1. 正则化的目的
在对已有的数据进行训练时,由于在实际中不可能获取无穷无尽的数据去训练,以获取一个泛化性能特别好的模型,所以针对当前的有限数据,学习出的模型很有可能会出现过拟合,也就是过分的拟合当前的数据,或者说模型太过复杂。
针对过拟合现象,正则化是人为的降低了模型的复杂度,类似于剪枝策略。希望在最小化训练误差的同时,通过这种正则化还能够提升模型的泛华能力。
2. L1正则化
L1正则化就是权值向量各个分量的绝对值之和,它更容易获得一个稀疏解。
3. L2正则化
L2正则化是权值向量的模的和,它对模型的过拟合有非常好的效果。
4. 为什么L1能够更容易获得一个稀疏解?
可以从三个方面来解释
- 首先从解空间的角度来看,因为L1它是各个分量的绝对值之和,所以在加入L1正则化后,相对于为原始的解空间加上了一个多边形的约束空间。而L2正则化是对各个分量的模的和,它的解空间约束是一个圆形。
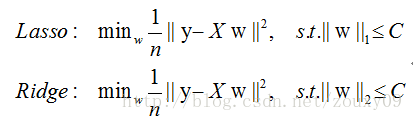

与圆形的解空间相比较,多边形的解空间尖端处更容易与原始解空间发生碰撞,而L1的尖端又刚好位于坐标轴上,因此也就更容易获得稀疏解。
扩展:
事实上,对于Lp范数来说,p 越小,对应的解空间解空间也就越尖锐,有更多的尖峰,也会更容易与原始解空间发生碰撞,但实际很少使用,是因为 p < 1 时,计算非常变得困难,L0范数就是一个NP难问题。
2.从函数求导的角度来看
假设原损失函数是C0,那么在L1正则化和L2正则化条件下对参数求导如下所示:


从求导公式中可以看出,当利用梯度下降方法时,w小于1时,L2的惩罚力度越来越小,很难惩罚到0,而L1的惩罚力度依然很大,完全可以到0。
3.从概率分布角度来说,L1正则化相对于为模型参数引入了拉普拉斯先验分布,L2正则化则是相对于引入高斯分布。


从两个不同分布的概率密度函数图上看,高斯分布在极值点(0处)取不同值的可能性是相同的,它始终只会接近于0但不会等于0。
但拉普拉斯分布就不一样,它是一种相对较尖锐的分布,在绝大时候,值都为0,只有很小的概率才不为0.
5. 为什么L2对过拟合的效果很好
因为过拟合,从数据层次来说,是因为模型对一些某些数据的权值过大,过于看重这些数据的重要性,所以降低过拟合要降低模型对这些数据的重视程度,也就是要减小权值的大小。
再回头想想L2的约束,它是在将权值约束在一个固定范围内,但同时又不会将权值 W 等于0,而是让它接近于 0 ,因此限制了某些数据对模型的影响大小,从而达到了防止过拟合的目的。
6. 稀疏性的好处
- 起到了特征选择的作用,权重为 0 意味着当前特征不会对模型产生影响。实际上,大部分的特征对最终的输出都是没有关系或者说不提供任何信息的,最终需要的只是一小部分特征。稀疏化,帮助模型自动的去掉那些没有用的特征。
- 可解释性,绝大部分的特征为0,只有小部分的特征不为 0 , 说明这些权重不为 0 的特征对最终的输出产生了影响,对于数据就有了较强的可解释性。
参考资料: