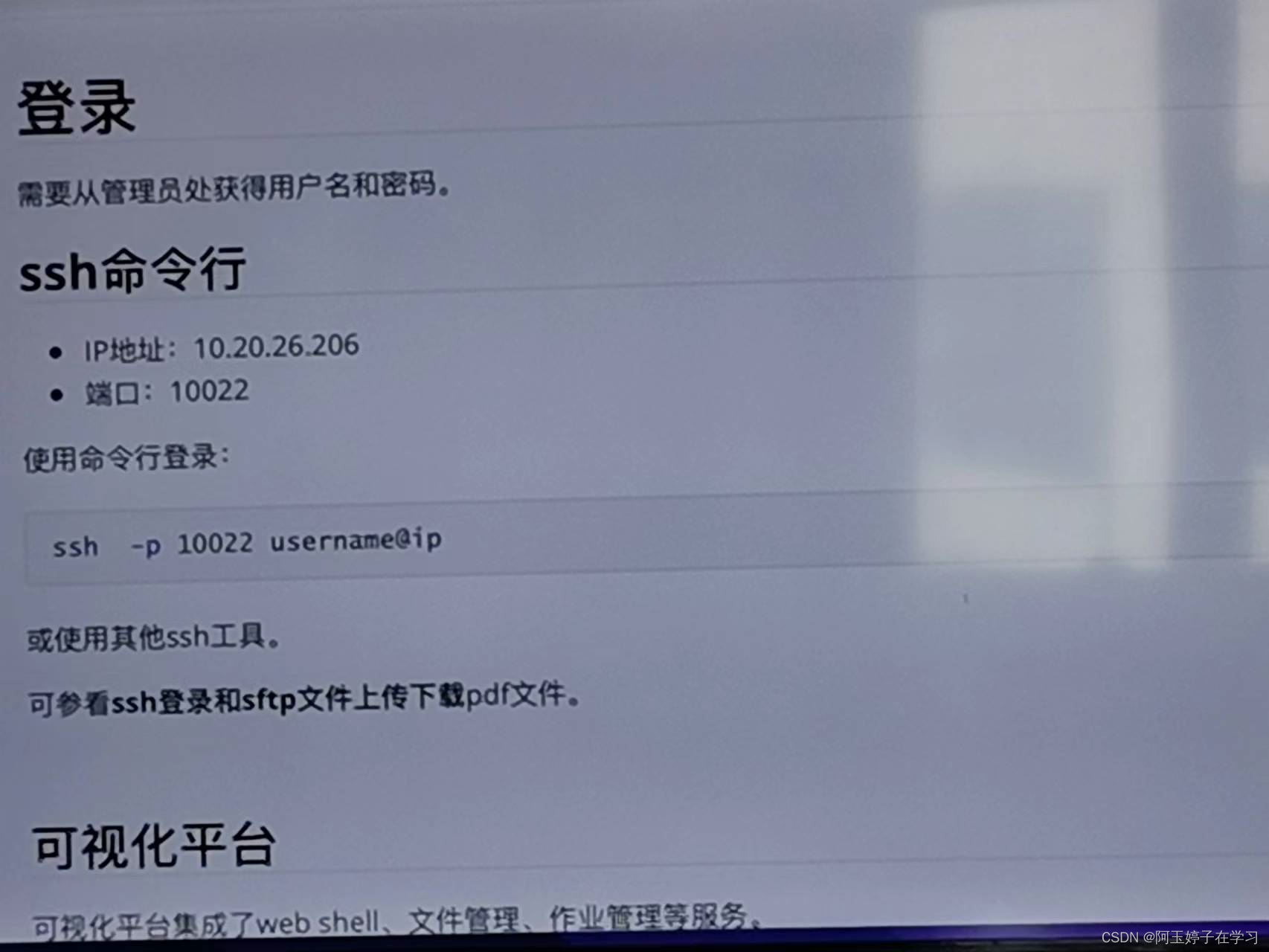
一、登录的IP地址、端口
用户名和密码由管理员在每个课题组分配一个。(等老师通知,用户手册后面群发)
二、Conda环境配置和激活
通用包管理,该集群平台有Conda,但是最好在自己的Home目录装Conda(训练好的代码方便打包带走),注意用的时候激活环境。
三、Slurm调度系统
概念:集群、节点、队列(分区)。
机制:作业先交给调度器再分配给服务器计算。
注意:
- 一块卡一般一个GPU;一般情况下一个人占用一块卡,如果有特殊情况向管理员申请;
- 所有的GPU只能供几个人同时使用,而且是一种排队&等待&调度的机制,所以如果是训练或者测试小数据时候可以优先用CPU计算(该集群中CPU的核比GPU多);
- 这里占用GPU的时间也并非“完全”,因为运行代码并非全部需要GPU,一般情况不会“揪住”一张卡不放;
- 可以共享服务器Home文件夹,大小目前没有限制
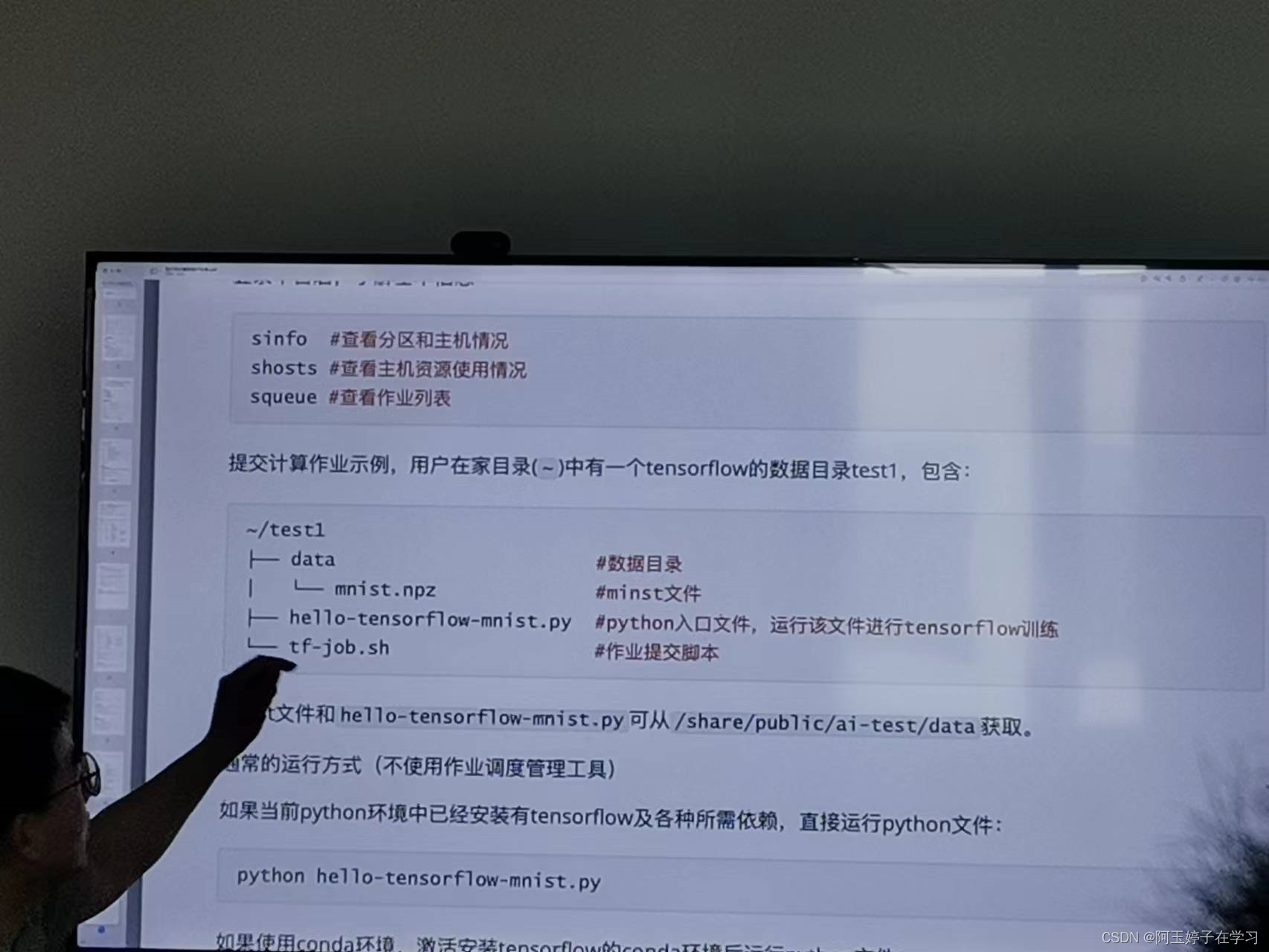
四、Sbatch—提交作业到集群平台
一些Sbatch命令(如提交作业:Sbatch tf-job.sh)
所以大概步骤:激活环境—写脚本—提交运行
五、Srun交互式作业
通常用Sbatch,Srun可用于调试;
六、Squeue查看作业结果
显示自己的运行状态,只能显示自己的正在算的,包括排队的。
七、Scontrol暂停和恢复作业
八、Sacct查看历史作业记录
九、Scancel取消作业
十、一些图