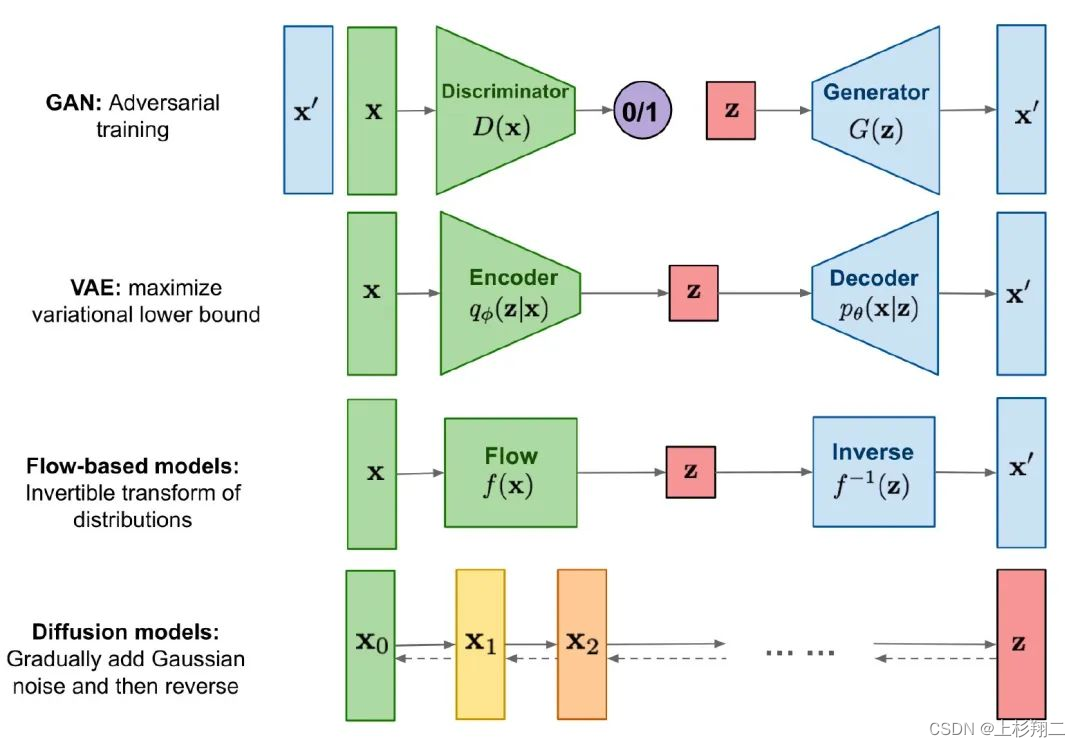
随着最近DALLE2和stable diffusion的大火,扩散模型的出色表现丝毫不逊色VAE和GAN,已经形成生成领域的三大方向:VAE、GAN和Diffusion,如上图可以简要看出几类主线模型的区别。
本期文章将简要介绍下扩散模型的数学原理和几个代表性模型。

扩散模型
扩散模型受热力学启发,通过反转逐渐的噪声过程来学习生成数据。如上图所示,分为扩散过程(forward/diffusion process)和逆扩散过程(reverse process)。
- 扩散过程( X 0 − X T X_0-X_T X0−XT):逐步对图像加噪声,这一逐步过程可以认为是参数化的马尔可夫过程。
- 逆扩散过程( X T − X 0 X_T-X_0 XT−X0):从噪声中反向推导,逐渐消除噪声以逆转生成图像。
训练完成后,就能通过随机采样高斯噪声来生成图像了。实际上扩散模型和AE、VAE很类似,一个粗略的发展过程可以认为是AE–VAE–VQVAE–Diffusion,而扩散模型也逐步从DDPM–GLIDE–DALLE2–Stable Diffusion。
先简要推导一下扩散模型的公式,再介绍相关文章:
- 扩散过程。在每个时间步内, q ( X t ∣ X t − 1 ) q(X_t ∣X_{t−1}) q(Xt∣Xt−1)可以表示为,给定 X t − 1 X_{t-1} Xt−1,服从均值为 1 − β t X t − 1 \sqrt{1−β_t} X_{t−1} 1−βtXt−1,方差为 β t I β_t I βtI的正太分布,其中I是个单位矩阵。 q ( X t ∣ X t − 1 ) = N ( X t ; 1 − β t X t − 1 , β t I ) q(X_t ∣X_{t−1})=N(X_t ; \sqrt{1−β_t} X_{t−1},β_t I) q(Xt∣Xt−1)=N(Xt;1−βtXt−1,βtI)每步的采样过程借鉴VAE的重参数技巧可以得到 X t = α t X t − 1 + 1 − α t Z t − 1 X_t=\sqrt{\alpha_t}X_{t-1}+\sqrt{1-\alpha_t}Z_{t-1} Xt=αtXt−1+1−αtZt−1,从而很容易知道每步噪音都是马尔科夫的连乘结果,即 α t = ∏ i = 1 t α i \alpha_t=\prod^{t}_{i=1} \alpha_i αt=∏i=1tαi,因此可以推导出, q ( X t ∣ X 0 ) = N ( X t ; α t X 0 , ( 1 − α t ) I ) q(X_t|X_0)=N(X_t;\sqrt{\alpha_t}X_0,(1-\alpha_t)I) q(Xt∣X0)=N(Xt;αtX0,(1−αt)I)
- 逆扩散过程。如果我们知道 q ( X t − 1 ∣ X t ) q(X_{t-1}|X_t) q(Xt−1∣Xt),则可以完成逆生成。但这一分布未知,因此同样借鉴VAE,训练一个网络 p ( X t − 1 ∣ X t ) p(X_{t-1}|X_t) p(Xt−1∣Xt)来近似。按照VAE的变分下界的训练思路,训练网络 p ( X t − 1 ∣ X t ) p(X_{t-1}|X_t) p(Xt−1∣Xt)就是最小化p(X_t|X_{t+1})和 q ( X t ∣ X t + 1 X 0 ) q(X_t|X_{t+1}X_0) q(Xt∣Xt+1X0)的KL散度。而 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)用 q ( X t ∣ X 0 ) q(X_t|X_0) q(Xt∣X0)和 q ( X t ∣ X t − 1 ) q(X_t|X_{t-1}) q(Xt∣Xt−1)来表示的,而这俩在上面的扩散过程中已经推导出,因此 q ( X t − 1 ∣ X t X 0 ) q(X_{t-1}|X_tX_0) q(Xt−1∣XtX0)是可知的。 q ( X t − 1 ∣ X t X 0 ) = q ( X 0 X t − 1 X t ) q ( X 0 X t ) = q ( X t ∣ X t − 1 X 0 ) ∗ q ( X t − 1 ∣ X 0 ) q ( X t ∣ X 0 ) q(X_{t-1}|X_tX_0)=\frac{q(X_0X_{t-1}X_t)}{q(X_0X_t)}=q(X_t|X_{t-1}X_0)* \frac{q(X_{t-1}|X_0)}{q(X_t|X_0)} q(Xt−1∣XtX0)=q(X0Xt)q(X0Xt−1Xt)=q(Xt∣Xt−1X0)∗q(Xt∣X0)q(Xt−1∣X0)
变分下界过程推导可看博主以往整理过的VAE和CVAE的推导。更详细的推导本博文将不做赘述,推荐苏神的博客:https://spaces.ac.cn/ 。
为什么扩散模型能成功?
层次式VAE,这或许证明了即使Encoder微小、隐空间维度固定、马尔科夫跃迁,当推广到无限层时,模型仍然能够学习到强大能力。
然后直接来看看由DDPM–GLIDE–DALLE2–Stable Diffusion的发展论文。

Denoising Diffusion Probabilistic Models
首先是DDPM,它采用一个U-Net 结构的Autoencoder来对t时刻的噪声进行预测。直接看看它的code就能更好的理解扩散模型的整个训练过程了。
class GaussianDiffusion(nn.Module):
def __init__(self,model,):
super().__init__()
self.model = model
self.channels = self.model.channels
self.self_condition = self.model.self_condition #条件控制
self.image_size = image_size #图片size
self.objective = objective
if beta_schedule == 'linear':
betas = linear_beta_schedule(timesteps)
elif beta_schedule == 'cosine':
betas = cosine_beta_schedule(timesteps)
else:
raise ValueError(f'unknown beta schedule {
beta_schedule}')
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value = 1.)
timesteps, = betas.shape
self.num_timesteps = int(timesteps)
self.loss_type = loss_type
# 采样相关的参数
self.sampling_timesteps = default(sampling_timesteps, timesteps) # default num sampling timesteps to number of timesteps at training
assert self.sampling_timesteps <= timesteps
self.is_ddim_sampling = self.sampling_timesteps < timesteps
self.ddim_sampling_eta = ddim_sampling_eta
# helper function to register buffer from float64 to float32
register_buffer = lambda name, val: self.register_buffer(name, val.to(torch.float32))
register_buffer('betas', betas)
register_buffer('alphas_cumprod', alphas_cumprod)
register_buffer('alphas_cumprod_prev', alphas_cumprod_prev)
# 先计算扩散过程的 q(x_t | x_{t-1})
register_buffer('sqrt_alphas_cumprod', torch.sqrt(alphas_cumprod))
register_buffer('sqrt_one_minus_alphas_cumprod', torch.sqrt(1. - alphas_cumprod))
register_buffer('log_one_minus_alphas_cumprod', torch.log(1. - alphas_cumprod))
register_buffer('sqrt_recip_alphas_cumprod', torch.sqrt(1. / alphas_cumprod))
register_buffer('sqrt_recipm1_alphas_cumprod', torch.sqrt(1. / alphas_cumprod - 1))
# 计算后验函数q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
# 然后得到: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
register_buffer('posterior_variance', posterior_variance)
# 实施diffusion chain
register_buffer('posterior_log_variance_clipped', torch.log(posterior_variance.clamp(min =1e-20)))
register_buffer('posterior_mean_coef1', betas * torch.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod))
register_buffer('posterior_mean_coef2', (1. - alphas_cumprod_prev) * torch.sqrt(alphas) / (1. - alphas_cumprod))
# 计算p2权重
register_buffer('p2_loss_weight', (p2_loss_weight_k + alphas_cumprod / (1 - alphas_cumprod)) ** -p2_loss_weight_gamma)
推荐这个pytorch库,
$ pip install denoising_diffusion_pytorch
可以轻松使用DDPM模型。
import torch
from denoising_diffusion_pytorch import Unet, GaussianDiffusion
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
)
training_images = torch.randn(8, 3, 128, 128) # images are normalized from 0 to 1
loss = diffusion(training_images)
loss.backward()
# after a lot of training
sampled_images = diffusion.sample(batch_size = 4)
sampled_images.shape # (4, 3, 128, 128)

GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
GLIDE最重要的贡献在于它允许文本作为条件来生成图像,即 text-conditional 图像。一张动图n胜千言,上图是 GLIDE 的训练过程:
- 首先将文本编码为 K 个 token 序列。
- 然后将token输入到 Transformer。
- transformer输出的最后一个token作为扩散模型的条件。其中每一步中都基于生成图像 E I ( x ) E_I(x) EI(x)与文本 E L ( l ) E_L(l) EL(l)之间的相似度来计算梯度 F ( x t , l , t ) = E I ′ ( x t ) ⋅ E L ( l ) F(x_t,l,t)=E'_I(x_t) \cdot E_L(l) F(xt,l,t)=EI′(xt)⋅EL(l)。且GLIDE是无分类器的扩散引导: ϵ ( x t ∣ c a p t i o n ) = ϵ ( x t ) + s ⋅ ( ϵ ( x t , c a p t i o n ) − ϵ ( x t ) ) \epsilon(x_t|caption)=\epsilon(x_t)+s \cdot (\epsilon(x_t,caption)-\epsilon(x_t)) ϵ(xt∣caption)=ϵ(xt)+s⋅(ϵ(xt,caption)−ϵ(xt))
再加上更多的参数(3.5B)和数据(DALLE),它可以更好的将文本信息加入到扩散模型以得到更好的训练效果。
paper:https://arxiv.org/pdf/2112.10741.pdf
project:https://github.com/openai/glide-text2im

Hierarchical Text-conditional Image Generation with Clip
DALLE2的模型结构如上图,其中扩散模型是基于GLIDE的。
- 虚线上半部分是预训练好的CLIP。一侧输入文本,一侧是图像,用于得到表征。
- 虚线下半部分是text-to-image的生成过程。这一过程是二阶的过程,即文本变图像特征,再特性特征变图像。首先文本特征输入autoregressive或者diffusion prior以得到初步的图像特征(实验证明diffusion效率更高,因此一般选用diffusion),然后该特征会进一步作为condition到反向扩散模型中生成最后的图片。
值得注意的是 GLIDE 模型以两种方式使用投影的 CLIP 文本嵌入。第一种是将它们添加到 GLIDE 现有的时间步嵌入中,第二种是通过创建四个额外的上下文 token,它们连接到 GLIDE 文本编码器的输出序列。
project:https://openai.com/dall-e-2/
code:https://github.com/lucidrains/DALLE2-pytorch

High-Resolution Image Synthesis with Latent Diffusion Models
Stable Diffusion的性能有多夸张,博主夸不动了。直接看模型结构,它由VAE,Unet, CLIP 文本编码器组成。
- VAE。在训练期间,VAE编码器用于获取图像的潜在表示(latents)以进行前向扩散过程,即加噪声。而在推理过程中,逆扩散的去噪过程使用VAE解码器生成图像。
- U-Net。编码解码都由ResNet组成。编码器得到图像表示,而解码器还原图像,且此时得到的应该是噪声较小的。更具体地说,U-Net 输出预测可用于计算预测去噪图像表示的噪声残差。此外,交叉注意力层被添加到 U-Net 的编码器和解码器部分(ResNet 块之间)以调节输出。
- CLIP。文本编码将文本转换为 U-Net输入。且和Imagen一样,Stable Diffusion在训练期间不训练文本编码器,而只是使用 CLIP 已经训练好的CLIPTextModel。
除了它的生成效果极好外,它的所有代码、模型和权重参数库都已经在 Huggingface 的 Github 上进行开放!!yyds!!
pip install diffusers==0.2.4 transformers scipy ftfy
几行代码便可以轻松冲浪。
from diffusers import StableDiffusionPipeline
# get your token at https://huggingface.co/settings/tokens
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)
prompt = "a photograph of an astronaut riding a horse" #输入文本
image = pipe(prompt)["sample"][0] #得到生成的图片
paper:https://arxiv.org/abs/2112.10752
code:https://huggingface.co/CompVis/stable-diffusion
huggingface:https://huggingface.co/blog/stable_diffusion
Diffusion的优势
Diffusion的优势主要在于生成质量高,借助大模型后面的能力空间较大。但训练资源消耗太大,不容易部署。
Stable Diffusion 2.0
更新,Stable Diffusion 2.0。Stable Diffusion 2.0和1.0版本大致相同,不同的地方在于使用了新的文本编码器,即不是CLIPText,而使用了OpenCLIP 。性能上与早期的 V1 版本相比,分辨率变得更为清晰,文本到图像生成模型可以生成默认分辨率为 512x512 像素和 768x768 像素的图像。
code:https://github.com/Stability-AI/stablediffusion
negative prompt
与正常的文本到图像 prompt 类似,Negative Prompting 是指不希望在图像中看到的信息。通过这种方法,可以使得用户从原始生成的图像中删除任何局部信息,如「no, not, except, without」等。
https://github.com/minimaxir/stable-diffusion-negative-prompt