Python刷视频
以下代码主要是使用python的selenium库来完成视频的自动播放的,主要过程是登录视频网站,再到达视频播放界面,点击视频播放,判断视频是否播放完成,同时解决如何播放一个界面中有多个视频的播放和切换不同小节和章节的视频播放,最后播放完所有视频
一、登录视频网站(XXT)
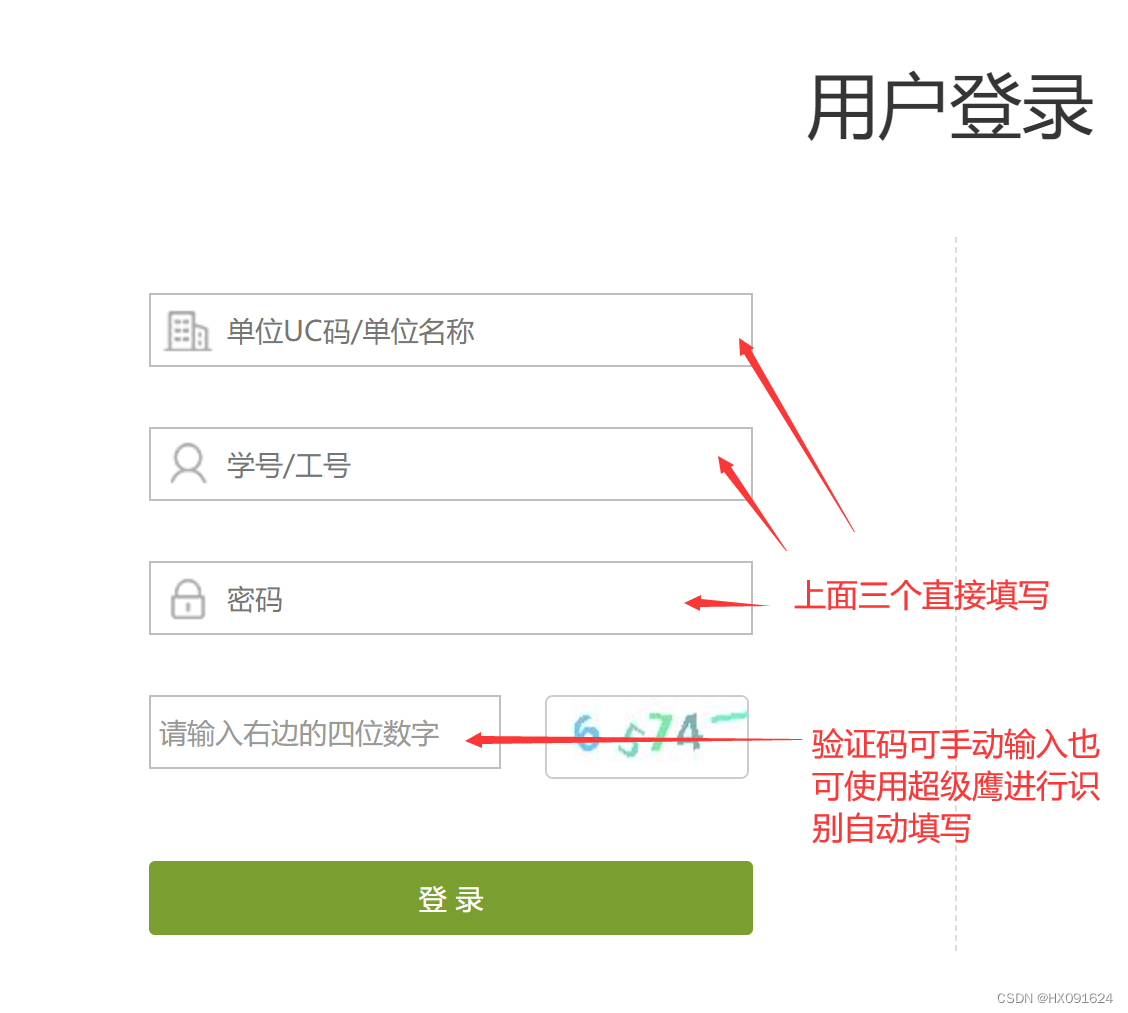
from selenium import webdriver # 导入库
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
web = webdriver.Chrome()
# 超星网站
url = "http://passport2.chaoxing.com/wunitlogin?refer=http%3A%2F%2Fi.mooc.chaoxing.com"
web.get(url)
# 反检查
option = Options()
option.add_argument('--disable-blink-features=AutomationControlled')
verify_code=input('请输入验证码:')
# 第一次登录进入学习通
def register_first(verify_code):
#输入用户名和密码
#account=input("请输入账号:")
#password=input("请输入密码:")
web.find_element(By.XPATH, '//*[@id="FidName"]').send_keys("学校名称")
time.sleep(3)
web.find_element(By.XPATH, '//*[@id="2201"]').click()
time.sleep(3)
