
背景介绍
维度表是数据仓库中的概念。它记录了事实表中属性的多维度详细信息。在数据分析、实时监控、精准推荐等业务中,需要维表 Join 来丰富事实表的信息,进而作进一步计算分析。其在生产实践中具有广泛的应用。
在实时计算中,Flink 开放了通用的 LookupJoin API,Connector 开发者只需实现一个自定义函数就能快速实现 LookupJoin 功能。需要在该函数中检索出对应 key 的维表数据即可。这种实现方式便捷,对于 MySQL、HBase、Redis 等数据源是非常适合的,但是对于不具备点查能力的数据源是不友好的。例如:Iceberg、Hive 的点查性能很差。Flink 官方 Hive Connector 的实现,是在任务启动时,将 Hive 表的全量数据缓存进内存。在生产上,对于海量数据的维表会带来下列问题:
需要消耗大量的内存资源,甚至无法使用。
每个 subtask 都需要加载全量数据,浪费资源。
维表数据无法及时更新,时效性差。
Flink 还推出了 Temporal Join 的功能,比 LookupJoin 功能更强。实现上,是将数据放在状态中,在关联计算时直接从状态中查询数据,可以避免依赖外部数据源的点查能力。
Arctic [1]是一个开源的搭建在 Apache Iceberg 表格式之上的流式湖仓服务,定位是提供流批一体能力的实时数据湖。湖仓一体的特性让批和流的数据加工、数据分析、科学计算、机器学习都能在数据湖中完成,避免了业务维护多份数据的烦恼,不用在多个存储间同步数据。流批一体又强调在数据湖上支持更多流式实时计算的生产能力。因此 Arctic 需要实现生产应用中常见的维表 Join 功能,同时希望维表具备更加实时的能力。
Flink Temporal Join
Temporal Join 介绍
时态表是一种以时间为版本的动态表,表的数据随时间不断变化,可以查询一张表不同时间版本的快照数据。
Temporal Join 把维度表视为一张时态表,读取来自事实表的数据,用指定的 event time ,去检索出维度表中对应时间版本的数据,从而达到关联两个表的效果。
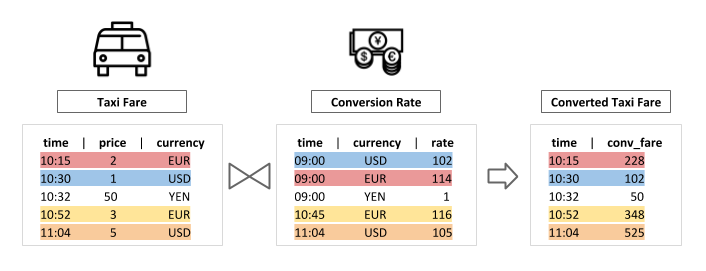
Flink Temporal Join 原理
Flink 从 1.9 版本开始就实现了 Temporal Join[2]。其实现原理可以用下图来展示:
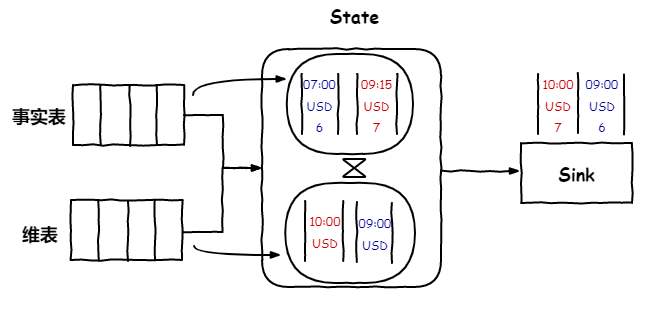
1.事实表和维度表的数据会在各自的 Source 算子中持续地读出发送到 Join 算子,在 Join 算子中两个表的数据会写入到状态(内存或 RocksDB)中。RocksDB 是一个使用 LSM[3](log-structured merge-tree) 实现的本地 kv 存储引擎。具有高效的读写性能,整体架构和介绍可参考官方文档[4]。当内存不足时,数据可以落盘避免出现 OOM。
2.当事实表的数据到来时,需要等待维表的数据就绪才可以进行关联计算。这里借助 Watermark 来实现,Watermark 的语义是所有小于该时间的数据都已到达。当两个流的数据来到 Join 算子时,会推动 Watermark 前进。当 Watermark 推进时,才表明维表中对应时间版本的数据都已经加载到了,这时才能关联到正确版本的数据。
3.此时,Join 算子会读出事实表中所有≤ watermark 的数据(对于时间大于 watermark 的数据可能维度表中对应时间的数据还没到),用每条数据中的 event time 去维度表中找到对应关联条件的、对应时间版本的数据(利用 RocksDB 的高效 KV 检索性能)。
关联时使用的时间是表上定义的 watermark( event time ) 字段,更准确的说, watermark 生成和 event time 是两个概念,只是官方的实现是把 event time 作为了 watermark。关联时用事实表的 event time 去维度表中查找小于等于该时间的最近一个版本的数据。
