model free算法中,由于未知模型,因此缺少两个重要的分布: p(r|a,s)和p(s’|a,s),因此求解贝尔曼方程或者贝尔曼最优方程必须估计state value和action value的期望。这里就涉及到重要的问题,如何理解action value和state value。
期望的解释
宇哥说过,期望可以看成两部分:概率分布和值,而期望就是概率和值的乘积求和。举个例子,如果骰子抛中6得100分,其他为0分,则概率分布是p(X=x)=1/6,而获得的值是f(6)=100,其他为0。
state value和action value的关系
对于一个state value来说,可以写成:
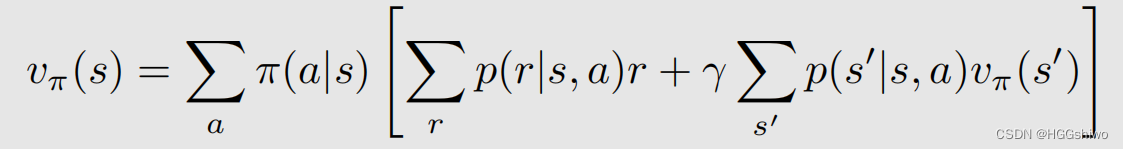
因此state value可以看成随机变量action a函数的期望:
- 概率分布为 a~Pi(s),就是对于一个状态s,取不同的a的概率是不同的
- 值为后面中括号的部分,就是q(a),是每个action对应的action value
总结就是:state value是action value的期望,这里面的随机变量是action a。
如果一个a对应的action value本身也是不确定的,只知道q(a,s)的期望,那么如果q1, q2, q3,…是对q(s,a)的多次采样,可以证明state value仍然是action state的一个期望,不同的是:
- 概率分布变为了 π ( a ) ⋅ 1 n a \pi(a)\cdot \frac1{n_a} π(a)⋅na1,na是对一个(s,a)对采样的次数
- 值变为了q(s,a),这里的q指的是对action value的一次采样结果
总结就是:state value是action value采样结果的期望。
mean estimation
下面给了一个mean estimation迭代算法,用来计算一个期望,它的思想就是获得了一个新的采样值x以后,如何用之前的期望w(k),计算出新的期望w(k+1),具体的方法如下:
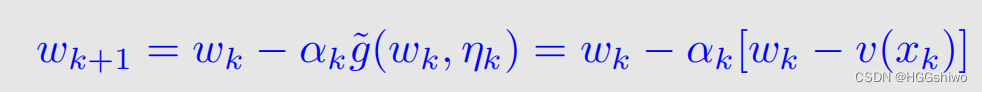
- wk指的是用k-1个v(x)的采样算出来的均值
- α k \alpha_k αk是一个满足RM算法条件的值,可以看成常数
- v ( x k ) v(x_k) v(xk)就是新获得的采样
总结就是:可以通过不断采样,加入新的数据,用来估计一个函数的均值或者期望
另外,对于期望来说,值会在里面体现为v(x),而概率分布体现在ak上。
有关贝尔曼方程和TD算法
上面已经说了,state value是action value的期望,并且给了一个通过采样计算期望的方式,那么是不是可以通过采样action value来获得state value的估计呢? 这是贝尔曼方程的解。
TD算法就是这样的:

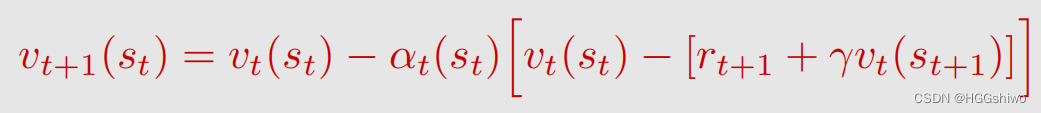
- v t表示了用前t个对action value的采样结果估计出的state value的值。
- 后面括号里面的内容就是w-v(x),w是前k个算出的均值,v(x)是新的均值,这里一样的是vt(st)是前t次对action value采样的结果算出的state value,而后面是第t+1次采样获得的action value,注意t+1次获得的action value需要用到前t次获得的state value。
有关其他TD算法
其实state value不是选择策略所必须的,因此直接求action value的期望就可以了。就是不需要考虑state value作为action value的期望,而是直接求action value的期望:
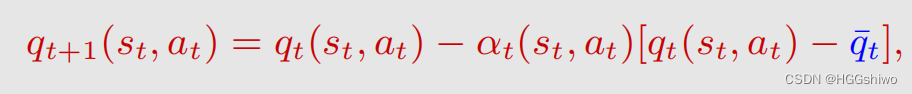
- q t + 1 q_{t+1} qt+1表示使用了前t+1个数据算出的action value q的均值
- q t ˉ \bar{q_t} qtˉ表示获得的新的action value的采样
根据如计算新的action value的采样发明了很多算法:

| 算法 | 如何估计action value | 如何估计action value中的state value |
|---|---|---|
| Sarsa | r + γ v r+\gamma v r+γv | 下一个采样的action value |
| n-step Sarsa | 一个路径的reward+终点的state value | 路径终点对应的那个采样的action value |
| Expected Sarsa | r + γ v r+\gamma v r+γv | 下一个采样state的action value的均值 |
| Q-learning | r + γ v r+\gamma v r+γv | 下一个采样state的最大的action value |
| MC | 整个episode的return | - |
值得注意的是,这里都需要通过策略获取一些episode来获得q的采样,而只有Q-learning修改了策略,因此Q-learning求解的问题是BOE,而其他的方法只是在给定的策略中估计state value,没有修改策略,因此求解的问题是BE