web.find_element(By.XPATH, '//*[@id="idNumber"]').send_keys("学号")
web.find_element(By.XPATH, '//*[@id="pwd"]').send_keys("密码")
# 验证码
web.find_element(By.XPATH, '//*[@id="numcode"]').send_keys(verify_code)
# 点击登录
web.find_element(By.XPATH, '//*[@id="userLogin"]/div/a').click()
time.sleep(3)二、进入课程判断是否完成

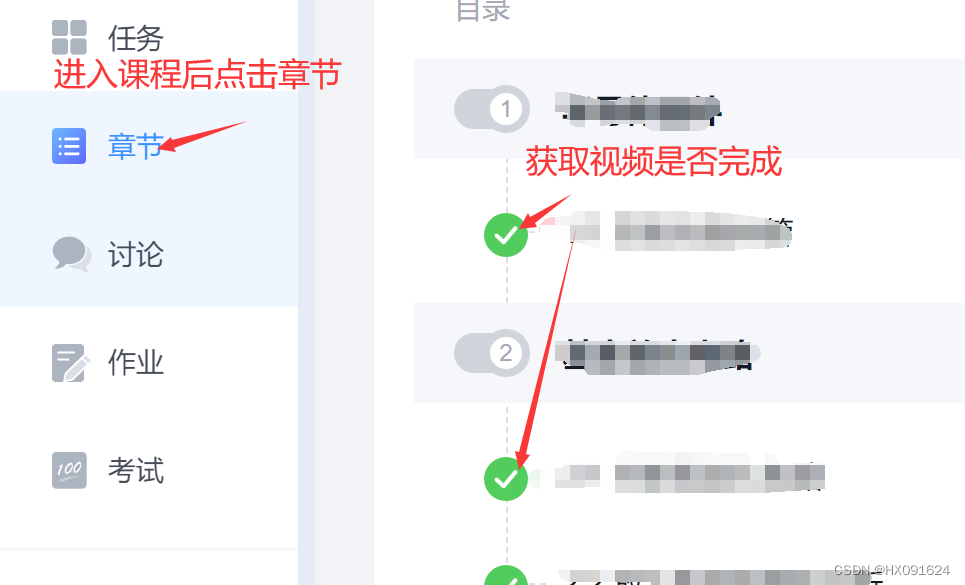
# 进入课程
def into_course():
# iframe框架,需要先跳转
web.switch_to.frame("frame_content")
time.sleep(3)
# 课程
course = web.find_element(By.XPATH,'//*[@id="course_206634766_54029448"]/div[2]/h3/a/span')
# 解决元素被遮挡点击不了的问题
web.execute_script('arguments[0].click()',course)
time.sleep(3)
# 跳转页面
web.switch_to.window(web.window_handles[-1])
# 进入章节
web.find_element(By.XPATH, '//*[@id="boxscrollleft"]/div/ul[1]/li[2]/a').click()
print('进入课程页')
