本篇博文整理一下IJCAI2022的一篇开放域神经信息抽取的综述(OpenIE),先放地址,
paper:https://www.ijcai.org/proceedings/2022/793

A Survey on Neural Open Information Extraction: Current Status and Future Directions
开放信息抽取很适合于许多开放世界的自然语言理解场景,如自动知识库构建、开放领域的问题回答和显式推理。随着深度学习技术的快速发展,许多神经OpenIE架构已经被提出,并实现了相当大的性能提高。
Open Information Extraction (OpenIE)可以定义为以n元关系元组的形式提取事实,即(arg1, predicate, arg2, . . . , argn),而不依赖于预先定义的 ontology schema。如上图是一个抽取例子,面向开放式的文本,抽取得到的元组都由一个predicate和多个arguments组成,而不需要任何特定关系的训练数据。
在深度学习之前,传统的OpenIE系统要么是统计学的,要么是基于规则的,并且严重依赖于语法模式的分析。随着深度学习技术的兴起,信息抽取领域也出现了更多的可能。
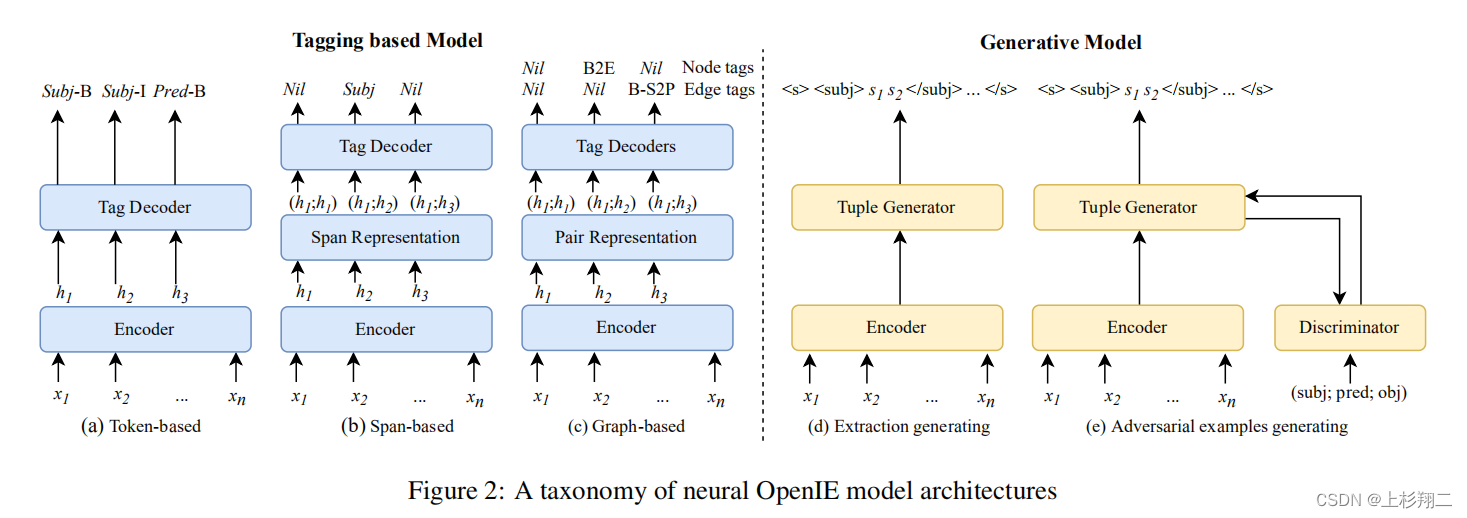
神经OpenIE模型可以分为Tagging-based Models和Generative models,如上图。
Tagging-based Models
基于标记的模型将OpenIE表示为一个序列标记任务。即,给定一组标签,每个标记表示一个标记或一个标记的角色(例如参数、谓词),模型学习每个标记的标签或基于句子的跨度的概率分布,最后OpenIE系统根据预测的标签输出元组。主要有三种实现思路:
- 基于标记的模型(token-based)。预测每个token属不属于argument或predicate。一个常见的标记方案是BIO for Beginning, Inside, and Out。如图2(a)给出了two-token subject和one-token predicate的示例,其中“O”标记该token不是argument或predicate的一部分。
- 基于跨度的模型(span-based)。直接预测token跨度是argument还是predicate。图2(b)给出了一个示例span(h1;h2)。通常,所有可能的span都要从输入句子中枚举并预测其类别。
- 基于图的模型(graph-based models)。构建一个Graph来识别三元组,其中节点为token spans,以及表示属于相同事实的连接节点的边,通过挖掘图中的最大团系来提取元组。如上图c。
