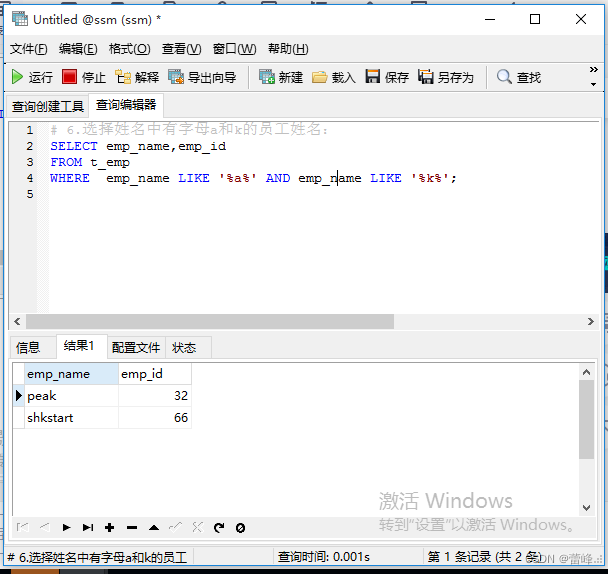
6.选择姓名中有字母a和k的员工姓名:
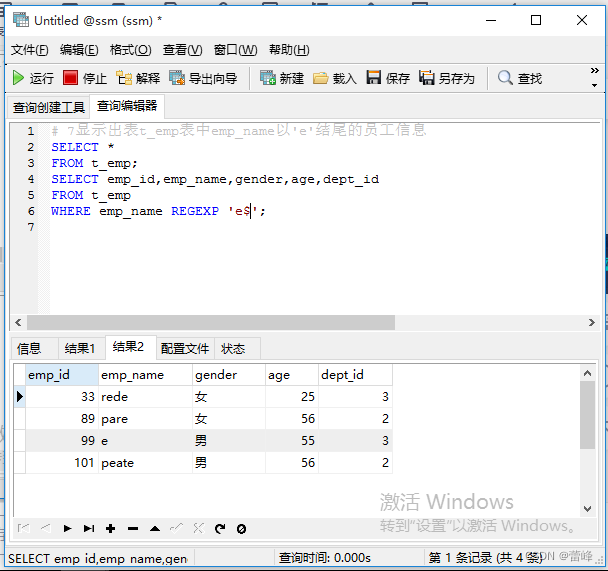
7.显示出表t_emp表中emp_name以'e'结尾的员工信息

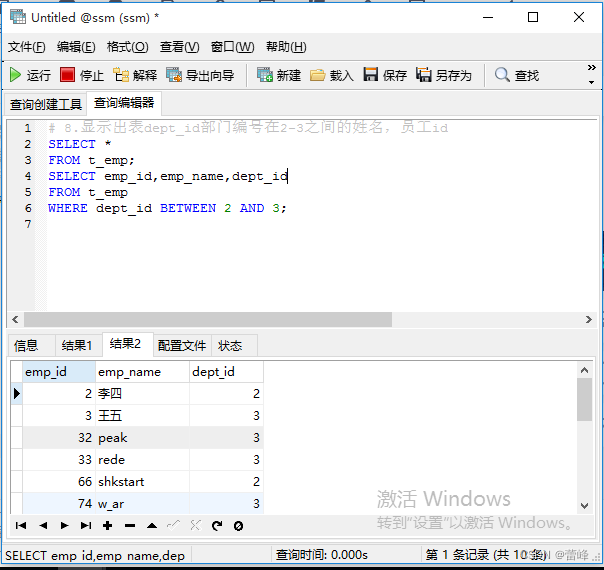
8.显示出表dept_id部门编号在2-3之间的姓名,员工id
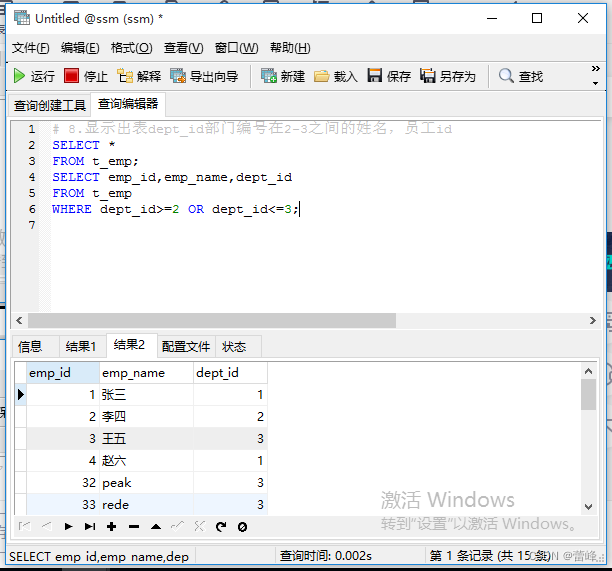
以下方式在查询出来的时候可能与以上结果会有不同之处。仅试用于本题。

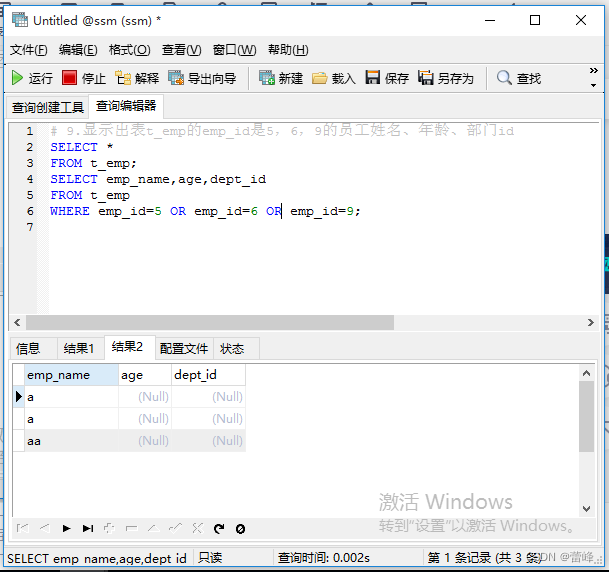
9.显示出表t_emp的emp_id是5,6,9的员工姓名、年龄、部门id

三、排序与分页
1.排序
1.1排序规则
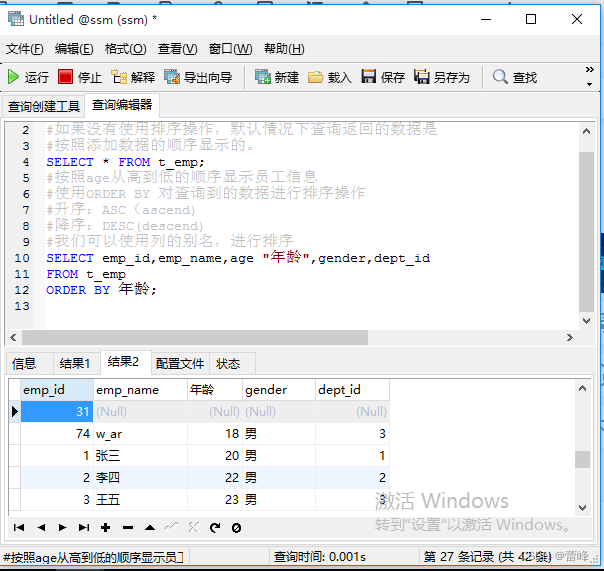