# iframe框架,需要先跳转
web.switch_to.frame("frame_content-zj")
time.sleep(3)
# 判断章节是否已经完成
def OK(li):
time.sleep(3)
# 获取课程状态
status = li.find_element(By.XPATH,'./div/div/div[3]/div/span').get_attribute("textContent")
return status三、先切换不同章节,再到每一章的每一个小节视频进行播放
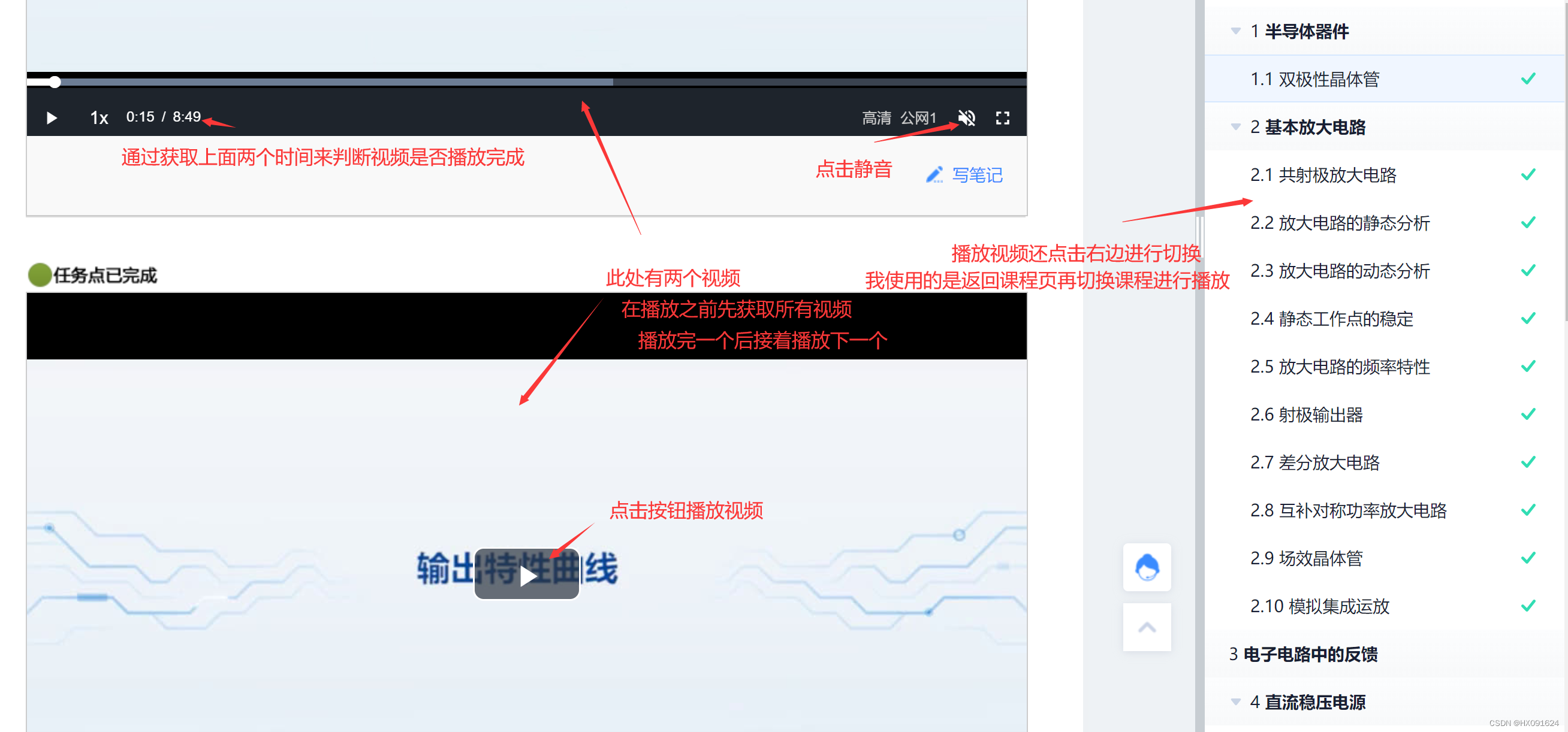
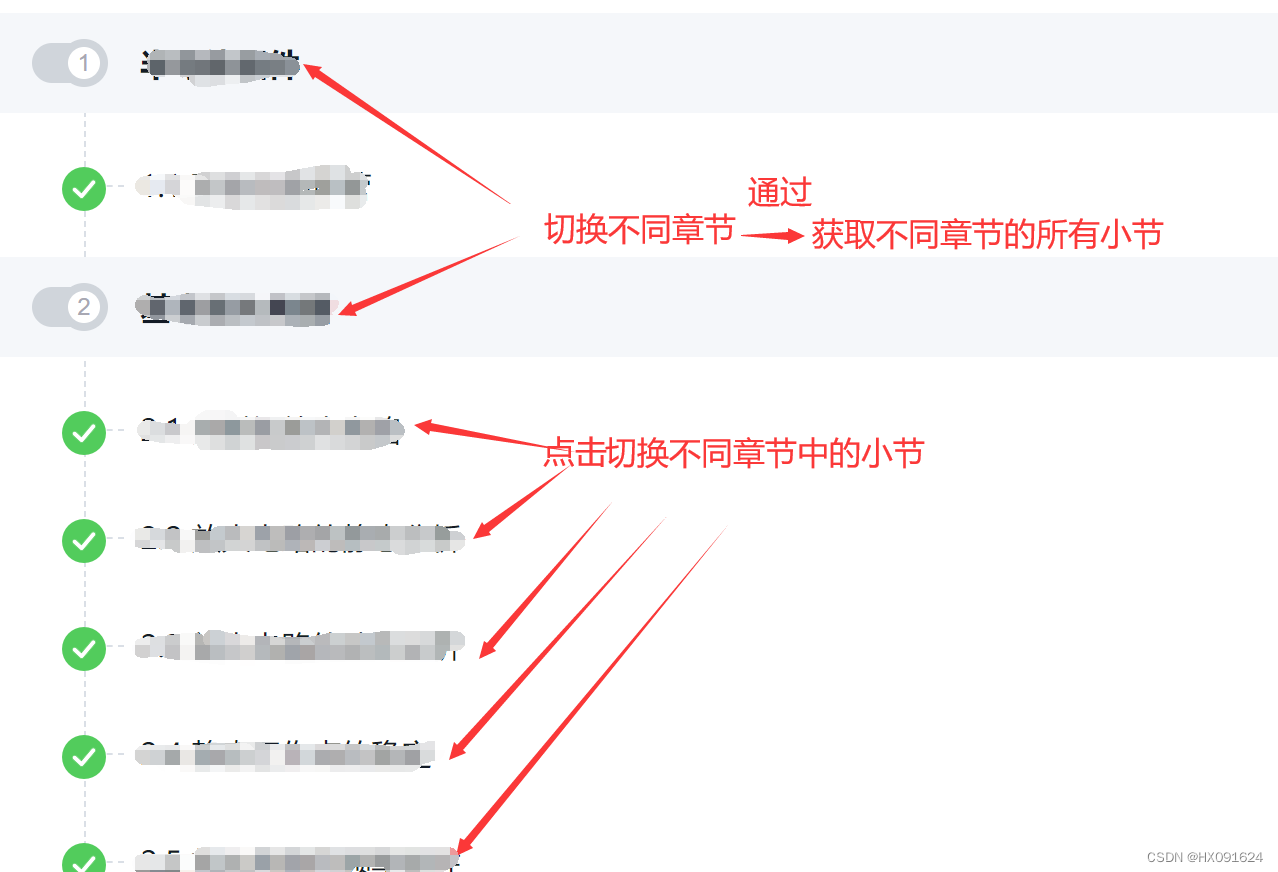
# 跳转后,播放同一章中的小节,同时获取一节中有几个iframe
# 传入同一章的每一节
def play_next(li):
time.sleep(6)
vedio_window = li.find_element(By.XPATH, './div/div/div[2]/span')
web.execute_script("arguments[0].click();", vedio_window)
time.sleep(3)
web.switch_to.frame("iframe")
time.sleep(3)
num_vedio = web.find_elements(By.XPATH, '//*[@id="ext-gen1045"]/div/div/p')
time.sleep(1)
# print(len(num_vedio))
# print('播放下一节')
# 返回一节中的视频数目
return len(num_vedio)
# 播放同一节中的所有视频 点击静音 每次进入下一个视频的iframe
def play_vedio(symbol,i):