4.为了避免状态的无限扩大,在关联计算完,会把表中已触发计算的所有数据清除,另一方面,在维表侧,会保留小于等于 watermark 的最近一个时间版本的数据,更早版本的数据会被清除。这里需要保留至少一个版本的数据,因为数据可能在未来不会变更。
Arctic 维表 Join 原理
实现思路
从语义上看,维表 Join 其实是一种特殊的 Temporal Join,等同于 processing time 的 Temporal Join。Lookup Join 是在数据到达 Join 算子时刻,去外部数据源检索数据,该时刻即 processing time 。而它不关注数据版本,该版本由外部数据源保证,对于事实表的数据,仅能关联上维表中最新版本的数据。因此从功能上看基于 processing time 的 Temporal Join 与维表 Join 是相同的。
从实现上看,对于前文提到的维表 Join 存在的问题,我们可以在 Flink Temporal Join 的官方实现中找到合适的解决方案:
1.内存资源有限:Temporal Join 将两个表的数据写入到状态中,生产环境一般使用 RocksDB。因此可以在内存资源不足时由 RocksDB 将数据调度到磁盘上,对于热点数据又可以缓存在内存中保证读数据的性能。
2.每个 SubTask 缓存重复多余的全量数据:Flink 的 Temporal Join 默认实现会在 Join 算子前根据 Join Key 进行 Hash,这样可以使得每个 SubTask 只保留分配到的 Key 的数据,避免缓存过多无用数据。
3.维表数据时效性:RocksDB 具备非常高效的写性能,只需要保证维度表的数据源是实时地读取并写入到状态中即可。可以借助 Kafka 等消息队列的实时性,或 Arctic 流批一体的特性来实现。
值得注意的是,Temporal Join 需要将数据先写入状态,对于 Arctic 表作为维表时,该维表可能是一张很大的表,读取存量数据会是一个耗时的工作,应该先将存量数据写入状态后,再触发 Join 关联计算,后续也会不断读取增量数据更新维表侧的状态数据。在存量数据加载阶段,不允许 Join 计算避免关联出错。
实现原理
接下来,以一张 Order 表作为事实表,User 表作为维表作为示例,介绍 Arctic 的维表 Join 实现。其中 Order、User 表只列出关键字段作为示例。
1.数据按从右向左的顺序依次读出向下游 Join 算子发送。其中 Order 表的 RowTime 为 LocalTimeStamp,即 process time;User 表的 RowTime 取 Long.MIN_VALUE,这时,维表侧只会保留一个版本的数据,新读到的数据会覆盖老的,这与 Lookup Join 的逻辑是一致的。该值可以保证 Join 时事实表的每行数据都能够与维表对应 Join Key 的数据匹配上,因为只有一个 Long.MIN_VALUE(最早) 的版本,任意一个 RowTime 数据都能匹配上。

2.Order 表会根据自定义的 Watermark 向下游发送,而 User 表在 Arctic 表读存量数据阶段,不会发送 Watermark。由于下游 Watermark 会取上游所有输入的最小值,因此 Join 算子的 Watermark 为空,两个流的数据都会缓存在 Join 算子的状态中。其中维表中的数据会以 RowTime、Join Key 作为 Key 存储。
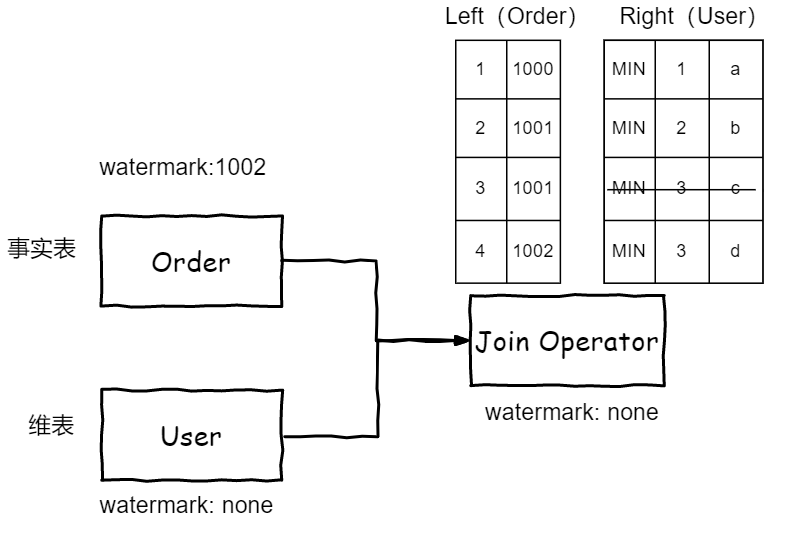
3.当 User 表加载完存量数据后,会向下游发送一个 Long.MAX_VALUE 的 Watermark,可以保证 Join 算子及下游的 Watermark 保持与 Order 表的一致,不影响 Order 表指定 event time 作为 Watermark 时的逻辑。同时能推进下游的 Watermark,当 Watermark 推进后,就会触发 Join 算子的 event time 定时器,开始关联两个表的计算。