Generative Models
生成模型将OpenIE表示为一个序列生成问题,它读取一个句子并输出一个序列的提取。
- Generate Extractions。生成模型架构通常包括:一个要给出句子上下文的分布式表示的编码器,和一个基于句子上下文和目前生成的序列来顺序生成的解码器。如上图d。
- Generate Adversarial Examples。该模型的目的是获得一个生成器,它可以生成与黄金注释非常相似的元组,以混淆鉴别器的判断。如上图e。
Model Comparison
与生成Generative模型相比,大多数基于标记Tagging的模型是非自回归的。这种基本的差异导致了四个典型的模型差异:
- 1)提取依赖性。自回归模型基于之前的预测结果去预测下一个元组,导致元组之间产生不必要的序列依赖性,这种依赖关系可能会导致多个步骤之间的错误传播。不过,这种依赖性也可以利用事实之间的相关性,以实现更好的推理。
- 2)提取的真实性。基于标记的模型不像生成模型那么灵活,因此提取的元组可能是不连贯的。
- 3)提取的可靠性。另一方面,生成模型的存在性也带来了不准确提取的风险:可能会产生在原始文本中没有表达出来的毫无意义的事实。
- 4)提取速度。自回归模型是 step by step逐步地输出结果,而基于标记的方法可以利用GPU并行性同时输出结果。因此Tagging推理速度大约比生成模型模型快35倍。
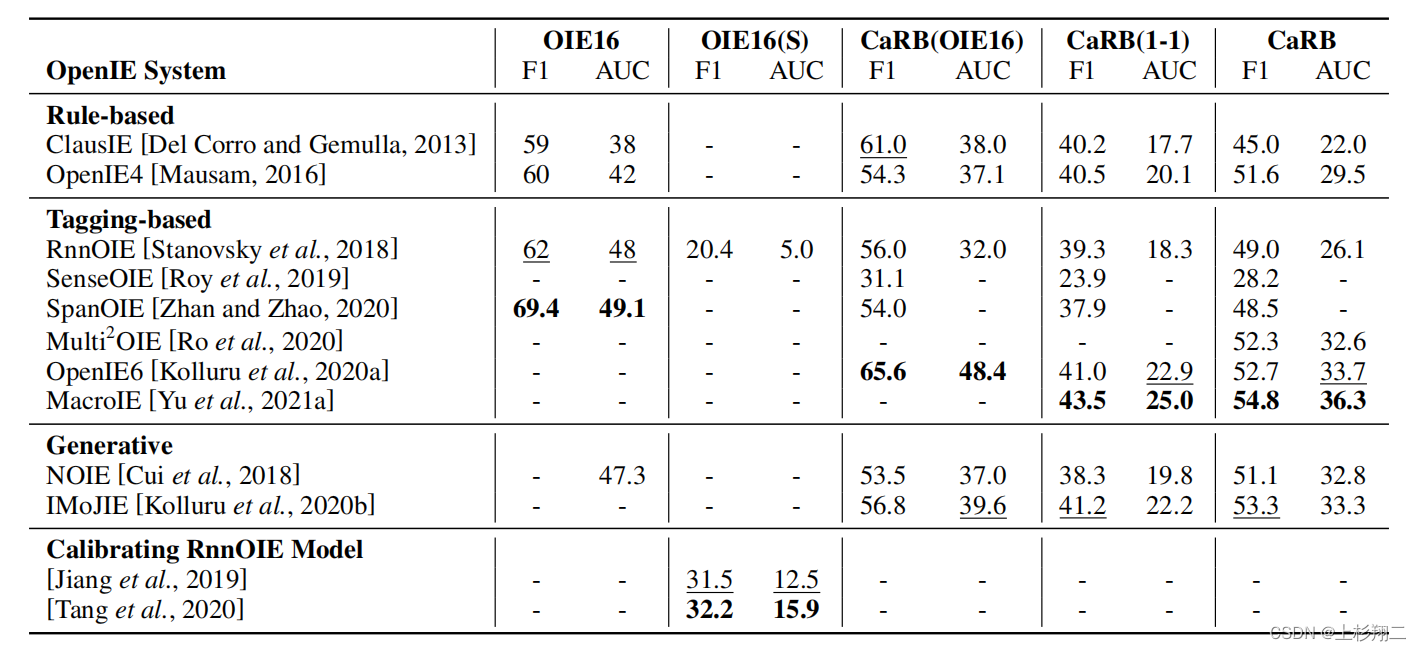
Performance Evaluation
神经OpenIE系统在两个流行的OIE2016和CaRB数据集上的性能。
Challenges and Future Directions
存在的挑战主要有,
- Evaluation。神经OpenIE仍然缺乏大规模、高质量的训练数据。
- Defnition。普通OpenIE不适用于开放域信息提取,然而大多数现有的研究都是在新闻、百科全书或网页上评估他们的解决方案,因此需要进行覆盖更多领域的基准测试。
- Application。与Closed IE相比,从OpenIE中提取的东西更难以使用。很有可能有多个谓词引用同一语义关系,或参数引用同一实体。如(Einstein; was born in; Ulm), (Ulm; is the birthplace of ; Einstein)。
未来的方向主要有,
- More open。新的源可以是文档级文本、多语言语料库或多模态数据。
- More focused。经典的OpenIE需要从源文本中提取所有事实。然而在许多情况下,我们只对与某些主题/实体相关的事实感兴趣,而后者可以是预先设定的。因此,抽取操作需要更加集中,并且更容易用于下游任务。