# 上一个视频播放完成,播放下一个视频
if symbol:
try:
# 开始播放下一个视频
web.switch_to.default_content()
web.switch_to.frame("iframe")
web.switch_to.frame(i)
paly_course = web.find_element(By.XPATH,"//*[@id='video']/button")
web.execute_script("arguments[0].click();", paly_course)
time.sleep(3)
voice = web.find_element(By.XPATH, '//*[@id="video"]/div[5]/div[6]/button')
web.execute_script('arguments[0].click()', voice)
time.sleep(3)
print(f'开始播放第{i+1}个视频')
except:
print(f"没有第{i+1}个视频")
# 判断视频是否播放完成
def vedio_finished():
try:
while True:
time.sleep(3)
vedio_stat_time = web.find_element(By.XPATH,'//*[@id="video"]/div[5]/div[2]/span[2]').get_attribute("textContent")
vedio_end_time = web.find_element(By.XPATH,'//*[@id="video"]/div[5]/div[4]/span[2]').get_attribute("textContent")
print("正在播放的时间和结束时间是:", vedio_stat_time, vedio_end_time)
# 每10秒检测一次视频是否完成
time.sleep(10)
if vedio_end_time == vedio_stat_time:
print('视频播放完成')
return 1
except:
print('视频不可播放')
return 1四、每次播放一个小节后点击返回课程
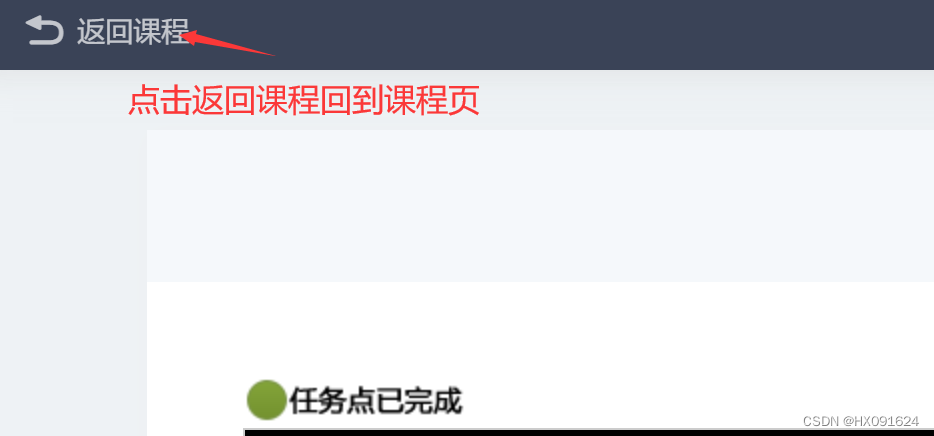
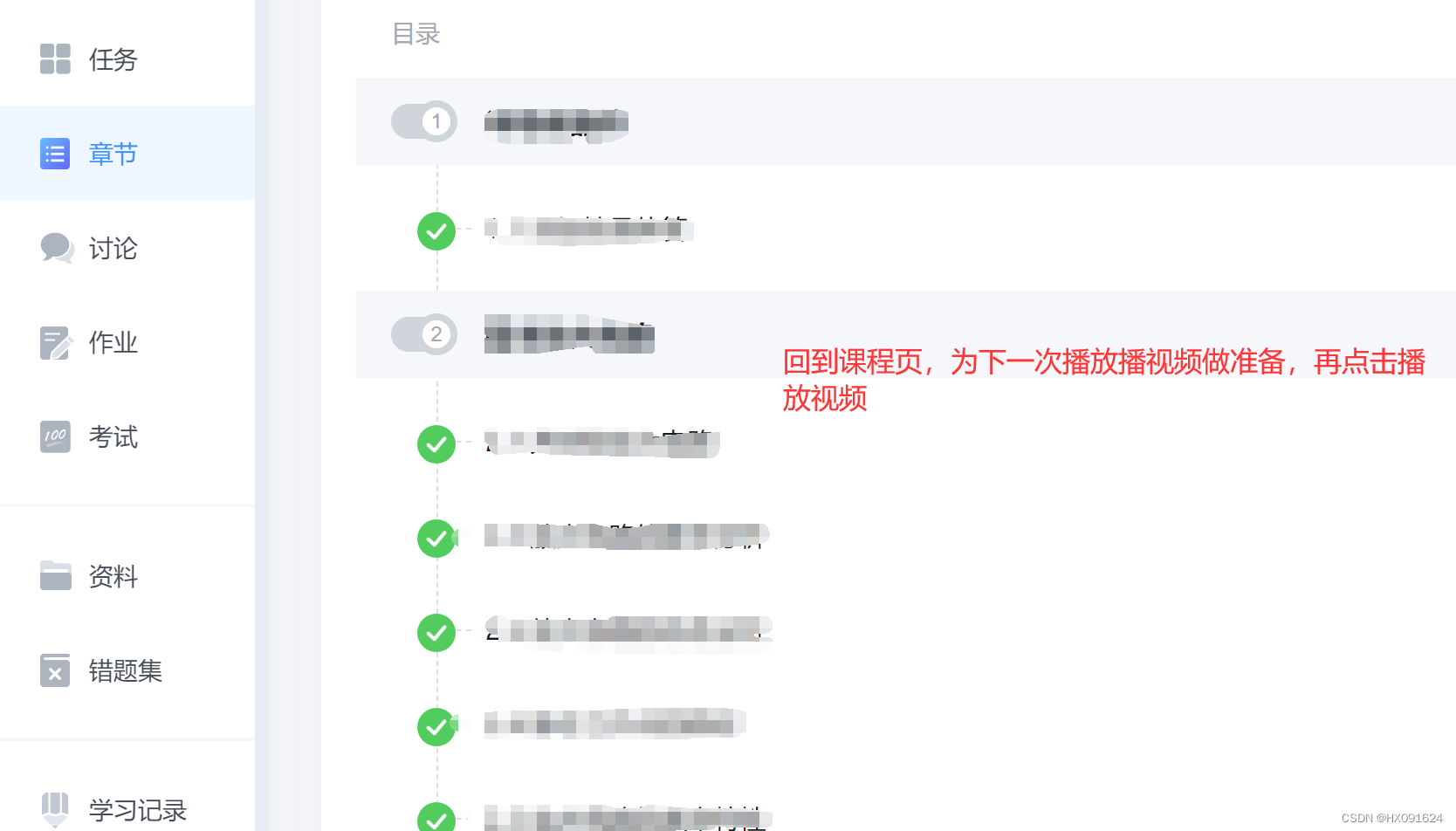
# 点击返回课程
def Retrun_course():
# 跳到最外层的页面
web.switch_to.default_content()
time.sleep(3)
web.find_element(By.XPATH, '/html/body/div[4]/div/div[1]/a').click()
time.sleep(3)
# 同时进入新的iframe的框架
web.switch_to.frame("frame_content-zj")
time.sleep(3)
print('点击返回课程')五、主函数
# 主函数
if __name__ == '__main__':
# 进入学习通
register_first(verify_code)
# 进入课程
into_course()
# 播放所有的章节,一共六个章节
for i in range(2,8):
# 获取每一个章节中的所有小节
li_list = web.find_elements(By.XPATH, f'//*[@id="fanyaChapter"]/div/div[2]/div[2]/div[{i}]/div[2]/ul/li')