Flink Temporal Join 算子在关联时,会过滤出状态中维度表 RowTime 小等于 Watermark 的所有数据,与维表相同 Join Key 且 RowTime 小等于事实表 RowTime、RowTime 最大的一条数据进行关联。根据上述的取值设计,维表中同一个 Join Key 的数据一旦发生变更,就会覆盖 Join 算子中的维表侧状态数据,因此同一个 Join Key 的数据只会保留一条最新的。使得关联计算可以按照 LookupJoin 的逻辑实现。
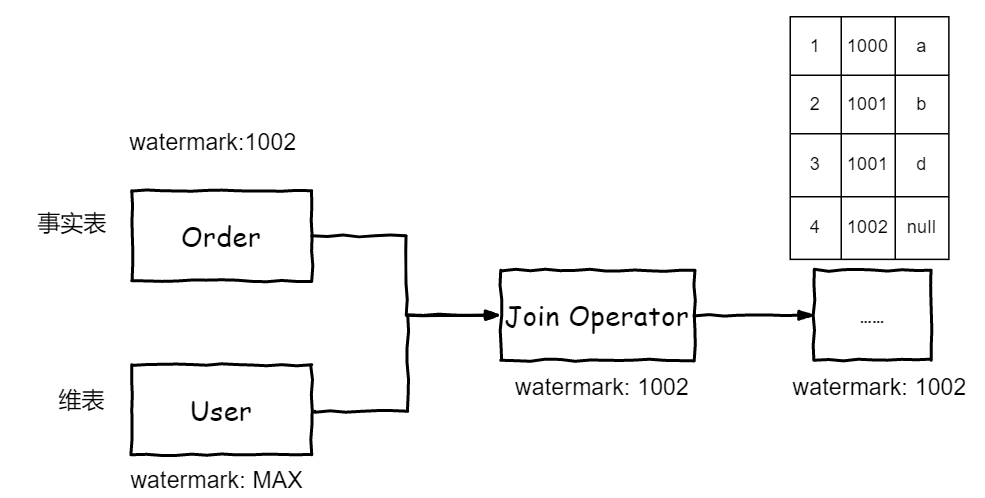
4.后续因为 User 表的 watermark 已经是最大值了,Join 算子的 watermark 会随 Order 表的 watermark 推进。而 User 表的增量数据会持续不断地被读取并发送更新到 Join 算子的状态中,保持状态中维度表数据的时效性。
如何判断存量数据加载完成
Arctic File Source 按照 Flink FLIP-27[5] 的接口实现,会在 JobManager 中监控 File 的数据,并将监控到的数据 Split 分发给 TaskManager 中的 Reader 读取。因此不同 Split 的数据是并行读取的,读的速度不一致,不能根据读出数据所在的 Snapshot 来判断是否读完存量数据。
我们采用的方案是在任务启动时,记录下 Arctic Source plan 出的所有 splits。当这些 splits 都读完后,再由 JobManager 通知所有的 Reader 向下游发送 Watermark。
如何保证任务 Failover 后正常运行
当任务发生 Failover 后,由于 Watermark 信息会发生丢失,这将导致 Failover 发生在读增量数据阶段时,任务恢复后 Join 算子将无法触发 Join 操作。
当 JobManager 发生 Failover 时,需要判断是否所有存量数据的 splits 都已完成。如果完成则会再次通知所有的 Reader 向下游发送 Watermark。
当 TaskManager 发生 Failover 时,需要判断是否已向下游发送过 Watermark。如果已发送过,则会再次发送。
使用示例
以上述例子来说明 Arctic 的维表 Join 的使用:
1.创建一张 Arctic 表 User 作为维表:
CREATE TABLE IF NOT EXISTS arctic_catalog.default_db.`user` (
id INT,
name STRING,
age INT,
PRIMARY KEY (id) NOT ENFORCED
);2.创建一张事实表,需要将 proctime 作为 watermark。当然,对于一个原本就有 watermark 需求的 SQL 任务,可以按原有的方式指定数据中的 eventTime 作为 watermark。
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
user_id INT,
order_time AS LOCALTIMESTAMP,
WATERMARK FOR order_time AS order_time
) WITH (/* ... */);3.按下述方式给 Arctic 维表添加 watermark 定义。如下所示,增加 opt 字段,该字段可以是任意名称,但不允许使用 arctic_catalog.default_db.`user` 表中的物理字段,即不能与 arctic_catalog.default_db.`user` 表中已有字段同名。并将该字段定义为 watermark。
CREATE TABLE user_dim (
opt TIMESTAMP(3),
WATERMARK FOR opt AS opt