(1)使用ORDER BY 对查询到的数据进行排序操作
升序:ASC(ascend)
降序:DESC(descend)(2)我们可以使用列的别名,进行排序
列的别名只能在ORDER BY中使用,不能在WHERE中使用
(3) 强调格式:WHERE需要声明在FROM后,ORDER BY之前。
列的别名:
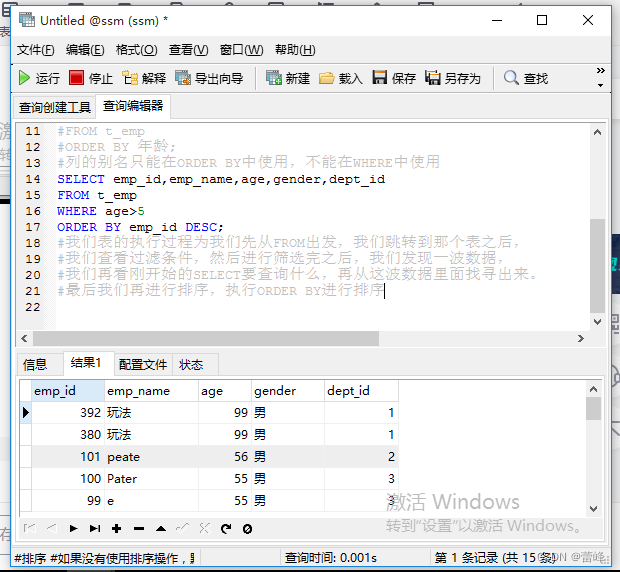
二级排序:
在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。

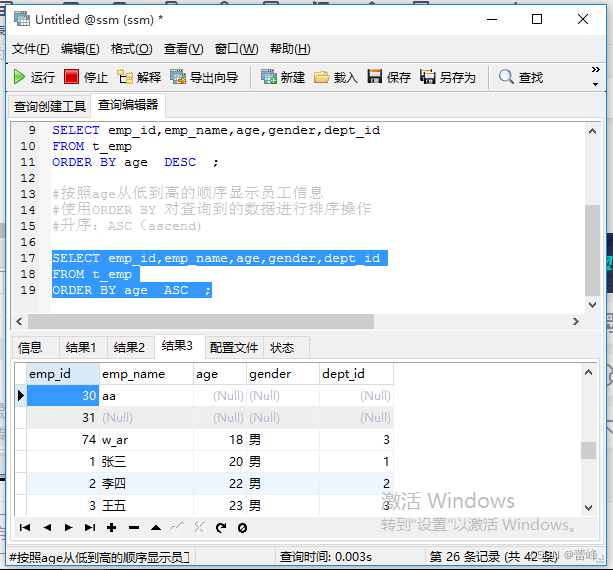
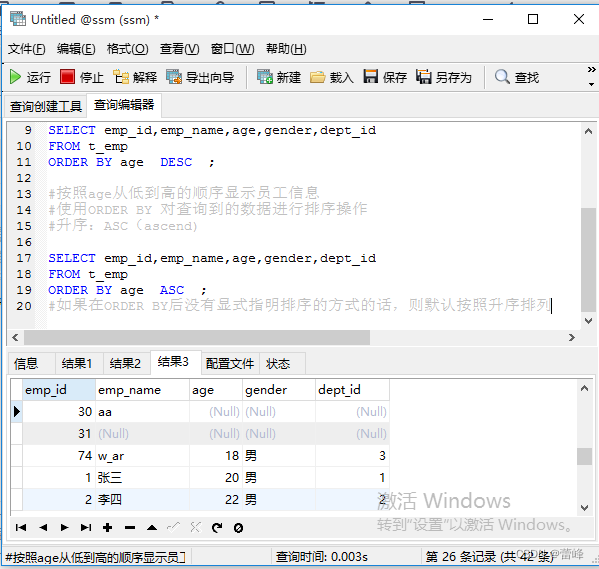


2.分页
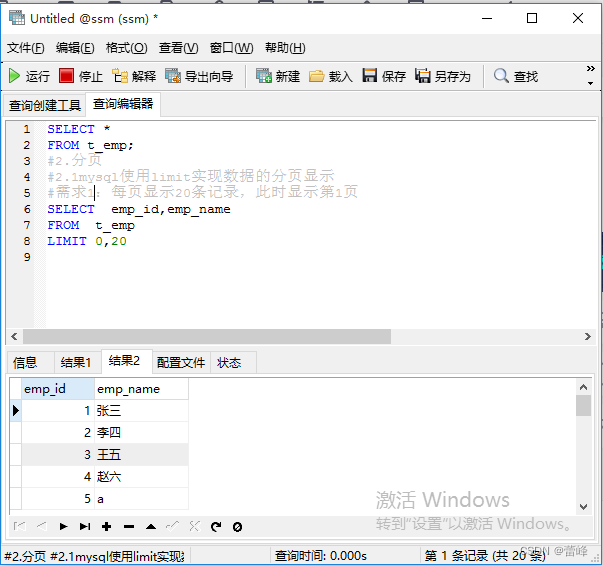