time.sleep(3)
# 播放一个章节中的一个小节
for j in range(len(li_list)):
# print(li_list[j])
# 跳转后,判断每一小节完成的状态,完成则跳过
status = OK(li_list[j])
print("每一小节状态:",status)
# 判断视频是否播放完成
if status != "已完成":
# 点击进入下一章的视频
num_vedio = play_next(li_list[j])
# 允许播放
symbol = 1;
# 播放每一节中的每一个视频
for k in range(0,num_vedio):
play_vedio(symbol,k)
# 判断视频是否播放完,播放完,则进入下一个
symbol = vedio_finished()
# print("symbol:",symbol)
# 完成一节的所有iframe后点击返回课程
Retrun_course()
# 每次重新获取一下列表
li_list = web.find_elements(By.XPATH,f'//*[@id="fanyaChapter"]/div/div[2]/div[2]/div[{i}]/div[2]/ul/li')
else:
# 已完成则跳过
continue总结
验证码部分还可以使用超级鹰进行识别,从而实现完全的自动化,提高效率,该部分可以自行学习,比较简单
参考资料:
https://blog.csdn.net/s_frozen/article/details/121136832?spm=1001.2014.3001.5506
https://blog.csdn.net/zhangkexin_z/article/details/90232187?spm=1001.2014.3001.5506