) LIKE arctic_catalog.default_db.`user`;4.开启 Arctic 表流读和维表的配置,执行维表 Join。
SELECT order_id, price, user_id, name, age
FROM orders
LEFT JOIN user_dim /*+OPTIONS('streaming'='true', 'dim-table.enable'='true')*/
FOR SYSTEM_TIME AS OF orders.order_time
ON orders.user_id = user_dim.idBenchemark
测试环境及配置
在测试中,对于数据量在 2100w 条数据(datagen 随机生成)、13G 大小的维表。使用以下配置:
Flink 版本:1.14
TaskManager 内存:2G
JobManager 内存:2G
state backend:RocksDB
state.backend.incremental:true
Checkpoint 间隔:1min
万兆网络带宽
Arctic 表配置:
base.file-index.hash-bucket: 8 (base store 文件 hash 的 bucket 个数)
change.file-index.hash-bucket: 8 (change store 文件 hash 的 bucket 个数)
测试维度
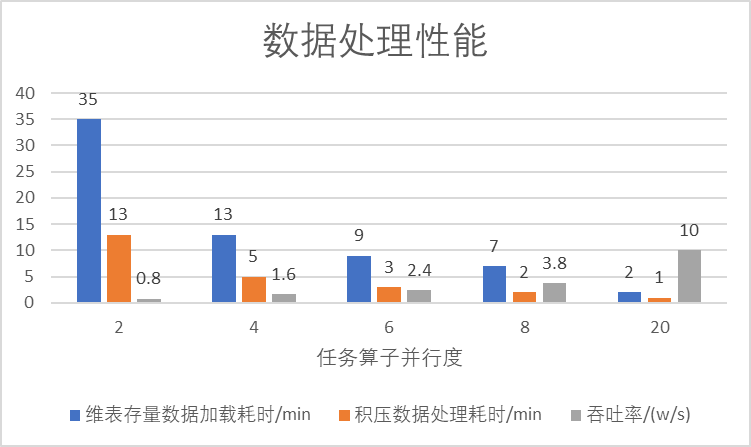
重点关注 Arctic 维表存量数据加载耗时(min)、积压数据处理耗时(min)、吞吐率(w条/s)三个指标。
维表存量数据加载耗时:在 Flink 算子刚启动时,会记录下 Arctic 表当前的 Snapshot,这部分数据的加载耗时记为存量数据加载耗时,之后写入的数据都为增量数据。
积压数据处理耗时:在维表存量数据加载阶段,会在 Join 算子中积压一批事实表的数据,在发出第一条 join 的数据之前,状态中事实表侧的数据需要读到内存中排序以决定发送顺序。积压数据处理耗时指的是从状态中读取当前 key 的数据及排序的耗时。
吞吐率:在维表存量数据加载完,把积压的数据处理完成后,事实表继续持续输入数据,此时 Join 算子向后续算子输出数据的速度。
测试方法及结果
1.用 Arctic 表作为维表,事实表使用 datagen 随机生成数据,key 范围为 1~1580w,速度设置为 10 w/s。分别设置并行度为 2、4、6、8、20 运行维表 Join 任务。
2.使用上述事实表分别进行维表关联,对比 Hive 表和 Arctic 表:
指标 |
Hive 维表 |
Arctic 维表 |
最小运行资源 (维表:630W,4G;吞吐率:1000/s) |
并行度:1,单并行度:1 core, 32G mem. |
并行度:1,单并行度:1 core, 4G mem. |
最小运行资源 (维表:2100W,13G;吞吐率:10w/s) |
生产不可用 |
并行度:16,单并行度:1 core, 2G mem. |
Failover 耗时 (维表:630W,4G; 1 core,32G mem) |
分钟级 |
秒级 |
维表实际大小 |
受TM内存限制 |
没有限制 |
维表数据更新 |
需要整表重新加载 |
只需读取增量数据 |
Shuffle |
无 |
自定义shuffle |
提高并发减少初始化耗时 |
不可以 |
可以 |
提高并发提高JOIN性能 |
不可以 |
可以 |
测试结论
1.Hive 作为维表,其大小受 TM 的内存限制,并且 TM 的内存较难设置,需要预估真实数据解压后的真实大小。而 Arctic 表作为维表几乎不限制 TM 的内存。比如 HDFS 中 4G 的数据,Hive 运行需要配置 32G 内存,但是 Arctic 只需要 4G 即可。即使增大并行度,Hive 对于单个 TM 也需要 32G,而 Arctic 在 4 个并行度时单个 TM 2G 就可以运行。