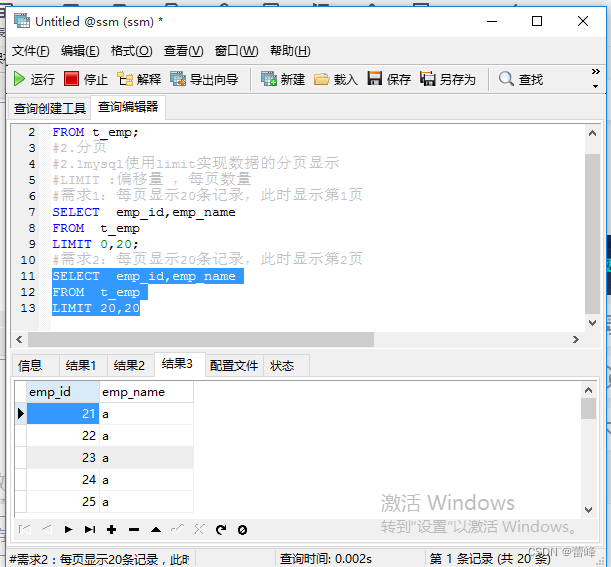
2.12.2mysql使用limit实现数据的分页显示:
每页显示pageSize条记录,此时显示第pageNo页:
公式:LIMIT (pageNo-1)*pageSize,pageSize;
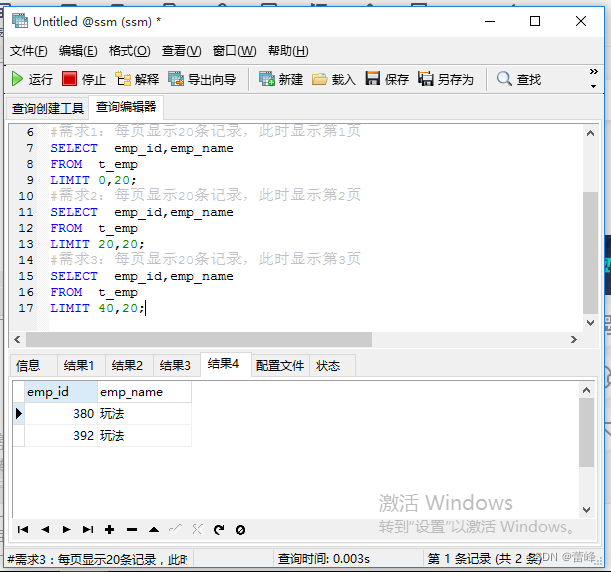
2.2WHERE.....ORDER BY.......LIMIT 的声明顺序如下:
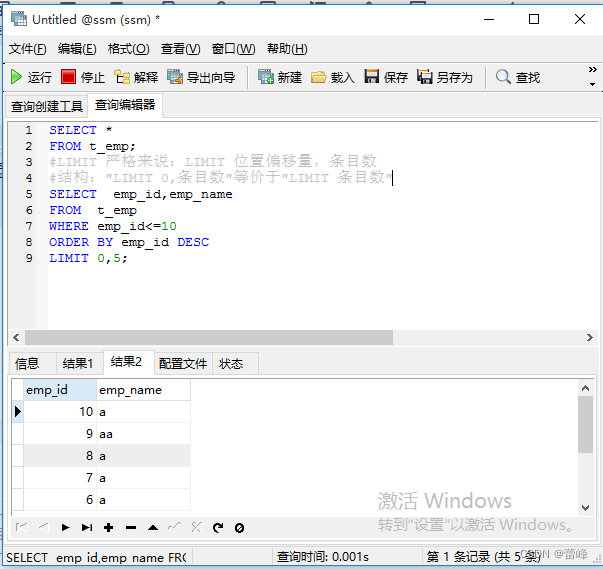

2.3MySQL8.0新特性:LIMIT....条目数..OFFSET...偏移量..
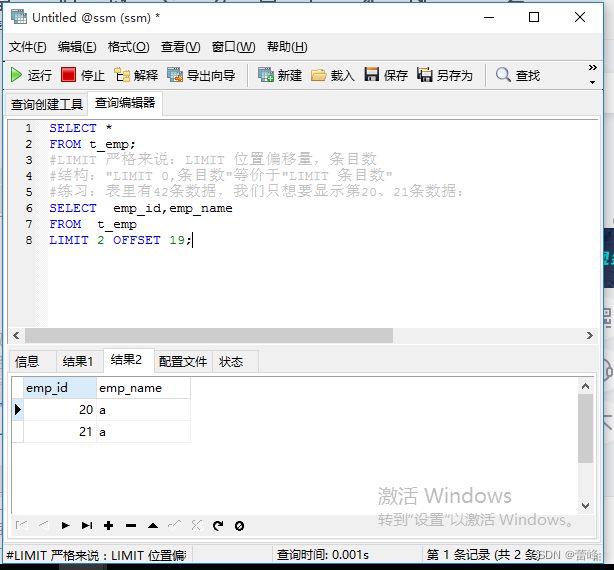
LIMIT子句必须放在整个SELECT语句的最后。
分页操作:
我们使用DB2数据库,我们使用FETCH FIRST 5 ROWS ONLY这样子的关键字来实现分页操作。
SELECT emp_id,emp_name,age,gender
FROM t_emp
ORDER BY age DESC
FETCH FIRST 5 ROWS ONLY; 我们使用SQL Server 和Access,需要使用TOP关键字,比如:
SELECT TOP 5 name, emp_id,emp_name,age,gender
FROM t_emp
ORDER BY age DESC
我们使用Oracle,我们基于ROWNUM,如下所示:
SELECT ROWNUM, emp_id,emp_name,age,gender
FROM t_emp
WHERE ROWNUM<5
ORDER BY age DESC;
2.4LIMIT可以使用在MySQL、PGSQL、MariaDB、SQLite等数据库中使用,表示分页。
不能使用在SQL Server 、DB2、Oracle!