- More unifed。OpenIE可以被视为最通用的IE任务,如实体识别、关系理解、元素匹配等。但目前没有一个统一IE任务之间的通用模型。
开放域抽取的特点是不限定关系类别、不限定目标文本,难点在于如何获取训练语料、如何获取实体关系类别、如何针对不同类型目标文本抽取关系。
具体OpenIE知识库也有多个重要的版本或系统的提出。
KnowItAll
KnowItAll是2004年由华盛顿大学发布,它主要基于可扩展的本体和少量的通用规则模板种子,为预定义类别和关系生成提取模板。主要包括以下三个步骤:
- 提取器(Extractor),利用规则如Marti Hears上下位抽取得到实体和实体关系。
- 搜索引擎接口(Search Engine Interface)。利用搜索引擎进行扩充,具体来说,会拿特定类别提取规则中的关键词请求搜索引擎,然后解析返回的结果,进行词性标注和名词短语识别,再依照第一步的规则进行匹配和规则约束提取。
- 以及概率评估器(Probabilistic Assessment)。对抽取得到的三元组进行过滤。
TextRunner
和KnowItAll类似,也分为三个步骤:
- 自监督学习器(Self-Supervised Learner)。它主要使用非词汇化词性和NP短语特征作为特征,并构造训练数据集,训练朴素贝叶斯模型或线性CRF与马尔可夫网络进行训练来判断给定三元组是否可信。
- 单步抽取器(Single-Pass Extractor)。对于输入的一句话,其进行词性标注和名词短语识别,并以短语之间的词语作为关系表示。再使用分类器进行分类来判别三元组是否可信。
- 基于冗余的评估器(Redundancy-Based Assessor)。由于直接以短语之间的词语作为关系表示,因此需要对关系短语进行归一化,如去除不必要的修饰词、副词等。
Reverb
TextRunner的归一化方法容易得到一些不可理解的关系短语,因此Reverb提出基于词性标注的关系抽取方式。
- 使用OpenNLP对原始句子进行词性标注和组块识别,再完成关系抽取和论元抽取。
- 设计句法约束和词法约束。这种细化使模型能够轻松处理包含多个动词的关系短语,并且满足短语构成的连续性。
OLLIE
Reverb的缺点在于其只能处理有限的句子结构,并将关系限制在动词模式,忽略了句子的上下文信息。因此OLLIE试图扩大关系短语的句法范围以覆盖更多的关系表达和上下文信息。
- 关系模式的获取。对包含三元组的句子进行依存关系分析、标注、句法检测、泛化得到一些关系模式。
- 基于关系模式的抽取。然后基于构建好开放模式实施提取。