2.Arctic 维表数据加载速度优于 Hive。增加并行度,Hive 的维表数据加载时间不变,而 Arctic 维表数据加载耗时随并行度的增大而降低。
3.Arctic 维表 Failover 耗费的时间比 Hive 短。Arctic 利用了 RocksDB 的增量 checkpoint,可以快速恢复。而 Hive 需要重新读取加载数据。
4.Arctic 维表对于数据的更新,只需加载增量部分,而 Hive 需要定时地全量重新加载来实现。
5.Arctic 最佳实践:用户可根据要求的吞吐率适当调整并发度
维表规模 |
2100w、13G |
Flink 配置 |
taskmanager.memory.managed.fraction: 0.7 |
并行度: 16 |
|
内存: 2G |
|
Arctic 配置 |
base.file-index.hash-bucket: 16 |
change.file-index.hash-bucket: 16 |
|
可达吞吐率 |
10w/s |
后续规划
未来将针对目前的实现方案进一步优化:
1.支持更加实时的维表。目前 Arctic Source 的维表仅实现了 File 读取,仍然会有上游 Checkpoint 时长的分钟级延迟。Arctic 表在存储上分为 FileStore 和 LogStore[6],旨在利用 LogStore(目前为 Kafka)存储 CDC 数据来提供毫秒级延迟的能力。未来计划实现 Arctic File 与 Log 的一体化读,保证增量数据可以在更低延迟内读取并更新至维表侧的状态中。
2.减少维表存量数据加载耗时。未来尝试在维表存量数据加载阶段不开始事实表的读取,从而减少事实表数据输入对维表存量数据加载的影响。
功能试用
目前,Arctic 已经实现了维表 Join,欢迎参考文档 Arctic Flink 维表 Join [7]试用,遇到相关问题可以通过社区创建 ISSUE[8] 反馈;也可以通过加 Arctic 微信小助手 “kllnn999”,备注“Arctic lover”,进 Arctic 用户交流群交流。
如果您对数据湖,湖仓一体,Table Format 或 Arctic 社区感兴趣,也欢迎通过上述方式联系我们深入交流。欢迎更多的开发者关注、使用和参与,欢迎贡献代码,一起打造行业领先的湖仓管理系统。
了解更多
作者简介:朱源,网易数帆资深平台开发工程师 Arctic、Flink Contributor
4 年从业经验,先后从事过交易引擎、工作流引擎、人工智能计算平台、实时计算引擎等基础设施的开发与实践,致力于分布式、实时计算、大数据等方向,目前主要负责 Arctic Flink 开发。
参考文献:
[1]Arctic:
https://arctic.netease.com/ch/
[2]TemporalJoin:
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/sql/queries/joins/#temporal-joins
[3]LSM(log-structured merge-tree):
https://en.wikipedia.org/wiki/Log-structured_merge-tree
[4]官方文档:
http://rocksdb.org.cn/doc/getting-started.html
[5]Flink FLIP-27:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface?src=contextnavpagetreemode
[6]LogStore:
https://arctic.netease.com/ch/table-format/table-store/#_2
[7]Arctic Flink 维表 Join:
https://github.com/NetEase/arctic/issues
[8]创建 ISSUE:
https://github.com/NetEase/arctic/issues
END