排序与分页课后练习:
1.查询员工的姓名和员工id和年龄,按年龄进行降序,按姓名升序显示。
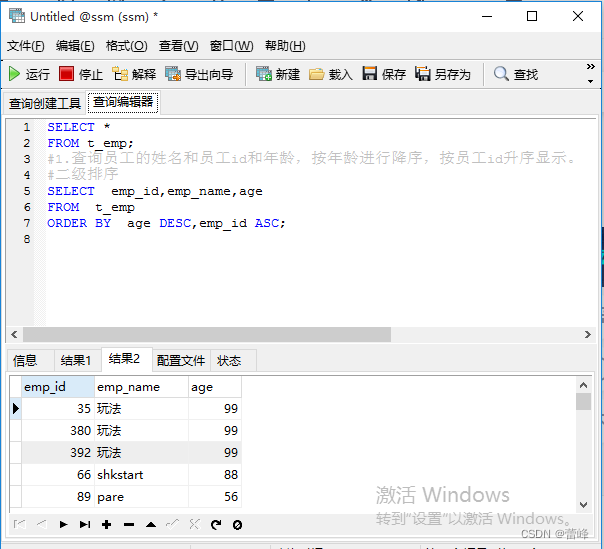
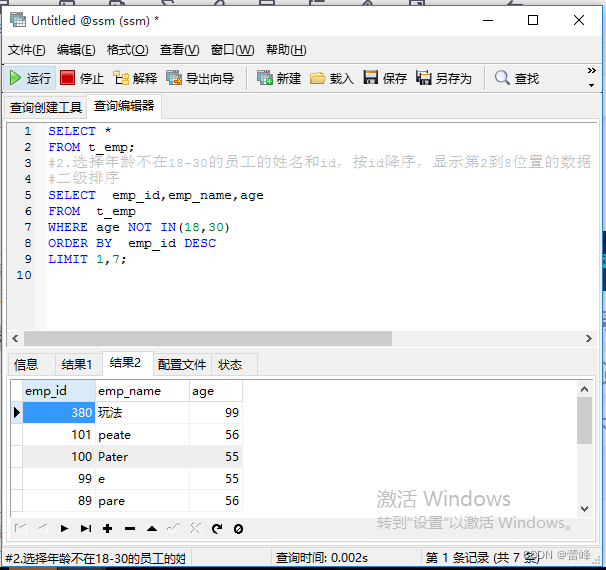
2.选择年龄不在18-30的员工的姓名和id,按id降序,显示第2到8位置的数据
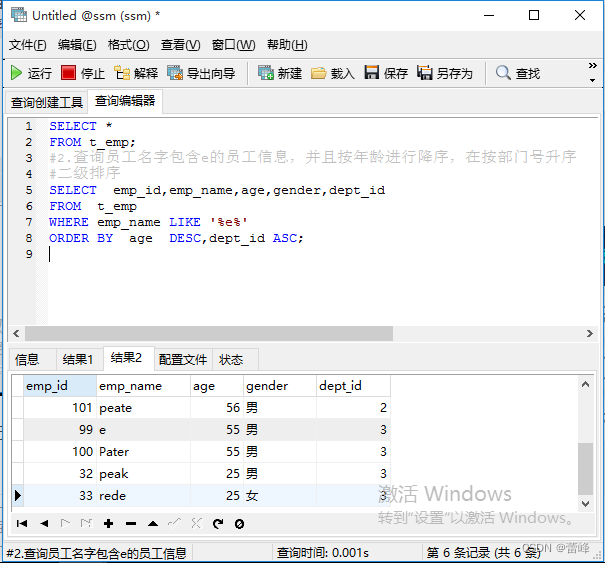
3.查询员工名字里面包含e的员工信息,并且按员工id进行降序,在按部门号升序
正则表达式: